







 zeppelin旨在提供一个支持多语言混合的REPL环境,允许用户在一个Note中混合使用多种语言进行数据分析和机器学习。对于使用者,这意味着更灵活的任务实现和调试能力;对于管理者,zeppelin降低了运维成本并提供了安全控制。zeppelin设计面临的问题包括代码执行位置、多租户支持、并发执行策略等,其解决方案涉及到解释器管理、进程通信和扩展性。zeppelin还提供了丰富的外围功能,如解释器接口、前端反馈和版本控制,以支持持续扩展和易用性。
zeppelin旨在提供一个支持多语言混合的REPL环境,允许用户在一个Note中混合使用多种语言进行数据分析和机器学习。对于使用者,这意味着更灵活的任务实现和调试能力;对于管理者,zeppelin降低了运维成本并提供了安全控制。zeppelin设计面临的问题包括代码执行位置、多租户支持、并发执行策略等,其解决方案涉及到解释器管理、进程通信和扩展性。zeppelin还提供了丰富的外围功能,如解释器接口、前端反馈和版本控制,以支持持续扩展和易用性。
通过我其他的zeppelin分析文章,大家可以从中了解zeppelin是什么样的。本篇试着阐述问题的另外一面,zeppelin为什么是这样的?本文从需求出发,探寻zeppelin的架构设计、技术选型、代码的模块划分和依赖关系最初的“出发点”。
zeppelin的核心功能用一句话总结就是:支持多语言混合的REPL(Read-Evaluation-Print-Loop)。这个核心功能的价值体现在:
站在使用者的角度,意味着:
1. 可以在一个Note中混合使用多种语言。用户可以根据需要完成的任务的类型,选择最合适的语言来实现,不再受限于单个语言的特性。例如:MarkDown能做出漂亮的文档,python和R有大量的科学计算、机器学习和可视化包,scala与Spark有天然的血缘关系,Shell处理本地文件非常方便……,可以想象一下将这些语言的优点都结合起来,会产生多么强大的生产力。
2. 数据分析和机器学习,从来都不是一个“一蹴而就”的过程。分析过程和机器学习算法一样,本质是不断迭代和试错的过程。数据科学家和算法工程师对数据分析平台最看中的能力是“有丰富的组件”和“可调试”(至少在我接触到的数据科学家和算法工程师来看是这样的),前者表达了对平台功能全面的需求,后者表达了如何对采用这些功能“平顺”地开展实际业务分析的需求,二者相辅相成。REPL相对于“拖拽式”的数据分析平台,虽然不能像传统IDE一样,设置断点和查看中间变量,但是相对于“纯黑盒”的拖拽式数据分析工具,能在很大程度上实现“调试”功能。
站在管理者的角度,意味着:
1. 使得统一工具环境成为可能。一个数据分析团队中,各成员由于擅长的语言不同,可能需要同时维护多种环境,如R、Python远程桌面开发环境,R和Python都是通过第三方扩展包进行扩展的,成员熟练使用的包,也有所不同,给运维造成了较大压力。实现一个集中式的分析工具,在服务端集中于一处,统一配置R、Python、Spark、Hadoop、Hive等开发环境,显著降低运维成本。
2. 使得进行统一安全控制成为可能。B/S系统,方便进行集中式用户权限控制,并且由于该平台”看到”的是各种语言的源码,可以对恶意代码进行监测和过滤,避免有意或者无意地对系统造成的损害。此外,可以限制所有过程都在线操作,不存在跨机器传递数据的问题,可限制导出数据,保障数据安全。
现在,让我们抛开对zeppelin的已有认知,假设让我们重新设计一个平台,实现上述核心功能,会面临哪些问题,这些问题都有哪些解决方案,各种方案又孰优孰劣,在此过程中,探寻zeppelin的设计动因和它要解决的问题。
首先看一下该平台要应对的典型场景:
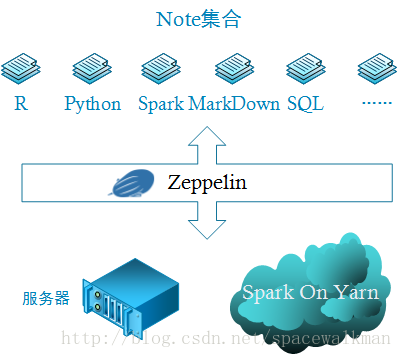
平台要解决的是:在服务端资源一定的情况下,如何尽可能正确和高效地执行多个用户混合了多种语言的Notes问题。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









