







毕业设计
开题报告
| 题 目: | 基于Hadoop的飞机航班预测系统设计与实现 |
| 院 系: | 大数据与人工智能学院 |
| 专 业: | 数据科学与大数据技术 |
| 班 级: | 数科201班 |
| 学 号: | 202001074140 |
| 学生姓名: | 张健 |
| 指导教师: | 马义想 |
郑州经贸学院毕业设计、开题报告
| 题 目 | 基于Hadoop+Hive的机票价格预测分析与可视化 | ||||||
| 姓名 | 张健 | 院系 | 大数据与人工智能学院 | 专业班级 | 数科201 | 学号 | 202001074140 |
| 1.选题背景和意义 (1)选题背景 在旅行规划中,机票价格一直是旅客关注的重点。机票价格的波动不仅受季节、航线、航空公司等因素的影响,还受到市场供求关系、经济形势等因素的影响。因此,通过对机票价格进行预测分析,可以帮助旅客选择更合适的出行时间和机票购买策略,从而节省旅行成本。 (2)意义 提高乘客购票决策:基于Hadoop的飞机票价格预测能够提供乘客准确的价格预测信息,帮助他们选择合适的购票时间和最优的价格,从而节省成本。 改善航空公司运营管理:航空公司可以准确预测票价趋势和需求变化,从而制定更具竞争力和市场响应性的票价策略。这有助于提高运营效率、增加收益和优化航线安排。 实现可持续发展:航空业是全球排放最高的行业之一。通过预测飞机票价格,并能够更好地安排航班和座位利用率,航空公司可以减少空座位和航班的浪费,从而降低碳排放和资源浪费,实现可持续发展。 推动大数据技术应用:基于Hadoop+Hive的机票价格预测分析与可视化,可以推动大数据技术在航空业的应用和发展。这对于促进航空公司数字化转型,提升数据分析和预测能力具有重要意义。 通过基于Hadoop+Hive的机票价格预测分析与可视化,可以为乘客提供更好的购票体验,为航空公司提供决策支持,促进航空业的可持续发展,并推动大数据技术在航空业的应用。 | |||||||
| 2.本选题在国内外的研究状况及发展趋势 (1)国内外的发展状况 在国内,随着大数据技术的逐渐普及和应用,基于Hadoop+Hive的机票价格预测分析与可视化的研究日益受到重视。一些研究者通过收集和处理大规模的机票价格数据,利用Hadoop+Hive进行机票价格分析和预测。例如,可以通过Hive进行机票价格数据的清洗、聚合和转换,再利用Hadoop进行机票价格模型的建立和预测。同时,也有研究者将预测结果进行可视化展示,使用图表、地图等方式呈现机票价格的变化趋势和规律。 在国外,基于Hadoop+Hive的机票价格预测分析与可视化的研究也取得了一定的进展。一些研究机构和航空公司利用大数据技术进行机票价格分析和预测,并取得了一些重要的研究成果。例如,他们通过收集和处理全球范围内的机票价格数据,利用Hadoop+Hive进行机票价格模型的建立和预测分析。同时,也在可视化方面进行了一些探索,将预测结果以图表、地图等形式展示。 (2)发展趋势 未来,基于Hadoop+Hive的机票价格预测分析与可视化的研究将继续发展。随着大数据技术的不断演进和应用,机票价格数据的规模和复杂性将进一步增加,需要更加强大和高效的数据处理和分析能力。因此,研究者将继续深化对Hadoop+Hive的应用,探索更加有效的机票价格分析和预测方法。同时,也将更加注重可视化技术的应用,提供更直观和易于理解的预测结果展示方式。 (3)参考文献 [1]卢敏,贾玉璇.基于多任务学习的机票价格预测模型[J].计算机工程与设计,2023 [2]王双,徐瑶,韩建云等.基于机器学习算法的机票价格预测研究[J].民航学报,2022. [3]姚悦.基于多预测模型的机票价格预测[D].东南大学,2021. [4]单文煜,吴垠,陈鹏.基于机器学习的机票价格预测研究[J].现代计算机,2020. [5]王楠,张显,李冬梅.基于大数据机器学习的航班价格预测研究[J].黑龙江大学自然科学学报,2019. [6]郭才森.近十年国内机票价格市场化改革进程分析与展望[J].民航管理,2021,(04):57-62. [7]陈建蓉.基于统计分析的航空货运价格预测[D].电子科技大学,2020. [8]鞠铁鑫.基于统计分析的航班价格变化差异性问题研究[D].黑龙江大学,2018. [9]Huang T ,Chen C ,Schwartz Z .Do I book at exactly the right time? Airfare forecast accuracy across three price-prediction platforms[J].Journal of Revenue and Pricing Management,2019,18(4):281-290. [10]Huang F ,Huang H .Event ticket price prediction with deep neural network on spatial-temporal sparse data[C]//[出版者不详],2020: | |||||||
| 3.主要设计内容 本项目主要包括以下几个部分: 数据收集和清洗: 从各个航空公司和第三方机票平台收集大规模的机票价格数据,包括航班信息、日期、价格等。对收集到的数据进行清洗,处理缺失值、异常值和重复值等,确保数据的准确性和完整性。 数据存储和管理: 利用Hadoop的分布式文件系统(HDFS)存储机票价格数据,并使用Hive进行数据管理和查询。将机票价格数据通过Hive表的方式进行组织和存储,方便后续的数据分析和预测。 数据分析和建模: 使用Hive进行数据分析,通过SQL语言对机票价格数据进行聚合、统计和计算,提取有用的特征。基于机票价格的历史数据,可以使用统计模型、时间序列模型或机器学习算法构建机票价格预测模型。选择合适的预测模型,根据历史数据进行训练和验证,得到预测模型的参数和准确度指标。 价格预测和可视化: 利用构建好的机票价格预测模型对未来时间段的机票价格进行预测。根据预测结果,可以将机票价格的变化趋势以可视化的方式进行展示,例如折线图、柱状图、地图等。通过可视化图表,使预测结果更加直观和易于理解,帮助旅客了解机票价格的变化规律,做出更好的出行决策。 用户界面设计:通过echarts等方式,将预测结果以图表、列表等形式直观地展现给用户,方便用户了解和比较不同的飞机票价格。 | |||||||
| 4.基本设计思路及技术关键点 (1)基本设计思路 将大数据处理,充分利用Hadoop和hive的分布式计算和存储能力,首先,收集并整理历史机票价格数据;然后,基于这些数据,构建预测模型;最后,利用已训练的模型对未来机票价格进行预测和分析,然后通过echarts生成可视化大屏。这些步骤可以帮助航空业务决策者预测未来的机票价格趋势,从而做出合理的定价和市场策略。
Hadoop通过分布式文件系统HDFS和分布式计算框架MapReduce,实现了大规模数据的存储和处理。通过合理的数据切分和分布式计算,可以充分利用集群中的计算资源,提高数据处理的效率和吞吐量。他采用数据冗余和容错机制,保证数据的可靠性和冗余备份。数据被切分成多个块,并存储在集群中的多个节点上,一旦某个节点出现故障,仍然可以通过其他副本进行数据的访问和计算。他的核心编程模型是MapReduce,它将数据处理任务分解为Map和Reduce两个阶段。开发人员可以通过编写Map和Reduce函数,实现数据的分析、处理和计算。此外,Hadoop还支持更高级的编程接口如Spark、Hive和Pig等,提供更丰富的数据处理能力和编程模型。 DrissionPage提供了简洁友好的API和丰富的文档,使得开发者可以快速上手并构建自己的爬虫程序。内置了自动化处理的功能,如动态加载、表单提交、验证码识别等,可以处理各种复杂的网页操作,省去了手动模拟的麻烦。支持多线程爬取,可以同时处理多个页面,提高爬取效率。支持将爬取的数据保存到各种格式的文件中,如CSV、Excel、数据库等,方便后续的数据分析和处理。提供了完善的日志记录和错误处理机制,便于定位和解决爬取过程中的问题。 使用Flask框架创建Web应用程序,搭建后端服务器,处理前端请求和逻辑处理。Flask提供了路由、模板引擎、HTTP请求处理等功能,可以处理前端与后端的交互。选择合适的Echarts图表类型和外观样式,根据设计需求和数据特点进行配置。利用Echarts提供的丰富的配置选项,对图表进行个性化定制,包括图表的主题、颜色、动画效果等。 PyFlink能够处理无界流式数据,将数据以连续、实时的方式进行处理和分析。它支持事件时间和处理时间两种处理方式,并具备窗口、水印等功能,可以实现对流数据的实时处理和聚合。PyFlink借助Apache Flink的分布式计算引擎,能够在大规模集群上进行并行计算和处理。通过将作业划分为多个任务,并利用网络通信进行数据交换和计算,实现高效的分布式计算。PyFlink提供了灵活的状态管理机制,可以对流式数据进行状态的存储和更新。PyFlink采用事件驱动的编程模型,开发者可以通过定义事件处理函数和操作符来处理输入的事件流。这样的模型能够快速响应事件的到达,并进行实时的处理和计算。
| |||||||
能够准确预测飞机票价格、生成可视化页面,满足用户的需求。具体的预期成果包括 1.高性能的数据处理:利用Hadoop+Hive的分布式计算框架和数据存储技术,预期成果应具有高性能的数据处理能力,能够处理和分析大规模的机票价格数据,提供快速高效的预测和可视化结果。 2.准确的预测结果:通过使用Hadoop+Hive的大数据处理和分析能力,预期成果将提供准确的机票价格预测结果。这将帮助用户在选择出行时间和购买机票时更加明智和高效,从而节省旅行成本。 3.可视化展示:利用可视化技术将机票价格的预测结果以直观的图表、地图等形式展示给用户,使用户更好地理解机票价格的变化趋势和规律,帮助他们选择合适的出行时间和机票购买策略。 | |||||||
| 6.指导教师意见及建议 签字: 2023年11 月 30日 | |||||||

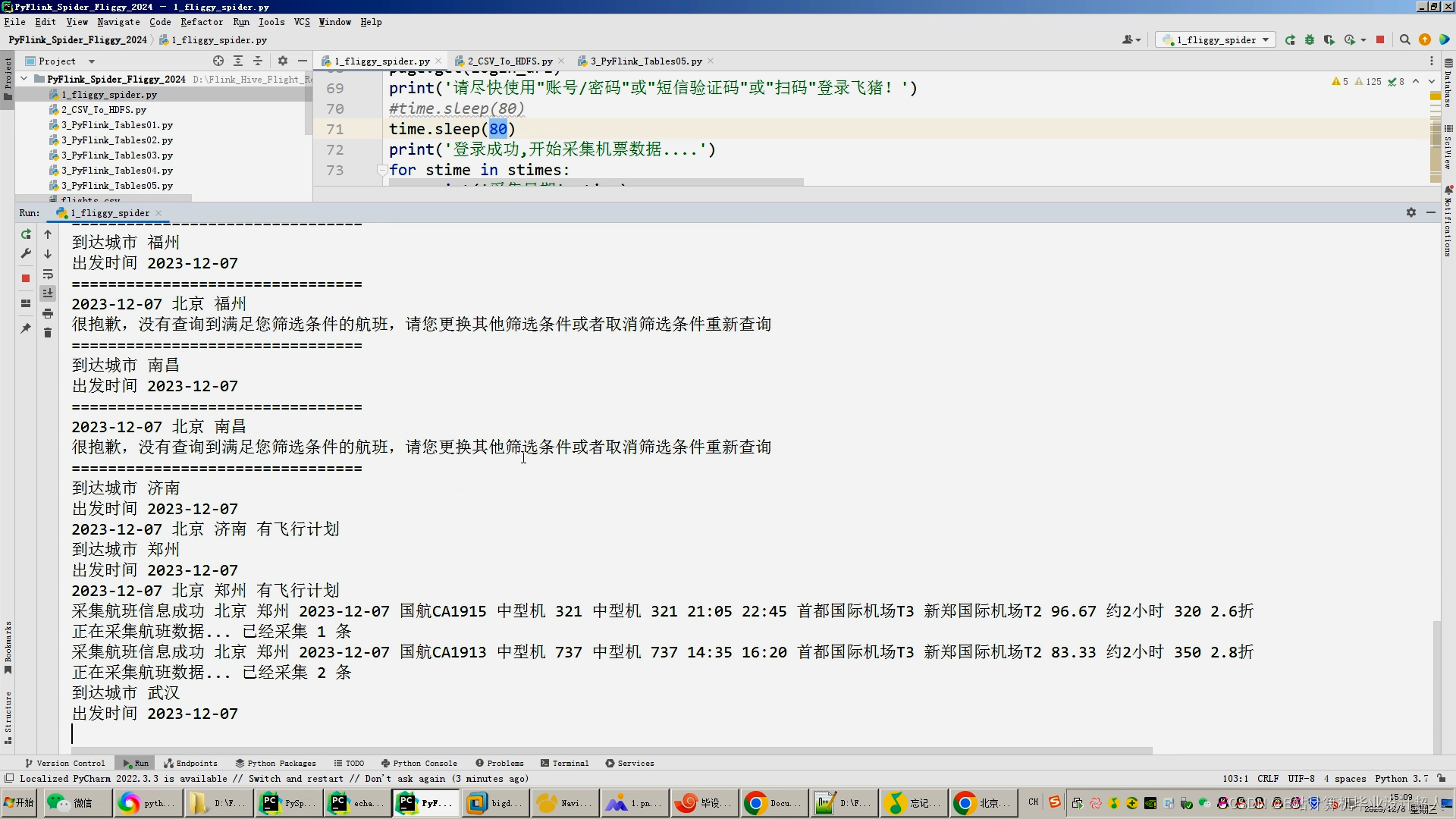
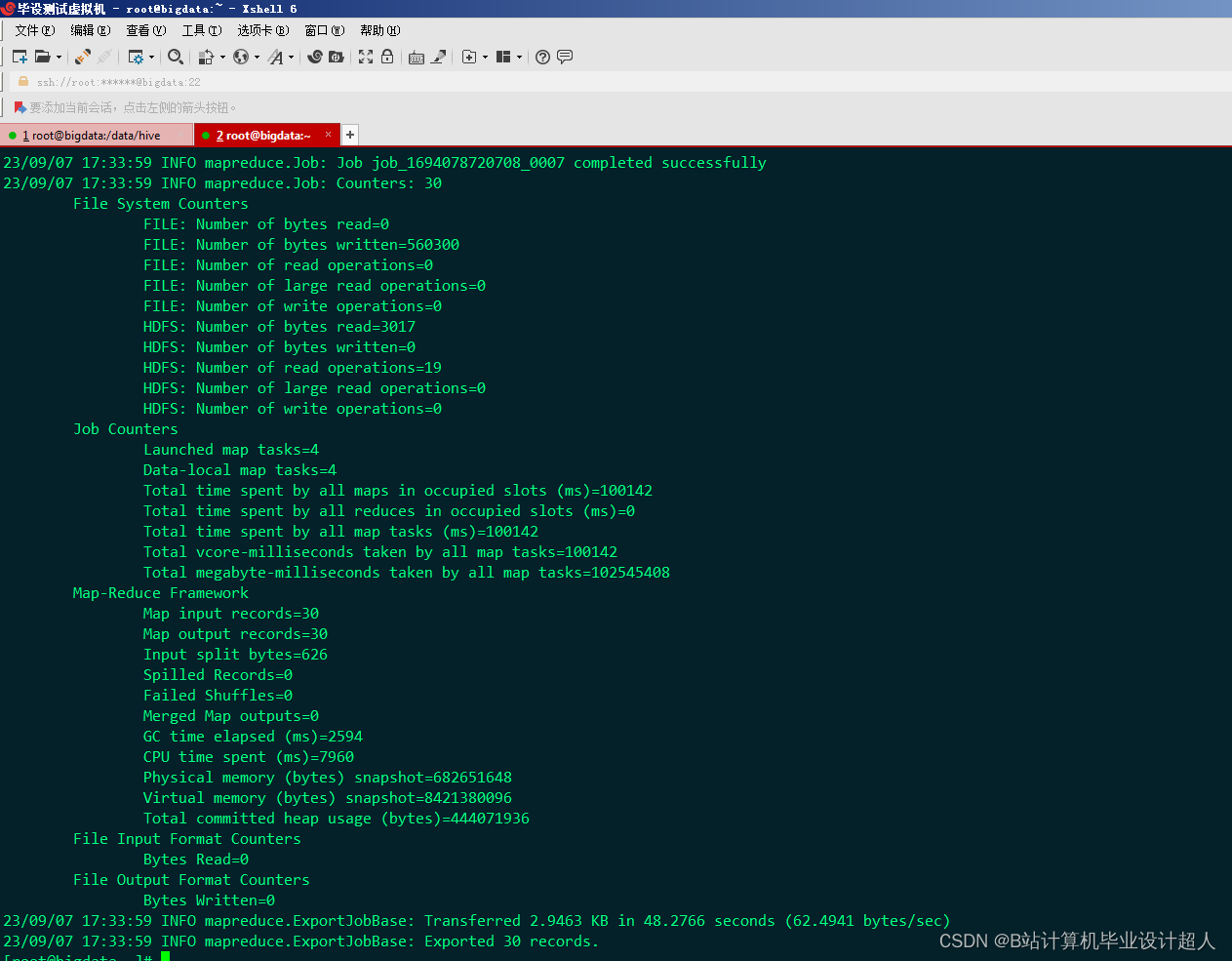

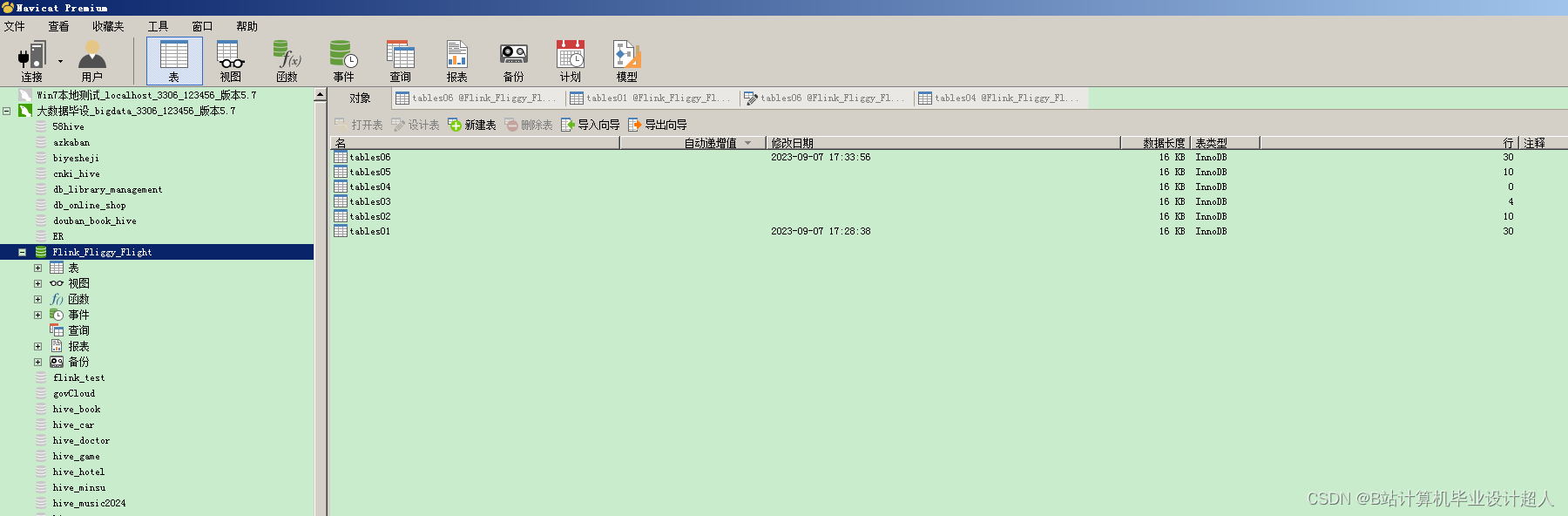
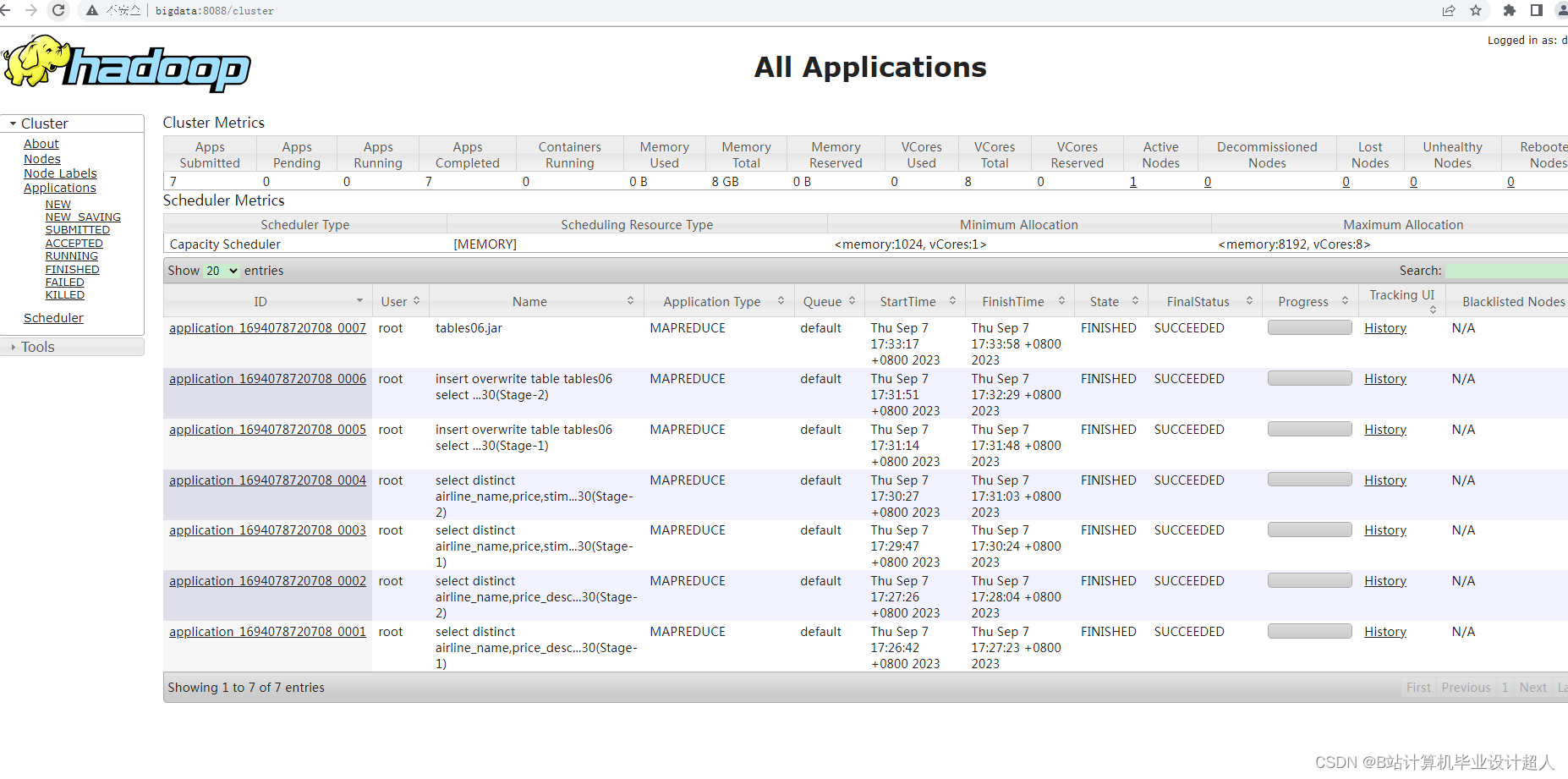
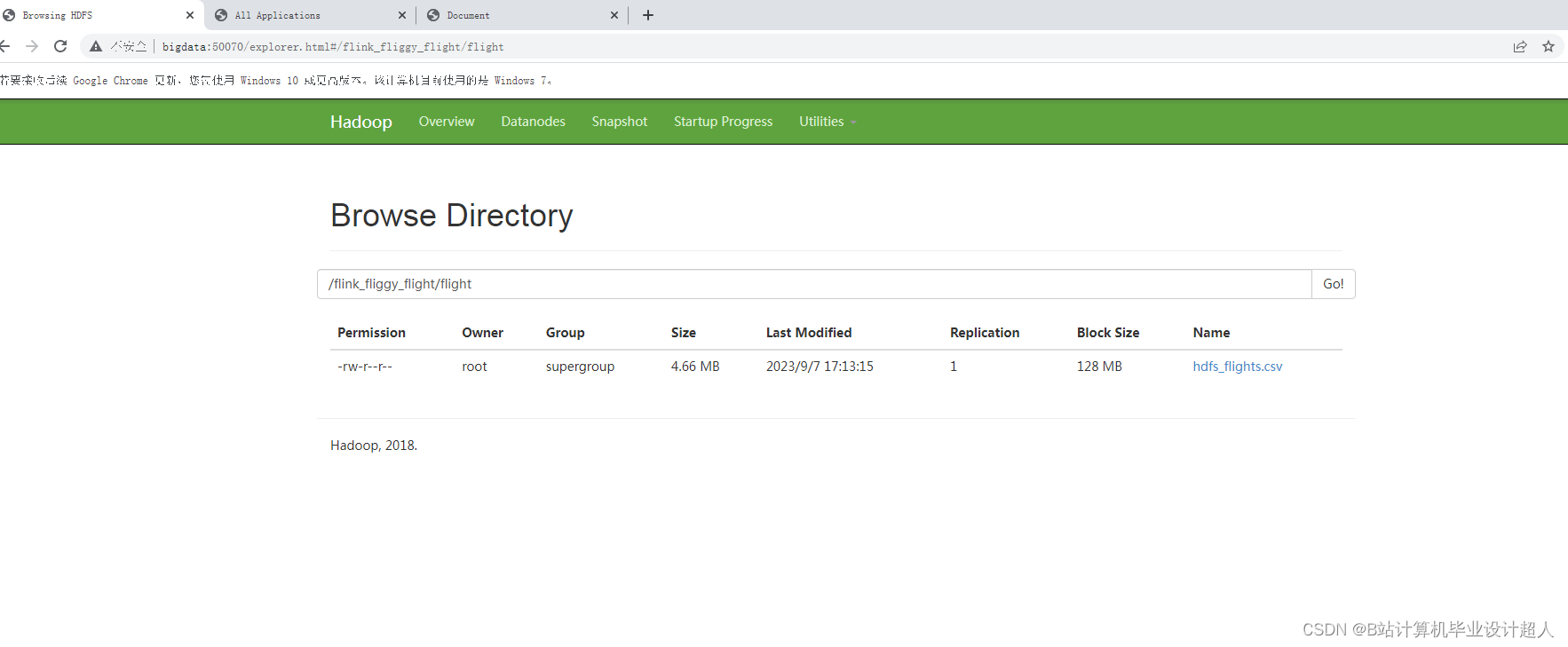
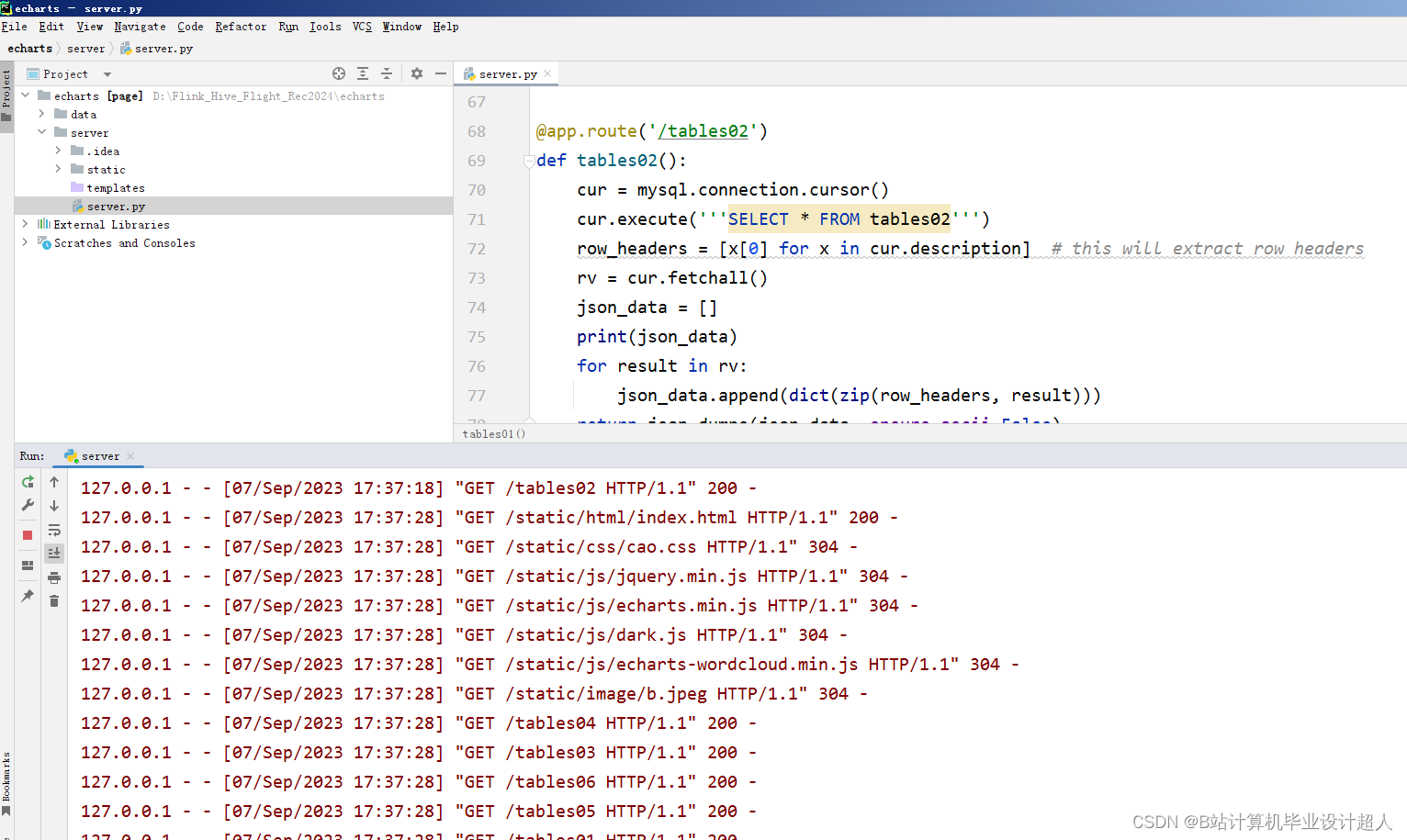
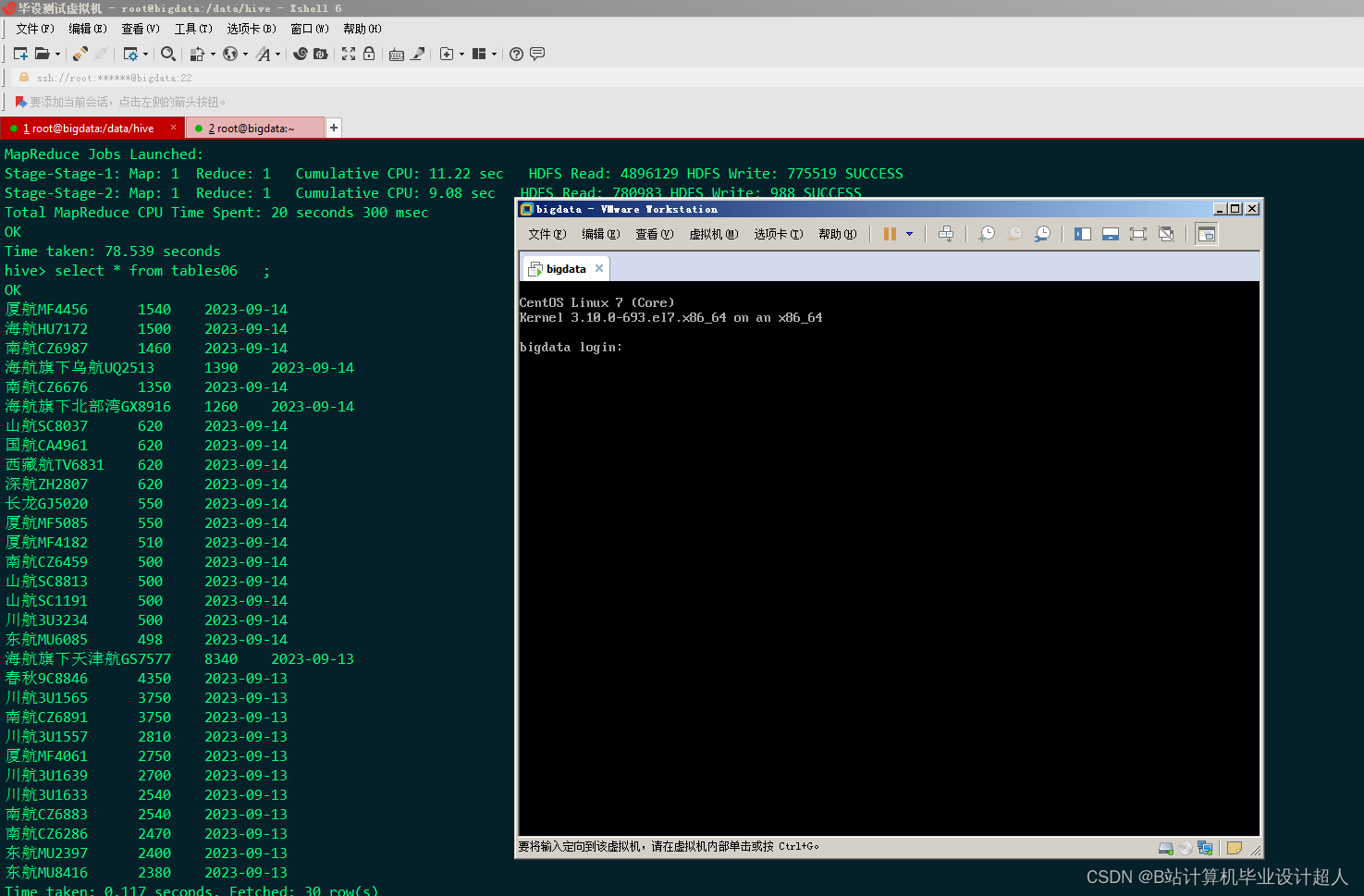
核心算法分下代码如下,您可以采用我的方案开发:
#Flink连接HDFS上面的CSV文件 使用Flink_SQL分析完入表
## 启动hadoop
## cd /data/hadoop/sbin
## sh /data/hadoop/sbin/start-all.sh
## 启动hive
## cd /data/hive
## nohup hive --service metastore &
## nohup hive --service hiveserver2 &
import os
from pyflink.common import Row
from pyflink.table import (EnvironmentSettings, TableEnvironment, TableDescriptor, Schema,
DataTypes, FormatDescriptor)
from pyflink.table.expressions import lit, col
from pyflink.table.udf import udtf
import logging
import sys
logging.basicConfig(stream=sys.stdout, level=logging.INFO, format="%(message)s")
env_settings = EnvironmentSettings.in_streaming_mode()
table_env = TableEnvironment.create(env_settings)
jars = []
for file in os.listdir(os.path.abspath(os.path.dirname(__file__))):
if file.endswith('.jar'):
file_path = os.path.abspath(file)
jars.append(file_path)
str_jars = ';'.join(['file:///' + jar for jar in jars])
table_env.get_config().get_configuration().set_string("pipeline.jars", str_jars)
# table_env.get_config().get_configuration().set_float('taskmanager.memory.network.fraction',0.8)
# table_env.get_config().get_configuration().set_string('taskmanager.memory.network.min','8gb')
# table_env.get_config().get_configuration().set_string('taskmanager.memory.network.max','16gb')
table_env.get_config().get_configuration().set_string('parallelism.default','1')
#先读取hadoop_hdfs上的CSV文件
table_env.execute_sql(
"""
CREATE TABLE `ods_flight` (
`start_city` string COMMENT '出发城市',
`end_city` string COMMENT '到达城市',
`stime` string COMMENT '出发日期',
`airline_name` string COMMENT '航班名称',
`flight_info` string COMMENT '飞机详细信息',
`flight_type1` string COMMENT '飞机型号',
`flight_type2` string COMMENT '飞机系列',
`setup_time` string COMMENT '出发时间',
`arr_time` string COMMENT '到达时间',
`start_airport` string COMMENT '起飞机场和航站楼',
`arr_airport` string COMMENT '到达机场和航站楼',
`ontime_rate` bigint COMMENT '准点率',
`flight_total_time` string COMMENT '飞行时间字符串',
`price` bigint COMMENT '价格',
`price_desc` string COMMENT '优惠折扣力度',
`flight_company` string COMMENT '航空公司',
`flight_type3` string COMMENT '飞行性质',
`setup_time_math` double COMMENT '出发时间_数字辅助',
`arr_time_math` double COMMENT '到达时间_数字辅助',
`arr_time2` string COMMENT '第几天到达',
`start_airport_simple` string COMMENT '起飞机场',
`arr_airport_simple` string COMMENT '到达机场',
`flight_total_time_math` bigint COMMENT '飞行时长_数字辅助',
`price_desc_math` double COMMENT '优惠折扣力度_数字辅助'
) WITH(
'connector' = 'filesystem',
'path' ='hdfs://bigdata:9000/flink_fliggy_flight/flight/hdfs_flights.csv',
'format' = 'csv'
)
"""
)
#设置下沉到mysql的表
table_env.execute_sql(
"""
create table tables01(
`airline_name` string primary key ,
`price_desc_math` double ,
`price_desc` string ,
`stime` string
) WITH(
'connector' = 'jdbc',
'url' = 'jdbc:mysql://bigdata:3306/Flink_Fliggy_Flight',
'table-name' = 'tables01',
'username' = 'root',
'password' = '123456',
'driver' = 'com.mysql.jdbc.Driver'
)
"""
)
#数据分析并且导入
#result=table_env.sql_query("select * from ods_zymk limit 10 ")
table_env.execute_sql("""
insert into tables01
select distinct airline_name,price_desc_math,price_desc,stime
from ods_flight
order by stime desc,price_desc_math asc
limit 30
""").wait()
#print("表结构",result.get_schema())
#print("数据检查",result.to_pandas())



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











