







| 基于Spark的航班飞机票数据分析及可视化展示 | |
| 学生姓名 | 马玉 |
| 院 部 | 数学与计算机学院 |
| 专业班级 | 2020级数据科学与大数据技术班 |
| 指导教师 | 汪贵生 |
二 ○ 二 四 年 五 月
基于Spark的航班飞机票数据分析与可视化展示
随着人们的生活水平不断提高,机票行业顺势快速发展。面对多样化的飞机出行需求,用户很难在庞大的资源数据中找到契合自身的信息。运用 Hadoop 大数据技术对相似的信息进行整理归纳为用户提供更加的机票出行方案,是本人提出的机票信息化方案。
因此本文阐述了一款基于大数据计算框架对机票数据进行分析的软件系统,实现了对数据采集、数据处理与分析、数据可视化展示为一体的操作,基本满足为用户推荐心仪机票的需求。机票数据分析及可视化突破了传统商务在时间、地域上的限制,成为了方便快捷、安全可靠的新兴电子化商务活动模式,使网上订票活动更加快速、明确、方便。对航空公司来说机票数据可视化既能扩大服务范围,扩大公司影响,减少营业费用,有对稳固航空公司的客源有着重要的辅助作用,站在旅客的角度,航班飞机票可视化提供了更多的方便,节省了更多时间。
本系统利用爬虫技术进行机票的数据爬虫,将各地的机票数据进行爬取,采集机票数据作为数据集,使用MapReduce对数据进行数据清洗,使用hive数仓技术建表建库,使用hive_sql和Scala完成数据的离线和实时分析,统计指标使用sqoop导入mysql数据库,使用Flask 搭建 web 后台,最后利用 Echarts 进行数据可视化展示。
本文旨在探讨如何利用Hadoop技术对机票数据进行全面、深入的分析,并将分析结果通过可视化方式呈现,以帮助经营者和游客更好地理解市场趋势和需求。本文将首先对相关文献进行综述,然后介绍Hadoop在机票数据分析中的应用方法和流程,接着展示可视化结果,最后对全文进行总结和展望。
关键词: 机票数据分析,hadoop框架,python爬虫
With the development of the economy, aircraft travel, as an important way of travel, has gradually become the first choice for people to travel and travel. However, in the face of fierce market competition and diversified customer demand, how to deeply analyze and visualize ticket data to improve operational efficiency and service quality has become an urgent problem in the industry. As a big data processing technology, Hadoop has the advantages of distributed storage and computing, and provides new solutions for data analysis and visualization.
The system uses crawler technology to capture ticket data, capture ticket data from various places, obtain data sets, use MapReduce to clean up data, use data warehouse technology to build tables and databases, and use hive_sql and Scala to complete offline and real-time data analysis. Statistical indicators use sqoop to import mysql database, use springboot framework to exchange data with MySql, use Flask to build network background, and use Echarts to visually display data.
The purpose of this article is to explore how to use Hadoop technology to conduct a comprehensive and in-depth analysis of ticket data and present the analysis results in a visual way to help operators and passengers better understand market trends and needs. This article will first review the relevant literature, then introduce the application methods and processes of Hadoop in ticket data analysis, then display the visualization results, and finally summarize the full text.
Keywords: data analysis, Hadoop framework, python crawler.
第一章绪论
1.1课题研究背景
近年来我国航空业高速发展,2022年,民航业完成运输总周转量599.3亿吨公里、旅客运输量2.5亿人次、货邮吞吐量607.6万吨,恢复至新冠肺炎疫情前的46.3%、38.1%、80.7%。前两年受疫情影响,国内机票业受到重创,2020年客运量为18亿人次,比2019年的45亿人次减少60.2%。得益于我国旅游业的迅速发展,在线机票市场也发展迅猛。2023年我国在线用户和在线机票市场交易规模分别达到2.28亿人和209.4亿元,同比增长55 %和64%。同样受疫情影响,2020年我国在线购票用户和在线机票市场交易规模分别下滑至1.82亿人和125.8亿元。随着疫情得到控制以及旅游业的大力发展,2023年我国在线机票市场交易规模有望上升至201.3亿元,回到疫情前水平。
疫情期间在线机票供给逆势增长,在消费市场低迷的情况下,疫情期间机票供给端却高速增长。根据中国机票与机票发展协会数据显示,2023年我国民航旅客运输量预计完成6.2亿人次,同比2022年增长145.9%,整体恢复至2019年的93.8%。2023年商务线航班恢复极为迅速,在2月份航班量已经超过2019年同期10个百分点以上,4-9九月份更是超20个百分点以上,不过客座水平明显不如2019年,2023全年商务线平均客座率约72%,比2019年下降12个百分点,航班运力供给远大于需求。为在线机票市场的后续发展奠定了较好的基础。
以上数据参考前瞻产业研究院《中国机票行业市场前景预测与投资战略规划分析报告》,同时前瞻产业研究院还提供产业大数据、产业研究、产业链咨询、产业图谱、产业规划、园区规划、产业招商引资、IPO募投可研、招股说明书撰写等解决方案。
民航建设是促进我国航空业产业升级的必然阶段,航空业经历了前几年的野蛮生长后,逐步进入理性经营、整合发展的阶段,但仍有大量投资进入机票行业,成为航空投资热点,使得民航业规模持续扩大。随着乘客消费升级,他们对于飞机出行的诉求也逐渐提高,更加注重出行品质和服务体验。国内航空公司恰恰因为富有主题的文化内涵、个性化的服务、优美的环境而迎合了市场发展。
机场与其周边环境和配套设施相结合,成为微型旅游购物的目的地。游客不需要再去大型商场,在机场中参与主题活动或购物体验就能够满足购物的需求。这种变化是航空业品质化的新趋势。机场多在城市,它的发展前景与当地经济社会发展息息相关。飞机成为人们出游的主流方式,既可以方便快捷领略当地自然风光与文化底蕴融合,又能兼顾人们的休闲度假需求,因而发展前景被广大业者看好。
随着机票销售数量的扩大,机票消费日益增加,“机票经济”形态内容愈加丰富。机票消费者的多样化需求,促使航空与其有关的产业通过相互融合渗透,使得当地居民有来自不同产业发展带来的收益,可实现家门口创业的梦想。相对于一二线城市而言,许多三四线城市的航空元素仍处于沉淀与待垦状态,而且三四线城市靠近农村,更利于对机票购买者产生近空消费牵引,商业红利自然值得期待。
近几年随着消费升级、居民对飞机出行的需求日益细分,富于人文情怀、价格美好的旅游拉动民航业发展,尤其是高景气度的周边游的重要入口。随着经济全球化发展,乘坐飞机国内外旅游成为主流选择,直播订购、飞机盲盒等深受年轻人喜爱的出圈销售模式,也将带着航空业达到新的增长点。飞机作为旅游交通产业重要的一环,未来的发展将逐步开始走向品牌化和集群化,不再是散打原始的模式。航空业态延伸空间大,产业资源的引入将有利于开发多渠道收益,在提升收入的同时提高航空业的抗风险能力。例如文创、实体类的商品可以打破时空限制,持续与消费者发生关联。这是提升消费者长期价值的有效方式。
1.2 课题研究目的和意义
近几年疫情对各行各业的影响巨大,航空产业链也是受害者之一。现如今疫情结束,百废俱兴。航空业首当其冲,因为在疫情期间人们被限制了自由,限制了活动范围,人们渴望自由和探索。而且在疫情期间看到了太多生生死死,许多人更愿意去选感受自己的生活,感受自己的价值,释放心中压抑许久的焦虑与不安。飞机就成为他们的首要选择。那么研究航班飞机票,首先可以帮助了解机票的市场现状和发展趋势,也可以为想要购买飞机票的人们提供重要参考,尽可能的满足人们的需求与期望,让他们与更好的出游体验。更重要的是航空业的发展可以带动当地经济的发展。
首先研究飞机票有助于更深入地了解航空市场和业务运营的内在规律,为相关企业和机构提供决策依据。其次,研究航班飞机票有助于提高航空业的整体竞争力和发展水平,促进航空市场的可持续发展。此外,航空的发展可推动地方经济的繁荣和发展,带动相关产业的协同发展,实现经济、社会和文化的多赢。
1.3 研究的主要内容
本文旨在探讨如何利用Spark技术对机票数据进行深入分析和可视化。首先,我们收集了大量的航班飞机票数据,包括入住率、房价、地理位置、设施等等。然后,我们利用Hadoop,Spark的分布式存储和计算优势,对数据进行清洗、分析和挖掘。最后,我们利用数据可视化工具,将分析结果以图形、图像等形式呈现出来,为机票的经营者和游客提供有价值的参考。
目的和意义
目的
在旅行规划中,机票价格一直是旅客关注的重点。机票价格的波动不仅受季节、航线、航空公司等因素的影响,还受到市场供求关系、经济形势等因素的影响。因此,通过对机票价格进行预测分析,可以帮助旅客选择更合适的出行时间和机票购买策略,从而节省旅行成本。
意义
提高乘客购票决策:基于Hadoop的飞机票价格预测能够提供乘客准确的价格预测信息,帮助他们选择合适的购票时间和最优的价格,从而节省成本。
改善航空公司运营管理:航空公司可以准确预测票价趋势和需求变化,从而制定更具竞争力和市场响应性的票价策略。这有助于提高运营效率、增加收益和优化航线安排。
实现可持续发展:航空业是全球排放最高的行业之一。通过预测飞机票价格,并能够更好地安排航班和座位利用率,航空公司可以减少空座位和航班的浪费,从而降低碳排放和资源浪费,实现可持续发展。
推动大数据技术应用:基于Hadoop+Hive的机票价格预测分析与可视化,可以推动大数据技术在航空业的应用和发展。这对于促进航空公司数字化转型,提升数据分析和预测能力具有重要意义。
通过基于Hadoop+Hive的机票价格预测分析与可视化,可以为乘客提供更好的购票体验,为航空公司提供决策支持,促进航空业的可持续发展,并推动大数据技术在航空业的应用。
主要内容
将大数据处理,充分利用Hadoop和hive的分布式计算和存储能力,首先,收集并整理历史机票价格数据;然后,基于这些数据,构建预测模型;最后,利用已训练的模型对未来机票价格进行预测和分析,然后通过echarts生成可视化大屏。这些步骤可以帮助航空业务决策者预测未来的机票价格趋势,从而做出合理的定价和市场策略。
1、 数据收集和清洗: 从各个航空公司和第三方机票平台收集大规模的机票价格数据,包括航班信息、日期、价格等。对收集到的数据进行清洗,处理缺失值、异常值和重复值等,确保数据的准确性和完整性。
数据存储和管理: 利用Hadoop的分布式文件系统(HDFS)存储机票价格数据,并使用Hive进行数据管理和查询。将机票价格数据通过Hive表的方式进行组织和存储,方便后续的数据分析和预测。
2、数据分析和建模: 使用Hive进行数据分析,通过SQL语言对机票价格数据进行聚合、统计和计算,提取有用的特征。基于机票价格的历史数据,可以使用统计模型、时间序列模型或机器学习算法构建机票价格预测模型。选择合适的预测模型,根据历史数据进行训练和验证,得到预测模型的参数和准确度指标。
3、用户界面设计:通过echarts等方式,将预测结果以图表、列表等形式直观地展现给用户,方便用户了解和比较不同的飞机票价格。
进度
2023-12-20至2023-12-30 Python爬虫采集机票数据(放到服务器上7*24小时跑爬虫脚本)
2024-01-01至2024-01-28 Linux大数据中间件搭建
2024-02-01至2024-02-28 离线指标分析
2024-03-01至2024-03-15 实时指标分析
2024-03-16至2024-03-29 指标导入
2024-04-01至2024-05-01 搭建可视化平台系统
具备条件
1.硬件条件:阿里云服务器一台、windows笔记本电脑。
2.软件条件:完整的Python、Java、大数据开发环境如jdk1.8、maven、mysql、vmvare、pycharm、idea、anaconda3。
3.知识储备条件:github开源库、黑马大数据相关实战项目教程、CSDN技术博客、实习经验
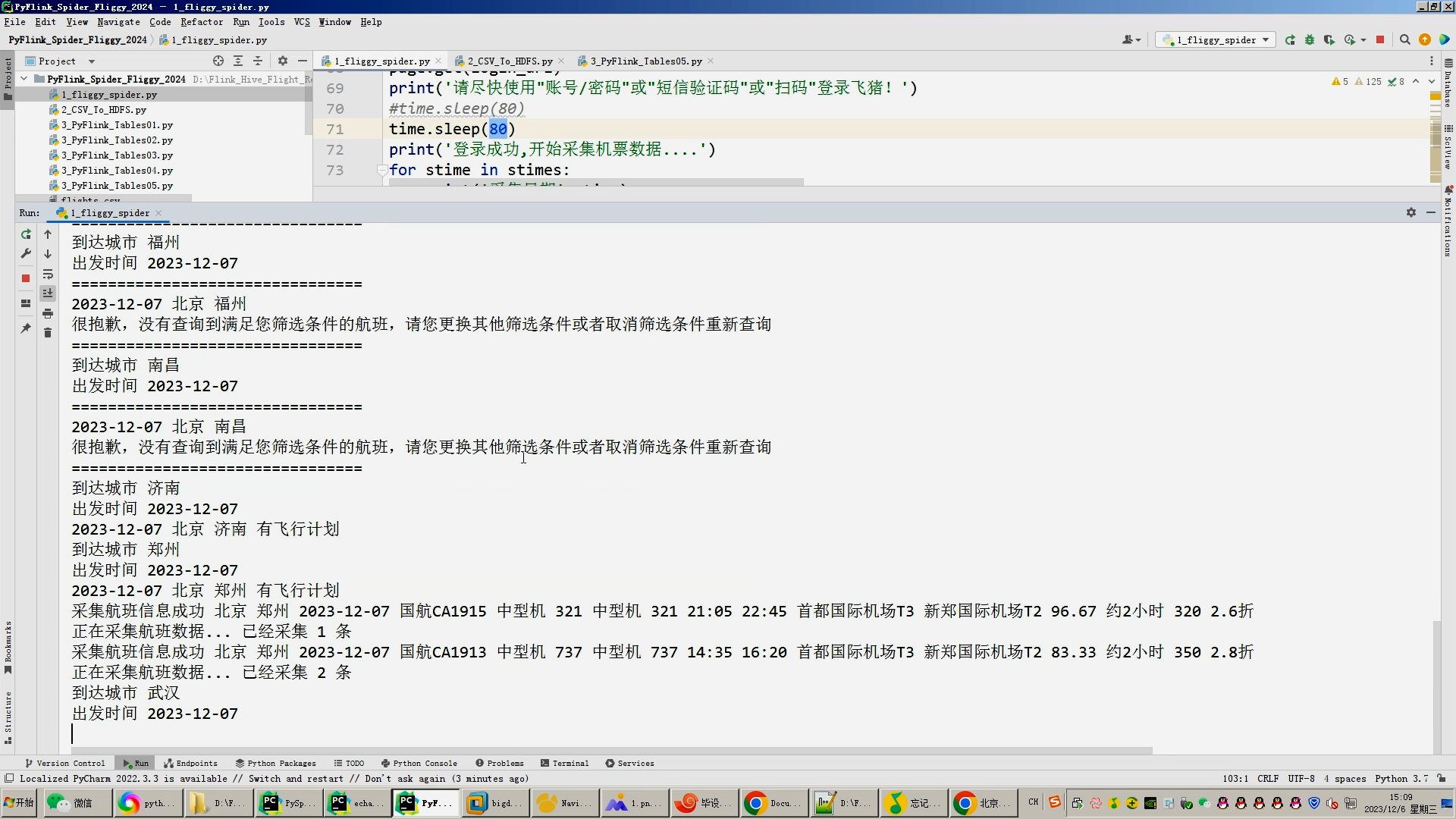
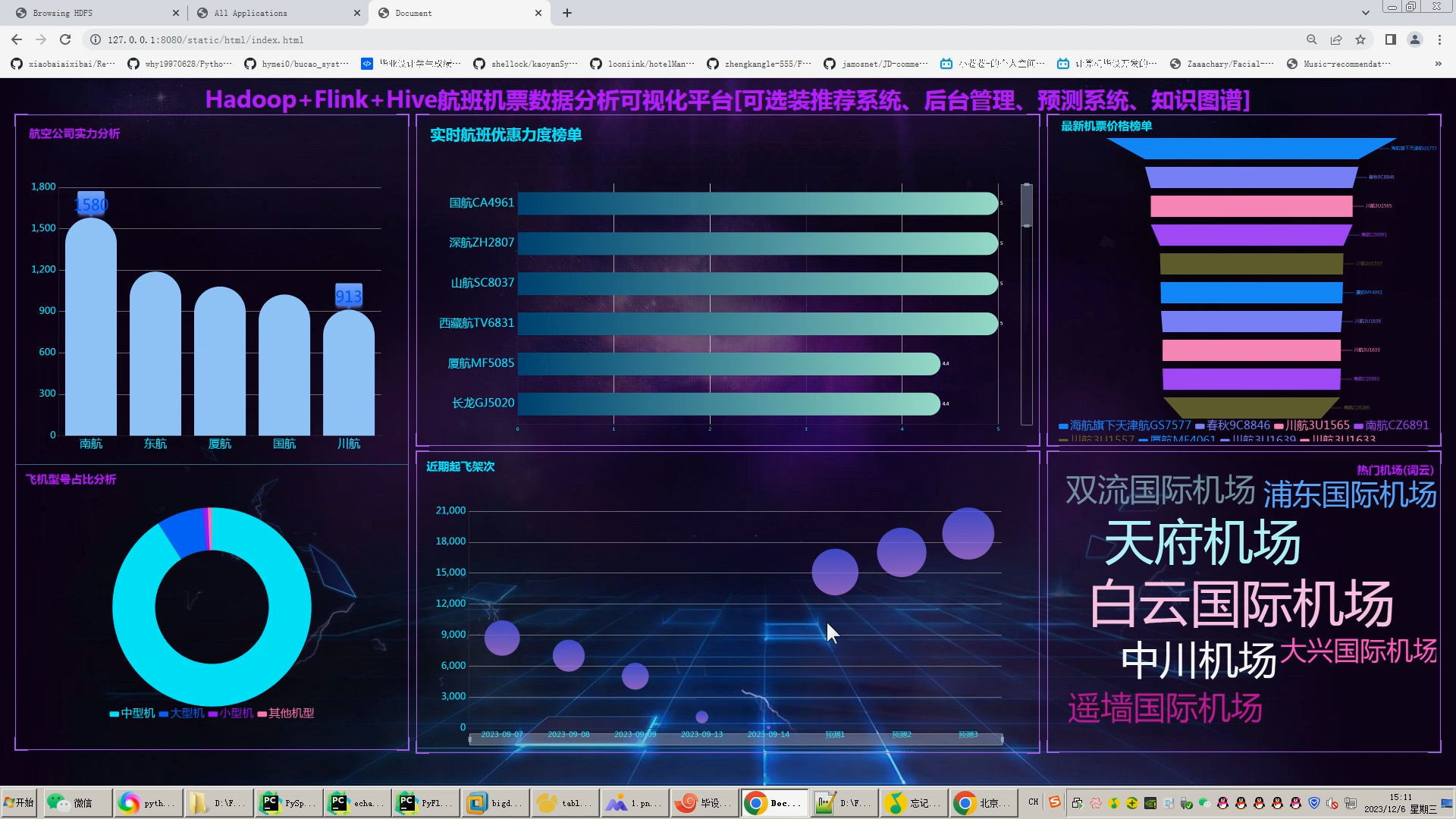
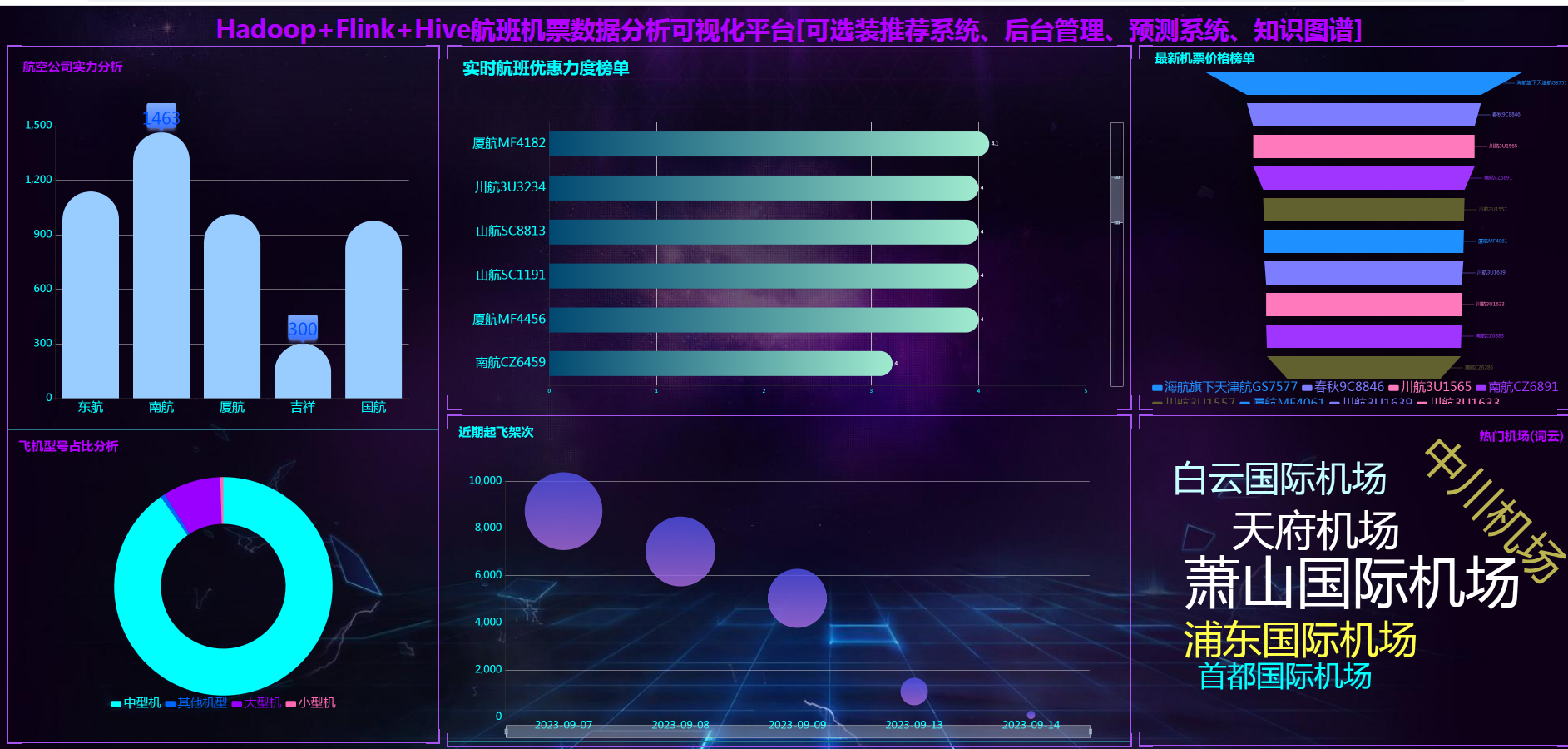
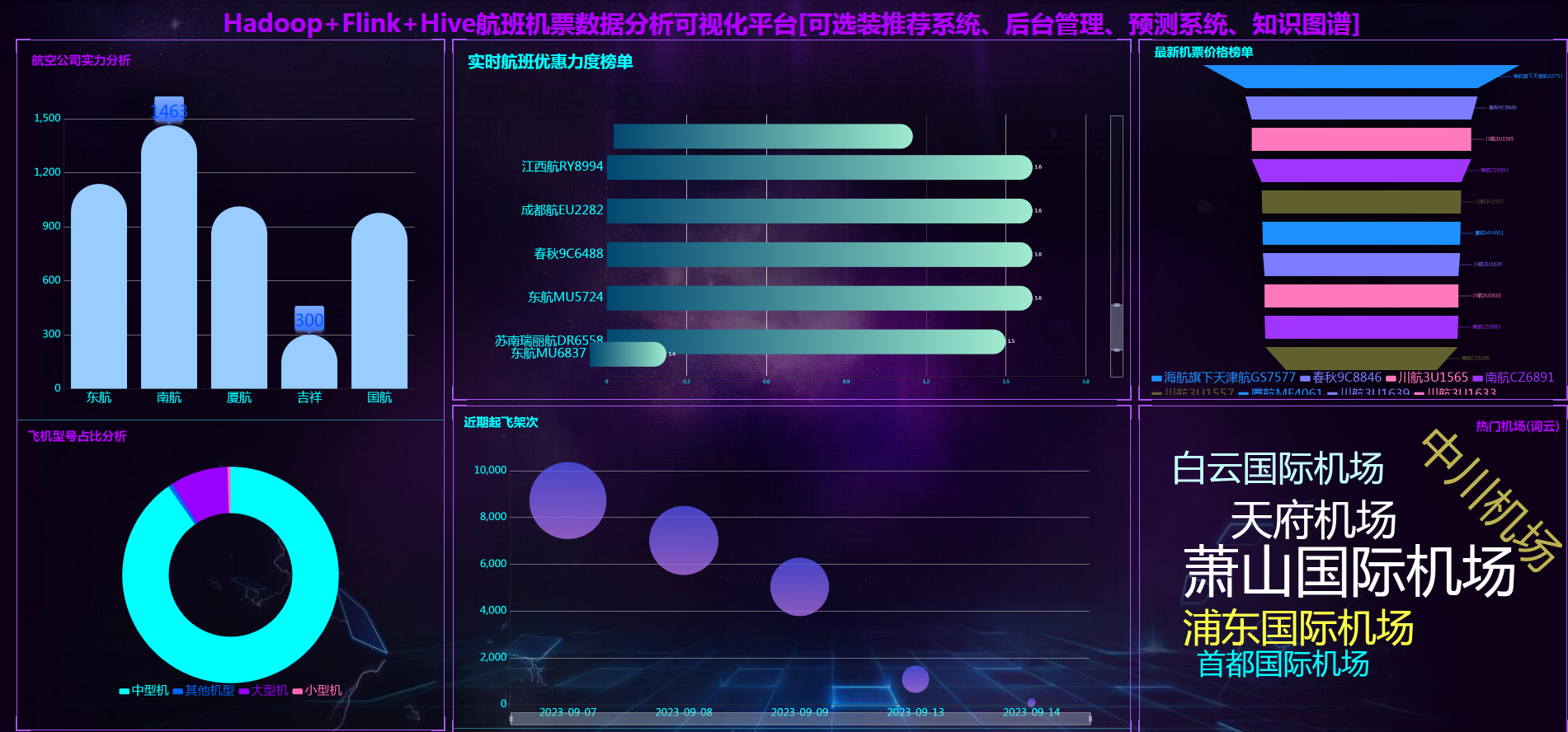
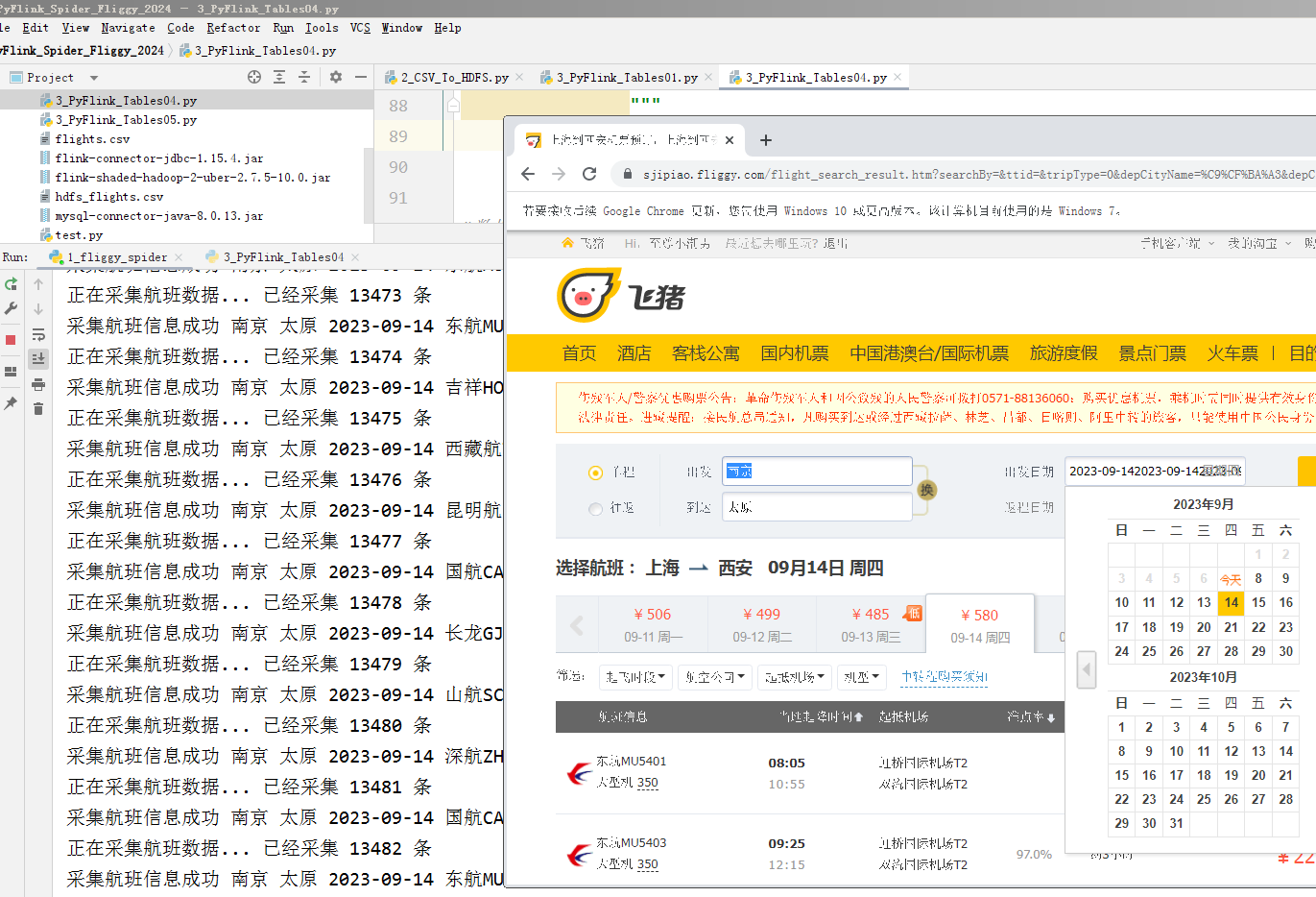

核心算法代码分享如下:
#使用PySpark完成部分机票指标分析
from pyspark.sql.types import StringType, StructField, IntegerType, DoubleType, StructType
from pyspark.sql.functions import col
from pyspark.sql import SparkSession
csv_format = 'com.databricks.spark.csv'
mysql_url = "jdbc:mysql://bigdata:3306/Flink_Fliggy_Flight"
prop = {'user': 'root', 'password': '123456', 'driver': "com.mysql.jdbc.Driver"}
# 1.创建SparkSession
spark = SparkSession.builder.appName("tables01_task").getOrCreate()
fields = [
StructField("start_city", StringType(), True),
StructField("end_city", StringType(), True),
StructField("stime", StringType(), True),
StructField("airline_name", StringType(), True),
StructField("flight_info", StringType(), True),
StructField("flight_type1", StringType(), True),
StructField("flight_type2", StringType(), True),
StructField("setup_time", StringType(), True),
StructField("arr_time", StringType(), True),
StructField("start_airport", StringType(), True),
StructField("arr_airport", StringType(), True),
StructField("ontime_rate", IntegerType(), True),
StructField("flight_total_time", StringType(), True),
StructField("price", IntegerType(), True),
StructField("price_desc", StringType(), True),
StructField("flight_company", StringType(), True),
StructField("flight_type3", StringType(), True),
StructField("setup_time_math", DoubleType(), True),
StructField("arr_time_math", DoubleType(), True),
StructField("arr_time2", StringType(), True),
StructField("start_airport_simple", StringType(), True),
StructField("arr_airport_simple", StringType(), True),
StructField("flight_total_time_math", IntegerType(), True),
StructField("price_desc_math", DoubleType(), True),
]
schema= StructType(fields)
# 2.读取本地文件路径
# flights_data = spark.read.format(csv_format).options( ending='utf-8').load(
# "hdfs://bigdata:9000/flink_fliggy_flight/flight/hdfs_flights.csv")
flights_data=spark.read.option("header", "false").schema(schema).csv("hdfs://bigdata:9000/flink_fliggy_flight/flight/hdfs_flights.csv")
# 3.创建临时表
flights_data.createOrReplaceTempView("ods_flight")
# 4.工作经验与薪水的关系
tables01_sql='''
select distinct airline_name,price_desc_math,price_desc,stime
from ods_flight
order by stime desc,price_desc_math asc
limit 30
'''
spark.sql(tables01_sql).write.jdbc(mysql_url, 'tables01', 'overwrite', prop)
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











