







西安工程大学本科毕业设计(论文)开题报告
学院:计算机科学学院 专业: 填表时间:2023年3月28日
| 姓 名 | 班级 | 学号 | |||
| 题 目 | 基于hadoop+spark的动漫视频推荐系统 | ||||
| 选题的意义: 随着互联网的快速发展,人们面临着海量的视频内容,如何从这些繁杂的视频中找到自己感兴趣的内容成为一个重要的问题。推荐系统作为一种解决信息过载问题的重要工具,能够根据用户的历史行为和偏好,预测用户可能感兴趣的内容,并对其进行推荐。在视频推荐领域,基于Hadoop和Spark的大数据框架的应用越来越广泛,它们能够处理大规模的视频数据,并对其进行深入的分析和挖掘。 本文旨在研究并设计一个基于Hadoop+Spark的视频推荐系统,该系统能够有效地利用大数据技术,对海量的视频数据进行处理和分析,并根据用户的行为和偏好进行视频推荐。与传统的推荐系统相比,基于Hadoop+Spark的视频推荐系统具有更高的处理能力和准确性,能够提供更加个性化的视频推荐服务。 | |||||
| 研究综述: 在基于Hadoop和Spark的视频推荐系统方面,一些国内外的研究机构和企业在大数据处理和分析方面进行了深入研究,并取得了一定的成果。例如,国外的Netflix利用Hadoop和Spark构建了一个大规模的推荐系统,能够处理海量的用户行为数据和视频数据,并为其用户推荐相关的视频内容。在国内,一些企业如阿里巴巴、腾讯等也在大数据处理和分析方面进行了深入研究,并推出了一些基于Hadoop和Spark的大数据产品和服务。 综上所述,推荐系统在国内外得到了广泛应用,不仅在视频领域,还在其他领域得到应用。在基于Hadoop和Spark的视频推荐系统方面,一些国内外的研究机构和企业已经取得了一定的成果,但是随着大数据技术的不断发展,还需要进一步研究和探索更加准确、高效的视频推荐算法和系统。 | |||||
| 论文(设计)写作提纲:
| |||||
| 研究工作进度安排: (根据学校安排自行修改) 1、查阅资料,拟定写作大纲,完成研究内容、现状、方法的研究等,提交开题报告; 2、基本完成毕业设计及毕业论文草稿的撰写; 3、提交中期检查相关资料,参加中期检查; 4、修改完善毕业设计,完成毕业设计和论文定稿的撰写; 5、提交答辩申请,参加答辩; 6、提交论文最终稿,打印装订论文,整理并上交全套毕业论文(设计)资料。 |
| 参考文献目录: [1] 基于短视频内容理解的用户偏好预测模型研究[D]. Muhammad Irbaz Siddique.北京交通大学,2023 [2] 基于人像聚类的短视频推荐系统的研究与实现[D]. 郝艳峰.辽宁大学,2022 [3] 基于前景理论的视频推荐方法研究[D]. 李天鹏.河南财经政法大学,2021 [4] 高校视频公开课点播平台智能推荐系统的设计与实现[D]. 陈汉福.华南理工大学,2022 [5] 基于物品协同过滤的个性化视频推荐算法改进研究[D]. 卜旭松.宁夏大学,2021 [6] 基于图论的个性化视频推荐算法研究[D]. 陈壁生.华南理工大学,2023 [7] 基于深度观看兴趣网络的视频推荐系统设计与实现[D]. 刘端阳.北京邮电大学,2021 |
| 指导教师意见: 签名: 2023年3月 29日 |
| 教研室主任意见: 签名: 2023年3 月29日 |
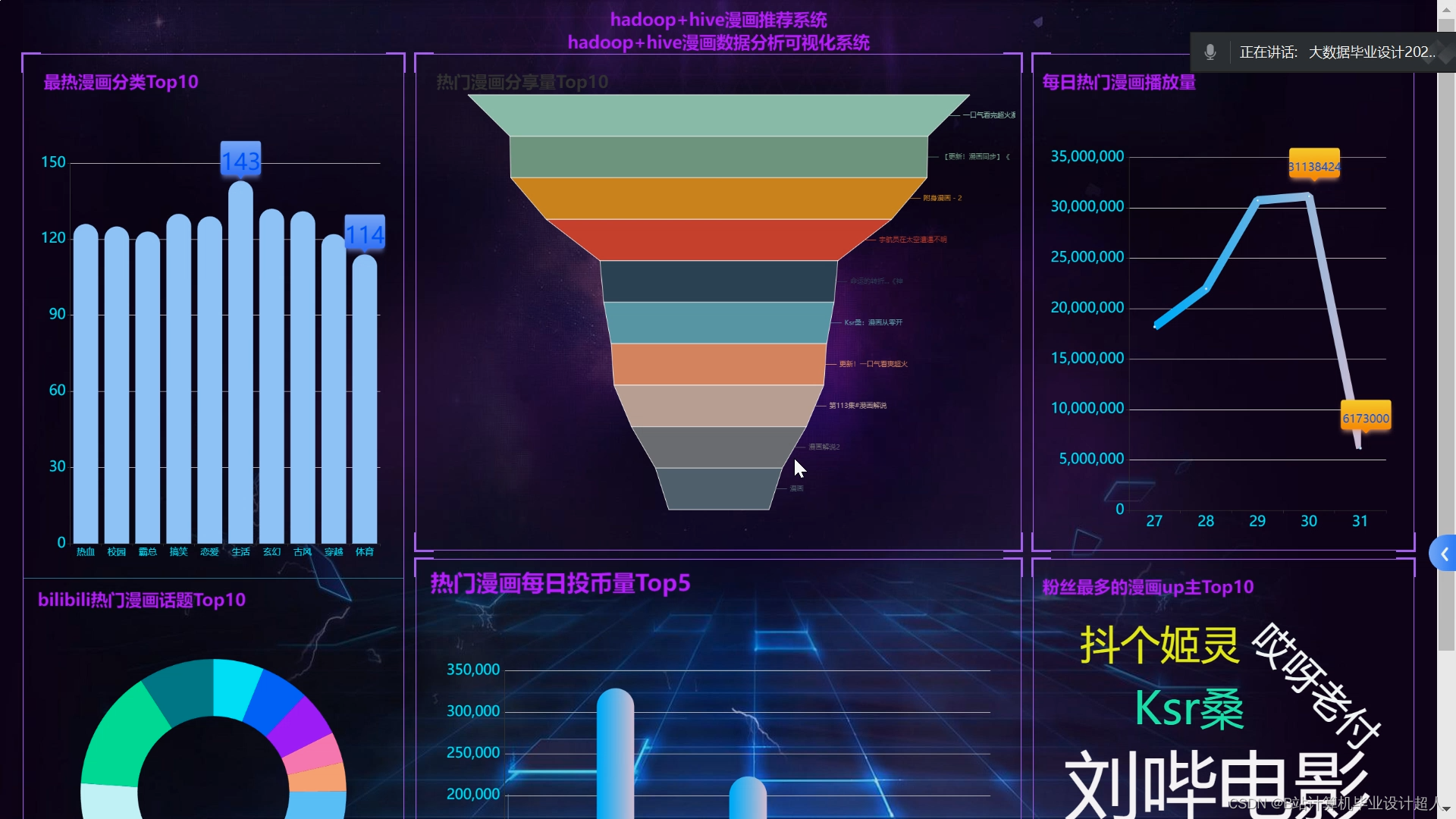
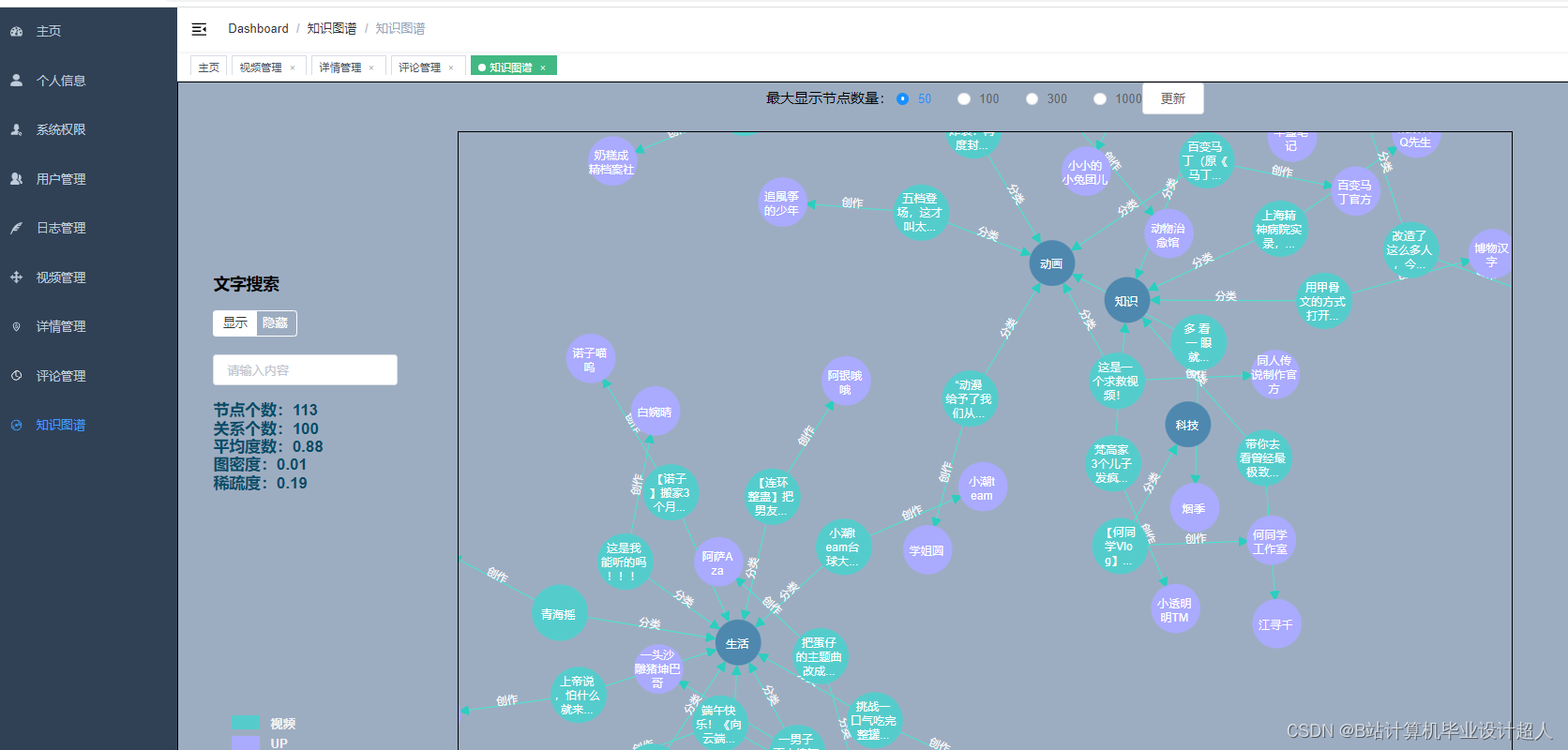
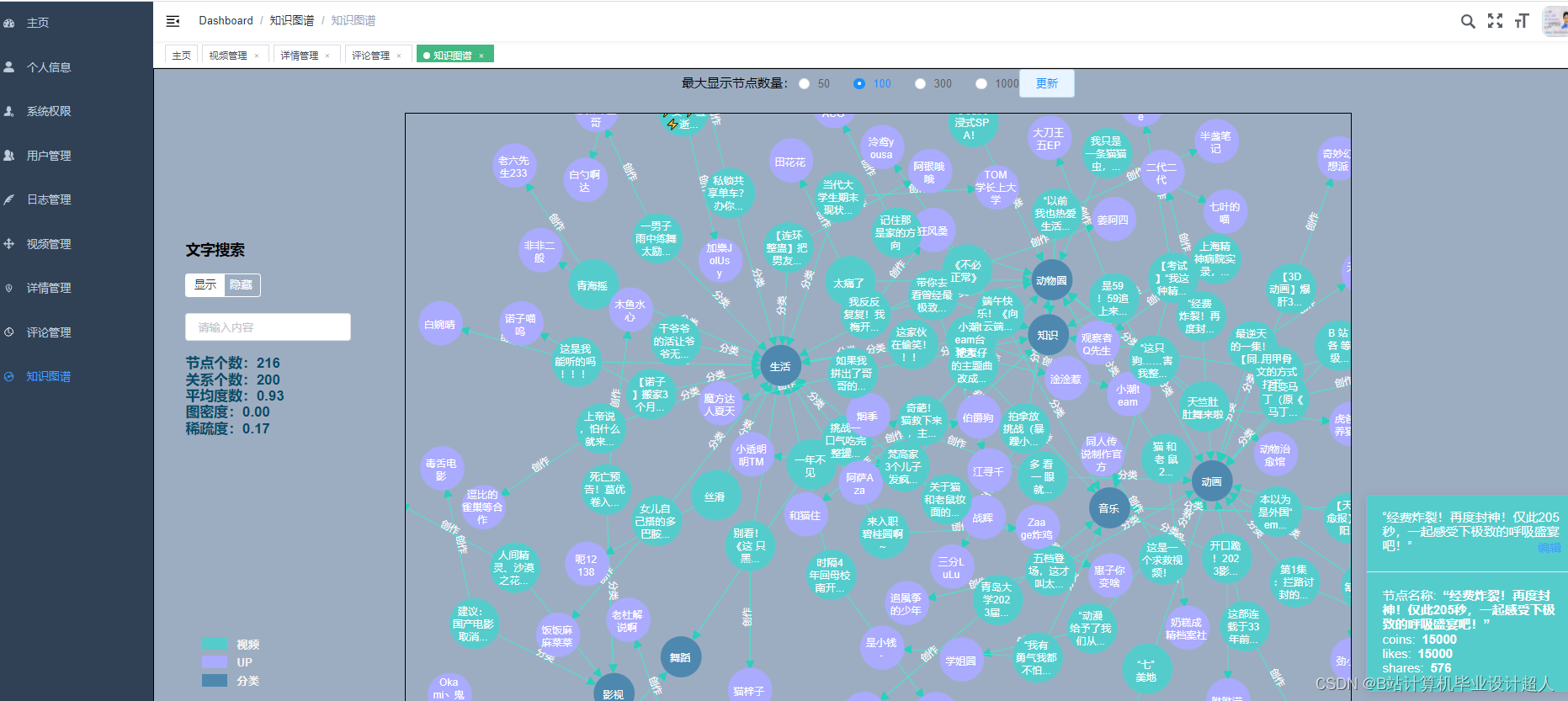
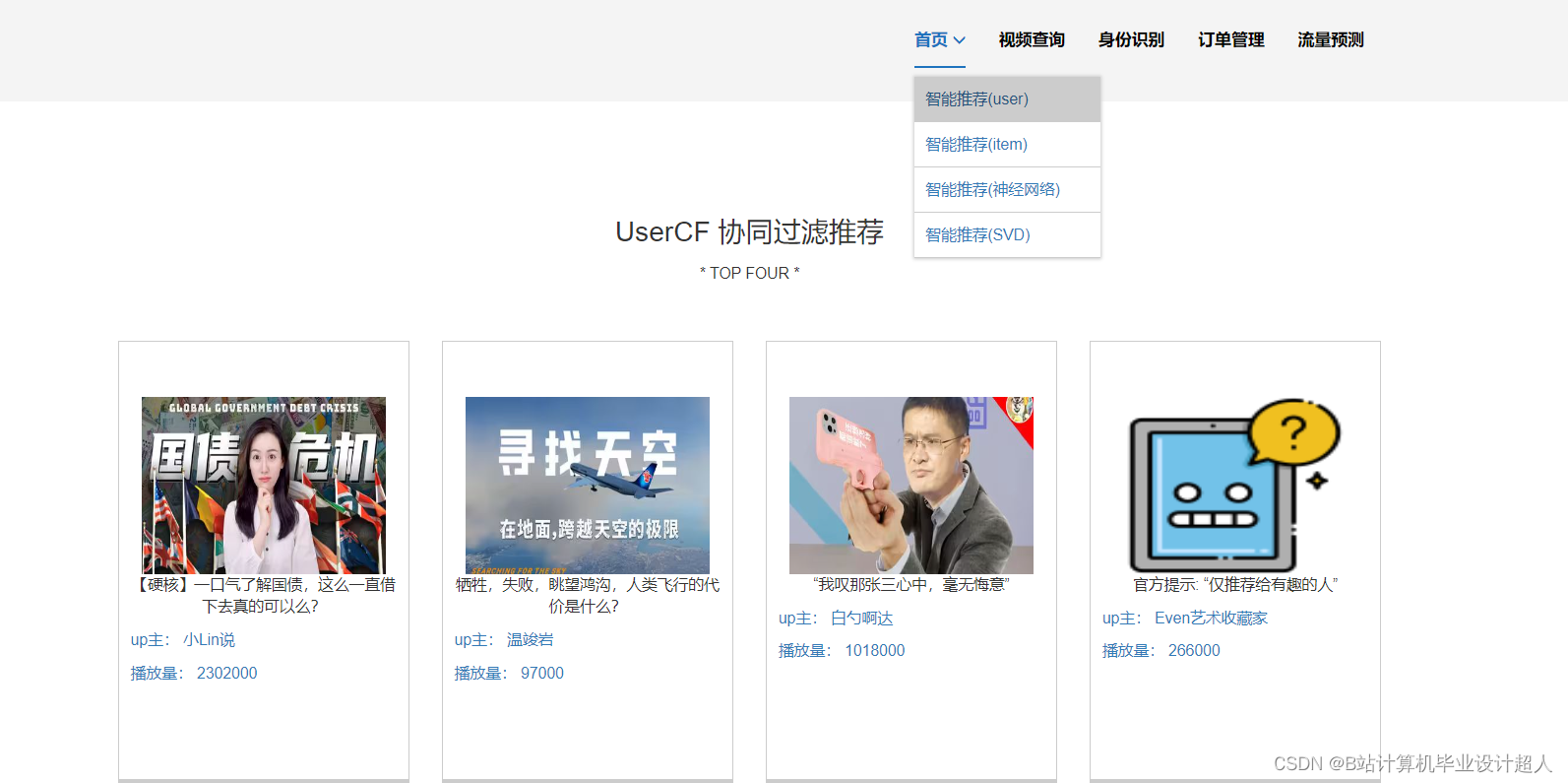
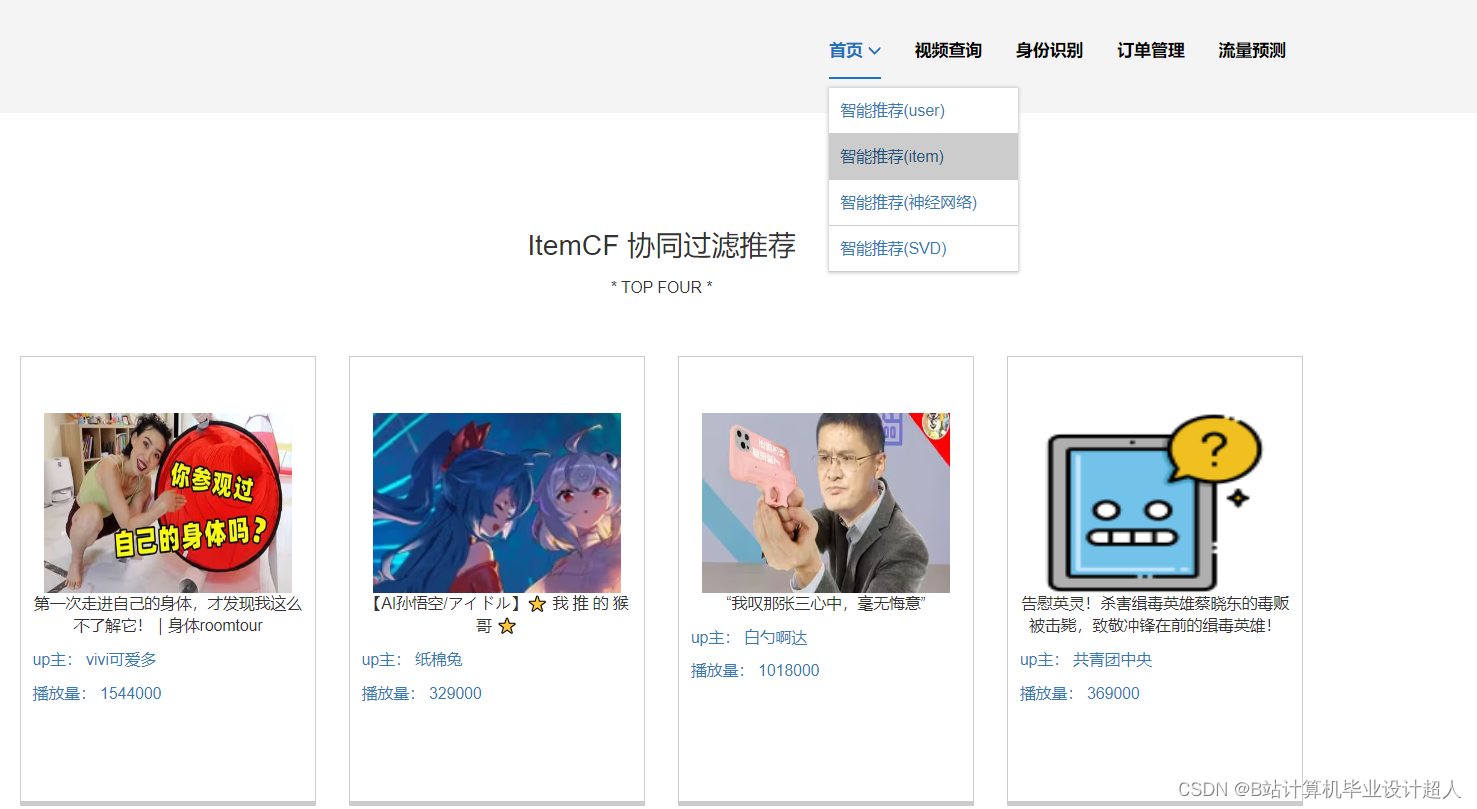
核心算法代码分享如下:
# coding=utf-8
# 基于物品的协同过滤推荐
import random
import sys
import math
from operator import itemgetter
import pymysql
from rate import Rate
import db
"""
"""
class ItemBasedCF():
# 初始化参数
def __init__(self):
self.n_sim_movie = 8
self.n_rec_movie = 4
self.trainSet = {}
self.testSet = {}
self.movie_sim_matrix = {}
self.movie_popular = {}
self.movie_count = 0
print('Similar movie number = %d' % self.n_sim_movie)
print('Recommneded movie number = %d' % self.n_rec_movie)
def get_dataset(self, pivot=0.75):
trainSet_len = 0
testSet_len = 0
# sql = ' select * from tb_rate'
results = db.session.query(Rate).all()
# print(results)
for item in results:
user, movie, rating = item.uid, item.iid, item.rate
self.trainSet.setdefault(user, {})
self.trainSet[user][movie] = rating
trainSet_len += 1
self.testSet.setdefault(user, {})
self.testSet[user][movie] = rating
testSet_len += 1
# cnn.close()
# db.session.close()
print('Split trainingSet and testSet success!')
print('TrainSet = %s' % trainSet_len)
print('TestSet = %s' % testSet_len)
# 读文件,返回文件的每一行
def load_file(self, filename):
with open(filename, 'r') as f:
for i, line in enumerate(f):
if i == 0: # 去掉文件第一行的title
continue
yield line.strip('\r\n')
print('Load %s success!' % filename)
# 计算电影之间的相似度
def calc_movie_sim(self):
for user, movies in self.trainSet.items():
for movie in movies:
if movie not in self.movie_popular:
self.movie_popular[movie] = 0
self.movie_popular[movie] += 1
self.movie_count = len(self.movie_popular)
print("Total movie number = %d" % self.movie_count)
for user, movies in self.trainSet.items():
for m1 in movies:
for m2 in movies:
if m1 == m2:
continue
self.movie_sim_matrix.setdefault(m1, {})
self.movie_sim_matrix[m1].setdefault(m2, 0)
self.movie_sim_matrix[m1][m2] += 1
print("Build co-rated users matrix success!")
# 计算电影之间的相似性 similarity matrix
print("Calculating movie similarity matrix ...")
for m1, related_movies in self.movie_sim_matrix.items():
for m2, count in related_movies.items():
# 注意0向量的处理,即某电影的用户数为0
if self.movie_popular[m1] == 0 or self.movie_popular[m2] == 0:
self.movie_sim_matrix[m1][m2] = 0
else:
self.movie_sim_matrix[m1][m2] = count / math.sqrt(self.movie_popular[m1] * self.movie_popular[m2])
print('Calculate movie similarity matrix success!')
# 针对目标用户U,找到K部相似的电影,并推荐其N部电影
def recommend(self, user):
K = self.n_sim_movie
N = self.n_rec_movie
rank = {}
if user > len(self.trainSet):
user = random.randint(1, len(self.trainSet))
watched_movies = self.trainSet[user]
for movie, rating in watched_movies.items():
for related_movie, w in sorted(self.movie_sim_matrix[movie].items(), key=itemgetter(1), reverse=True)[:K]:
if related_movie in watched_movies:
continue
rank.setdefault(related_movie, 0)
rank[related_movie] += w * float(rating)
return sorted(rank.items(), key=itemgetter(1), reverse=True)[:N]
# 产生推荐并通过准确率、召回率和覆盖率进行评估
def evaluate(self):
print('Evaluating start ...')
N = self.n_rec_movie
# 准确率和召回率
hit = 0
rec_count = 0
test_count = 0
# 覆盖率
all_rec_movies = set()
for i, user in enumerate(self.trainSet):
test_moives = self.testSet.get(user, {})
rec_movies = self.recommend(user)
for movie, w in rec_movies:
if movie in test_moives:
hit += 1
all_rec_movies.add(movie)
rec_count += N
test_count += len(test_moives)
precision = hit / (1.0 * rec_count)
recall = hit / (1.0 * test_count)
coverage = len(all_rec_movies) / (1.0 * self.movie_count)
print('precisioin=%.4f\trecall=%.4f\tcoverage=%.4f' % (precision, recall, coverage))
def rec_one(self,userId):
print('推荐一个')
rec_movies = self.recommend(userId)
# print(rec_movies)
return rec_movies
# 推荐算法接口
def recommend(userId):
itemCF = ItemBasedCF()
itemCF.get_dataset()
itemCF.calc_movie_sim()
reclist = []
recs = itemCF.rec_one(userId)
return recs
if __name__ == '__main__':
param1 = sys.argv[1]
# param1 = "1"
result = recommend(int(param1))
list = []
for r in result:
list.append(dict(iid=r[0], rate=r[1]))
print(list)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











