







| 题目名称:基于大数据的美食推荐系统的设计与实现 | |||||
| 课 题 性 质 | 课 题 来 源 | ||||
| 是否联系实际 | 是 | 自选课题 | |||
| 毕业设计(论文)和 毕业实习主要场所 | 校外 | 毕业设计(论文) 周数 | 24 | ||
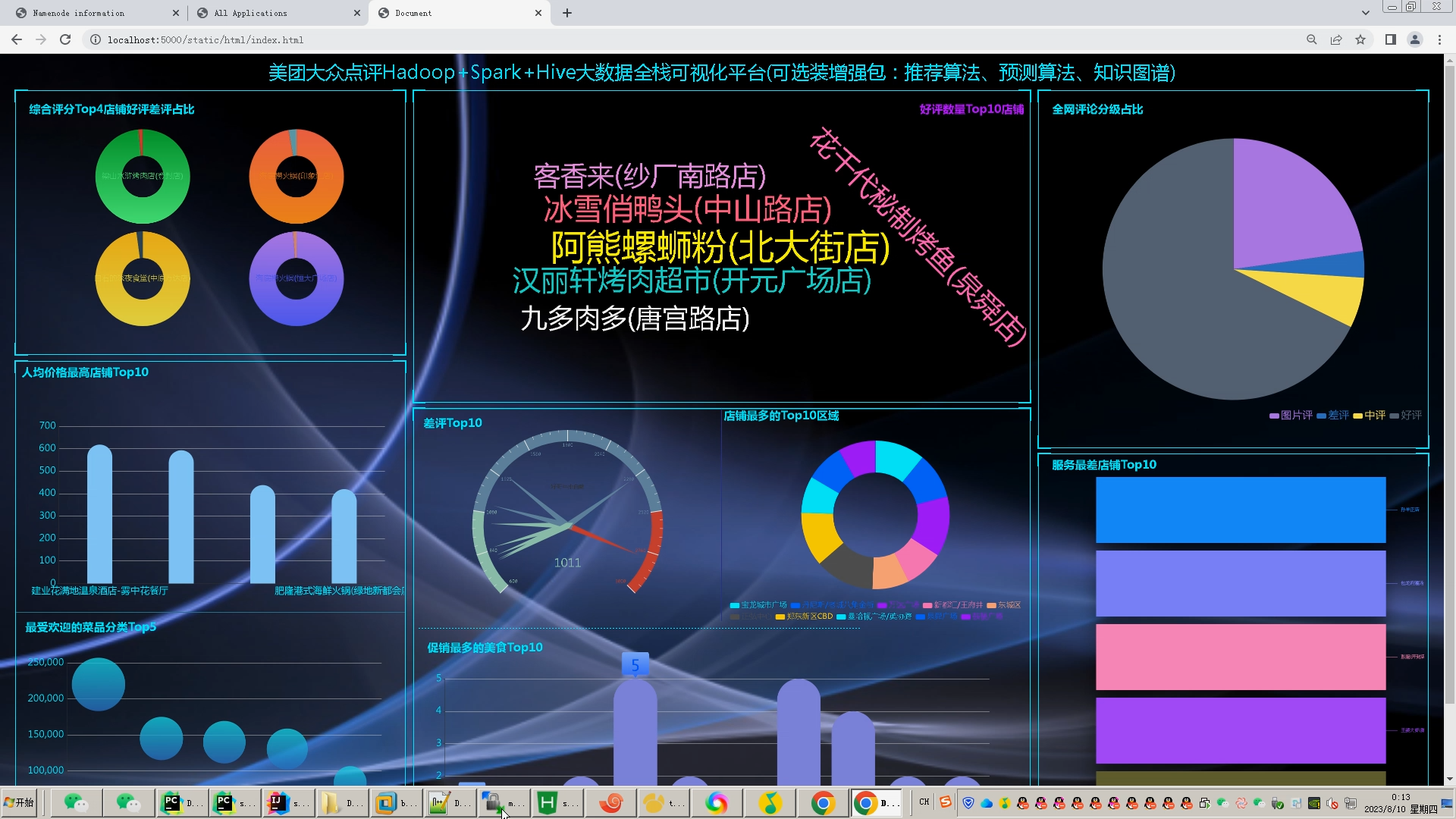
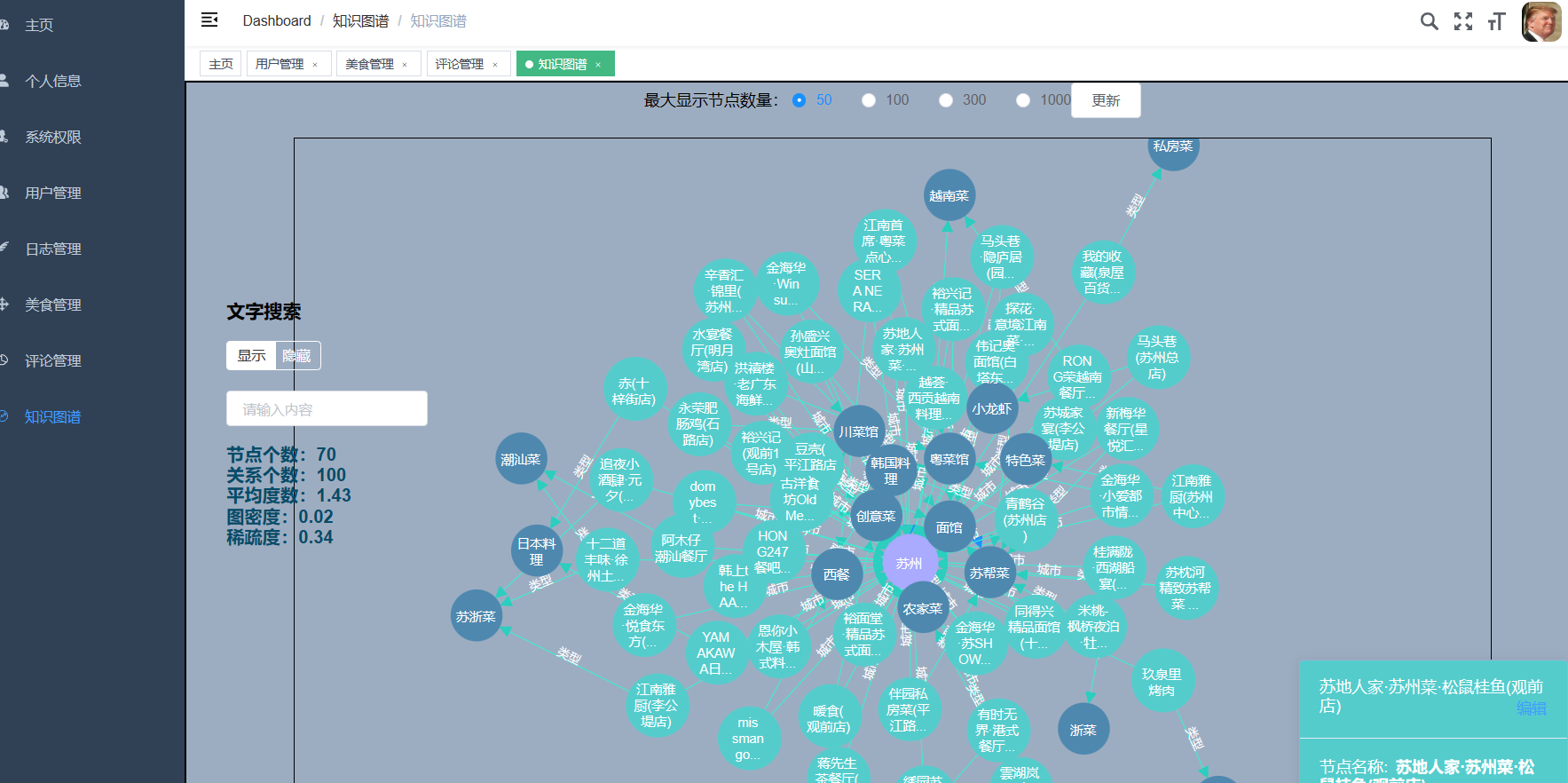
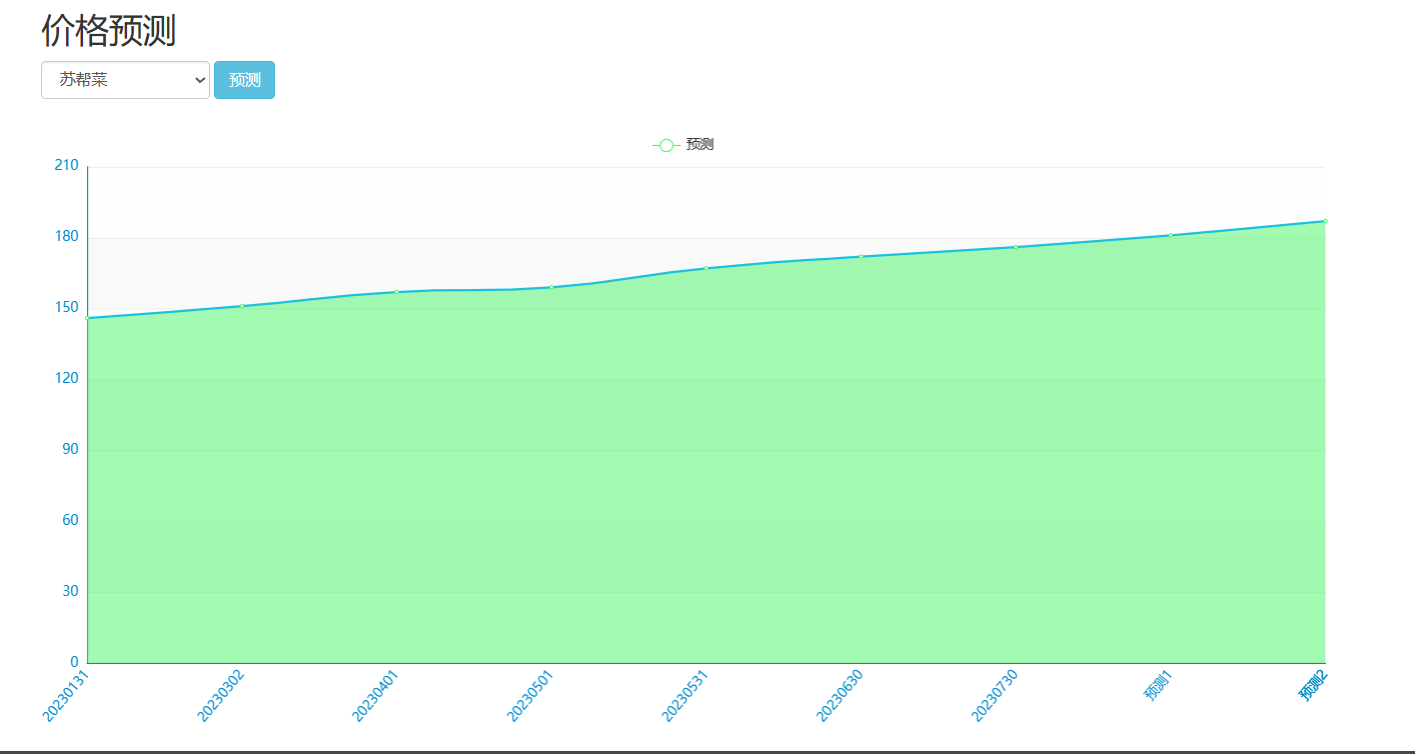
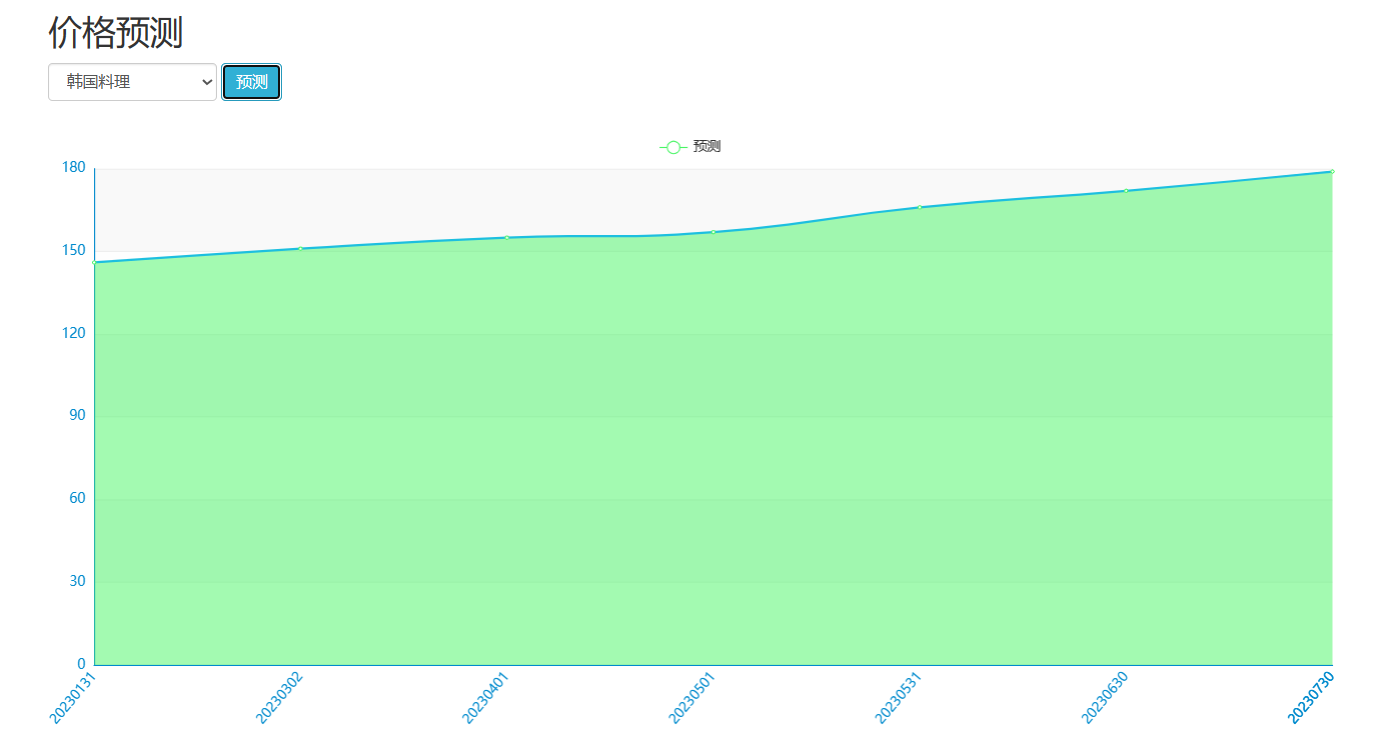
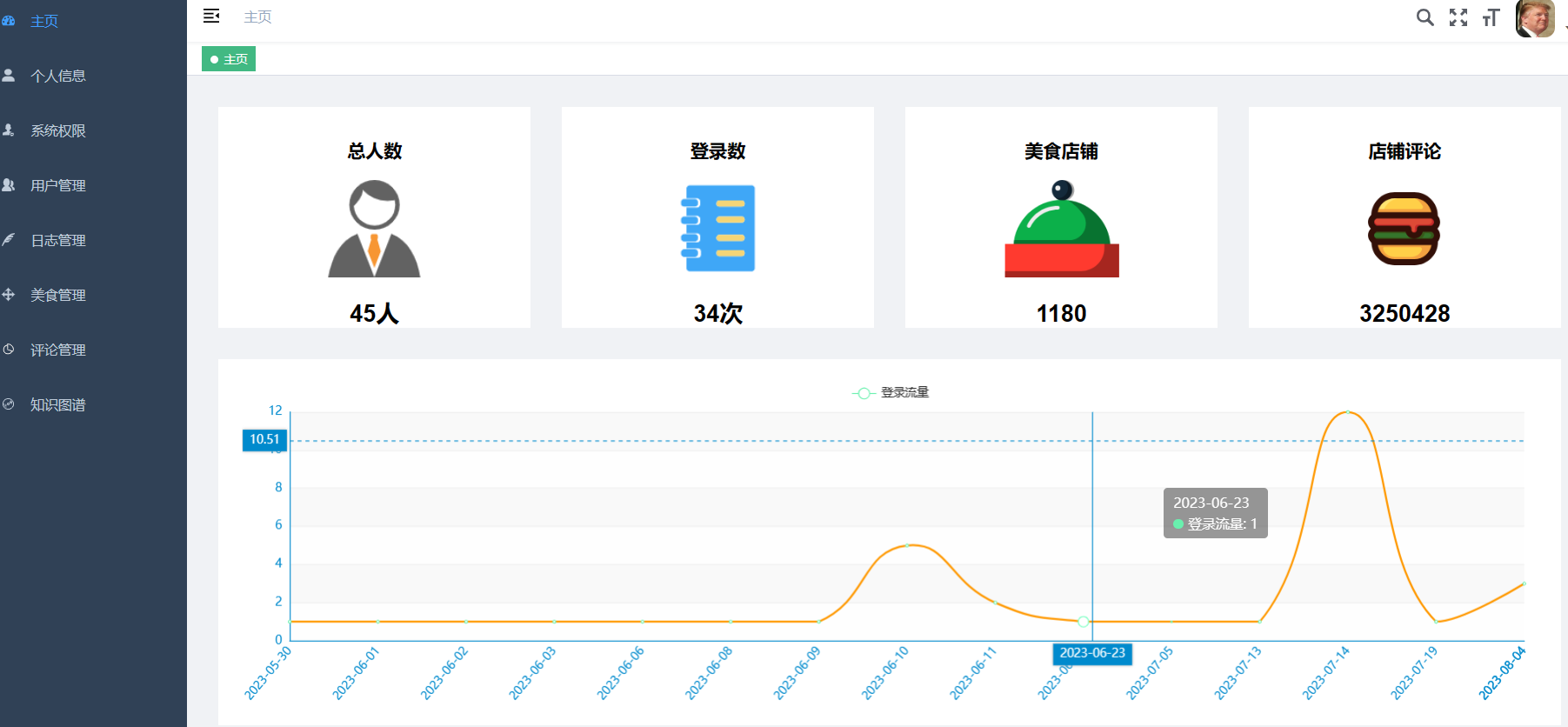
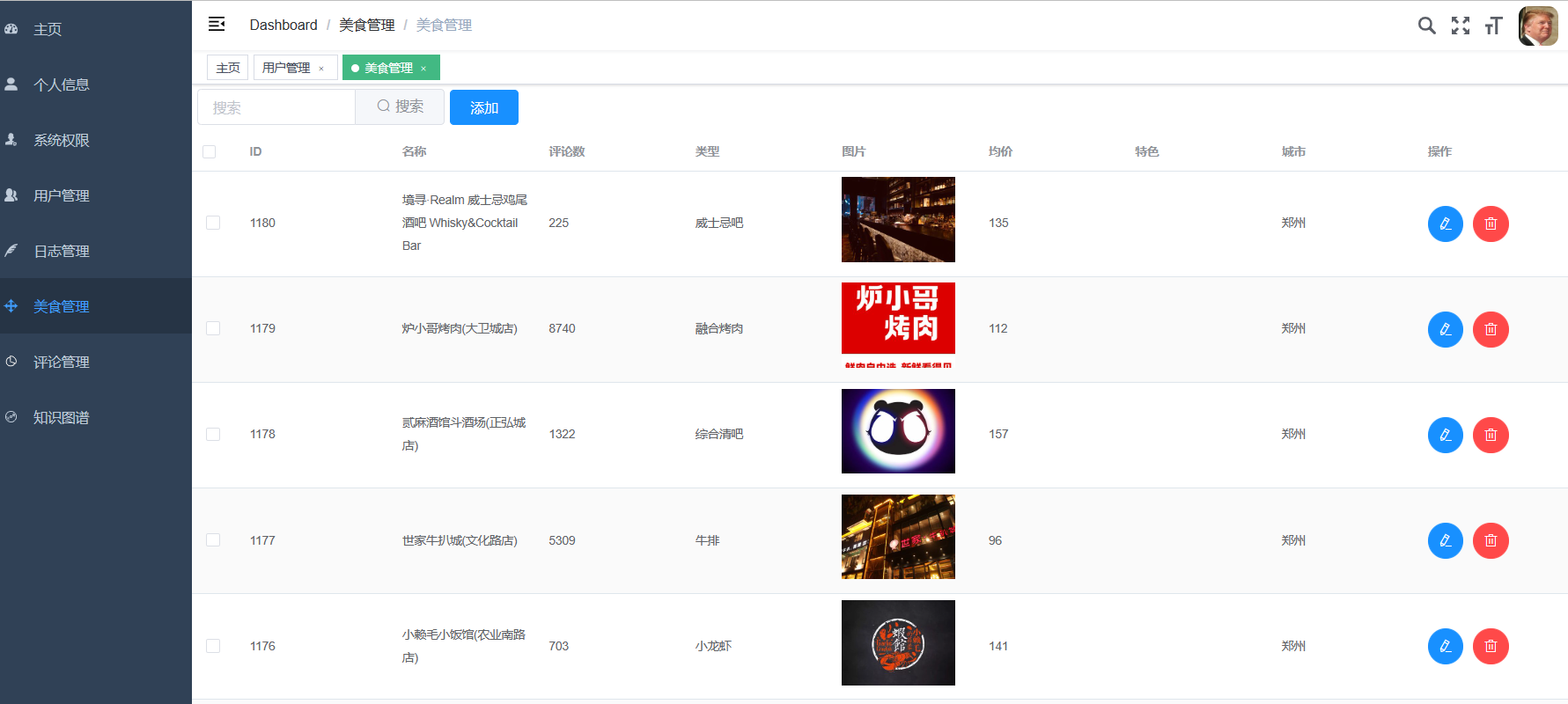
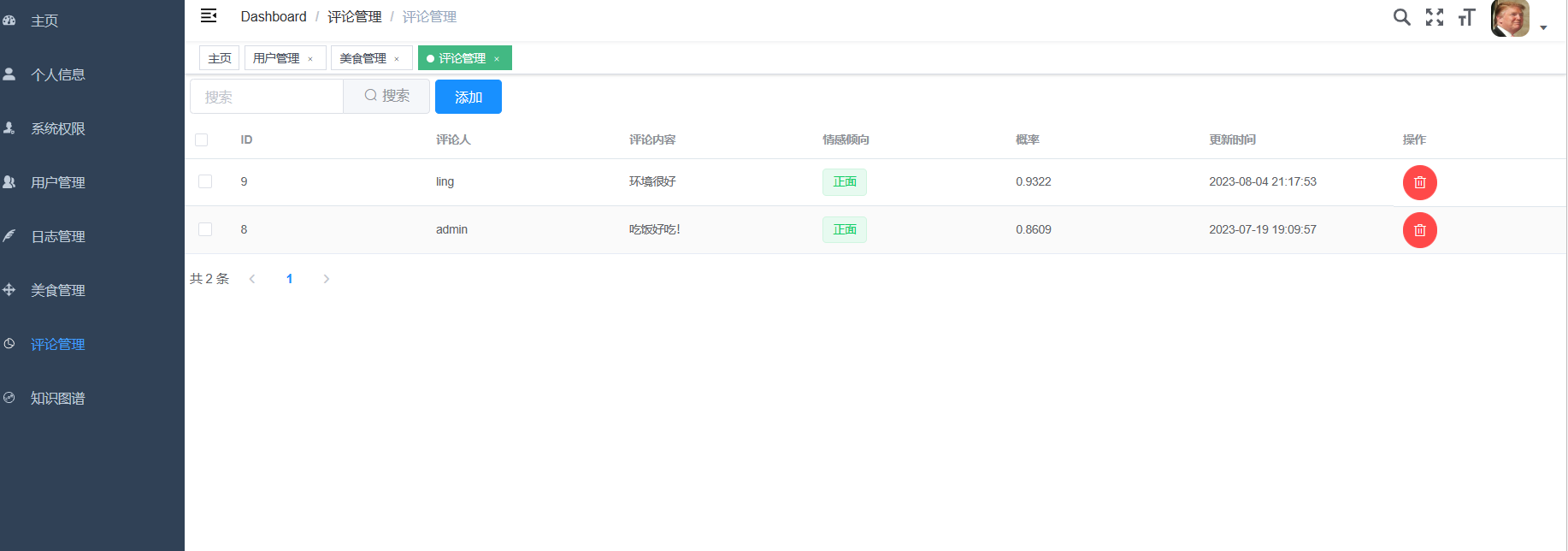
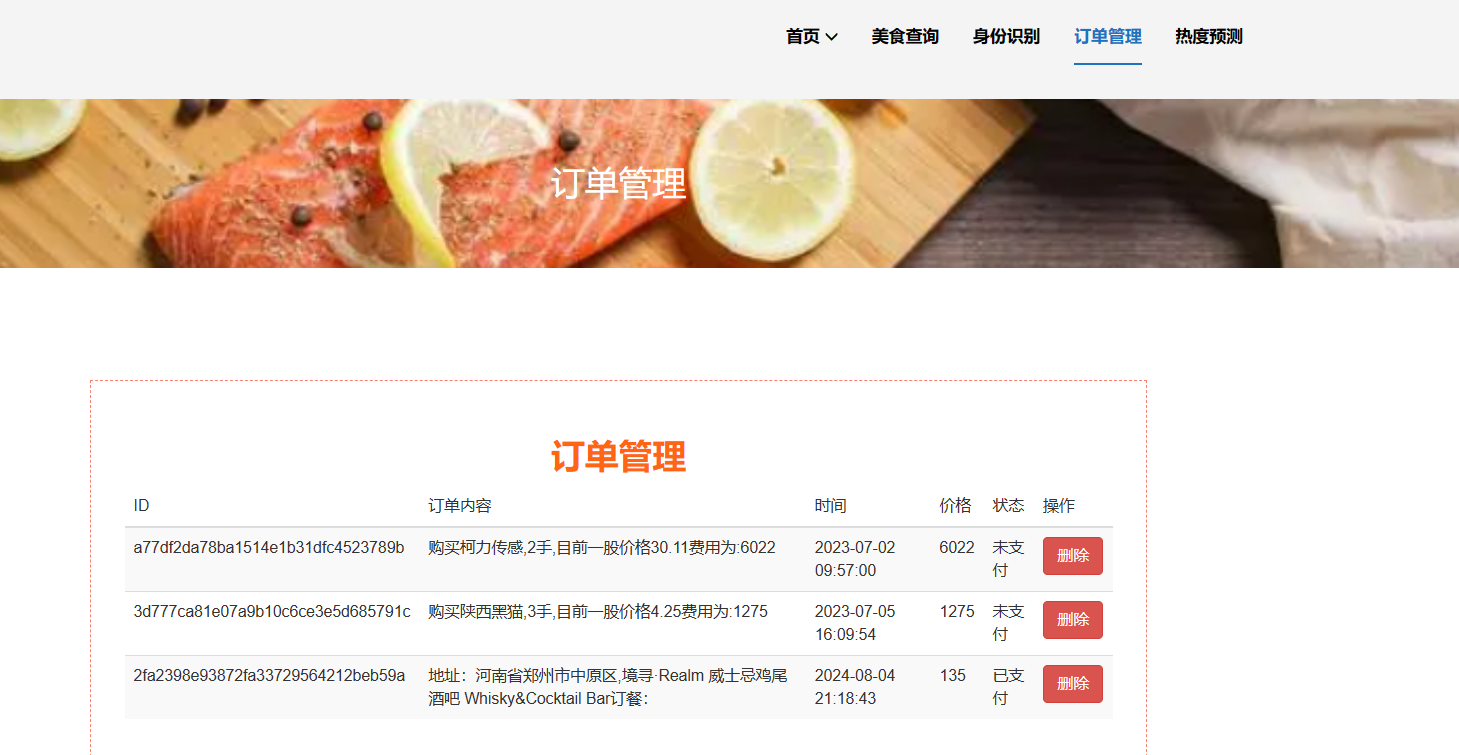
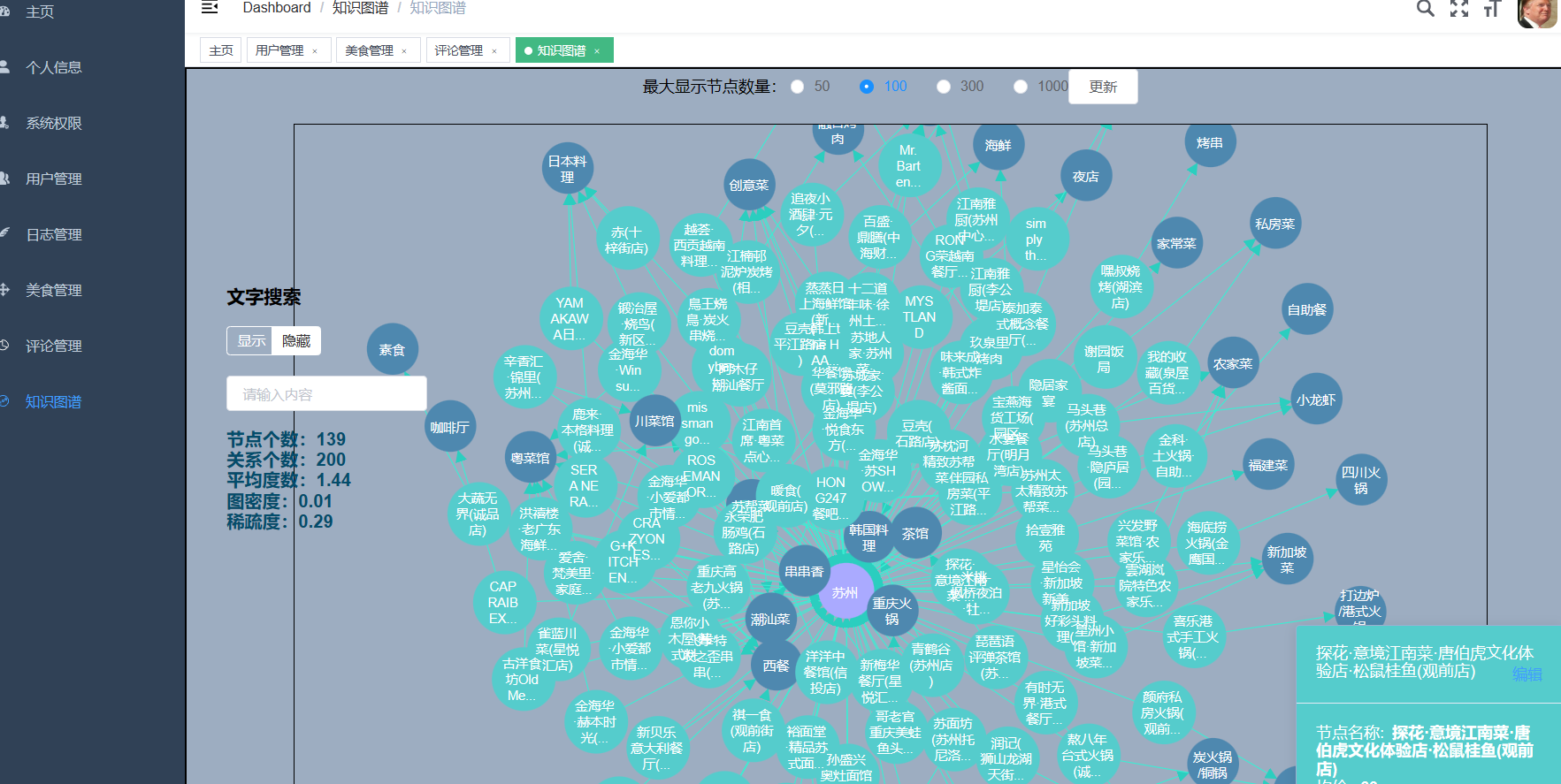
| 课题主要研究内容及预期达到的目标: 本课题旨在通过设计一种基于大数据技术的美食推荐系统帮助解决本地美食的推广与智能推荐问题。预期用户可以通过网站首页进行美食搜索、个性化美食推荐、支付宝下单、美食点评等功能。管理员能够登录后台管理系统进行美食管理、美食知识图谱查看、评价管理等数据维护。Python爬虫可以采集美团约1W条本地美食数据。用户可以直观观看可视化统计大屏。 | |||||
| 课题研究的工作基础或实验条件: 工作基础:使用Python爬虫采集美团APP本地美食数据作为基础数据集 开发环境:IDEA、navicat_for_mysql、jdk1.8、maven、mysql、nodejs | |||||
| 课题所涉及的知识: 注意:可以写开发所用的框架、开发所用的语言、开发所用的数据库以及使用到的其他专业知识(如推荐系统、深度学习)等。 样例:前端开发框架采用Vue.js和ElementUI,后端开发框架采用SpringBoot,数据库采用MySQL,前端开发语言主要采用HTML、JavaScript,后端开发语言主要采用Java,使用神经网络混合推荐算法进行个性化美食推荐。 | |||||
| 专业核心组意见: 专业核心组组长签字: 年 月 日 | 学院审批意见: 教学院长签字: 年 月 日 | ||||


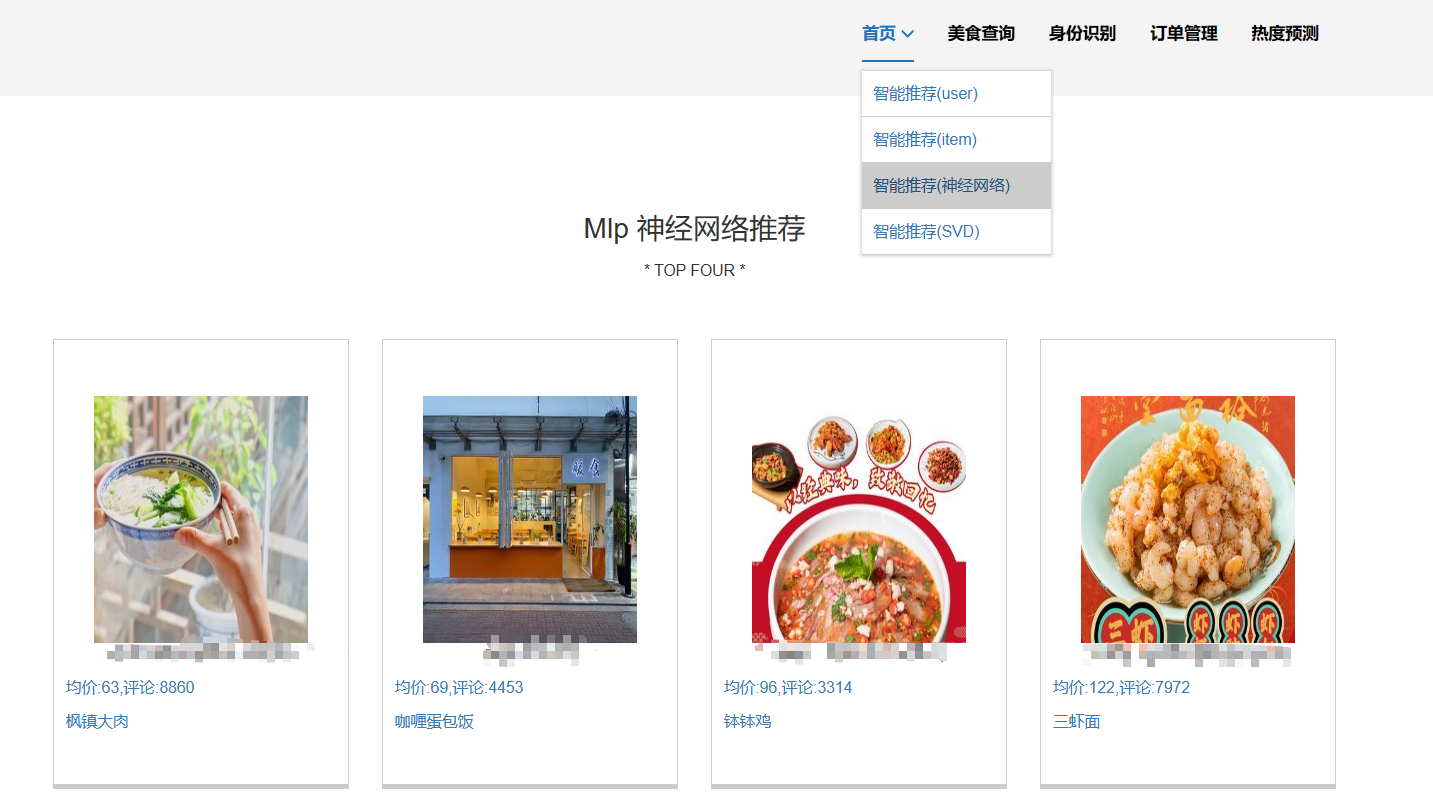
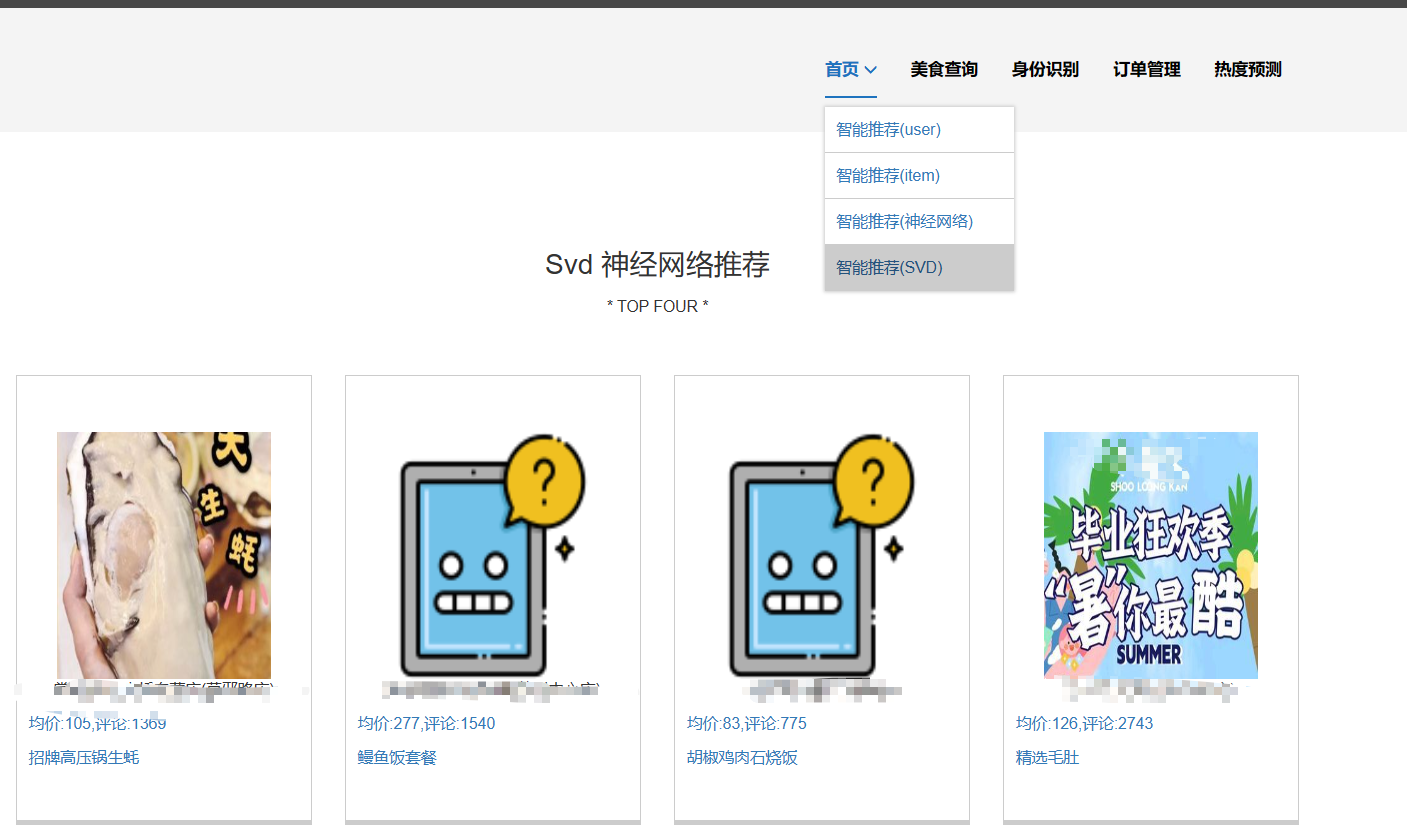
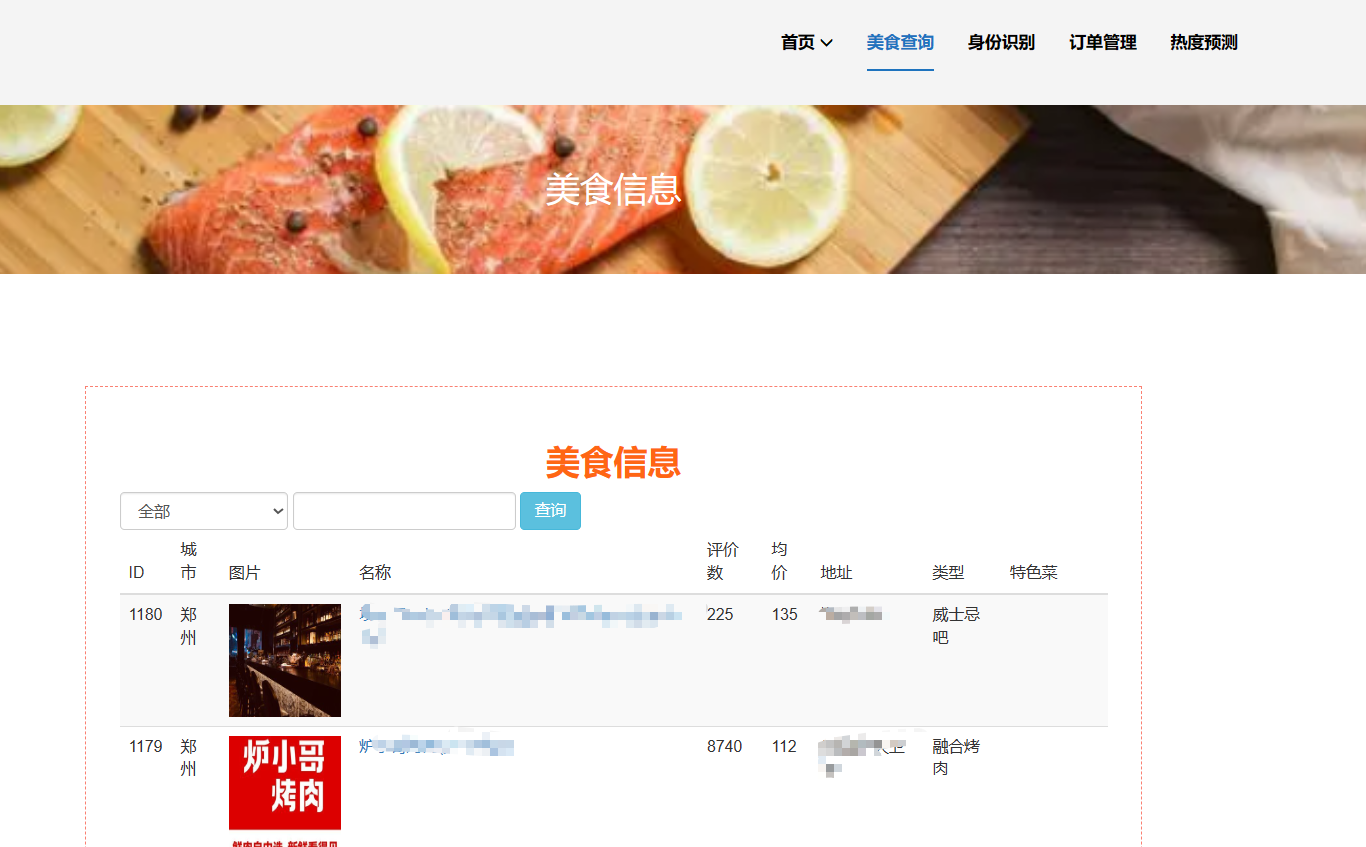
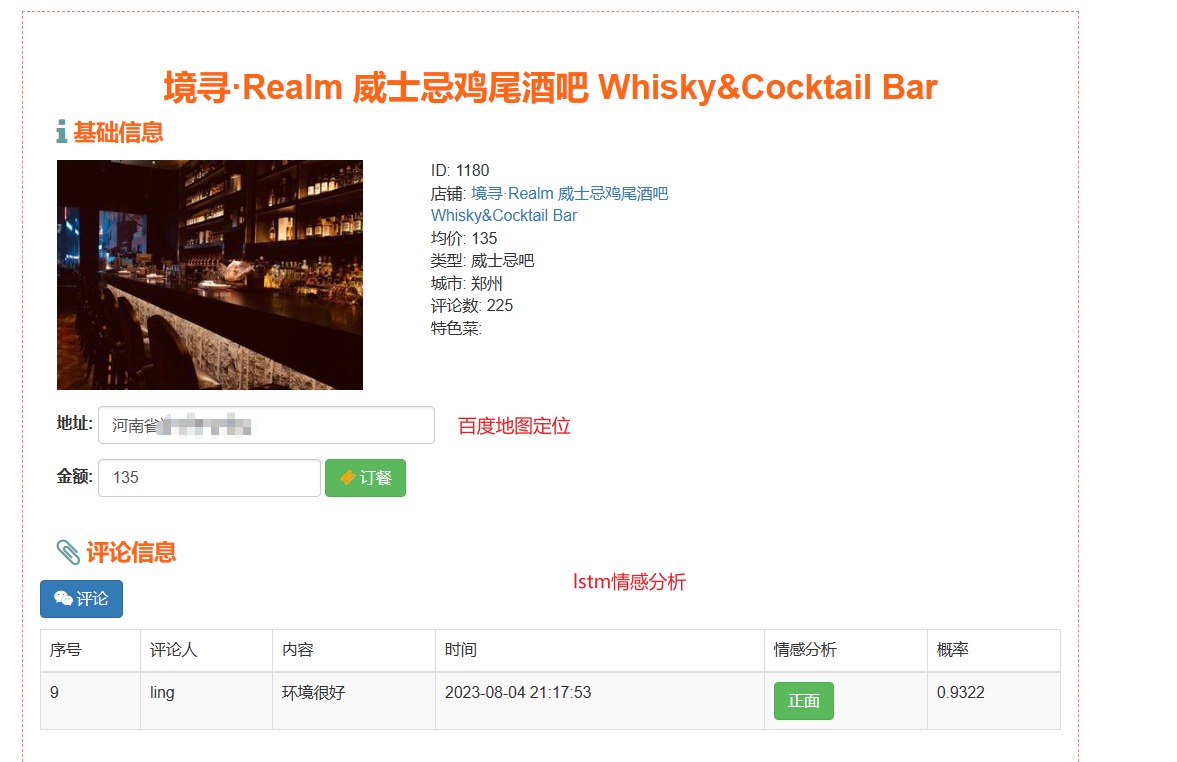
核心算法代码分享如下:
# coding=utf-8
# 基于物品的协同过滤推荐
import random
import sys
import math
from operator import itemgetter
import pymysql
from rate import Rate
import db
"""
"""
class ItemBasedCF():
# 初始化参数
def __init__(self):
self.n_sim_movie = 8
self.n_rec_movie = 4
self.trainSet = {}
self.testSet = {}
self.movie_sim_matrix = {}
self.movie_popular = {}
self.movie_count = 0
print('Similar movie number = %d' % self.n_sim_movie)
print('Recommneded movie number = %d' % self.n_rec_movie)
def get_dataset(self, pivot=0.75):
trainSet_len = 0
testSet_len = 0
# sql = ' select * from tb_rate'
results = db.session.query(Rate).all()
# print(results)
for item in results:
user, movie, rating = item.uid, item.iid, item.rate
self.trainSet.setdefault(user, {})
self.trainSet[user][movie] = rating
trainSet_len += 1
self.testSet.setdefault(user, {})
self.testSet[user][movie] = rating
testSet_len += 1
# cnn.close()
# db.session.close()
print('Split trainingSet and testSet success!')
print('TrainSet = %s' % trainSet_len)
print('TestSet = %s' % testSet_len)
# 读文件,返回文件的每一行
def load_file(self, filename):
with open(filename, 'r') as f:
for i, line in enumerate(f):
if i == 0: # 去掉文件第一行的title
continue
yield line.strip('\r\n')
print('Load %s success!' % filename)
# 计算电影之间的相似度
def calc_movie_sim(self):
for user, movies in self.trainSet.items():
for movie in movies:
if movie not in self.movie_popular:
self.movie_popular[movie] = 0
self.movie_popular[movie] += 1
self.movie_count = len(self.movie_popular)
print("Total movie number = %d" % self.movie_count)
for user, movies in self.trainSet.items():
for m1 in movies:
for m2 in movies:
if m1 == m2:
continue
self.movie_sim_matrix.setdefault(m1, {})
self.movie_sim_matrix[m1].setdefault(m2, 0)
self.movie_sim_matrix[m1][m2] += 1
print("Build co-rated users matrix success!")
# 计算电影之间的相似性 similarity matrix
print("Calculating movie similarity matrix ...")
for m1, related_movies in self.movie_sim_matrix.items():
for m2, count in related_movies.items():
# 注意0向量的处理,即某电影的用户数为0
if self.movie_popular[m1] == 0 or self.movie_popular[m2] == 0:
self.movie_sim_matrix[m1][m2] = 0
else:
self.movie_sim_matrix[m1][m2] = count / math.sqrt(self.movie_popular[m1] * self.movie_popular[m2])
print('Calculate movie similarity matrix success!')
# 针对目标用户U,找到K部相似的电影,并推荐其N部电影
def recommend(self, user):
K = self.n_sim_movie
N = self.n_rec_movie
rank = {}
if user > len(self.trainSet):
user = random.randint(1, len(self.trainSet))
watched_movies = self.trainSet[user]
for movie, rating in watched_movies.items():
for related_movie, w in sorted(self.movie_sim_matrix[movie].items(), key=itemgetter(1), reverse=True)[:K]:
if related_movie in watched_movies:
continue
rank.setdefault(related_movie, 0)
rank[related_movie] += w * float(rating)
return sorted(rank.items(), key=itemgetter(1), reverse=True)[:N]
# 产生推荐并通过准确率、召回率和覆盖率进行评估
def evaluate(self):
print('Evaluating start ...')
N = self.n_rec_movie
# 准确率和召回率
hit = 0
rec_count = 0
test_count = 0
# 覆盖率
all_rec_movies = set()
for i, user in enumerate(self.trainSet):
test_moives = self.testSet.get(user, {})
rec_movies = self.recommend(user)
for movie, w in rec_movies:
if movie in test_moives:
hit += 1
all_rec_movies.add(movie)
rec_count += N
test_count += len(test_moives)
precision = hit / (1.0 * rec_count)
recall = hit / (1.0 * test_count)
coverage = len(all_rec_movies) / (1.0 * self.movie_count)
print('precisioin=%.4f\trecall=%.4f\tcoverage=%.4f' % (precision, recall, coverage))
def rec_one(self,userId):
print('推荐一个')
rec_movies = self.recommend(userId)
# print(rec_movies)
return rec_movies
# 推荐算法接口
def recommend(userId):
itemCF = ItemBasedCF()
itemCF.get_dataset()
itemCF.calc_movie_sim()
reclist = []
recs = itemCF.rec_one(userId)
return recs
if __name__ == '__main__':
param1 = sys.argv[1]
# param1 = "1"
result = recommend(int(param1))
list = []
for r in result:
list.append(dict(iid=r[0], rate=r[1]))
print(list)















 948
948

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











