







感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
流程:
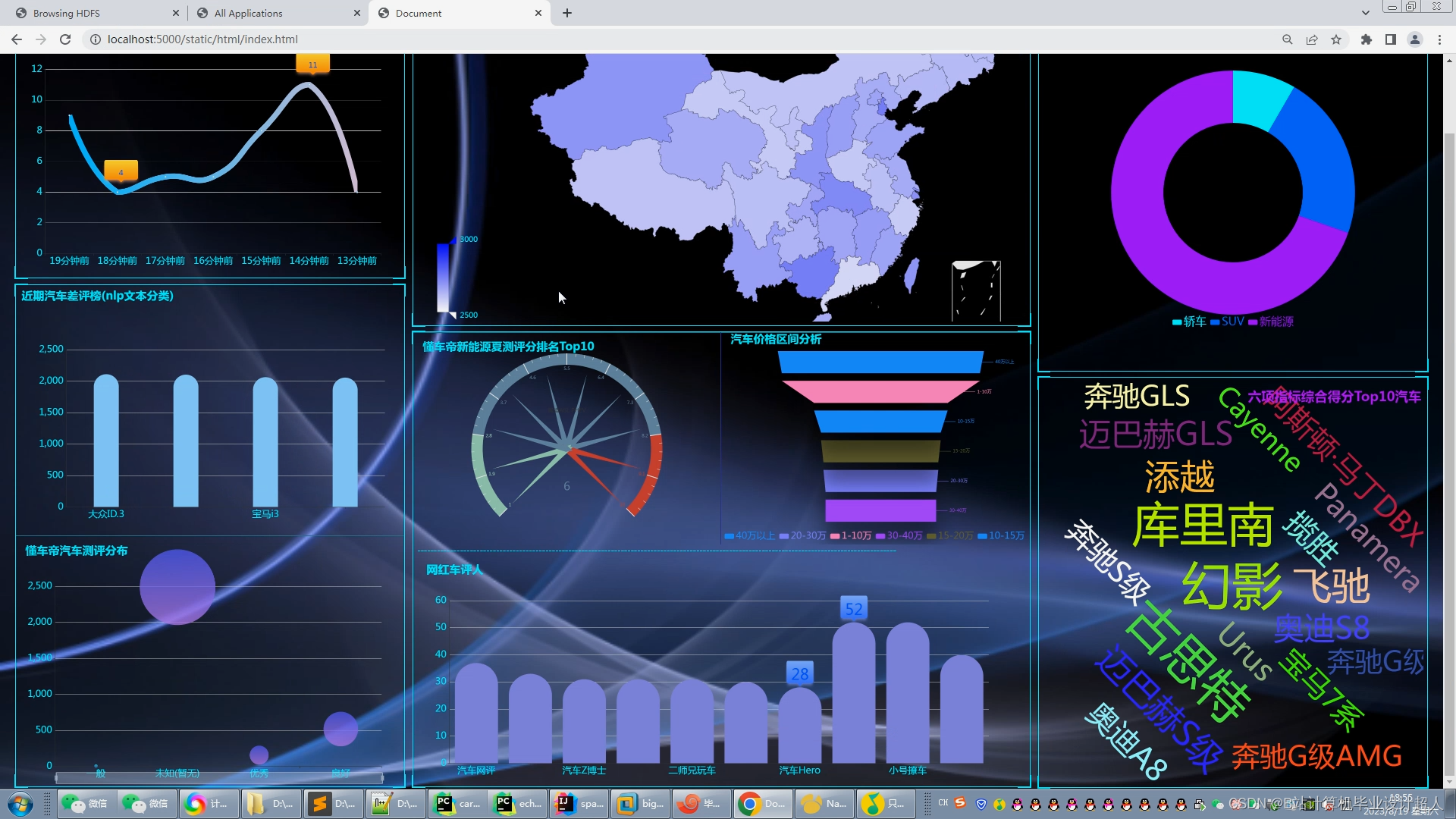
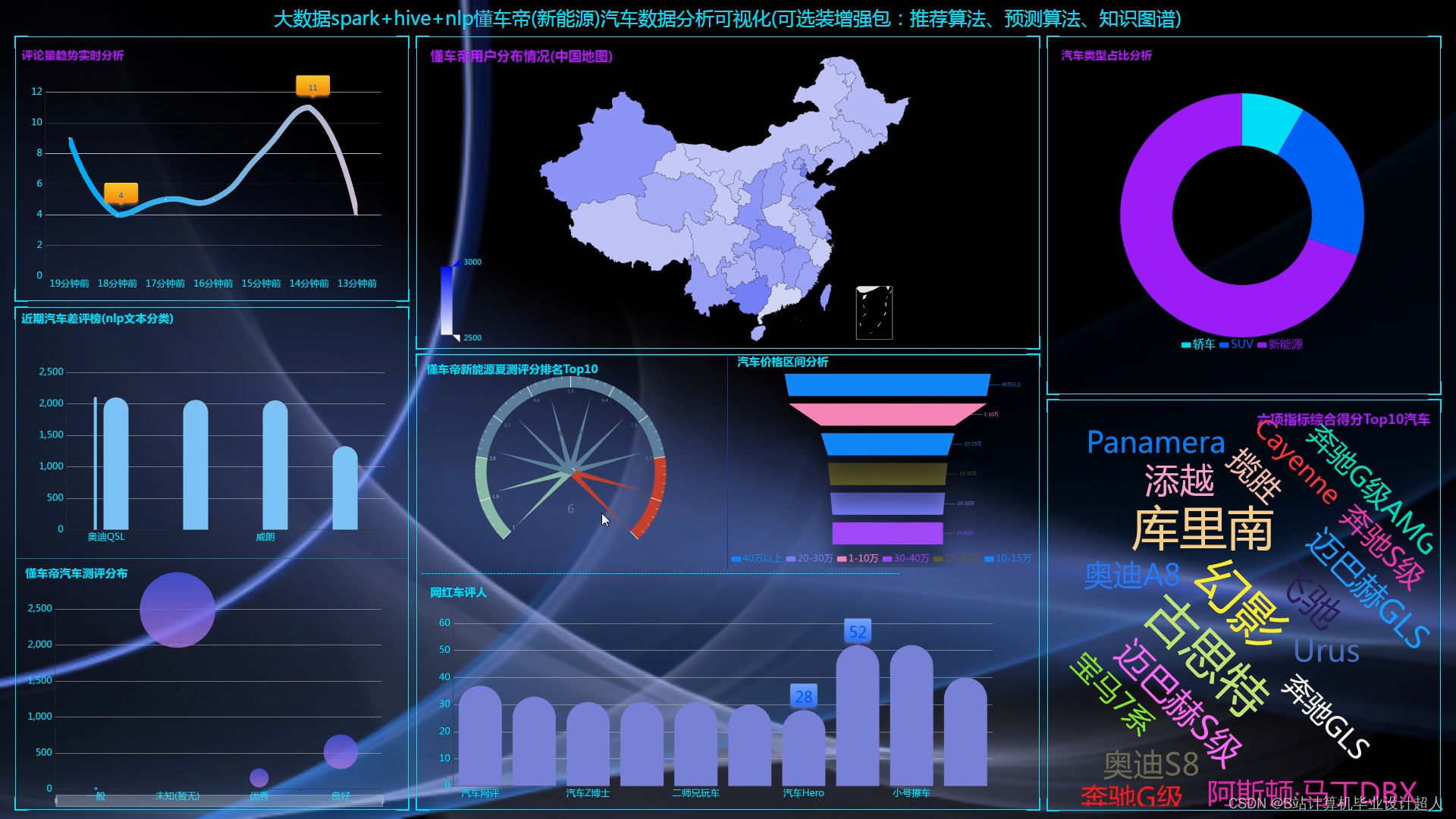
1.Python爬虫采集懂车帝汽车评分数据、汽车评论数据、车评人数据等存入mysql和.csv文件;
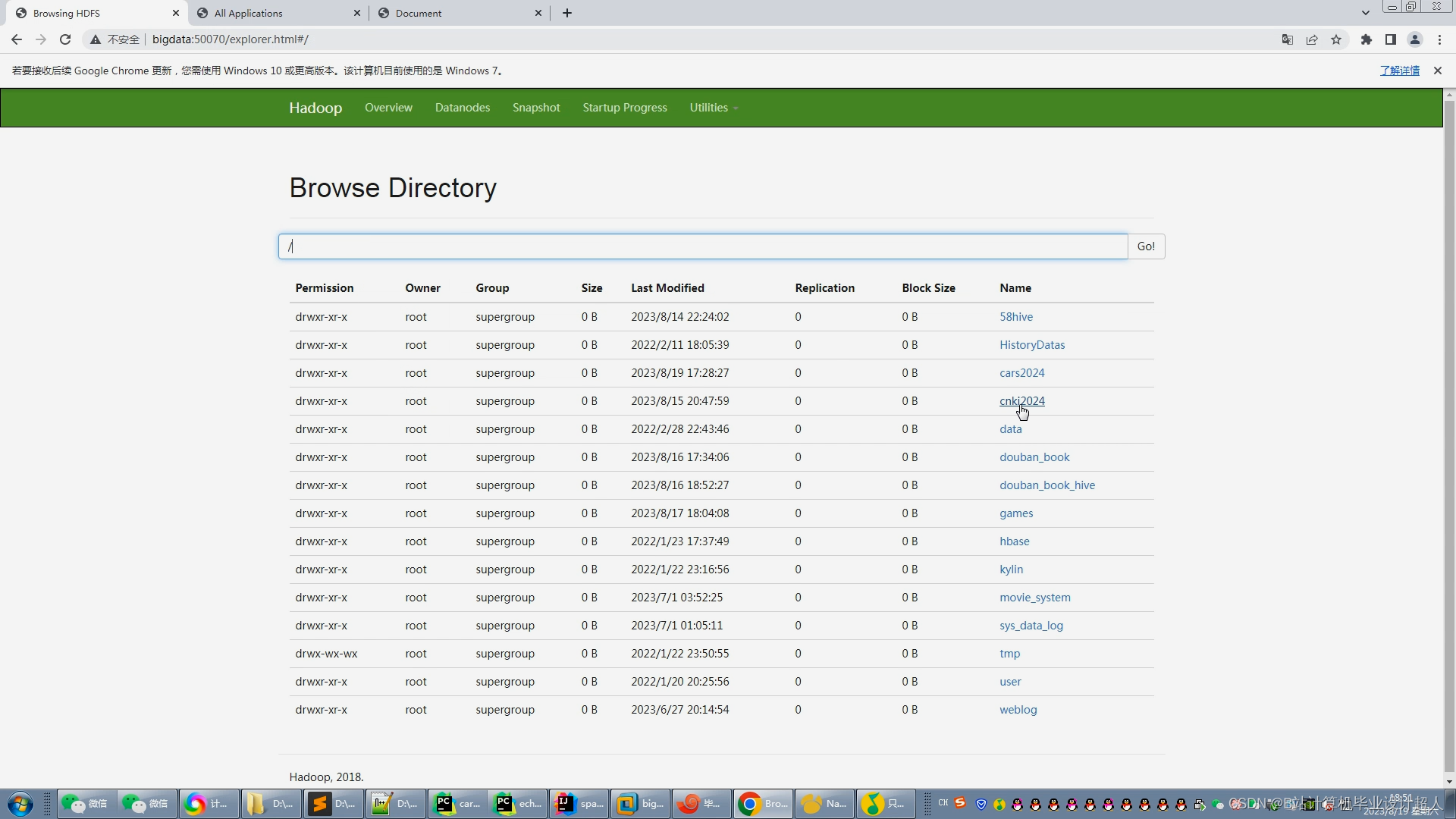
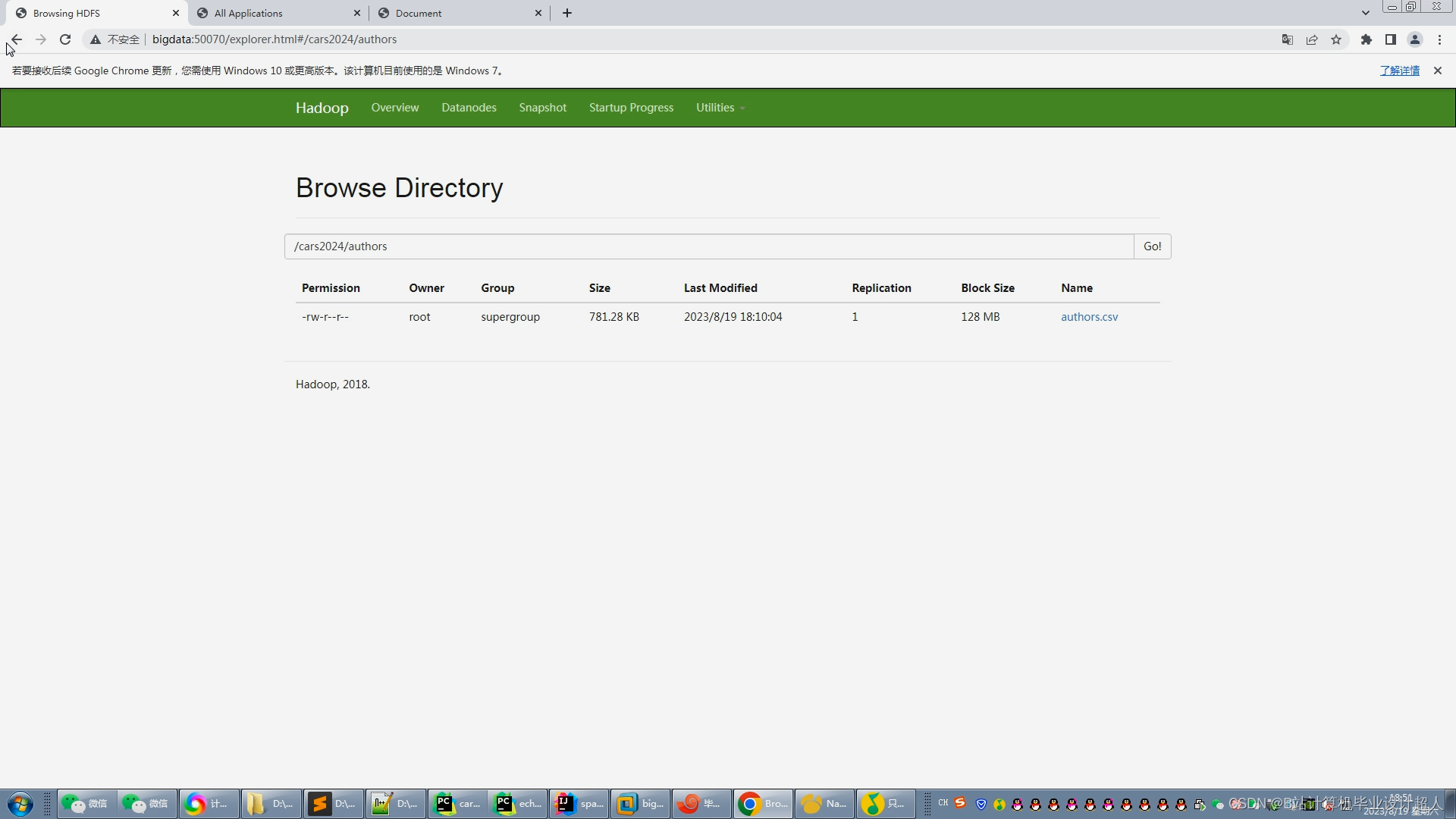
2.使用pandas+numpy或者MapReduce对上面的数据集进行数据清洗生成最终上传到hdfs;
3.使用hive数据仓库完成建库建表导入.csv数据集;
4.使用hive之hive_sql进行离线计算,使用spark之scala进行实时计算;
5.将计算指标使用sqoop工具导入mysql;
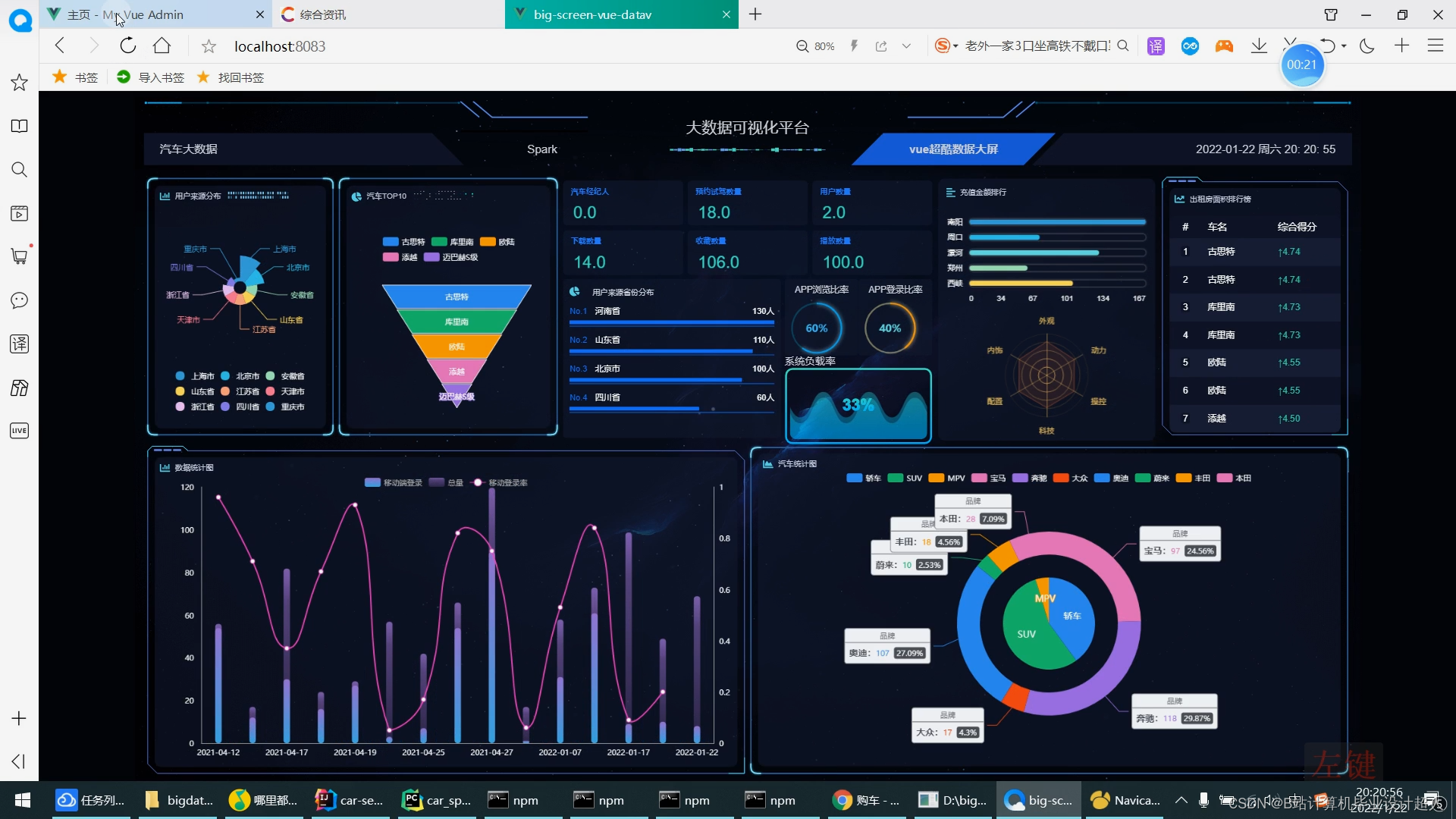
6.使用Flask+echarts进行可视化大屏实现;
创新点:nlp文本分类情感分析、装杯大屏幕、Python爬虫采集海量(10万+数据)、hive离线计算+spark实时计算双实现防止导师喷你!
注意:如果你还觉得系统工作量不够或者太low可以选装推荐算法、预测算法、知识图谱、后台管理等
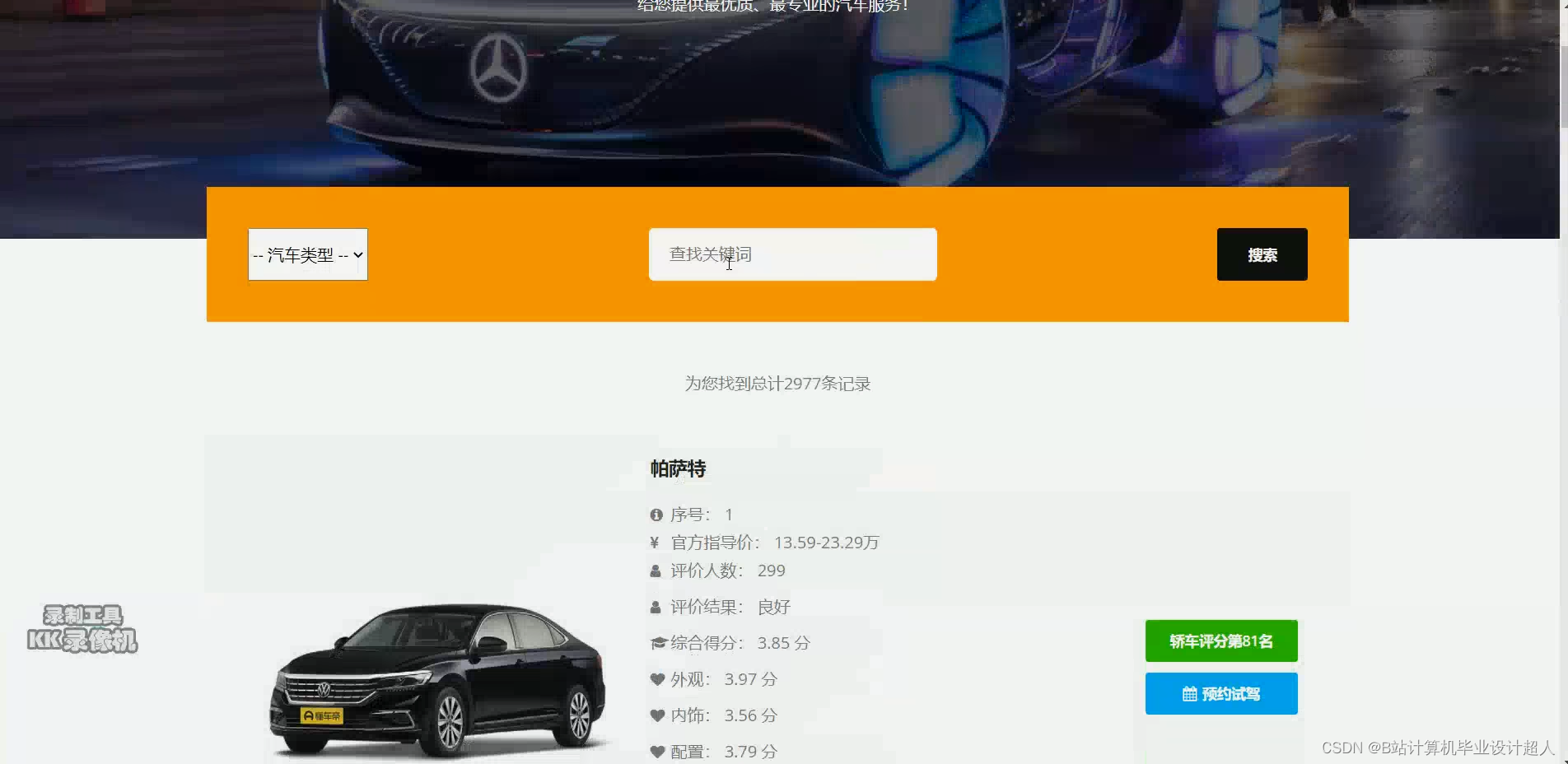
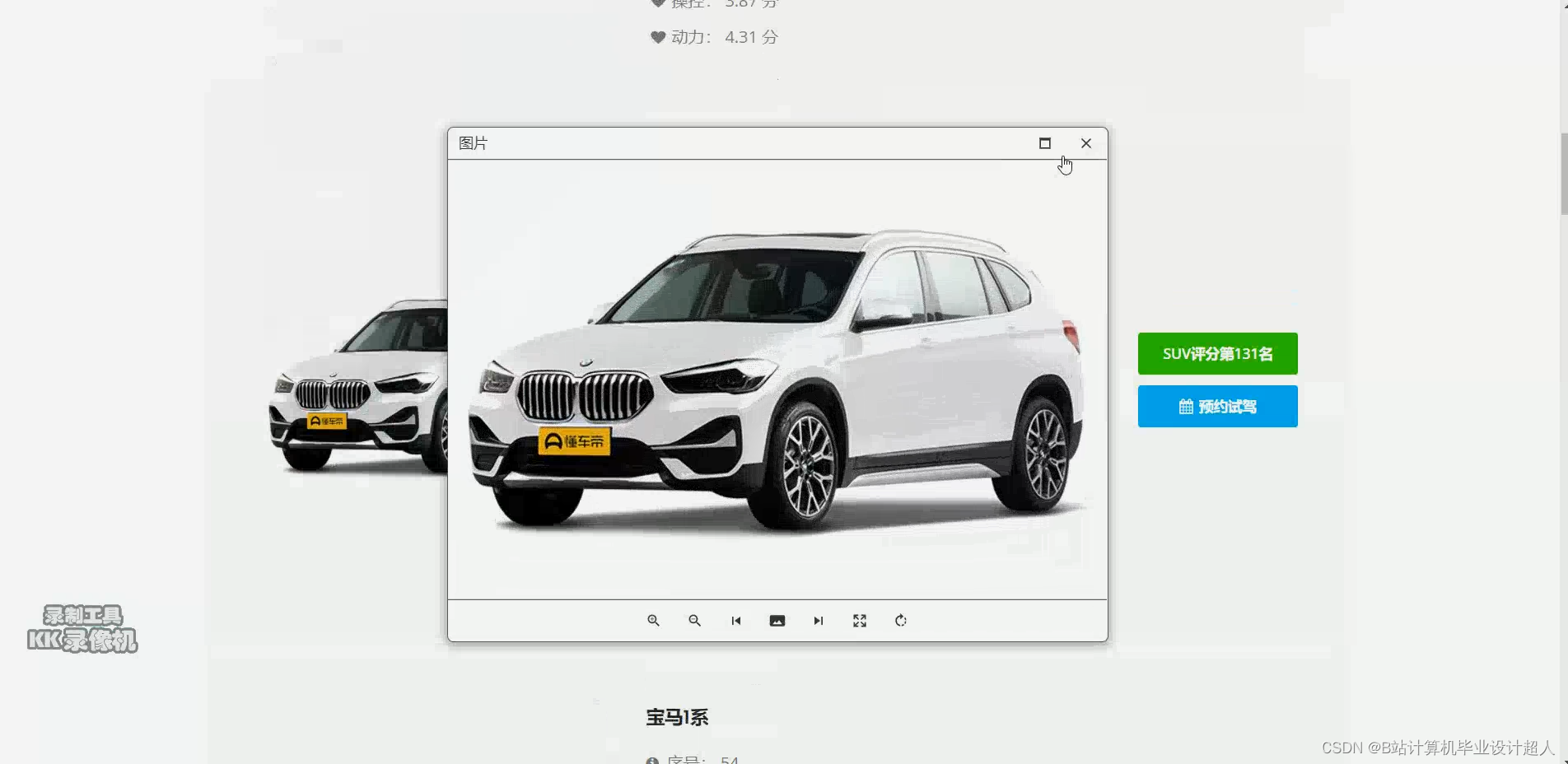
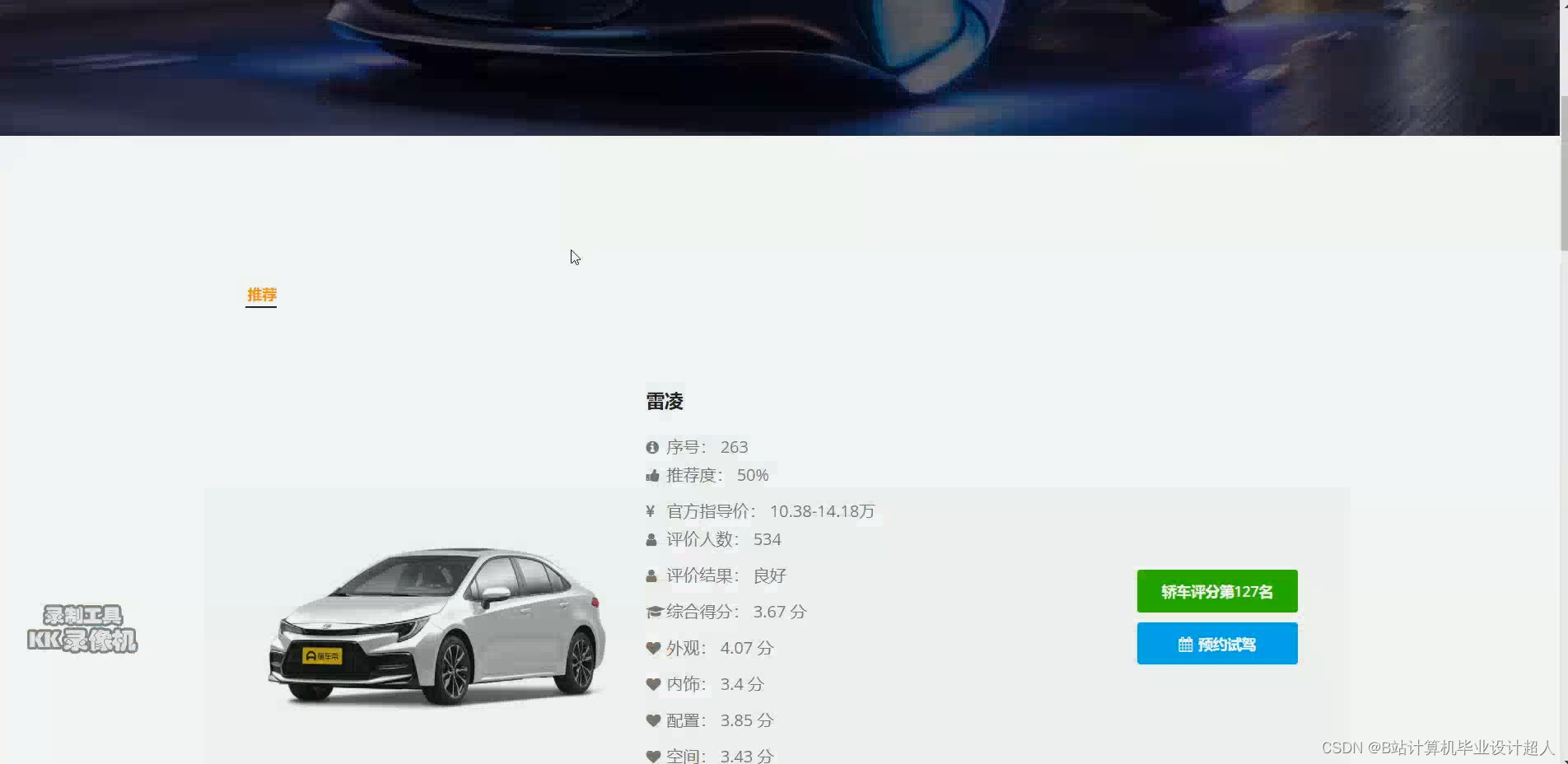
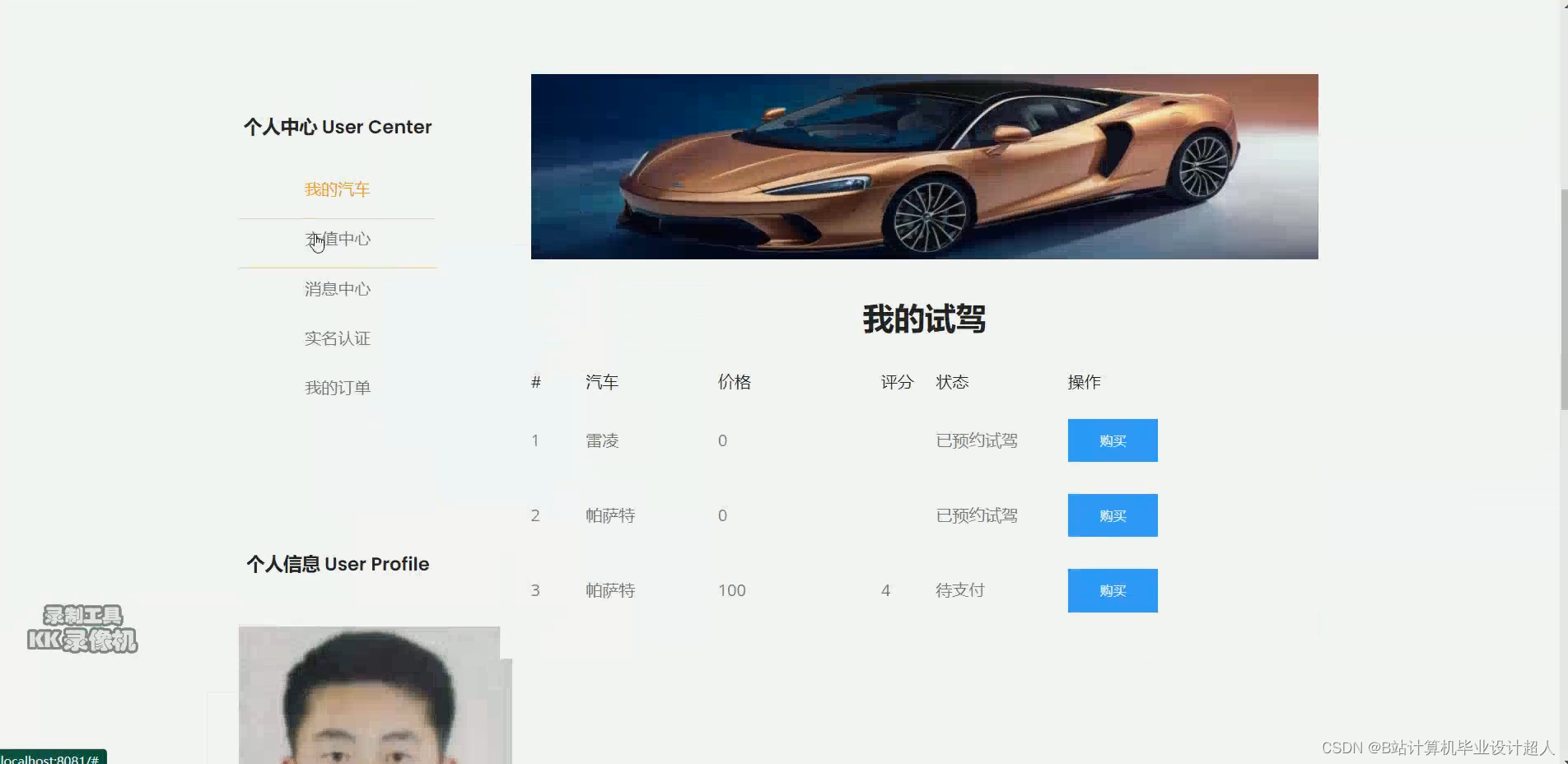
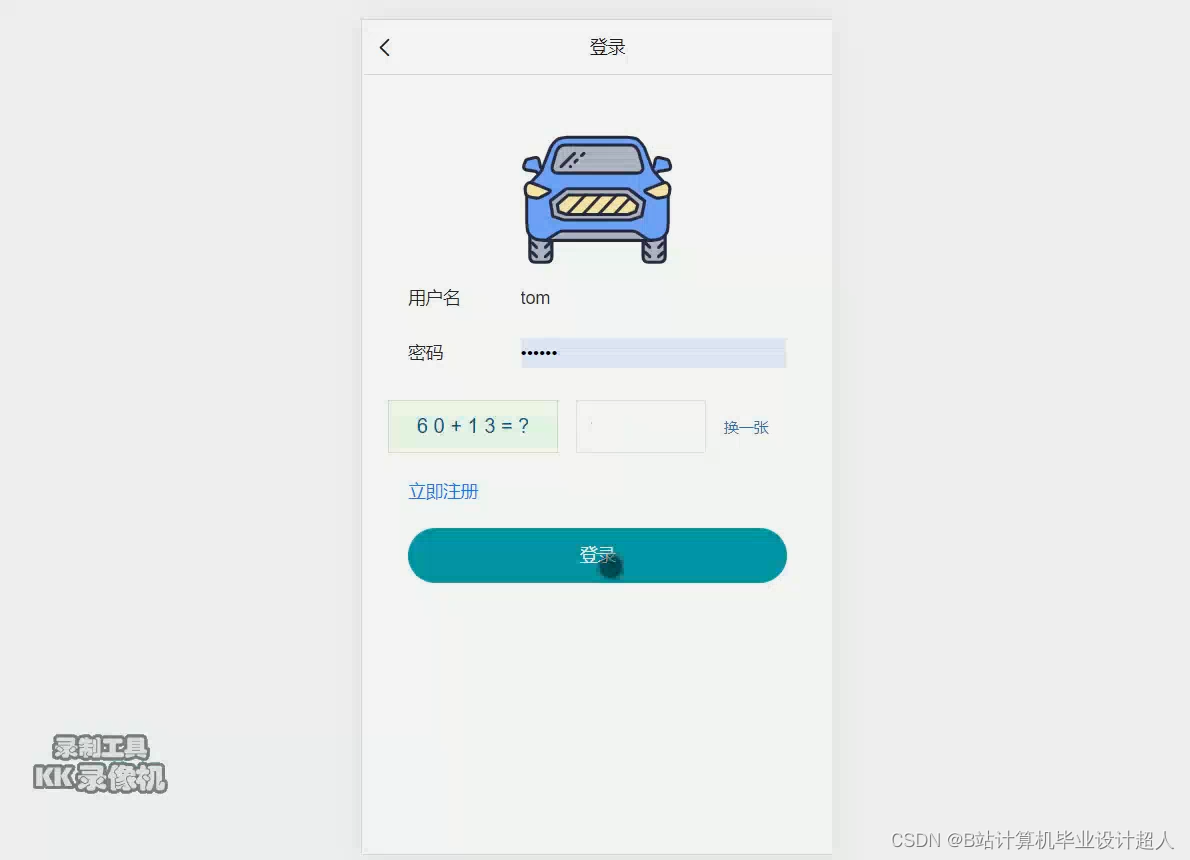
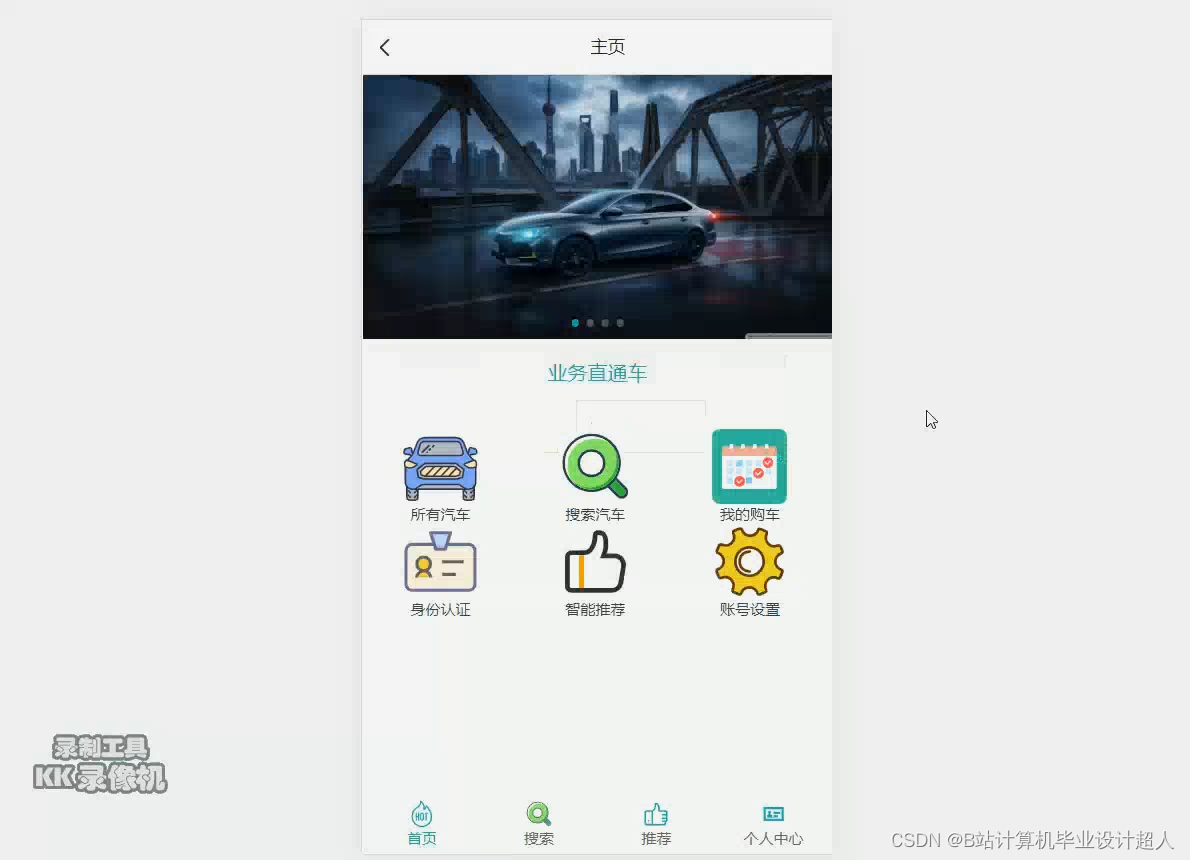
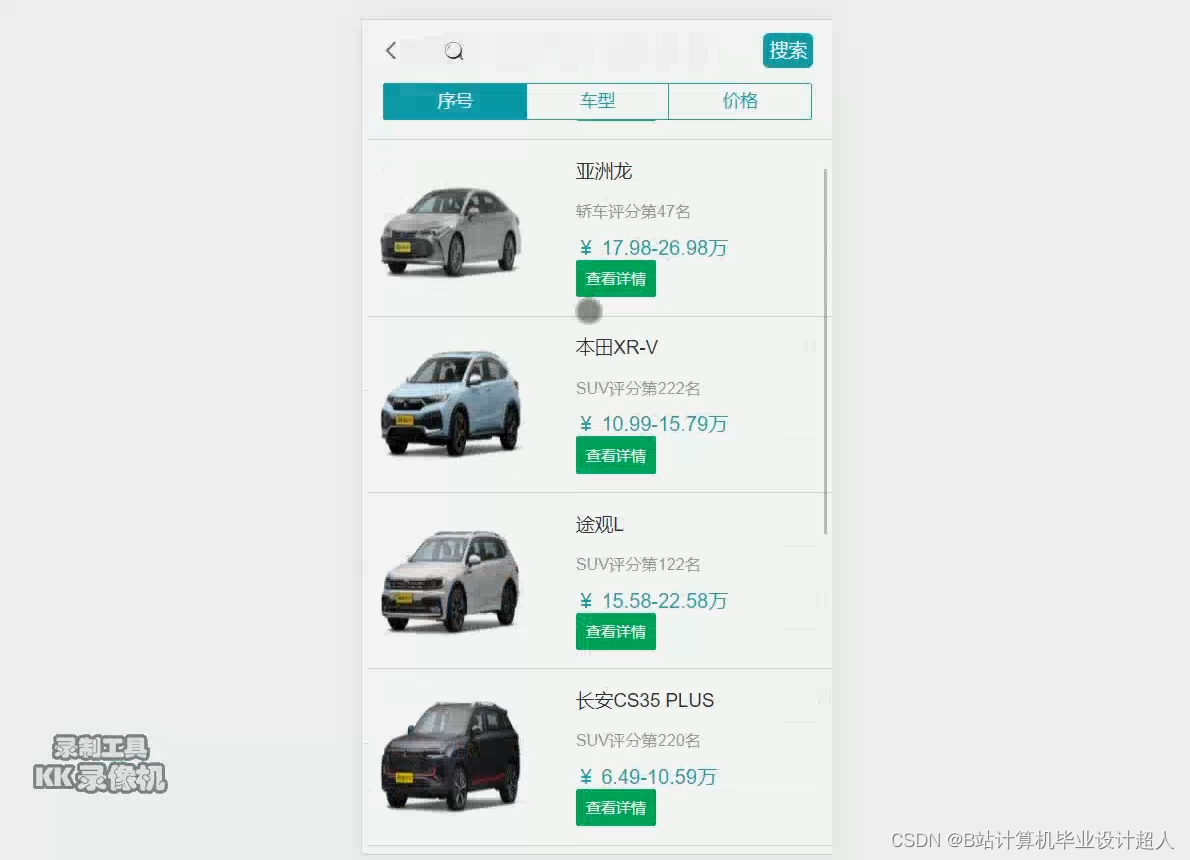
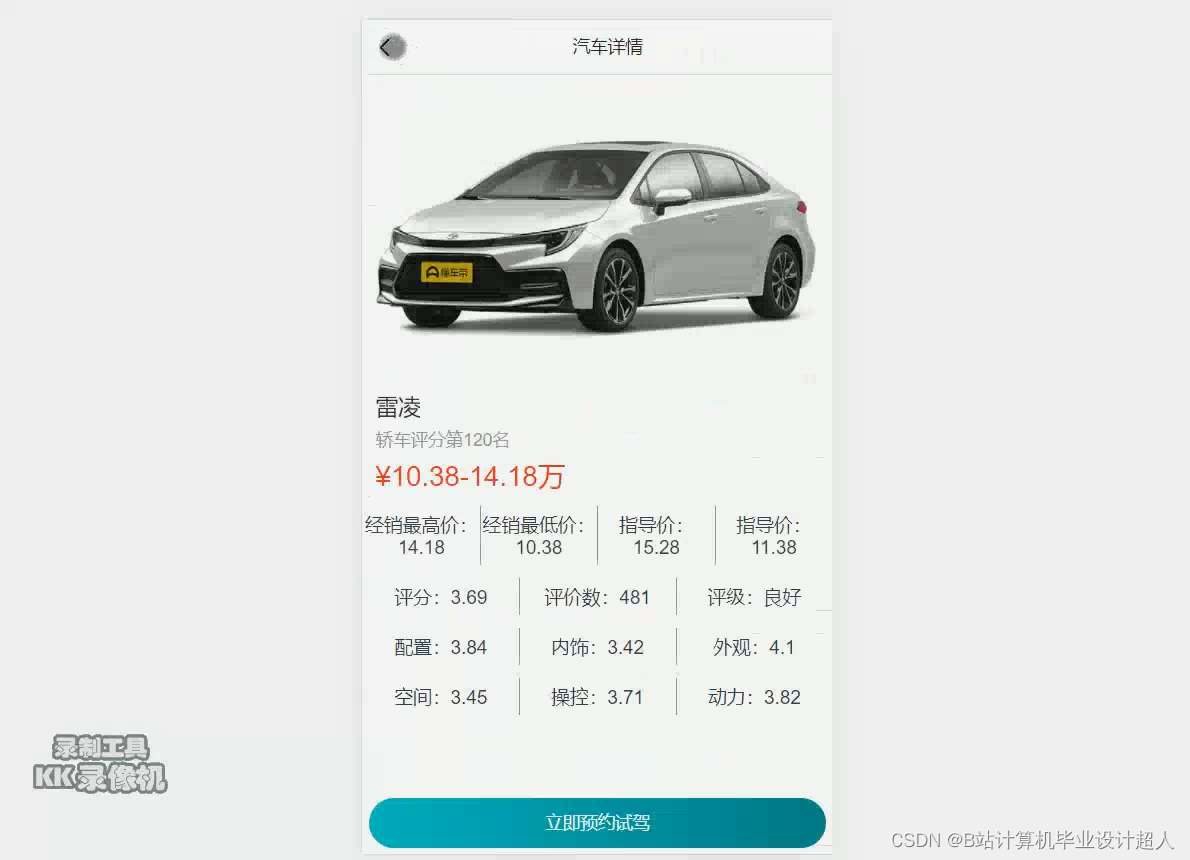
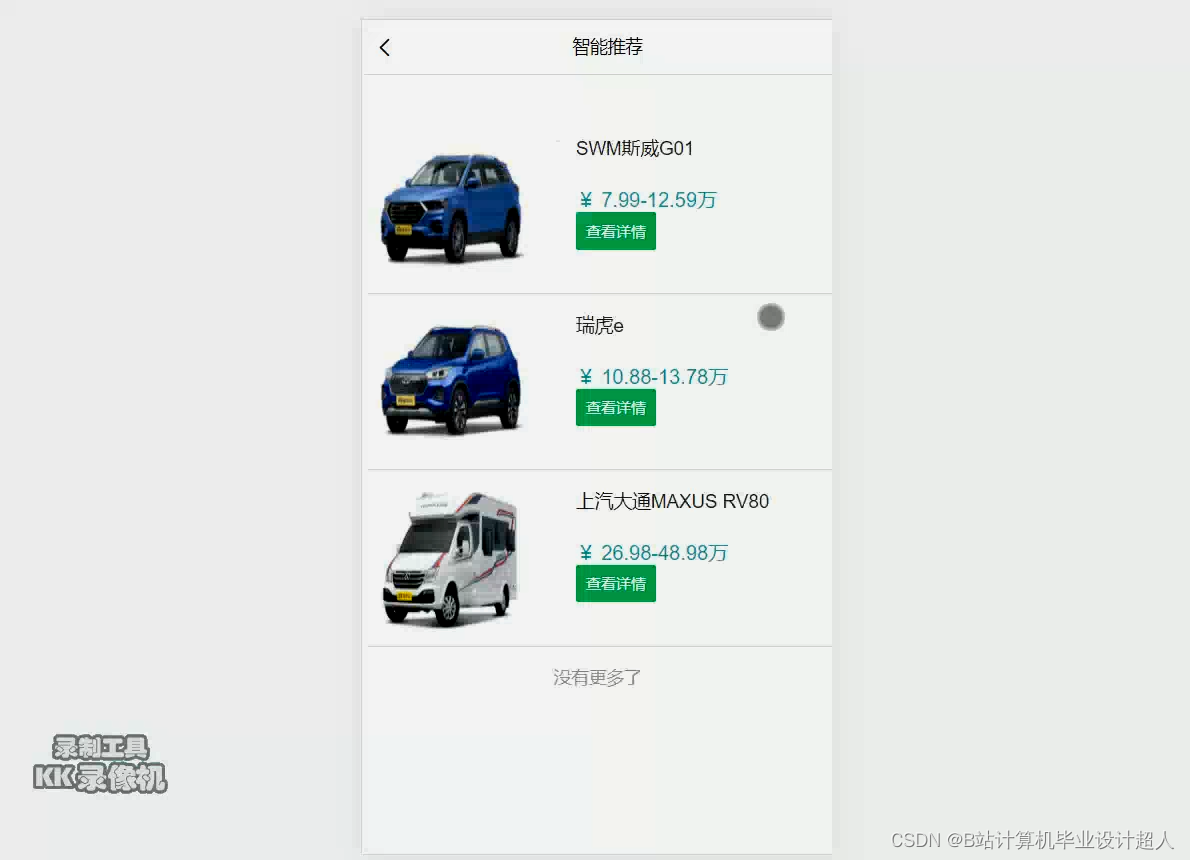
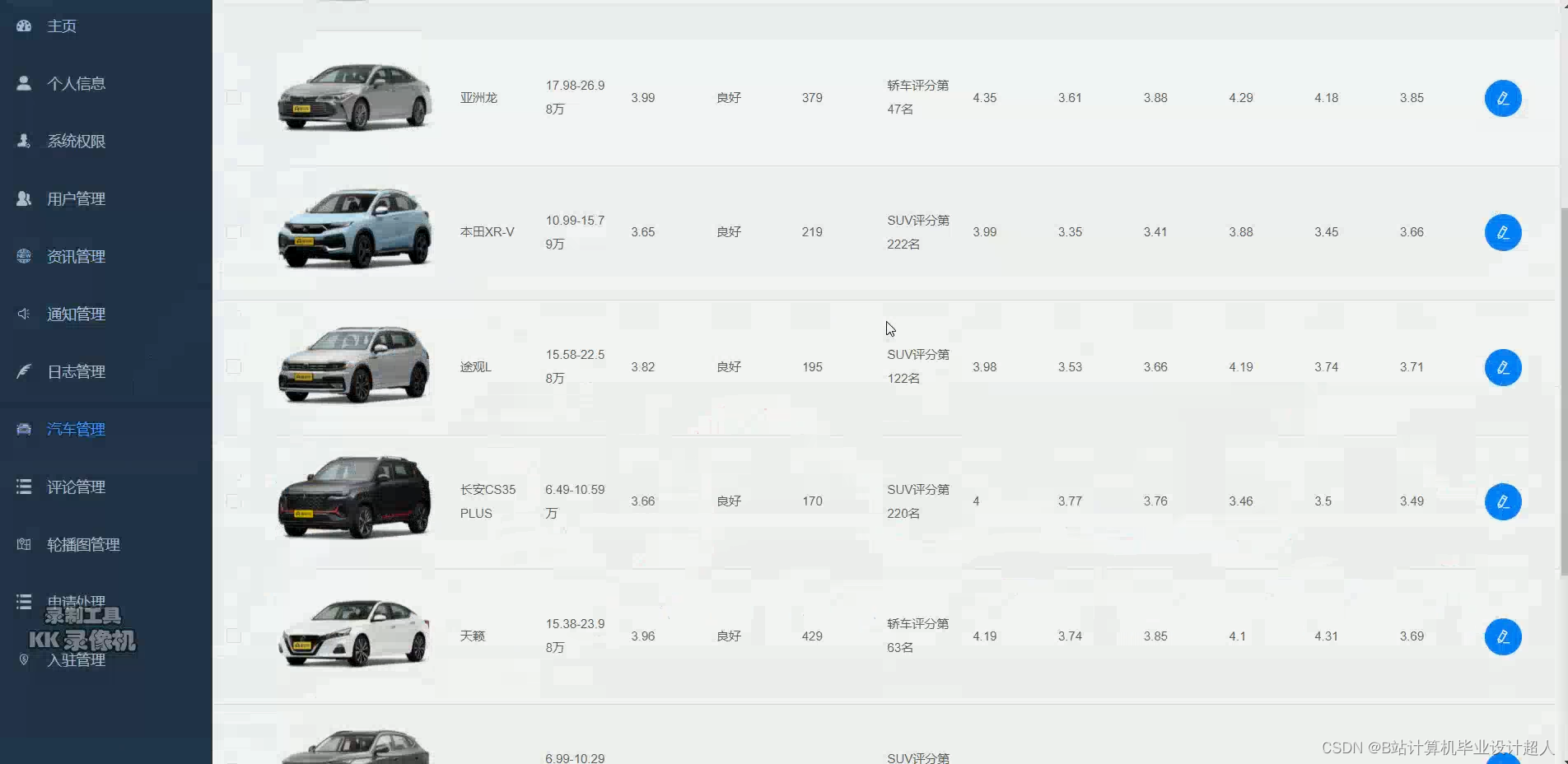
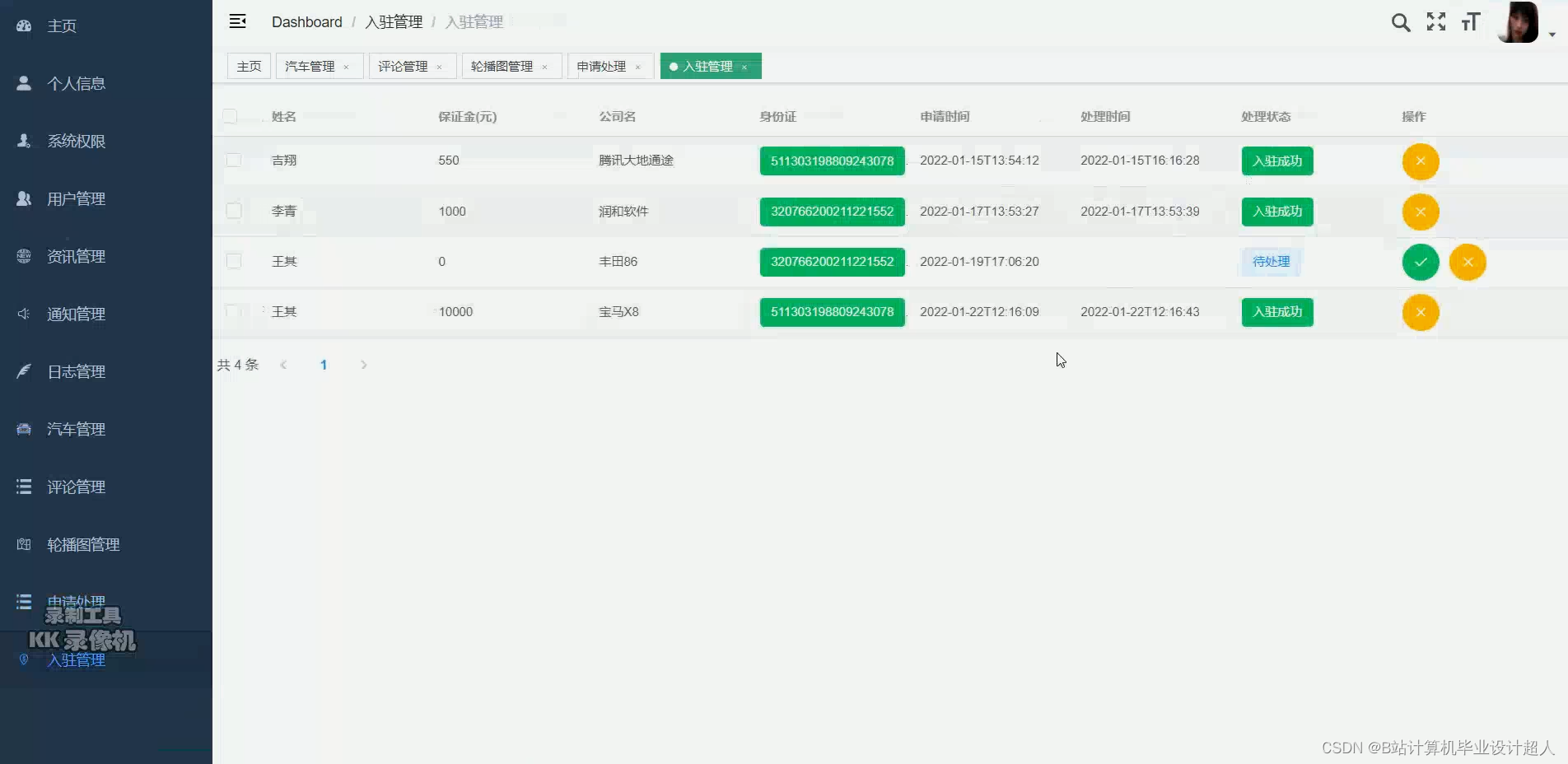
部分核心代码分析解析如下:
import requests
from bs4 import BeautifulSoup
# 定义要爬取的URL
url = 'https://www.dcd.cn/car/选择你要爬取的车型'
# 发送HTTP请求并获取页面内容
response = requests.get(url)
response.encoding = 'utf-8' # 指定页面编码
# 使用BeautifulSoup解析页面内容
soup = BeautifulSoup(response.text, 'lxml')
# 查找价格信息所在的元素
price_info = soup.find('div', class_='price-info')
# 提取价格信息并打印
price = price_info.find('span', class_='price').text.strip()
print(f"价格: {price}")

















 1337
1337

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











