






 本文探讨了如何利用大数据技术对慕课平台的课程学习数据进行行为分析,通过机器学习和深度学习构建模型,实现个性化推荐。研究内容包括数据采集、预处理、模型构建(如协同过滤、深度学习模型)、数据可视化以及预期的成果和时间安排。
本文探讨了如何利用大数据技术对慕课平台的课程学习数据进行行为分析,通过机器学习和深度学习构建模型,实现个性化推荐。研究内容包括数据采集、预处理、模型构建(如协同过滤、深度学习模型)、数据可视化以及预期的成果和时间安排。
| 课题名称 | 基于大数据的慕课平台课程学习数据行为分析可视化与个性化推荐 | ||||
| 课题来源 | 课题类型 | BY | 指导教师 | ||
| 学生姓名 | 专 业 | 计算机科学与技术 | 学 号 | ||
| 开题报告内容:(调研资料的准备,设计/论文的目的、要求、思路与预期成果;任务完成的阶段内容及时间安排;完成设计所具备的条件因素等。) 一、选题背景
二、设计目的和要求
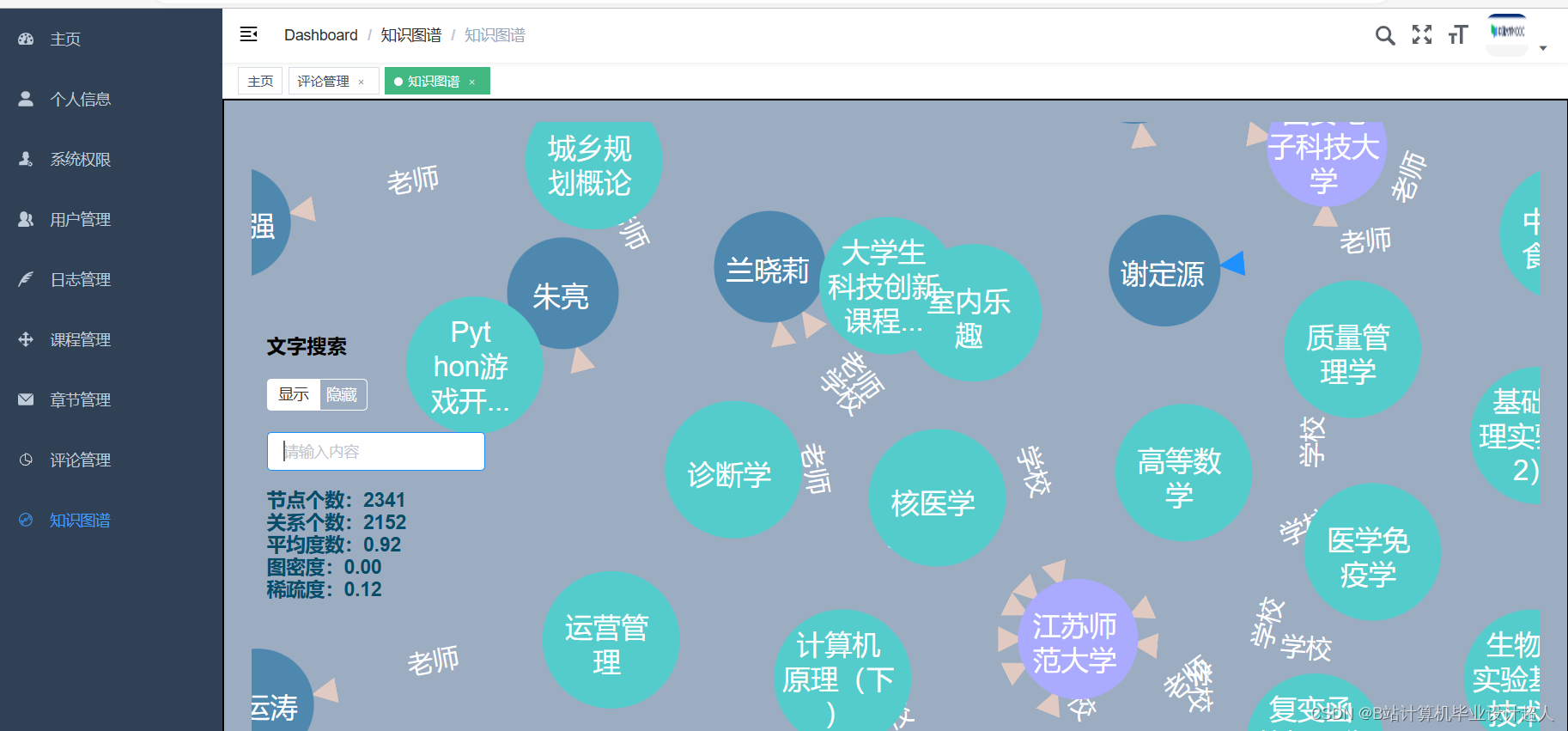
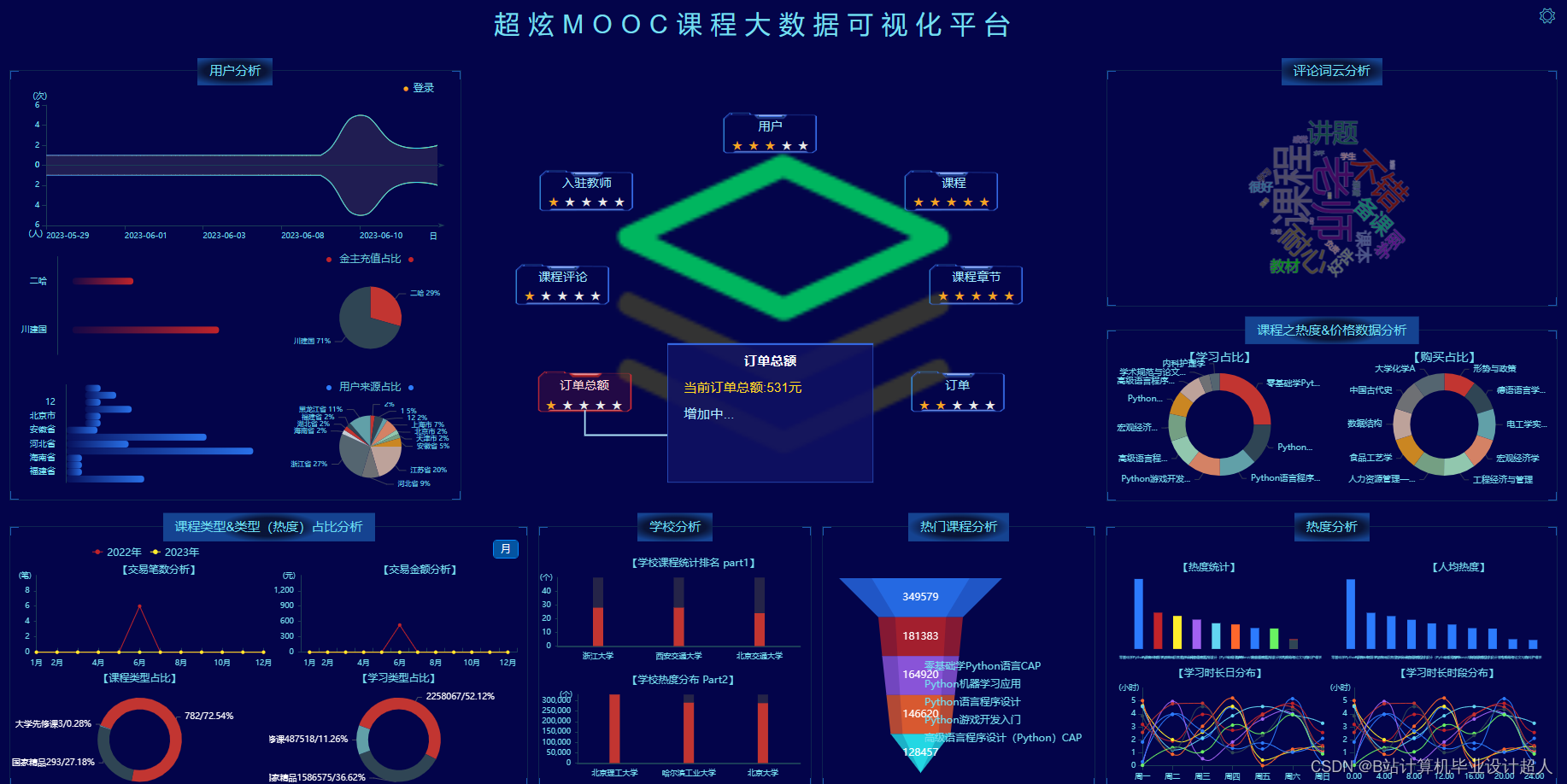
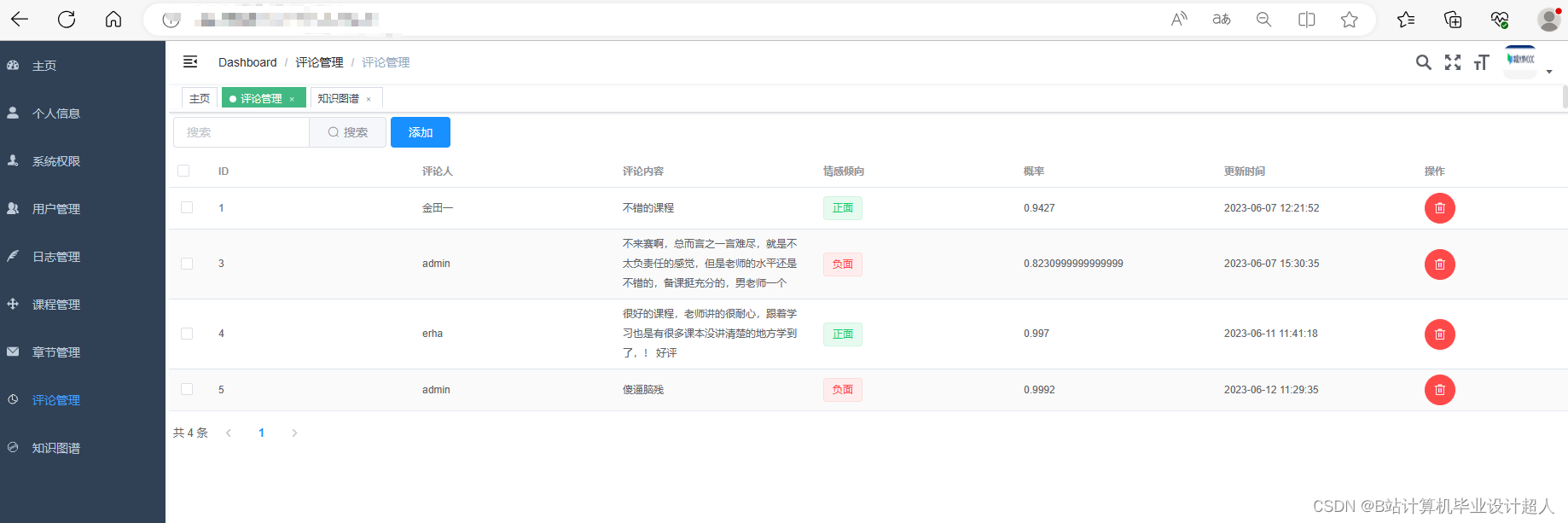
(1)使用PyCharm、IDEA等工具进行代码编写。 (2)结合机器学习、深度学习等数据分析技术构建模型。 (3)使用知识图谱、SparkSQL等技术进行数据可视化大屏分析
(1)认真查阅相关文献资料,充分做好前期准备工作。 ①到学校图书馆借阅机器学习和数据挖掘等方面的图书。 ②从中国知网等网站查找相关论文 20 篇,重点阅读 10篇。 ③通过查找相关课程视频,自主学习与本课题有关的知识。 (2)按照毕业论文(设计)相关文件要求独立完成毕业论文(设计)。 ①完成课程推荐系统、可视化系统的设计与实现。 ②撰写论文时,要有图表形象表达,要体现论文的主要特色。 三、设计内容和思路 内容 (1)采集数据集:利用selenium框架采集mooc慕课网海量课程数据。 (2)数据预处理:对数据进行缺失值、重复值处理,导入mysql数据库等操作。 (3)模型构建与测试:构建协同过滤算法(基于用户/物品)、LSTM、SVD神经网络混合推荐模型、MLP模型等,使用课程数据集、用户轨迹数据(随机构造、程序埋点生成)进行测试,并依据测试结果,对所有模型的效率、精准度进行优化。 (4)系统可视化:使用Spark、Hadoop、Hive、知识图谱neo4j图数据库、echarts等技术对数据进行可视化数据分析。 思路 (一) Selenium自动化Python爬虫工具采集慕课网课程课程数据、学习数据约80-100万条存入.csv文件作为数据集; (二)使用pandas+numpy或MapReduce对数据进行数据清洗,生成最终的.csv文件并上传到hdfs; (三)使用hive数仓技术建表建库,导入.csv数据集; (四)离线分析采用hive_sql完成,实时分析利用Spark之Scala完成; (五)统计指标使用sqoop导入mysql数据库; (六)使用springboot+vue.js+echarts进行可视化大屏开发; (七)使用协同过滤算法(基于用户/物品)、LSTM、SVD神经网络混合推荐模型、MLP模型等等进行个性化推荐。并进行参数优化、算法二次开发升级; (八)使用卷积神经网络KNN、CNN实现课程流量预测; (九)搭建springboot+vue.js前后端分离web系统进行个性化推荐界面、课程流量预测界面、知识图谱等实现; 四、预期成果 (1)编写系统源代码; (2)毕业设计说明书。 五、设计时间安排 第1周:查阅相关资料,完成文献综述。 第2周:结合课题要求,提交开题报告,并完成开题答辩。 第3~5周:进行系统分析、总体设计和详细设计。 第6~9周:实现系统编码、调试及软件测试;撰写毕业设计。 第10~12周:修改毕业设计至定稿,资格审查。 第13~14周:毕业设计答辩及资料归档。 六、完成设计所需要的条件 (1)软硬件环境:硬件环境有win10笔记本电脑配置有16G内存、256G固态硬盘(用于存储、计算、开发);软件环境有Python、JDK1.8、Hadoop、Spark、Hive、Maven、Vue.js等。 (2)数据库:MySQL数据库 (3)开发环境与工具:Vmvare、IDEA、Pycharm、Navicat 七、参考文献 [1]尹旭熙.基于Hadoop和Spark的可扩展性化工类大数据分析系统设计[J].粘接,2021,46(06):81-83+93. [2]李林国,查君琪,赵超等.基于Hadoop平台的大数据可视化分析实现与应用[J].西安文理学院学报(自然科学版),2022,25(03):53-58. [3]杨志雄.大数据分析的机器学习算法研究[J].信息记录材料,2023,24(05):92-94.DOI:10.16009/j.cnki.cn13-1295/tq.2023.05.003. [4]Ravesa A,Ahmad S S. Precision agriculture using IoT data analytics and machine learning[J]. Journal of King Saud University - Computer and Information Sciences,2022,34(8PB). [5]Bernd S,Desiree K,Antonio G D, et al. Approach for machine learning based design of experiments for occupant simulation[J]. Frontiers in Future Transportation,2022. [6]Kumar A,Sreenatha G A,Dubey K A, et al. Machine Learning Approaches and Applications in Applied Intelligence for Healthcare Data Analytics[M].CRC Press:2021-09-12. [7]陈琦. 面向个性化课程推荐的深度学习方法研究[D].山东师范大学,2021.DOI:10.27280/d.cnki.gsdsu.2021.000635. [8]卜南翔,徐述,王玉婷等.基于大数据平台的课程教学资源推荐系统应用探究[J].数码世界,2019(03):189. [9]方思怡.标准知识图谱的技术路径与应用场景探讨[J].中国标准化,2023(11):49-55. [10]郭芳清. 基于图神经网络的知识图谱推荐算法研究[D].大连理工大学,2022.DOI:10.26991/d.cnki.gdllu.2022.001269. [11]郭婺,郭建,张劲松等.基于Python的网络爬虫的设计与实现[J].信息记录材料,2023,24(04):159-162.DOI:10.16009/j.cnki.cn13-1295/tq.2023.04.025. [12]李明轩,李峰.人工智能时代知识图谱与深度学习的相互交融——评《知识图谱与深度学习》[J].中国科技论文,2023,18(02):240. [13]汪娅.深度学习的认识论意蕴[J].哈尔滨学院学报,2022,43(12):12-16. [14]魏胤真.基于计算机深度学习的个性化资源推荐算法研究[J].现代工业经济和信息化,2023,13(03):56-58.DOI:10.16525/j.cnki.14-1362/n.2023.03.020. [15]韩厚畴. 基于深度学习的混合推荐算法研究[D].吉林大学,2022.DOI:10.27162/d.cnki.gjlin.2022.006503. 指导教师签名: 指导教师手签 2023.1.6-1.13(定稿时删除该说明) 年 月 日 | |||||
课题来源:(1)教师拟订;(2)学生建议;(3)企业和社会征集;(4)科研单位提供
课题类型:(1)A—工程设计(艺术设计);B—技术开发;C—软件工程;D—理论研究;E—调研报告
(2)X—真实课题;Y—模拟课题;Z—虚拟课题
要求(1)、(2)均要填,如AY、BX等。
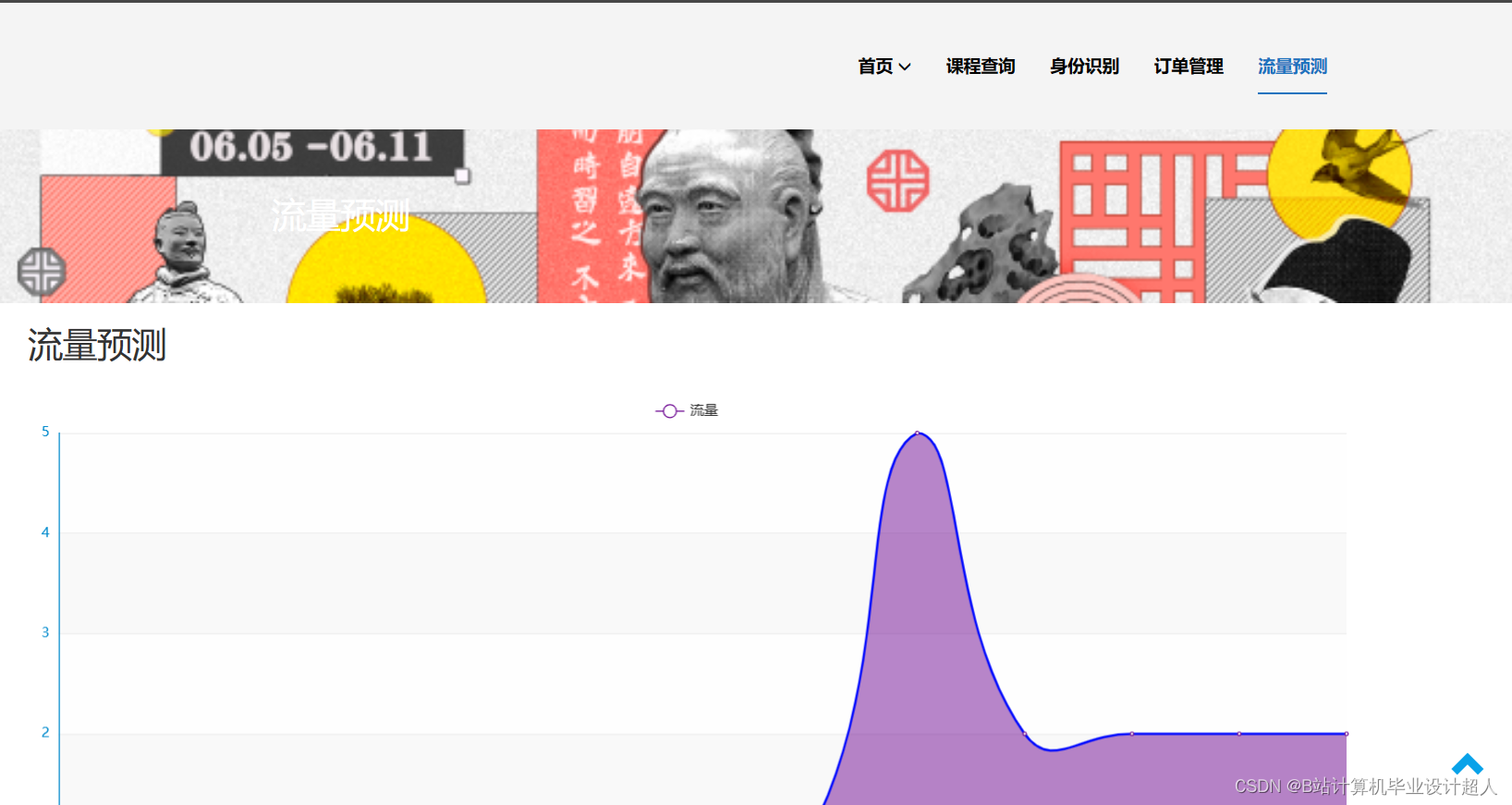
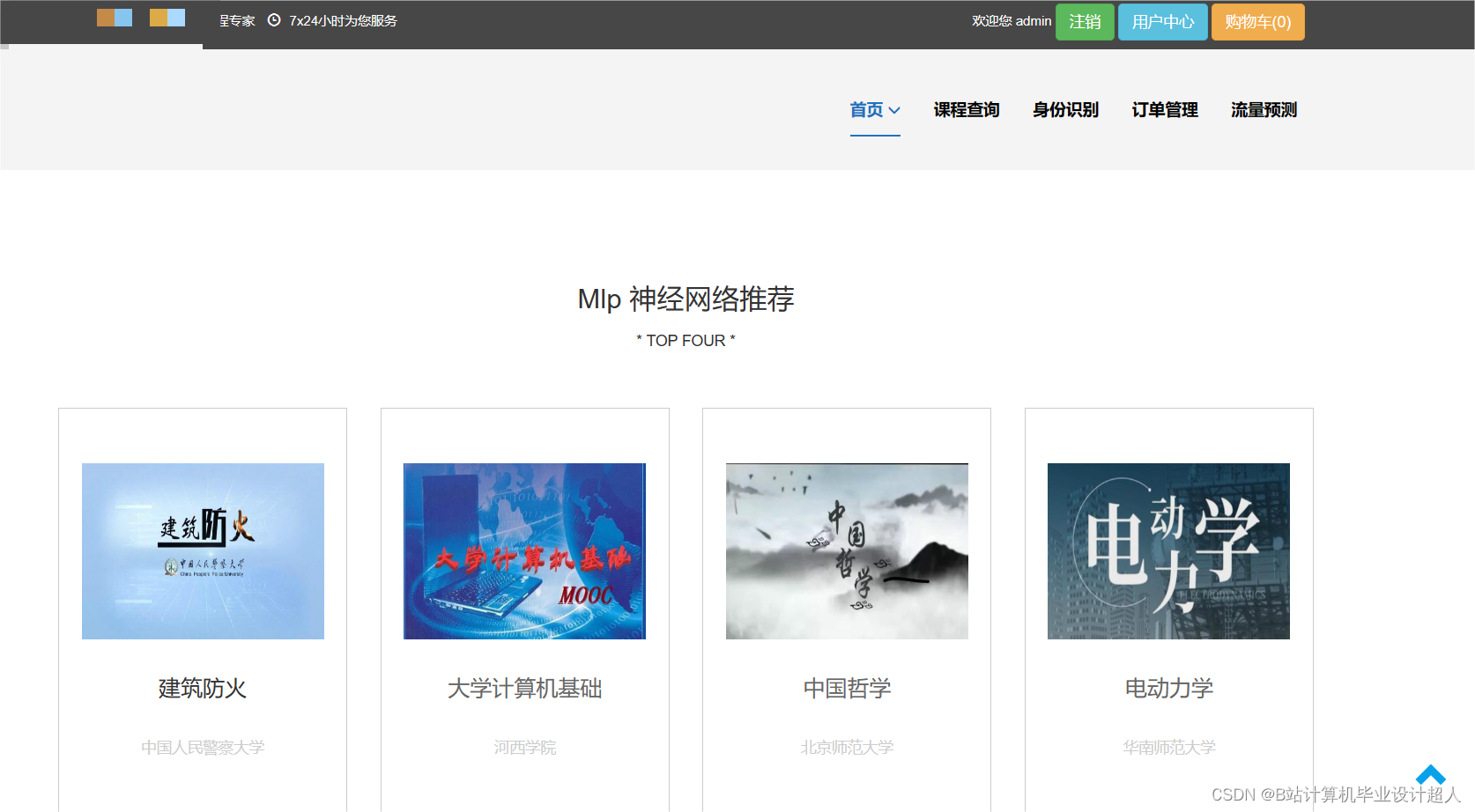
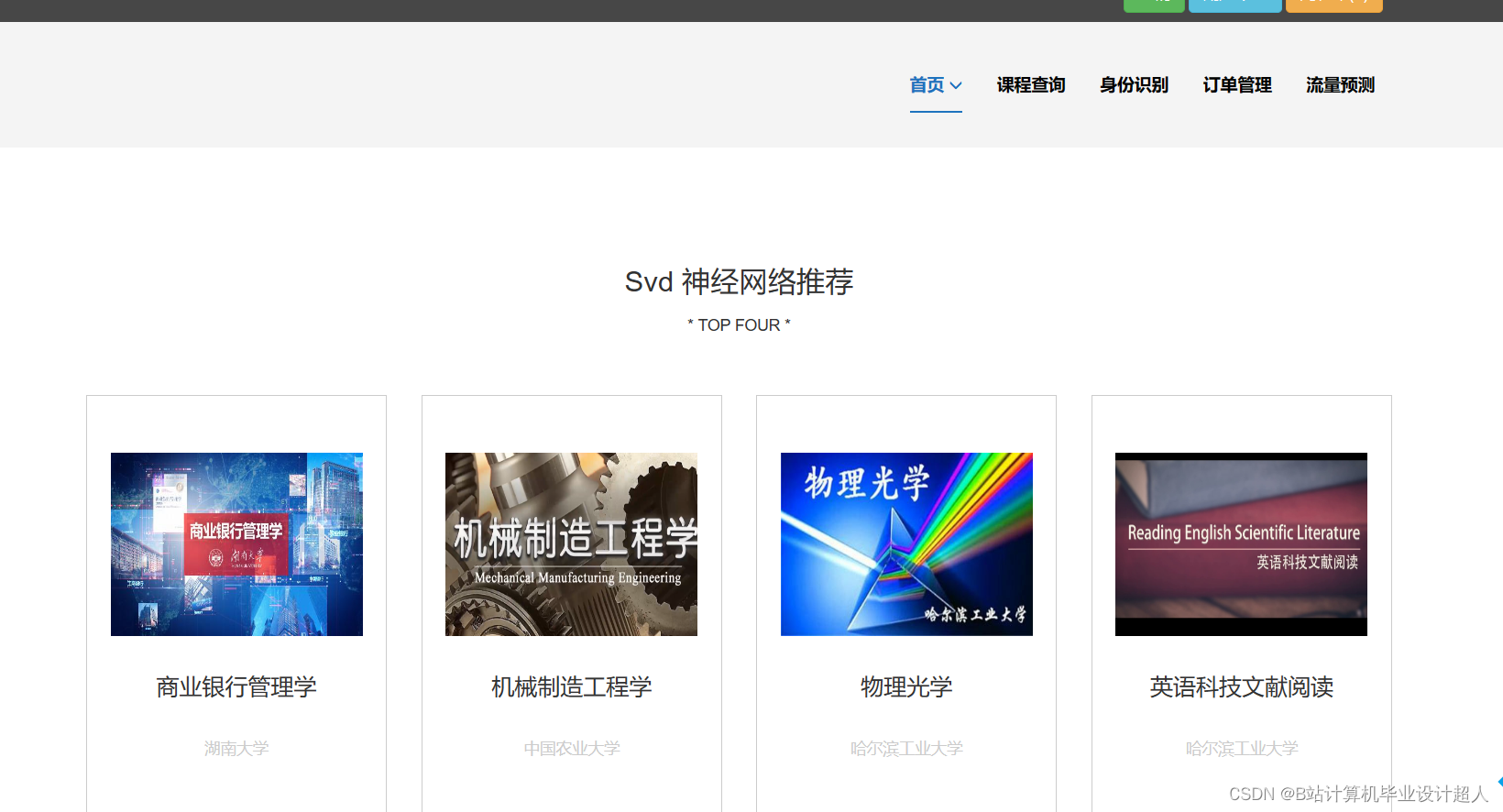
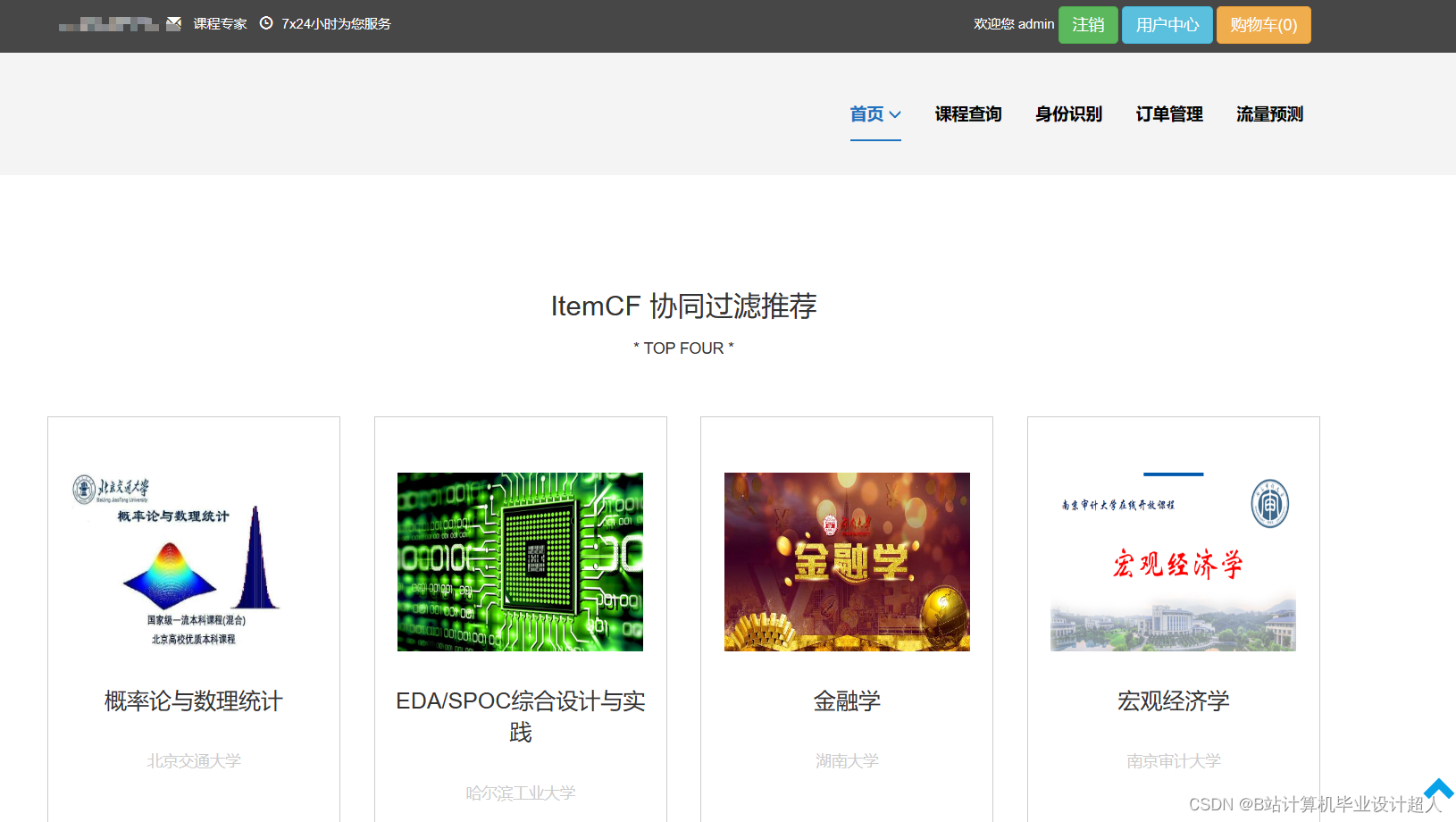
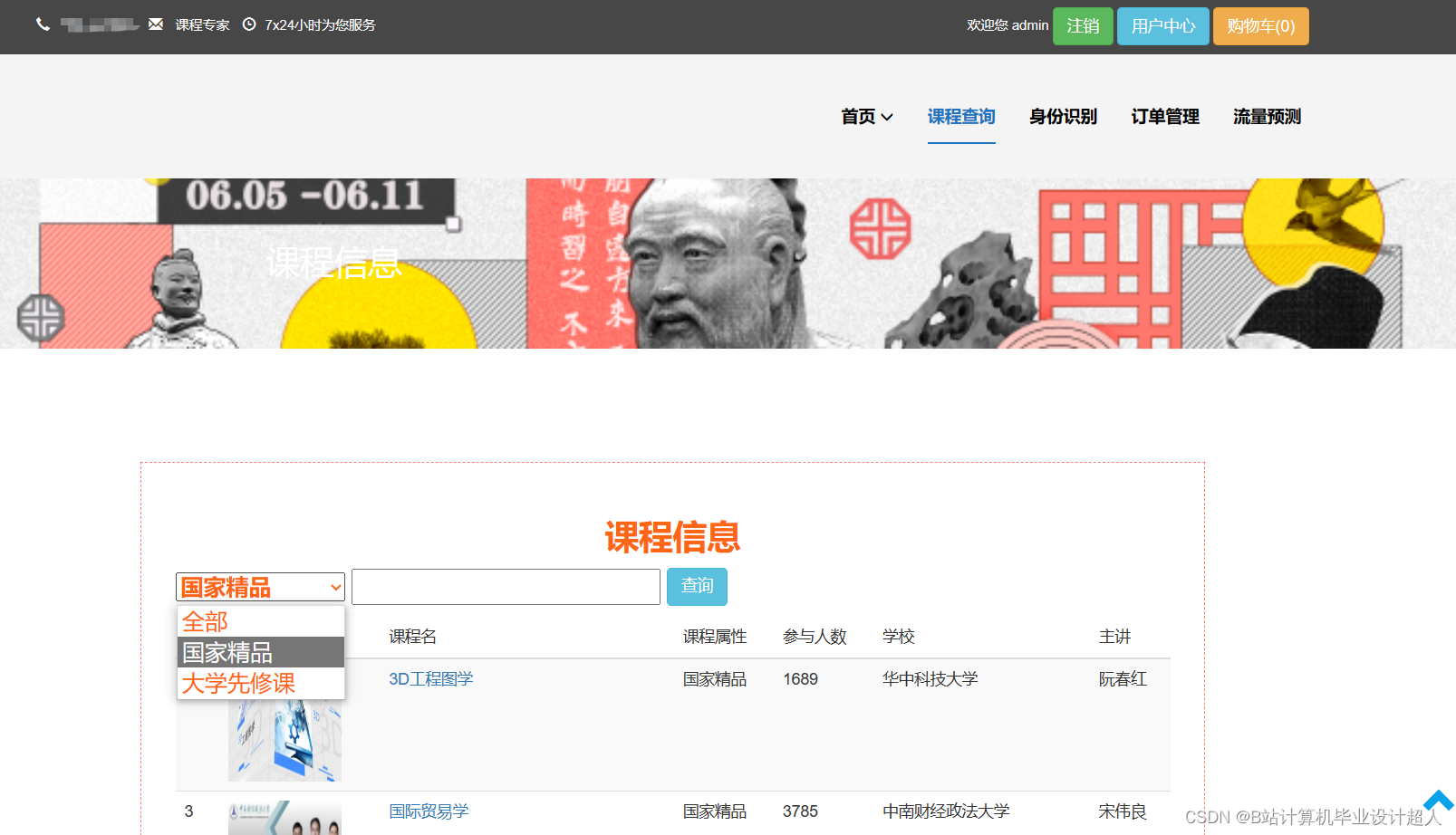
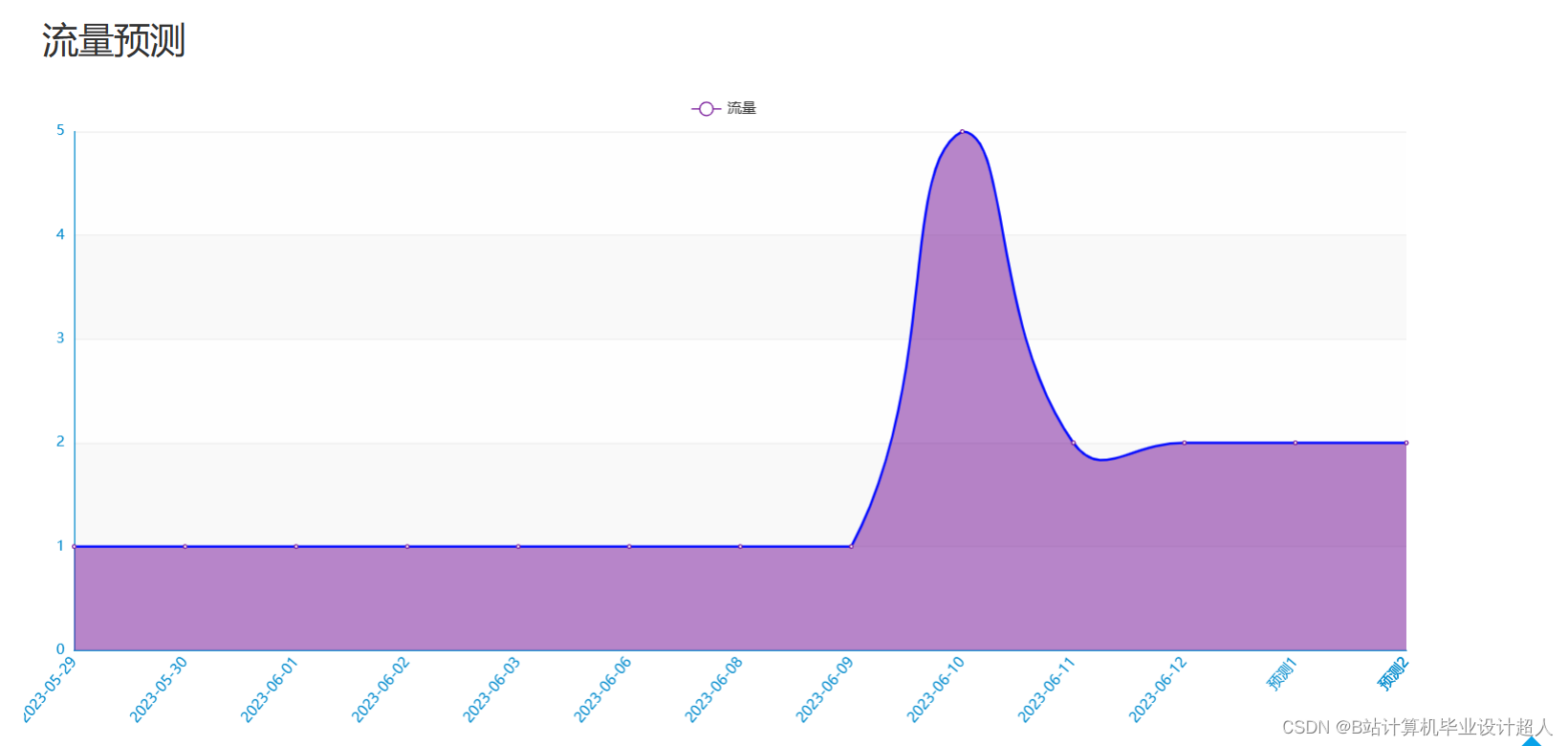

下面是一个简单的使用 TensorFlow 实现的课程推荐算法的示例代码。这个示例实现了一个基于矩阵分解的协同过滤推荐系统:
import numpy as np
import tensorflow as tf
# 假设有5个用户和10门课程
num_users = 5
num_courses = 10
embedding_dim = 5
# 模拟用户和课程的交互数据(用户ID,课程ID,评分)
interactions = np.array([[0, 1, 4.0],
[1, 2, 3.0],
[2, 0, 5.0]])
# 创建用户和课程的嵌入矩阵
user_embedding = tf.Variable(tf.random.normal([num_users, embedding_dim]))
course_embedding = tf.Variable(tf.random.normal([num_courses, embedding_dim]))
# 定义模型
def model(user_ids, course_ids):
user_emb = tf.nn.embedding_lookup(user_embedding, user_ids)
course_emb = tf.nn.embedding_lookup(course_embedding, course_ids)
# 计算用户和课程之间的内积作为预测评分
preds = tf.reduce_sum(user_emb * course_emb, axis=1)
return preds
# 定义损失函数和优化器
def loss_fn(preds, ratings):
loss = tf.reduce_mean(tf.square(preds - ratings))
return loss
optimizer = tf.keras.optimizers.Adam(learning_rate=0.01)
# 将数据划分为用户ID和课程ID两列
user_ids = interactions[:, 0].astype(np.int32)
course_ids = interactions[:, 1].astype(np.int32)
ratings = interactions[:, 2].astype(np.float32)
# 训练模型
for epoch in range(100):
with tf.GradientTape() as tape:
preds = model(user_ids, course_ids)
loss = loss_fn(preds, ratings)
gradients = tape.gradient(loss, [user_embedding, course_embedding])
optimizer.apply_gradients(zip(gradients, [user_embedding, course_embedding]))
print(f'Epoch {epoch+1}, Loss: {loss.numpy()}')
# 使用模型进行推荐
user_id = np.array([0])
course_ids = np.arange(num_courses)
predicted_ratings = model(user_id, course_ids)
print('Predicted ratings for user 0:')
print(predicted_ratings.numpy())
这段代码演示了一个简单的协同过滤推荐系统,使用了用户和课程的嵌入矩阵来学习用户和课程的表示。在训练过程中,模型尝试预测用户与课程之间的交互评分,并通过均方误差损失函数进行优化。最后,使用训练好的模型进行推荐时,可以输入用户ID,得到对所有课程的预测评分。
请注意,这只是一个简单的示例代码,实际的推荐系统可能需要更复杂的模型和数据处理。希望这能帮到你!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











