






黄河科技学院本科毕业设计 任务书
工 学部 大数据与计算机应用 科教中心 计算机科学与技术 专业
2018 级普本1/专升本1班 学号 学生 指导教师
毕业设计题目
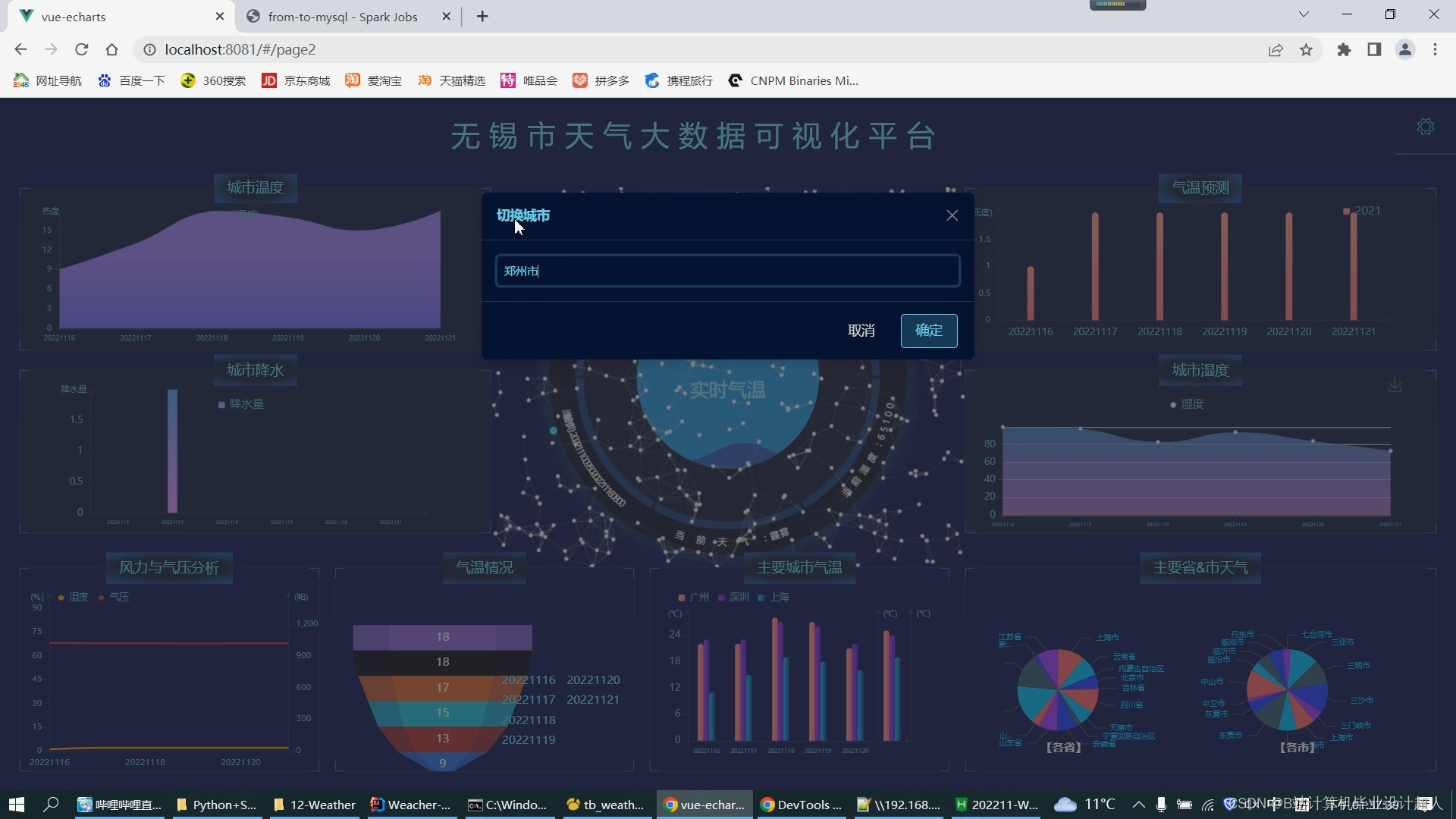
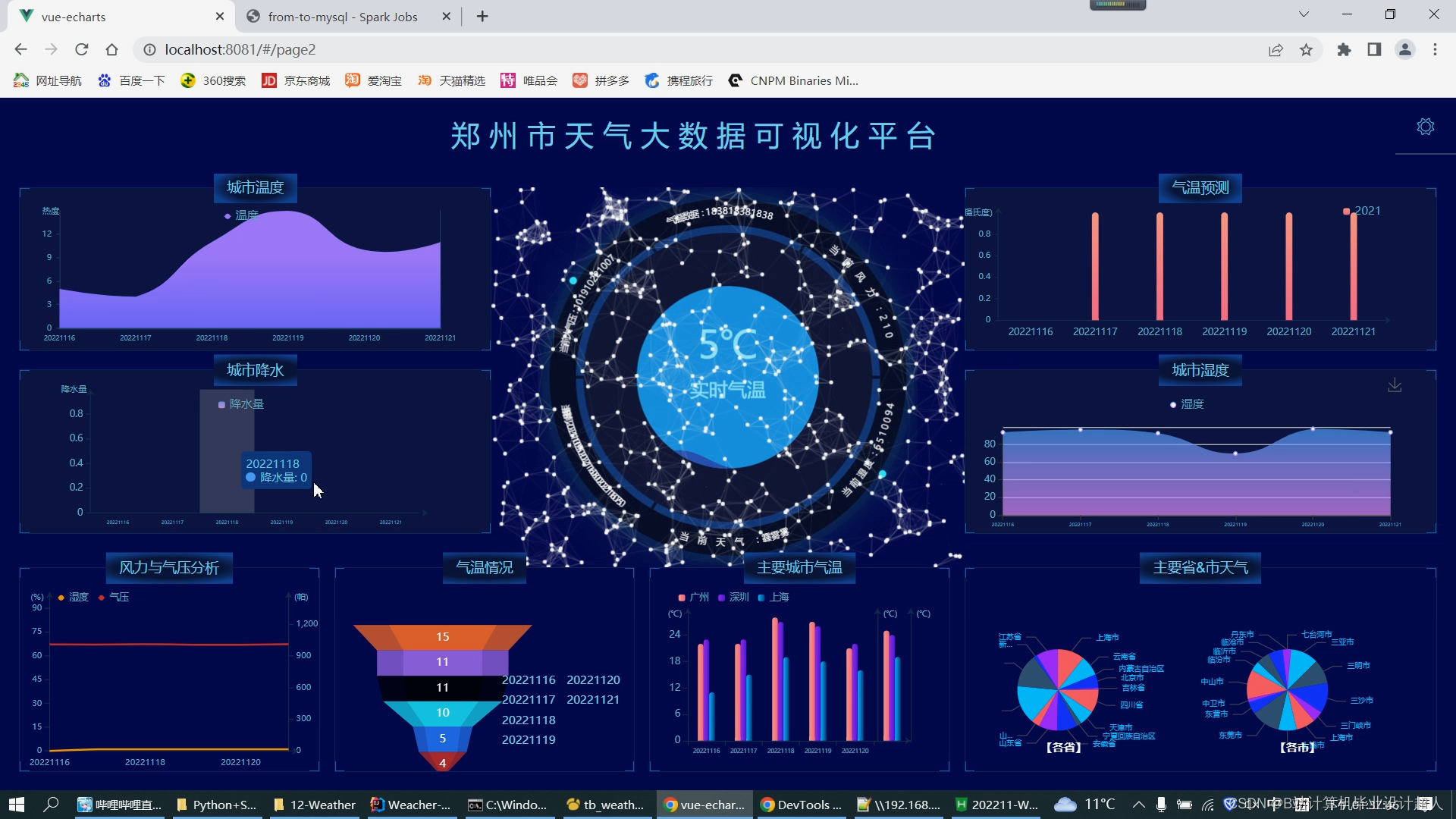
基于大数据的天气预测与数据分析系统的设计与实现
毕业设计工作内容与基本要求(目标、任务、途径、方法,应掌握的原始资料(数据)、参考资料(文献)以及设计技术要求、注意事项等)
一、设计的目标和任务
- 数据采集与处理:天气预测系统需要采集大量的数据,包括气象观测数据、卫星遥感数据、地理信息数据等。同时,需要对这些数据进行清洗、去重、格式转换等处理,以便于后续的分析和预测。
- 机器学习与深度学习算法:基于大数据的天气预测系统需要利用机器学习与深度学习算法对历史数据进行分析,找出其中的规律和特征,并根据这些规律和特征进行预测。常见的算法包括线性回归、决策树、随机森林、神经网络等。
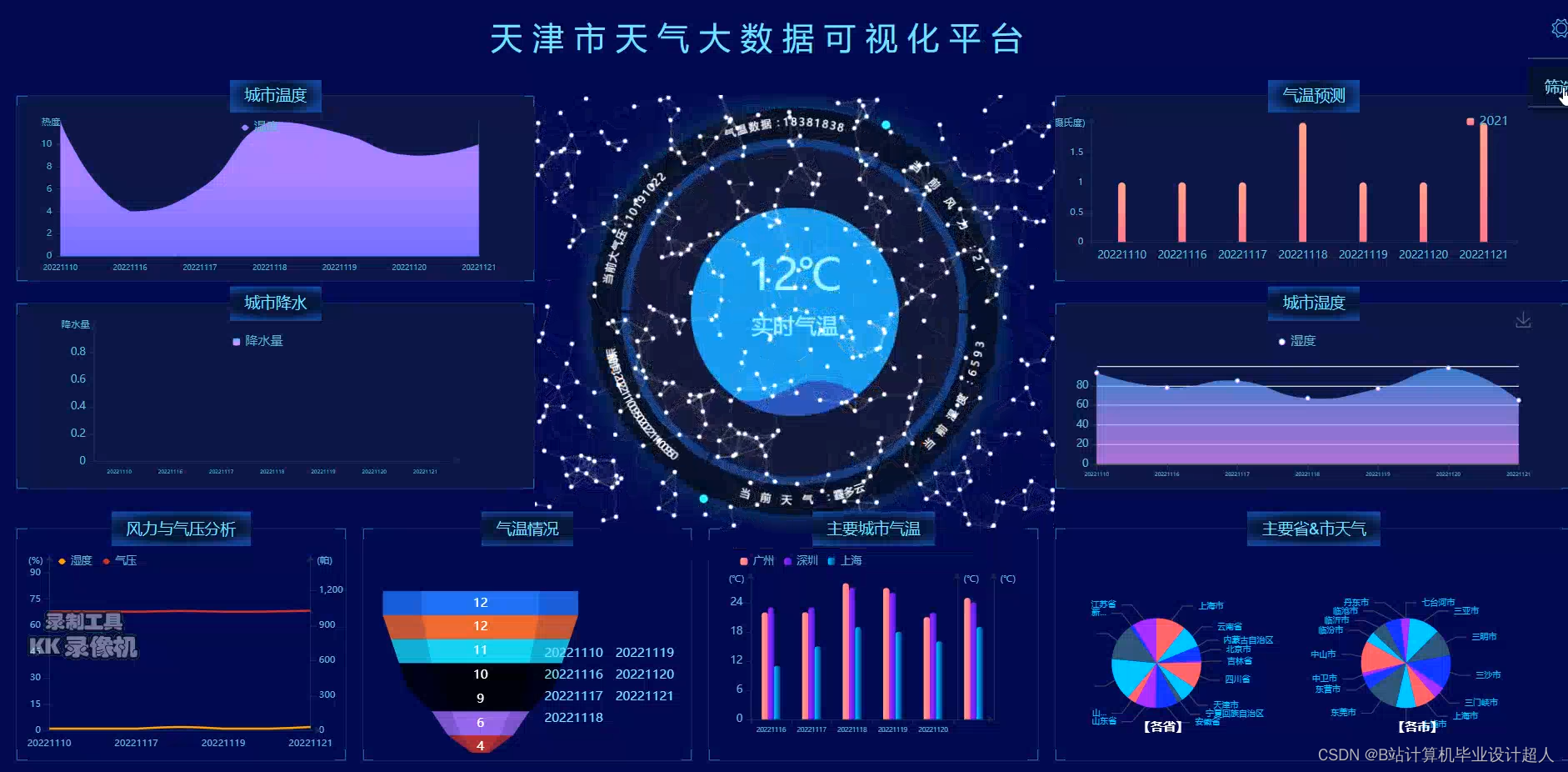
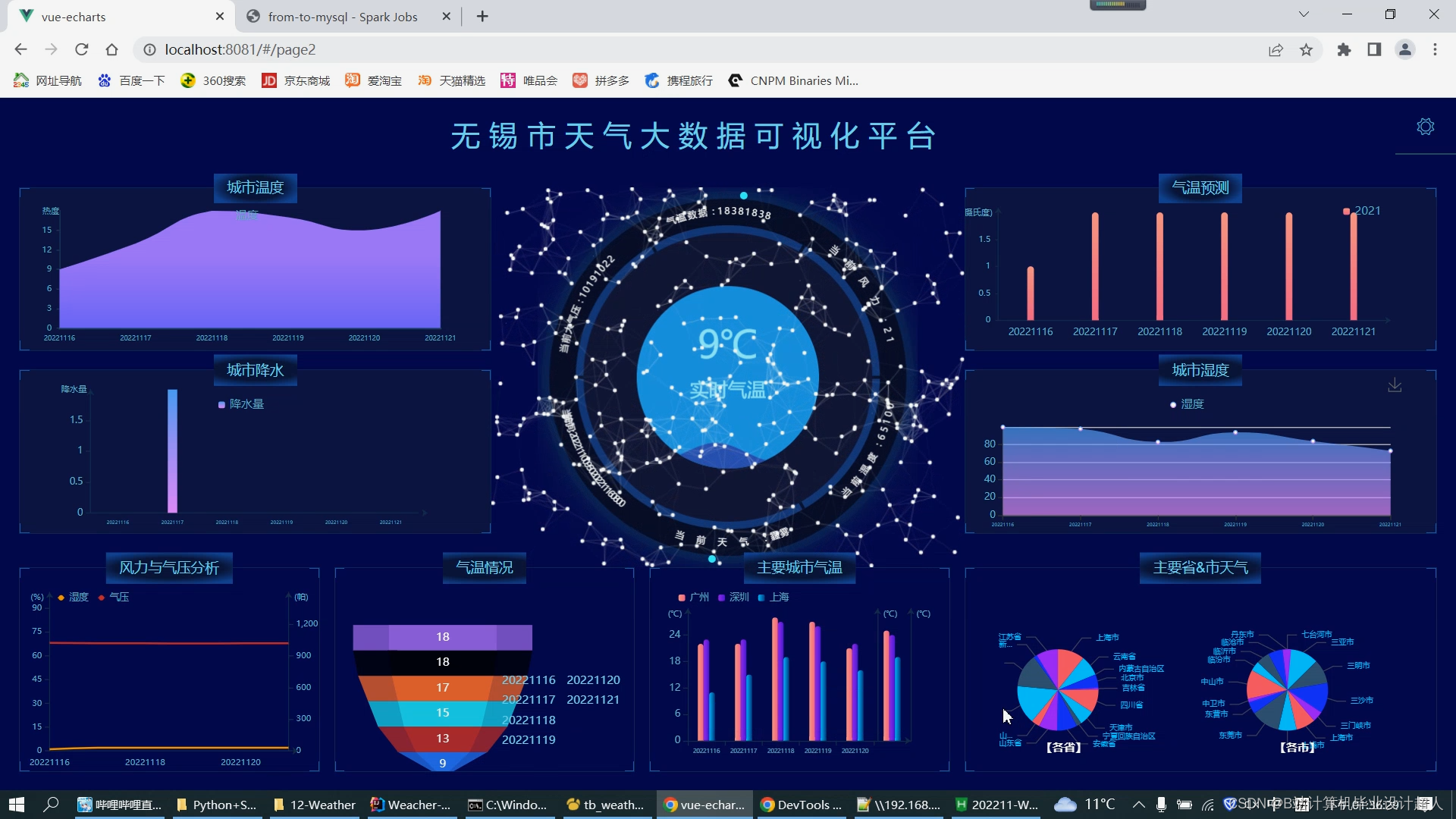
- 数据可视化技术:将预测结果以直观的方式呈现给用户,是天气预测系统的重要功能之一。数据可视化技术可以将数据以图表、图像等形式展示,帮助用户更好地理解预测结果。
二、设计途径和方法
本文首先介绍了天气预测的概念,阐述了天气预测对生产生活的重要影响。接着,从发展历程、特点两个方面对Python进行了分析,并介绍了如何搭建Python开发环境。随后,介绍了网络爬虫的概念,从原理和分类两个方面对网络爬虫进行了研究,在上述基础上,分析了基于Python的网络爬虫技术,设计并实现了基于Python的天气预测系统。所使用的算法可以有效对天气进行预测,为用户的出行天气预警提供有效帮助。
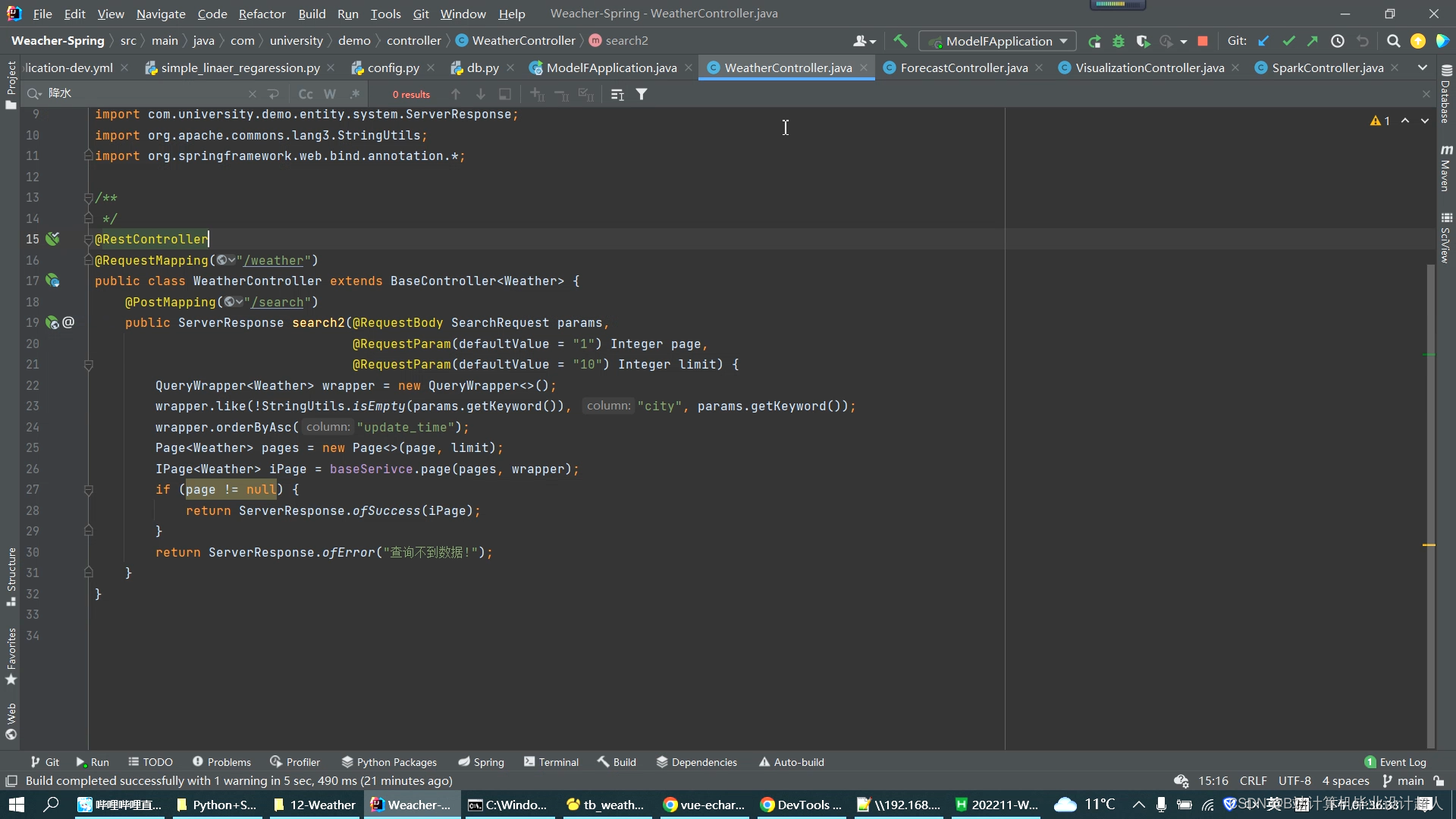
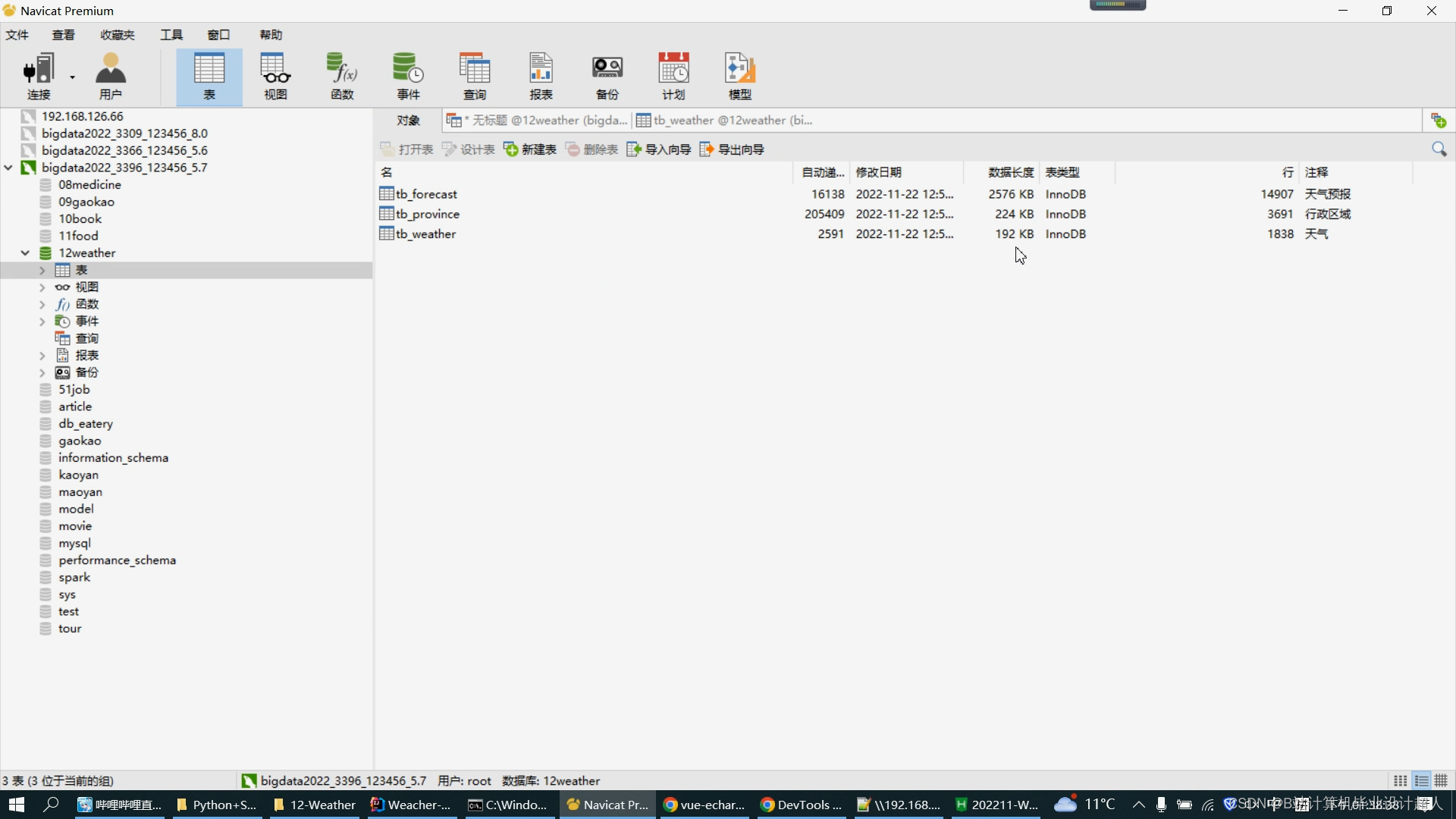
- Python爬虫模块:使用requests爬取腾讯天气的气象数据作为分析数据集存入mysql;
- Spark实时计算模块:集成SparkSQL完成气象数据统计指标的计算提取;
- 数据预测模块:使用Python线性回归预测、机器学习/深度学习模型对气象数据进行分析,并将结果以json的形式推送给前端UI界面;
- 数据可视化模块:使用echarts实现数据可视化大屏;
三、应掌握的原始资料和技术
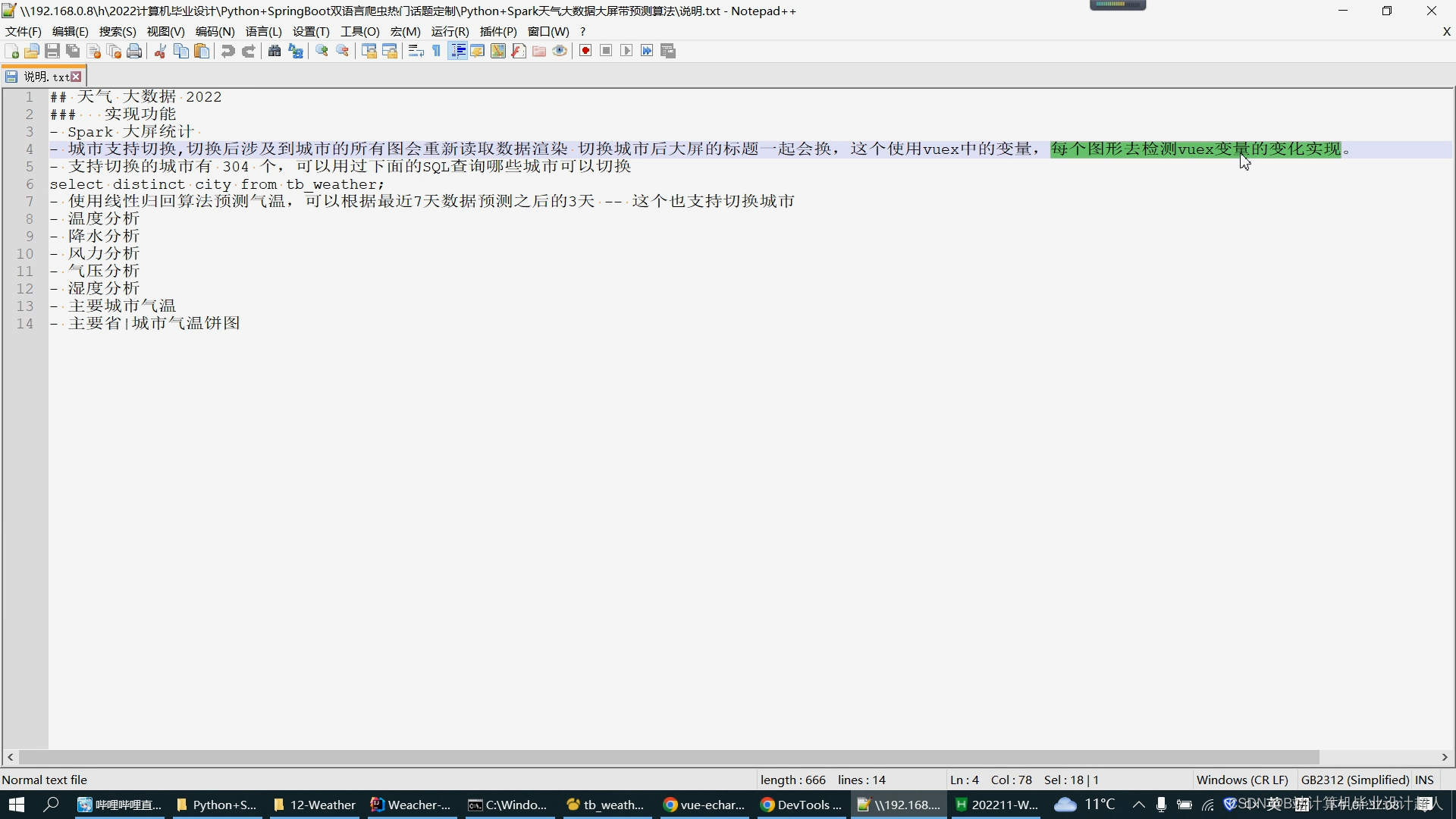
原始资料:腾讯天气接口采集的近10年天气数据
技术:
- 前端技术:vue.js、echarts
- 后端技术:springboot、mybatis
- 数据库技术:mysql
- 大数据技术:hadoop、spark、hive
- 机器学习算法:卷积神经网络、线性回归算法
四、进度安排
第1周:查阅相关资料,完成文献综述。
第2周:结合课题要求,提交开题报告,并完成开题答辩。
第3~5周:进行系统分析、总体设计和详细设计。
第6~9周:实现系统编码、调试及软件测试。撰写毕业设计。
第10~12周:修改毕业设计至定稿,资格审查。
第13~14周:毕业设计答辩及资料归档。
五、参考文献
[1] 华丽,陈澄. 云计算环境下气象大数据服务应用 [J]. 农业与技术,2022,37(20):231+234.
[2] 屈世甲,武福生. 矿井风速数据预处理中Kalman 滤波方法 [J]. 煤矿安全,2023,47(1):116-118+122.
[3] 胡虎,杨侃,朱大伟,等. 基于EEMD-GRNN 的降水量预测分析 [J]. 水电能源科学,2020,35(4):10-14.
[4] 黄春艳,韩志伟,畅建霞,等. 基于EEMD 和GRNN 的降水量序列预测研究 [J]. 人民黄河,2021,39(5):26-28.
[5] 邢彩盈,张京红,黄海静. 基于BP 神经网络的海口住宅室内气温预测 [J]. 贵州气象,2022,40(5):38-42.
[6] 张晓伟,关东海,莫淑红. 和田绿洲气温与相对湿度的GM(1,1)预测模型 [J]. 中国农业气象,2020(1):31-33.
[7] 马楚焱,祖建,付清盼,等. 基于遗传神经网络模型的空气能见度预测 [J]. 环境工程学报,2021,9(4):1905-1910.
[8] 陈烨,高亚静,张建成. 基于离散Hopfield 模式识别样本的GRNN 非线性组合短期风速预测模型 [J]. 电力自动化设备,2022,35(8):131-136.
[9] 张鑫宇,宋瑾钰.LBS 系统研究现状综述 [J]. 工业控制计算机,2023,29(4):101-102+112.
[10] 钱海钢.Beacon 技术构建图书馆LBS 服务的分析 [J]. 农业图书情报学刊,2022,30(5):45-49.
[11] 肖锋,侯岳,王留召,等. 基于LBS 的智能信息推送技术研究 [J]. 测绘与空间地理信息,2021,38(6):125-127.
[12] 刘辉,郭梦梦,潘伟强. 个性化推荐系统综述 [J]. 常州大学学报(自然科学版),2021,29(3):51-59.
[13] 李社宏. 大数据时代气象数据分析应用的新趋势 [J]. 陕西气象,2022(2):41-44.
[14] 黄立威,江碧涛,吕守业,等. 基于深度学习的推荐系统研究综述 [J]. 计算机学报,2023,41(7):1619-1647.
[15] Zhao Junqing and Tie Pengfei. Design and Implementation of Energy-Saving Logistics Management System for Route Optimization[J].Wireless Communications and Mobile Computing, 2022.
[16] Qi liang SUN. Design and Implementation of Personnel Management Information System Based on SSM[C].2021.
六、注意事项
(1)对于开发过程中遇到的问题注重自己查阅资料寻找解决方案,同时,多和导师沟通交流解决。
(2)寻找同类系统进行对比学习和参考,提高开发效率。

当然可以!下面是一个使用Spark ML库进行天气预测的简单示例代码:
# 导入必要的库
from pyspark.ml import Pipeline
from pyspark.ml.feature import VectorAssembler
from pyspark.ml.regression import RandomForestRegressor
# 加载数据
data = spark.read.format("csv").option("header", "true").load("weather_data.csv")
# 数据预处理
assembler = VectorAssembler(inputCols=["temperature", "humidity"], outputCol="features")
data = assembler.transform(data)
# 划分数据集为训练集和测试集
(trainingData, testData) = data.randomSplit([0.7, 0.3])
# 创建随机森林回归模型
rf = RandomForestRegressor(featuresCol="features", labelCol="label")
# 构建管道
pipeline = Pipeline(stages=[rf])
# 训练模型
model = pipeline.fit(trainingData)
# 进行预测
predictions = model.transform(testData)
# 显示预测结果
predictions.select("features", "label", "prediction").show()
在这个例子中,我们假设有一个包含温度和湿度特征的天气数据集,并且我们想要预测天气的标签(比如降雨量)。首先,我们加载数据,并使用VectorAssembler将温度和湿度特征合并成一个特征向量。然后,我们随机将数据集划分为训练集和测试集。
接下来,我们创建了一个随机森林回归模型,并将其作为一个阶段添加到管道中。我们使用训练集对模型进行训练,并使用测试集进行预测。最后,我们显示了预测结果,包括特征向量、实际标签和预测值。
请注意,这只是一个简单的示例代码,实际的天气预测算法可能需要更多的特征工程和参数调整来提高准确性。
















 9795
9795











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











