




毕业设计开题报告
基于大数据技术的高考志愿推荐系统
- 课题的目的及意义
- 研究现状
1、传统填报方法效率低、效果差。
目前,全国大部分省(自治区、直辖市)都是高考成绩公布后开始填报志愿,大部分家长和考生仅仅利用招生考试机构公布志愿填报日程几天时间,从全国近2700所高校和500多个专业中做出选择[1],对很多毫无经验的家长和考生来说难度较大。因为影响高考志愿因素太多,如考生职业生涯规划、个人和家庭情况、分数、院校、专业、城市、高考志愿政策规则[2]、填报策略技巧、近3到5年录取数据、就业情况等,如果仅在几天内通过传统手段,以手工查阅书籍材料,往往会因为资料难找、耗时长、易疲劳出错等原因,填报志愿和最终录取结果往往不尽如人意。
2、填报方案不科学,录取不满意案例多。
《中国青年报》社会调查中心发起的一项10万人参加的抽样调查,超过71.2%的人后悔当年的高考志愿。我们可以在新闻媒体或网络上看到很多志愿填报不科学的典型案例,其中很多是高材生[3]。2008年周某以青海省第三名的成绩被北京大学生命科学学院录取,两年后周某选择转学到了北京工业技师学院。2017年李某从中国科学技术大学退学补习,2018年高考以云南省理科第8名的好成绩拒绝清华大学和北京大学发出的邀请,选择了四川大学口腔专业。2017年广西理科高考第3名考生,填错高考志愿批次,最后通过征集志愿获得录取。2017年浙江省646高分考生竟报考独立学院,全省被独立学院录取的600分以上考生多达9人[4]。现实中,还有很多高考过来人默默承受着高考志愿填报失误带来的痛,比如对专业不满意、对院校不满意、填错批次、错过填报时间、被退档、毕业后从事与自己所学专业[5]毫无关联的工作等。
(二)课题背景
高考是中国的大学招生的学术资格考试,在目前看来,高考的考试类型有两种,一种是文理分科,另一种是新高考模式。传统的文理分科是将学生分成两个类型,一种是文科,除了语数外三门课以外需要学习政史地,理科相对应的就需要学习物化生。根据学生的高考成绩和每个大学在所对应省份的总体招生计划来分梯度划线,也就是我们常说的重本线,二本线和专科线。
高考填报志愿对每个考生都非常重要,每年全国有数百万家庭使用网络了解高考支援志愿信息并推荐填报志愿。对于很大一部分考生和家长来说,短时间了解全国数千所高等院校的招生标准、历史录取分数、专业要求等信息非常困难。往往由于信息的缺失或错误造成高考志愿与考生成绩之间的较大差异,对考生造成不可挽回的损失。
(三)课题意义
在本项目中主要研究的是传统文理分科的高考模式,因为这种模式有着大量的数据支撑,提供训练,能够高精度地做出预测。而新考高模式刚刚施行,其数据量不足以支撑训练,因此预测结果也不会很好。高考录取填报推荐志愿方式,梯度志愿和混合录取,经过不断优化,平行志愿已成为了高考录取的主流,大部分省份都采取平行志愿,所以本次项目也就平行志愿的录取方式来进行研究。即分数优先,满足偏好的方式,所以本项目着重对学生位次进行研究。针对高考这一热门话题,国内外都有着不少的专家学者对其进行研究,在过去的实践中,人们往往选用经典的时间序列方法来解决预测高校录取问题,即利用近5年高校录取的分数线,名次求平均值来预测当年的分数线,但是利用时间序列预测,就必须保证时间序列的过去值、当前值、和未来值之间存在着某种确定的函数关系。所以这养的预测是不够精确,不够完善的。除了基于时间序列的预测以外,还有人通过录取线差法来对高考录取进行研究,所谓录取线差是指考生意向院校当年平均录取分数与其所在招生批次录取控制分数线的差值。但是,每年高考试卷难度有别,造成了各个院校各年度的录取分数可能发生较大的变化。
(四)课题目的
基于此开发一款高考数据推荐与可视化系统。旨在优化高考数据推荐与可视化系统的功能和提高用户体验,争取在高考报考中占的一席之地。相信在大学教育时代,用户能够通过本平台足不出户就能够筛选到心仪的学校。
- 课题任务、重点研究内容及实现途径
- 课题任务
高考数据推荐与可视化系统主要是基于大数据技术开发,使用Python爬虫、Spark分析、人物画像、短支付宝沙箱支付、身份证自动识别、推荐算法-协同过滤算法(基于用户、基于物品全实现)组合技术完整整个项目的开发,同时使用SpringBoot框架,前端开发主要使用Html与Css的结合来进行页面的展示与布局;使用MySQL来进行数据的存储,通过整合MyBatis来进行对后台系统数据的管理,以及前端与数据库中数据的查取;利用Echarts进行数据的可视化分析。系统主要有以下功能模块:
1.用户模块:
1.1用户登录后可以进行个人信息的查看以及修改。
1.2可以进行一对一的关于志愿的收费咨询。
1.3对志愿的模拟填写,通过填写的分数进行推荐。
2.管理员模块:
2.1对用户的信息进行管理。
2.2对首页院校广告位的院校信息进行上架与下架。
2.3对用户的反馈建议进行处理。
2.4对数据库信息的管理。
3.推荐模块:
3.1通过用户输入的分数可以进行两个层次的推荐,即能够冲一冲的、较为稳妥的。
3.2推荐在此分数段的考生,都有过那些志愿的填报
3.3管理员可以根据用户的分数进行相关推荐的管理以及推荐数量的管理。
4.院校查询模块:
4.1用户能够对院校的基本信息进行查询,包括官网、院校代码、院校地址、院校所属、专业详情的信息显示。
4.2能够对各个省份的招生政策进行查询。
4.3管理员能够对院校的相关信息进行更新或删除。
5.院校信息的展示模块(广告位):
5.1管理员将部分院校的信息或图片展现在首页。
5.2用户能够通过首页,对热门院校进行直观的查看了解。
6.数据分析模块:
6.1通过各个省份的高考人数进行可视化的分析。
6.2对全国高校的数量进行可视化分析对比。
7.建议反馈模块:
7.1用户可以将本系统的不足或者错误进行提出问题建议。
7.2管理员对用户的建议与反馈进行处理并作出回应以及奖励。
数据大屏可视化
通过spark分析和echarts可视化展示各地高考人数、高考人数比例、热词展示、志愿填报情况、高校分布情况等具体数据。
(二)重点研究内容
1、推荐系统:包含协同过滤算法的两种实现(基于用户、基于物品)、基础业务功能;
2、后台管理系统:数据管理;
3、爬虫:爬取历年高考分数、高考院校信息,并可以实时更新;
4、数据大屏驾驶舱:使用Spark+Flink实时计算框架完成数据统计,以echarts形式进行可视化显示;
(三)实现途径
1、使用SpringBoot+Vue.js前后端分离完成web开发;
2、使用echarts技术开发设计大屏驾驶舱;
3、集成第三方接口阿里云短信、百度AI平台、百度地图;
4、独立使用MySQL数据库和navicat终端完成数据表设计;
5、使用Hadoop、Spark、Flink实时计算框架进行数据分析;
参考文献:
[1] 刘昊,李民.基于SSM框架的客户管理系统设计与实现[J].软件导刊,2017,16(07):87-89
[2] 孙乐康.基于SSM框架的智能Web系统研发[J].决策探索(中),2019(05):93
[3] 明日科技.Java从入门到精通(第3版).清华大学出版社.2014
[4] 王金龙,张静.基于java+Mysql的高校慕课(MOOC)本系统设计[J].通讯世界,2017,(20):276-277.
[5] 徐雯,高建华.基于Spring MVC及MyBatis的Web应用框架研究[J].微型电脑应用,2012,28(07):1-4+10
[6] 先巡,袁军.Ajax/Javascript在网页中的特效应用[J].黔南民族师范学院学报,2019,39(S1):100-103
[7] 王琴.基于Bootstrap技术的高校门户网站设计与实现[J].哈尔滨师范大学自然科学学报,2017,33(03):43-48
[8] 佘青.利用Apache Jmeter进行Web性能测试的研究[J].智能与应用,2012,2(02):55-57
[9] 蒲冬梅.软件项目可行性分析评审的要点[J].医院技术与软件工程,2017(24):54-55
[10] 李丹. 派遣信息网络管理平台设计与实现[J]. 软件导刊,2016,15(03):97-98.
[11] 刘震林,喻春梅.基于MVC模式的JAVA Web开发与实践应用研究[J].网络安全技术与应用,2021,(1):57-58.
[12]王红娟.基于软件开发的Java编程语言分析[J].电脑知识与技术,2021,17(5):60-61.
[13] Rachit Mohan Garg, YaminiSood, Balaji Kottana, Pallavi Totlani. A Framework Based Approach for the Development of Web Based Applications Waknaghat[J].Jaypee University of Information Technology,2017,1(1):1-4.
[14] Henry Labordre,Vincent Jonack. SMS and MMS interworking in mobile networks[M] .Boston: Artech House, 2019.
|
三、进度计划 | ||
|
序号 |
起止时间 |
工 作 内 容 |
|
1 |
2022.12.12-2022.12.18 |
毕业设计的开题 |
|
2 |
2022.12.19-2023.03.26 |
数据采集与处理、数据分析、系统设计与实现、毕业设计说明书的撰写阶段 |
|
3 |
2023.03.27-2023.04.09 |
毕业设计的中期检查 |
|
4 |
2023.04.10-2023.05.21 |
数据采集与处理、数据分析、系统设计与实现、毕业设计说明书的撰写阶段 |
|
5 |
2023.05.22-2023.06.04 |
毕业答辩、提交毕业设计文档材料 |
学生签名: 刘鑫宇
2022 年 12 月 17 日
四、指导教师意见
同意该同学开题。
指导教师签名: 刘文博
2022年 12 月 18 日
说明:
1.开题报告应根据教师下发的毕业设计任务书,在教师的指导下由学生独立撰写。
2.本页不够,请加页。
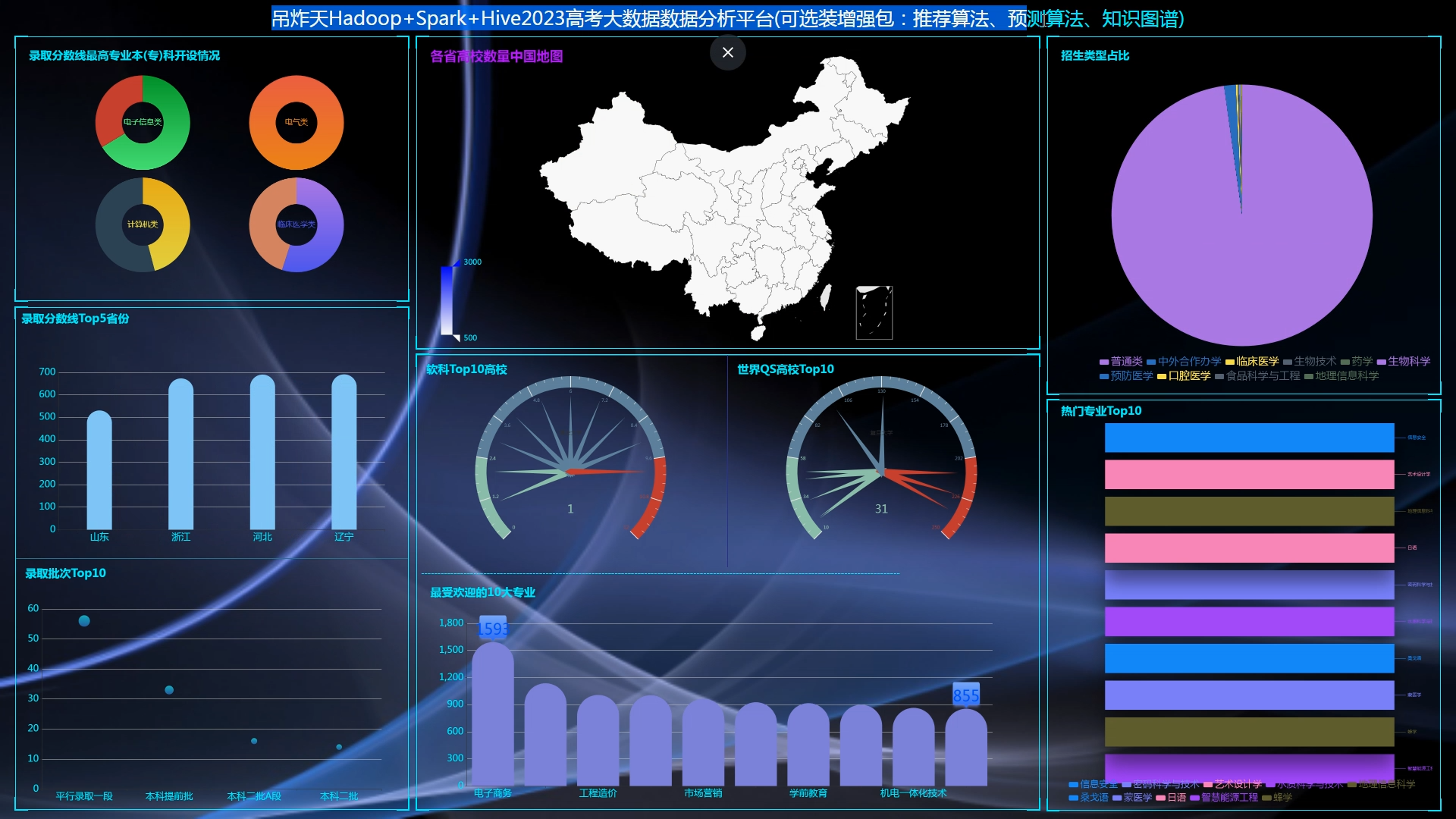


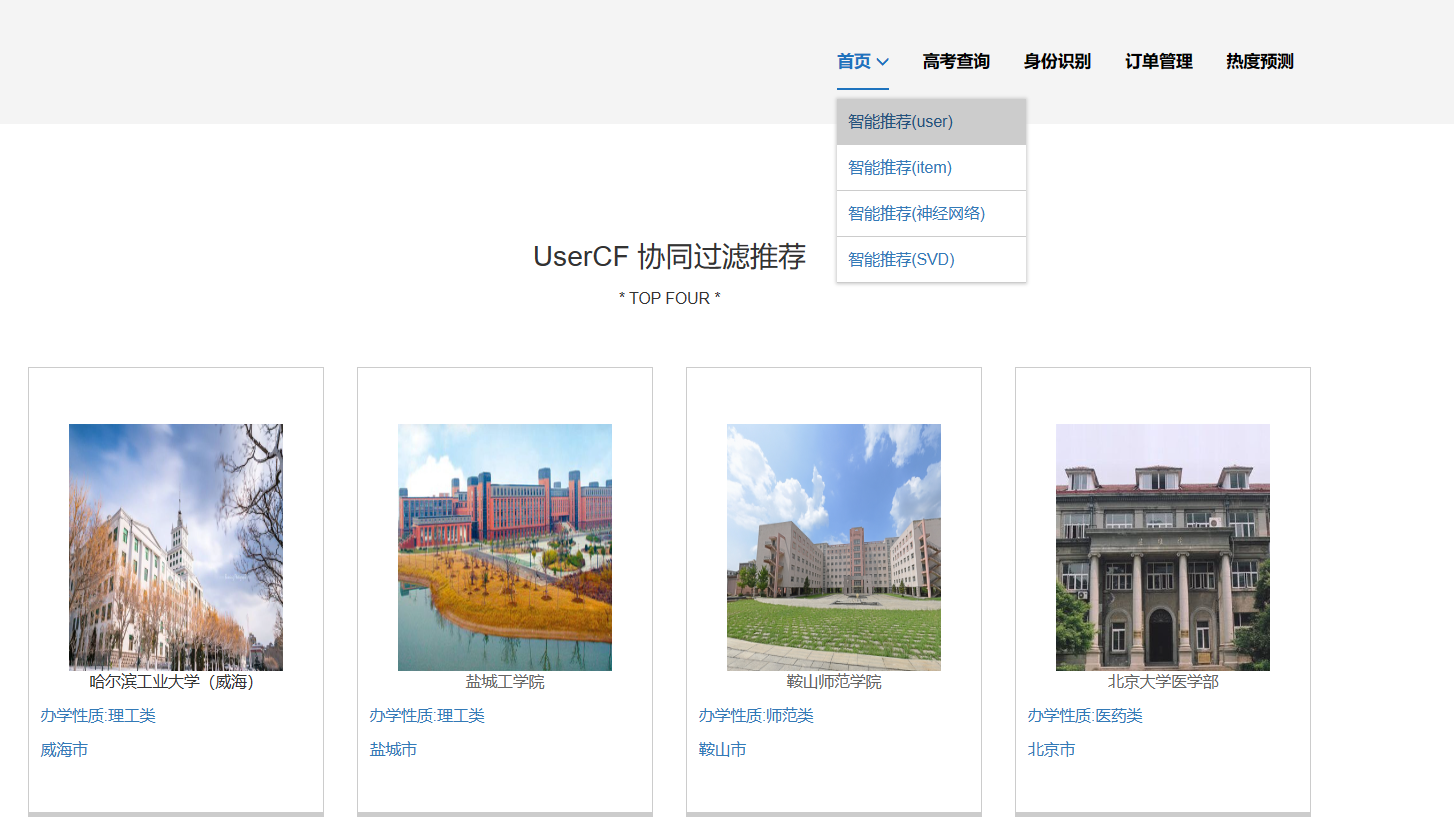
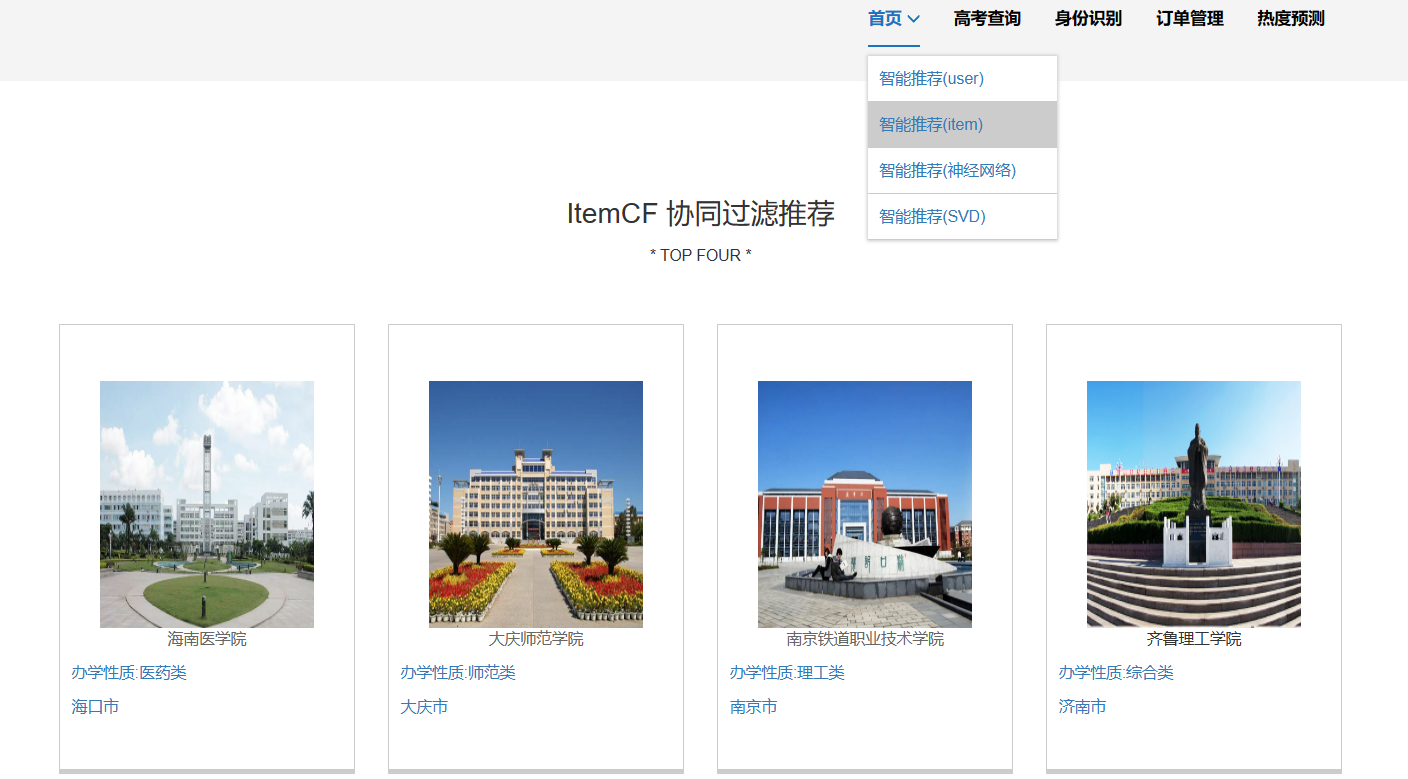
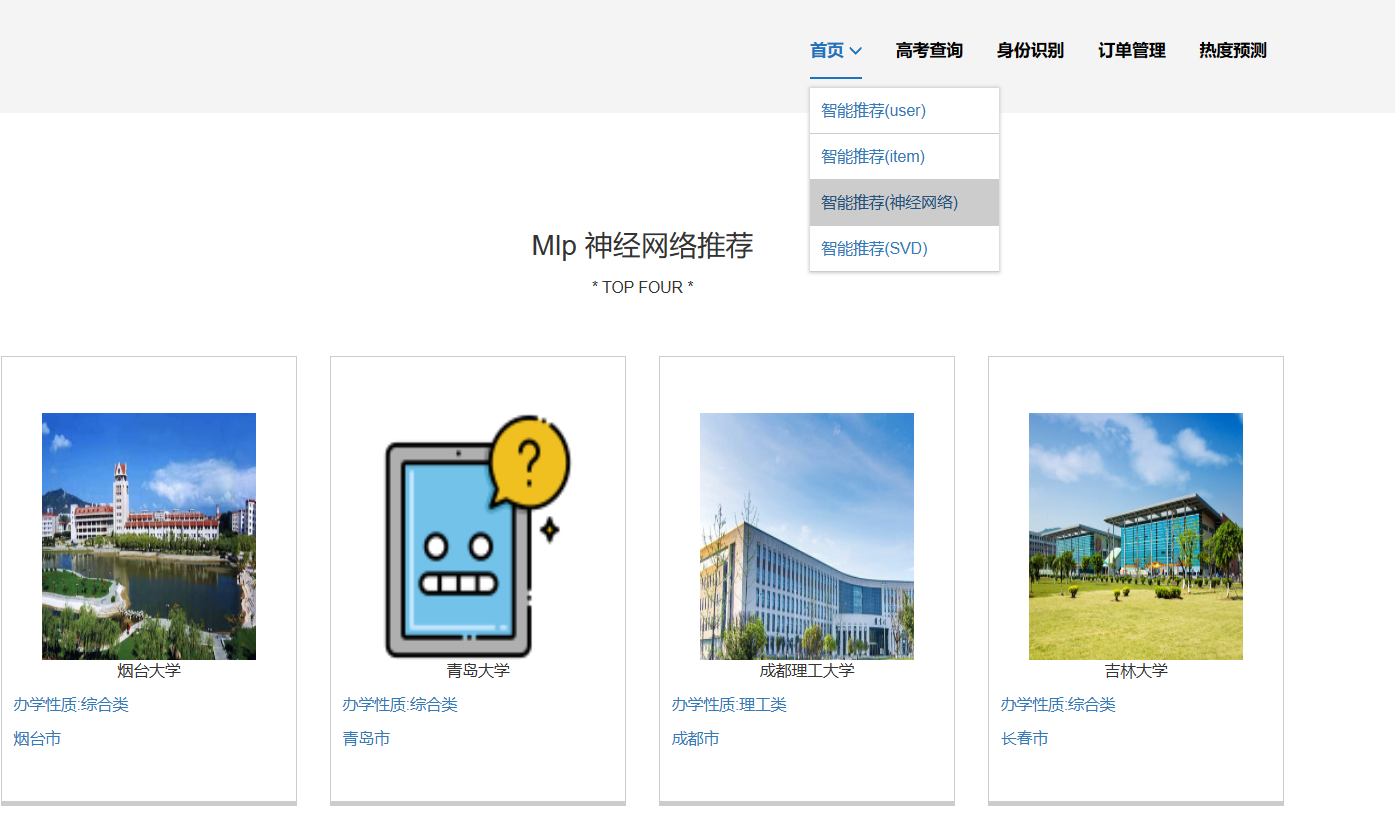
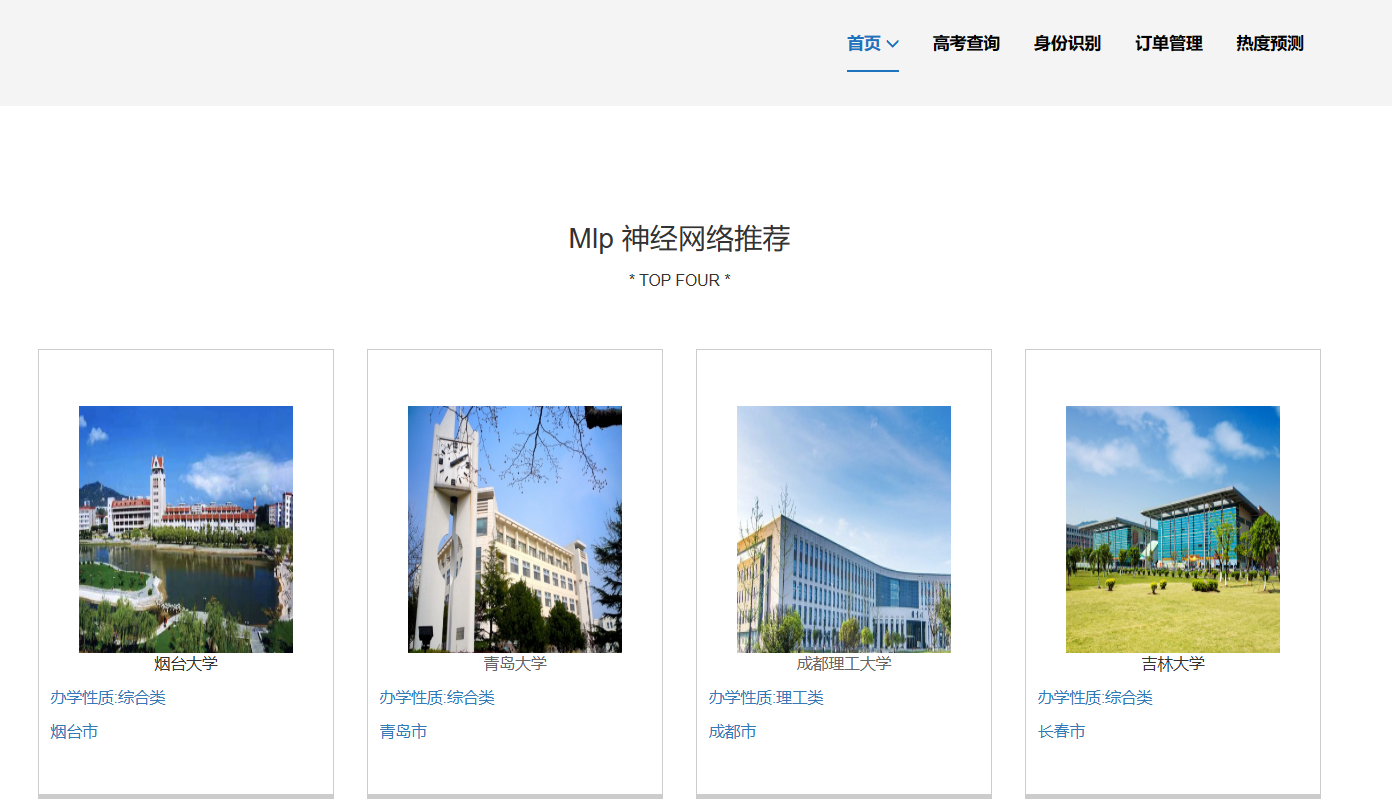
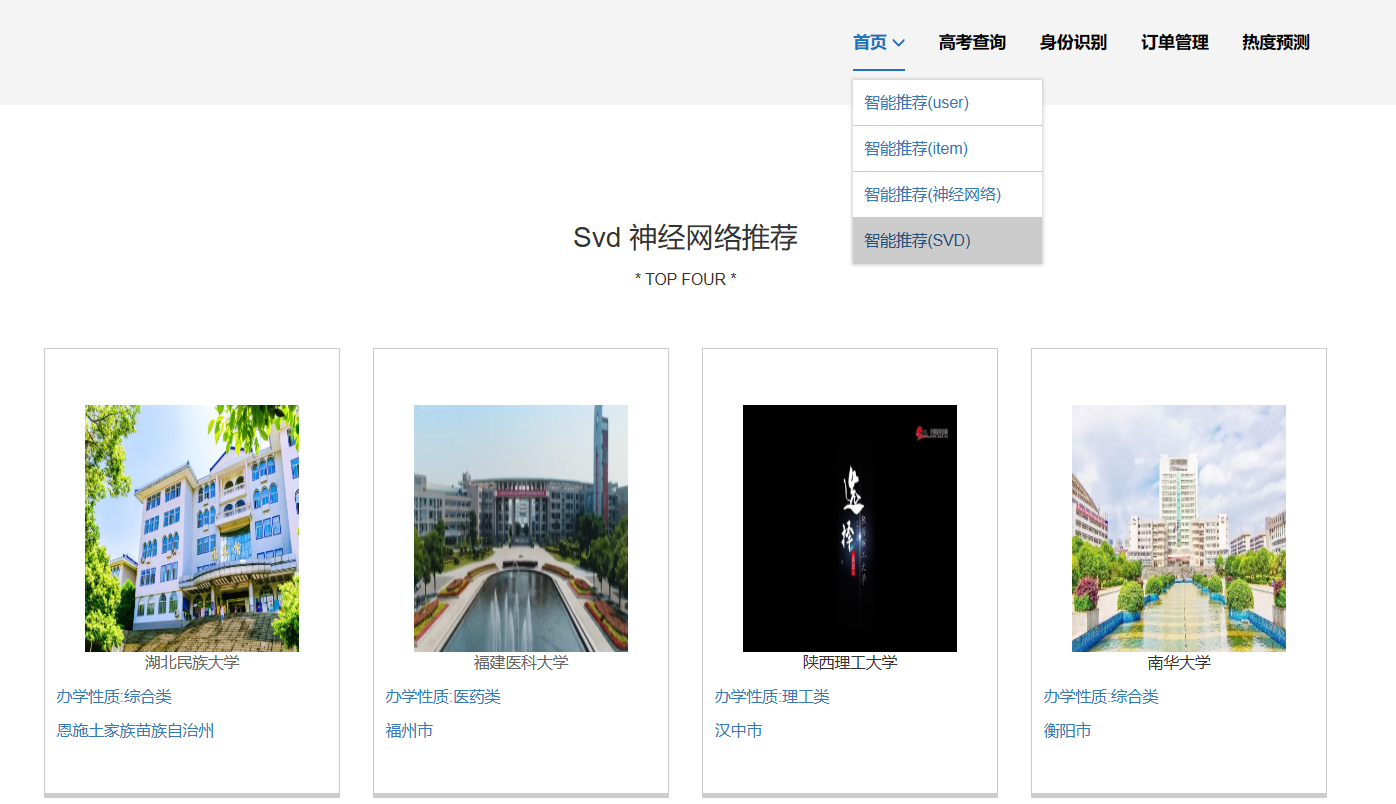
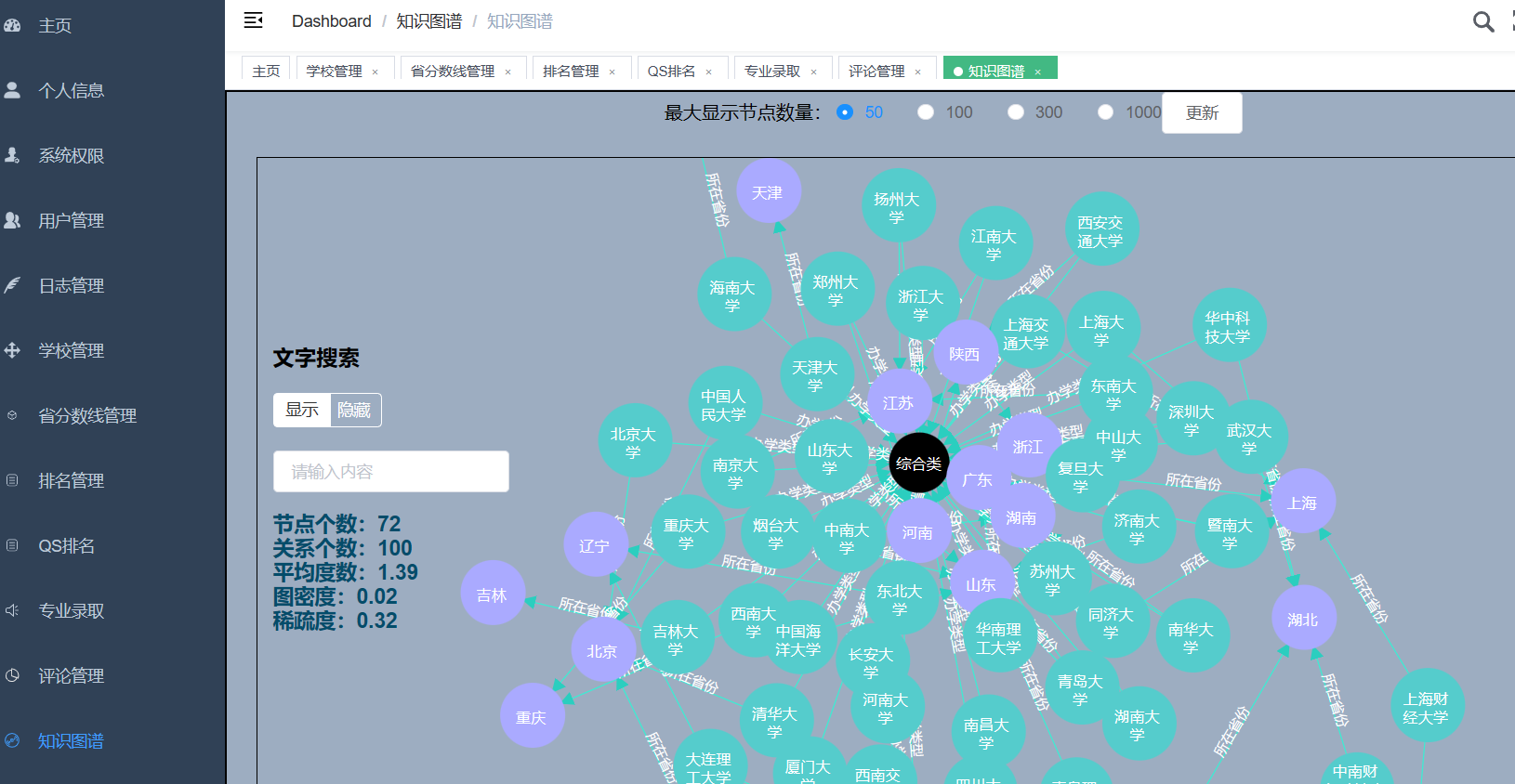
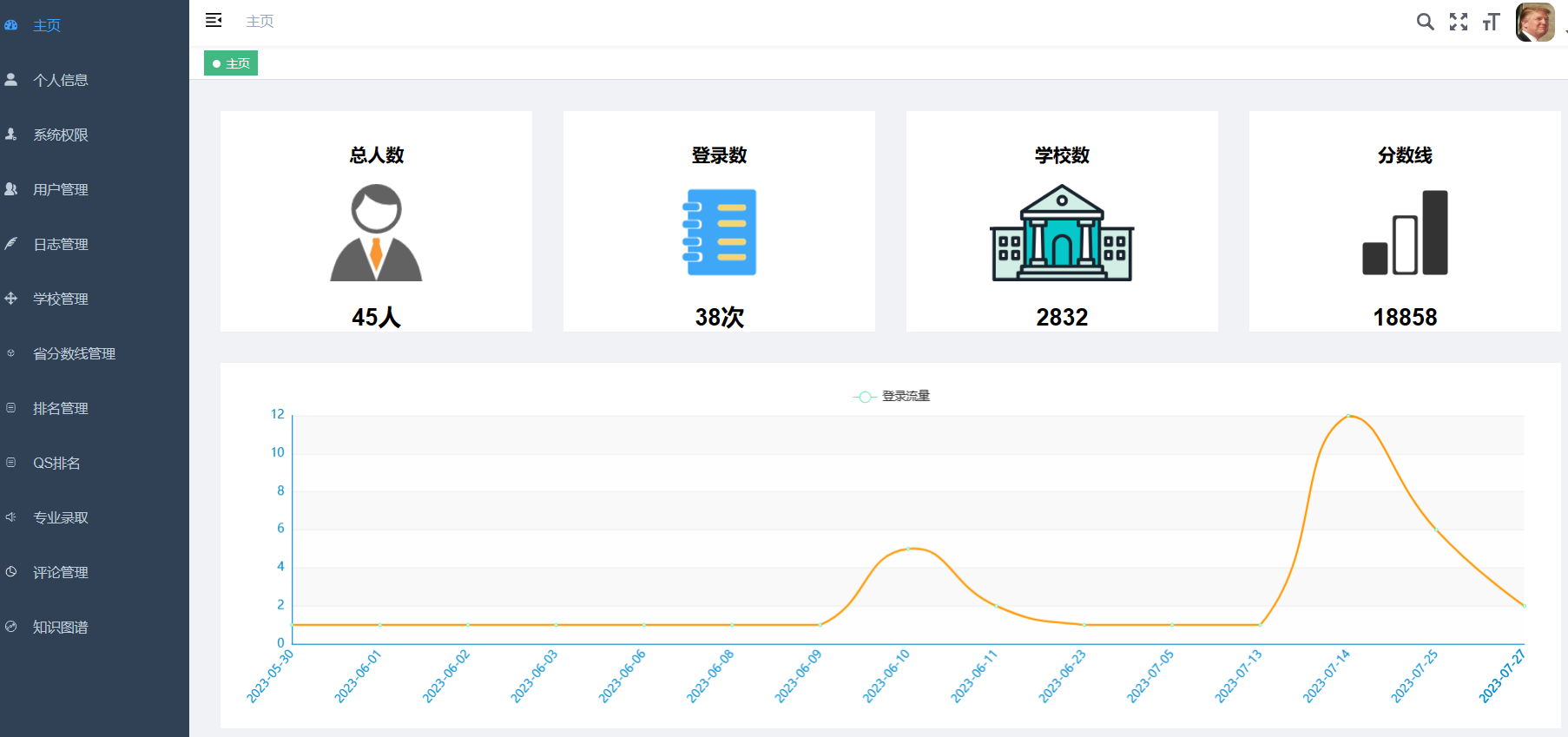


核心算法代码分享如下:
package com.sql
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.types._
import org.junit.Test
import java.util.Properties
class GaokaoSpark2024_FixBug {
val spark = SparkSession.builder()
.master("local[6]")
.appName("高考数据实时计算")
.getOrCreate()
//省控线模式
val school_province_score_Schema = StructType(
List(
StructField("id", IntegerType),
StructField("school_id", IntegerType),
StructField("student_province_id", IntegerType),
StructField("student_type",IntegerType),
StructField("year", IntegerType),
StructField("max_score", IntegerType),
StructField("min_score",IntegerType),
StructField("avg_score", IntegerType),
StructField("pro_score", IntegerType),
StructField("min_position", IntegerType),
StructField("batch_name", StringType)
)
)
val school_province_score_Df = spark.read.option("header", "false").schema(school_province_score_Schema).csv("hdfs://192.168.227.166:9000/gaokao/ods_school_province_score/school_province_score.csv")
//省份
val province_Schema = StructType(
List(
StructField("id", StringType),
StructField("province_id", IntegerType),
StructField("province_name",StringType),
StructField("policy", StringType),
StructField("gknum1", IntegerType),
StructField("gknum2",IntegerType),
StructField("gknum3", IntegerType)
)
)
val province_Df = spark.read.option("header", "false").schema(province_Schema).csv("hdfs://192.168.227.166:9000/gaokao/ods_province/province.csv")
//专业线
val school_special_score_Schema = StructType(
List(
StructField("year", StringType),
StructField("school_id", StringType),
StructField("special_id",StringType),
StructField("type", StringType),
StructField("batch", StringType),
StructField("zslx",StringType),
StructField("max", StringType),
StructField("min", StringType),
StructField("average", StringType),
StructField("min_section", StringType),
StructField("province", StringType),
StructField("spe_id", StringType),
StructField("info", StringType),
StructField("special_group", StringType),
StructField("first_km", StringType),
StructField("sp_type", StringType),
StructField("sp_fxk", StringType),
StructField("sp_sxk", StringType),
StructField("sp_info", StringType),
StructField("sp_xuanke", StringType),
StructField("level1_name", StringType),
StructField("level2_name", StringType),
StructField("level3_name", StringType),
StructField("level1", StringType),
StructField("level2", StringType),
StructField("level3", StringType),
StructField("spname", StringType),
StructField("zslx_name", StringType),
StructField("local_batch_name", StringType),
StructField("sg_fxk", StringType),
StructField("sg_sxk", StringType),
StructField("sg_type", StringType),
StructField("sg_name", StringType),
StructField("sg_info", StringType),
StructField("sg_xuanke", StringType)
)
)
val school_special_score_Df = spark
.read.option("header", "false")
//.option("nanValue",0)
.schema(school_special_score_Schema)
.csv("hdfs://192.168.227.166:9000/gaokao/ods_school_special_score/school_special_score.csv")
//学校
val school_Schema = StructType(
List(
StructField("id", IntegerType),
StructField("school_id", IntegerType),
StructField("school_name",StringType),
StructField("province_id", IntegerType),
StructField("province_name", StringType, nullable=true),
StructField("city_id", IntegerType),
StructField("city_name",StringType),
StructField("level", StringType),
StructField("type", StringType),
StructField("nature", StringType),
StructField("email", StringType),
StructField("phone", StringType),
StructField("site", StringType),
StructField("address", StringType),
StructField("status", IntegerType),
StructField("ad", StringType),
StructField("hot", IntegerType),
StructField("img", StringType),
StructField("oid", IntegerType),
StructField("label", StringType)
)
)
val school_Df = spark.read.option("header", "false").schema(school_Schema).csv("hdfs://192.168.227.166:9000/gaokao/ods_school/school.csv")
//软科
val ruanke_rank_Schema = StructType(
List(
StructField("school_id", IntegerType),
StructField("province_name", StringType),
StructField("type_name",StringType),
StructField("name", StringType),
StructField("rank", IntegerType),
StructField("sort", IntegerType)
)
)
val ruanke_rank_Df = spark.read.option("header", "false").schema(ruanke_rank_Schema).csv("hdfs://192.168.227.166:9000/gaokao/ods_ruanke_rank/ruanke_rank.csv")
//QS
val qs_world_Schema = StructType(
List(
StructField("school_id", StringType),
StructField("type_name", StringType),
StructField("province_name",StringType),
StructField("rank", StringType),
StructField("name", StringType),
StructField("sort", StringType)
)
)
val qs_world_Df = spark.read.option("header", "false").schema(qs_world_Schema).csv("hdfs://192.168.227.166:9000/gaokao/ods_ruanke_rank/ruanke_rank.csv")
//专业
val special_Schema = StructType(
List(
StructField("boy_rate", StringType),
StructField("degree", StringType),
StructField("fivesalaryavg",StringType),
StructField("girl_rate", StringType),
StructField("hightitle", StringType),
StructField("id", StringType),
StructField("level1", StringType),
StructField("level1_name", StringType),
StructField("level2", StringType),
StructField("level2_name", StringType),
StructField("level3", StringType),
StructField("level3_name", StringType),
StructField("limit_year", StringType),
StructField("name", StringType),
StructField("rank", StringType),
StructField("salaryavg", StringType),
StructField("spcode", StringType),
StructField("special_id", StringType),
StructField("view_month", StringType),
StructField("view_total", StringType),
StructField("view_week", StringType),
StructField("detail_link", StringType)
)
)
val special_Df = spark.read.option("header", "false").schema(special_Schema).csv("hdfs://192.168.227.166:9000/gaokao/ods_special/special.csv")
@Test
def init(): Unit = {
//school_province_score_Df.show()
province_Df.show()
//school_special_score_Df.show()
//school_Df.show()
//ruanke_rank_Df.show()
//qs_world_Df.show()
}
// ----剩余使用spark_sql完成
// ---指标3 录取批次Top10
@Test
def tables03(): Unit = {
school_province_score_Df.createOrReplaceTempView("ods_school_province_score")
val df2 = spark.sql(
"""
select batch_name,count(1) num
from ods_school_province_score
where year = date_format(current_timestamp(),'yyyy')
group by batch_name
order by num desc
limit 10
""")
df2
// .show(50)
.coalesce(1)
.write
.mode("overwrite")
.option("driver", "com.mysql.cj.jdbc.Driver")
.option("user", "root")
.option("password", "123456")
.jdbc(
"jdbc:mysql://bigdata:3306/2412_gaokao?useSSL=false",
"table03",
new Properties()
)
}
//指标4 最受欢迎的专业
@Test
def tables04(): Unit = {
school_special_score_Df.createOrReplaceTempView("ods_school_special_score")
val df2 = spark.sql(
"""
select spname,count(1) num
from ods_school_special_score
group by spname
order by num desc
limit 10
""")
df2
// .show(50)
.coalesce(1)
.write
.mode("overwrite")
.option("driver", "com.mysql.cj.jdbc.Driver")
.option("user", "root")
.option("password", "123456")
.jdbc(
"jdbc:mysql://bigdata:3306/2412_gaokao?useSSL=false",
"table04",
new Properties()
)
}
//--指标5:中国地图
@Test
def tables05(): Unit = {
school_Df.createOrReplaceTempView("ods_school")
val df2 = spark.sql(
"""
select province_name,count(1) num
from ods_school
where length(province_name) >0
group by province_name
""")
df2
// .show(50)
.coalesce(1)
.write
.mode("overwrite")
.option("driver", "com.mysql.cj.jdbc.Driver")
.option("user", "root")
.option("password", "123456")
.jdbc(
"jdbc:mysql://bigdata:3306/2412_gaokao?useSSL=false",
"table05",
new Properties()
)
}
//---指标6:软科排名Top10高校
@Test
def tables06(): Unit = {
ruanke_rank_Df.createOrReplaceTempView("ods_ruanke_rank")
val df2 = spark.sql(
"""
select name,rank
from ods_ruanke_rank
order by rank asc
limit 10
""")
df2
//.show(50)
.coalesce(1)
.write
.mode("overwrite")
.option("driver", "com.mysql.cj.jdbc.Driver")
.option("user", "root")
.option("password", "123456")
.jdbc(
"jdbc:mysql://bigdata:3306/2412_gaokao?useSSL=false",
"table06",
new Properties()
)
}
//---指标7特殊原因只能使用hive_sql
//指标8 招生类型占比
@Test
def tables08(): Unit = {
school_special_score_Df.createOrReplaceTempView("ods_school_special_score")
val df2 = spark.sql(
"""
select zslx_name,count(1) num
from ods_school_special_score
where zslx_name is not null
group by zslx_name
order by num desc
limit 10
""")
df2
//.show(50)
.coalesce(1)
.write
.mode("overwrite")
.option("driver", "com.mysql.cj.jdbc.Driver")
.option("user", "root")
.option("password", "123456")
.jdbc(
"jdbc:mysql://bigdata:3306/2412_gaokao?useSSL=false",
"table08",
new Properties()
)
}
//指标9 招生类型占比
@Test
def tables09(): Unit = {
special_Df.createOrReplaceTempView("ods_special")
val df2 = spark.sql(
"""
select name,view_total
from ods_special
order by view_total desc
limit 10
""")
df2
//.show(50)
.coalesce(1)
.write
.mode("overwrite")
.option("driver", "com.mysql.cj.jdbc.Driver")
.option("user", "root")
.option("password", "123456")
.jdbc(
"jdbc:mysql://bigdata:3306/2412_gaokao?useSSL=false",
"table09",
new Properties()
)
}
}




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











