







温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
《Python+大模型微博舆情分析》开题报告
一、选题背景与意义
随着互联网技术的飞速发展,社交媒体平台已成为人们表达意见、分享情感和交流信息的重要渠道。微博作为中国最具影响力的社交媒体平台之一,每天产生海量的用户生成内容(UGC),这些数据蕴含着丰富的社会舆情和情感倾向。舆情分析,作为自然语言处理(NLP)领域的一个重要分支,旨在从文本数据中自动提取和识别主观信息和情感倾向。通过对微博数据进行舆情分析,可以深入了解公众对某一事件或话题的态度和情绪,为政府、企业和研究机构提供科学的决策支持。
然而,微博数据的海量性和复杂性给舆情分析带来了巨大挑战。传统的舆情分析方法在处理大规模数据时效率较低,且准确性有待提升。近年来,随着深度学习技术的快速发展,大模型(如BERT、GPT等)在自然语言处理任务中表现出色,为微博舆情分析提供了新的解决方案。Python作为一种高效的编程语言,结合大模型和相应的框架(如Flask或Django),为开发微博舆情分析系统提供了极大的便利。
本研究旨在开发一个基于Python和大模型的微博舆情分析系统,通过自动化的数据抓取、情感分类和情感趋势分析,实现对微博舆情的实时监控和深度洞察,为政府、企业和学术界提供有价值的参考。
二、研究内容与方法
2.1 研究内容
本研究主要包括以下几个方面:
- 数据抓取与预处理:利用Python编写爬虫程序从微博平台抓取用户发布的相关数据,包括微博内容、评论、转发数和点赞数等。对抓取到的数据进行预处理,包括去重、清洗和标准化,以确保数据的准确性和一致性。
- 情感分析:采用大模型(如BERT)和先进的情感分析算法(如VADER),对微博文本进行情感评分和分类,判断其是正面、负面还是中性的情感。
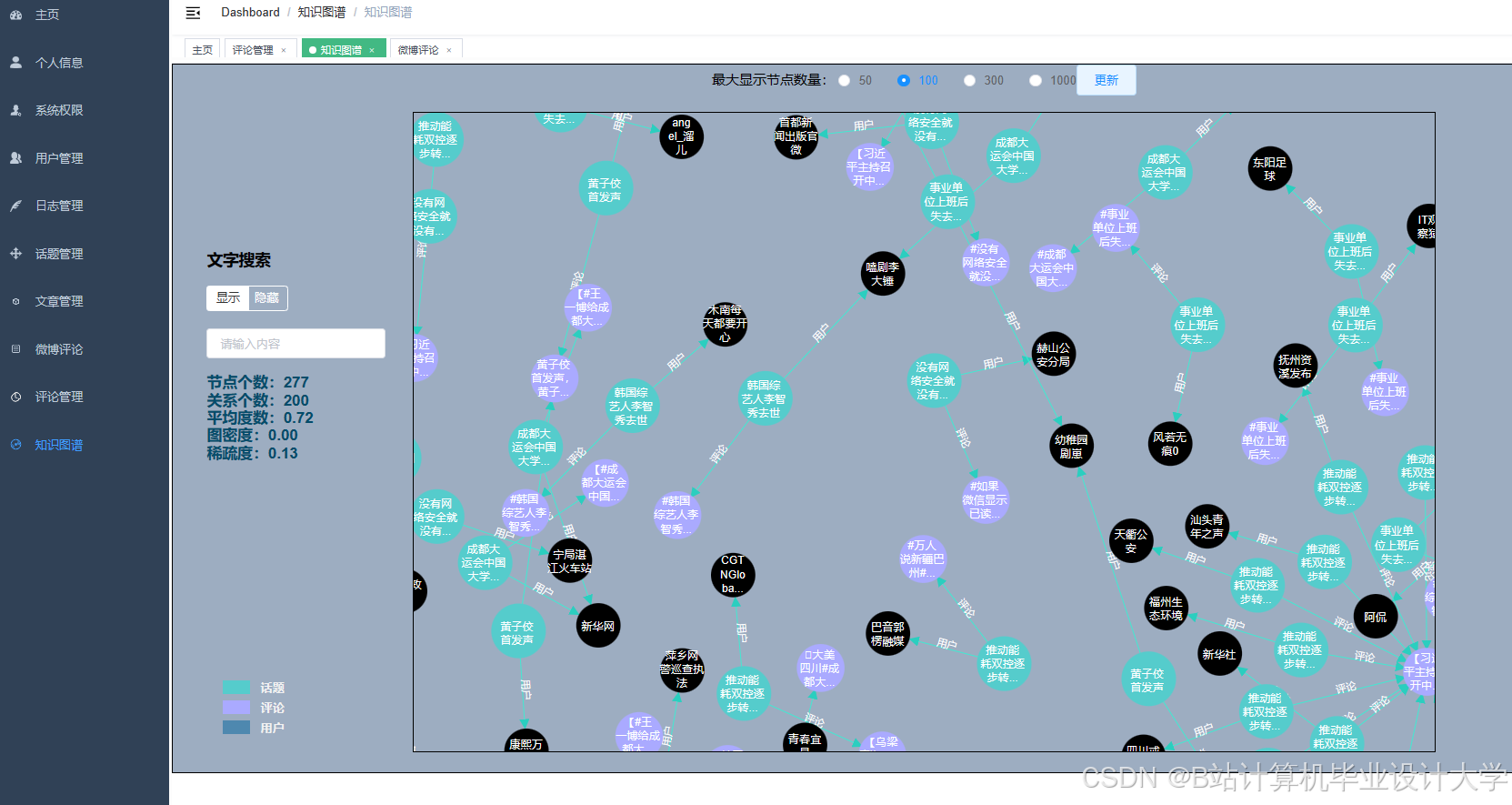
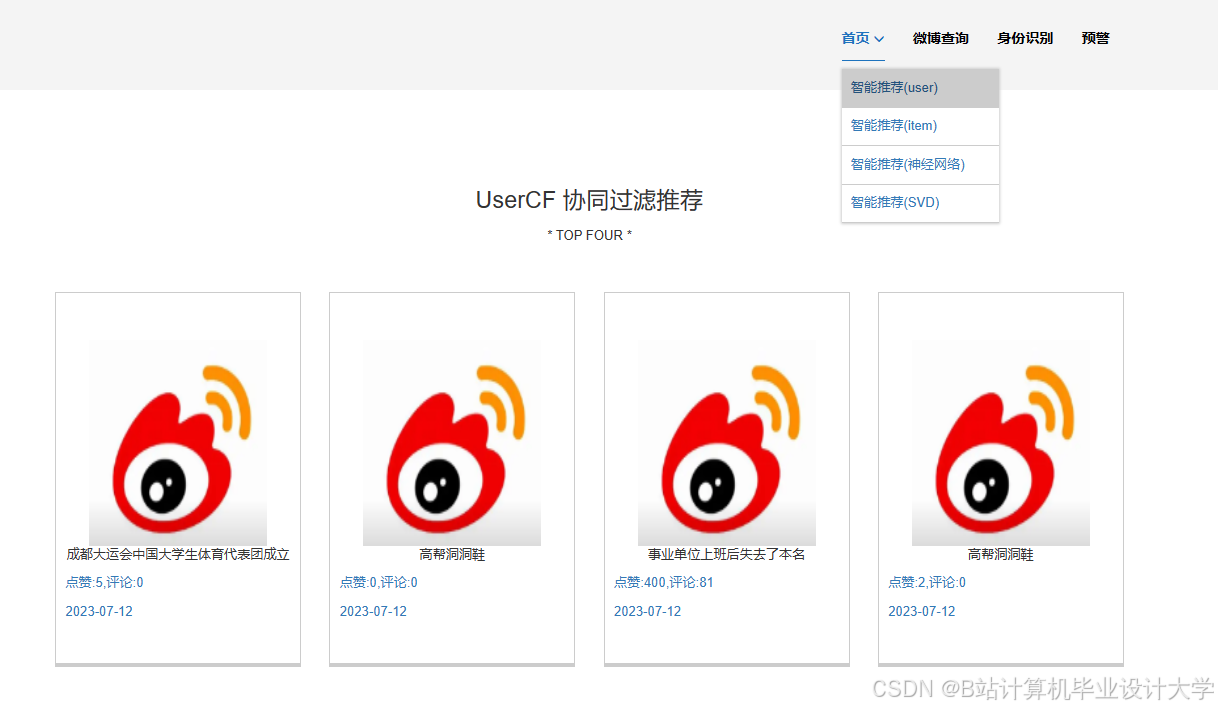
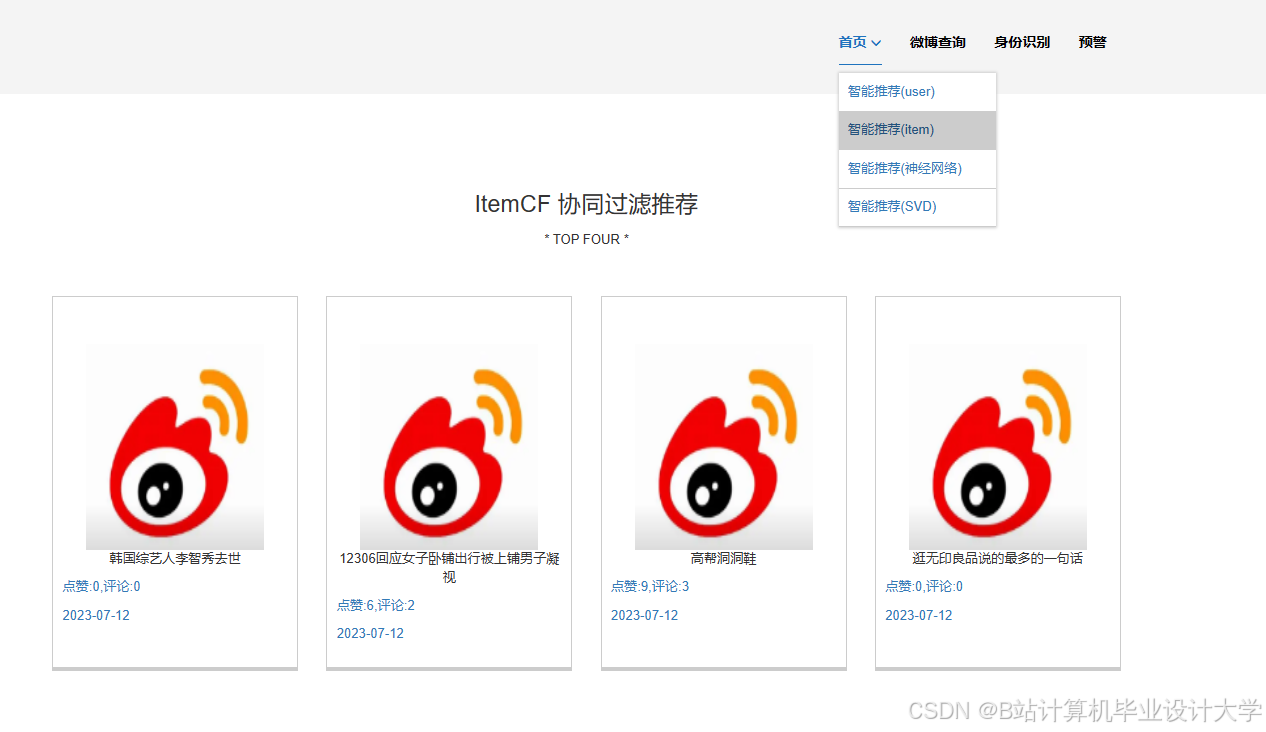
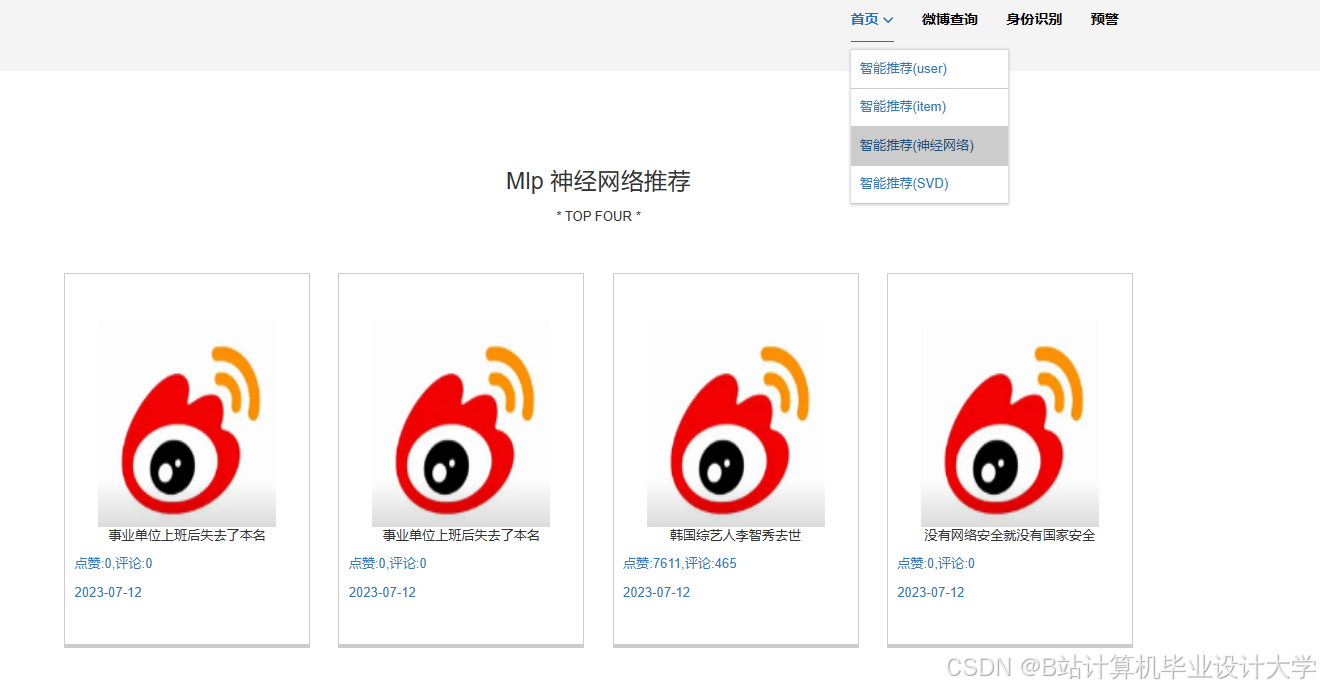
- 结果展示:使用Flask或Django构建Web应用,将分析结果以可视化形式展示给用户。设计用户交互界面和数据展示模块,通过图表(如柱状图、饼图、趋势图等)展示情感分布、舆情趋势等关键信息。
- 系统优化与迭代:根据实际应用中的反馈,持续优化模型以提高准确率。同时,考虑引入新的技术和算法(如多任务学习、持续学习等),进一步提升系统的性能和实用性。
- 文献研究:查阅相关文献,了解现有的微博舆情分析技术和方法,为系统设计提供理论支持。
2.2 研究方法
- 技术选型:选择Python作为开发语言,结合Flask或Django框架、数据库(如MySQL)和NLP库(如jieba、NLTK、TextBlob等)进行开发。
- 系统设计与开发:采用模块化设计思想,将系统划分为数据抓取模块、数据预处理模块、情感分析模块和Web展示模块。分别进行开发,并确保各模块之间的协同工作。
- 系统测试与优化:对实现的系统进行测试,包括功能测试、性能测试和安全测试等。根据测试结果,对系统进行优化和改进,确保系统的稳定性和可靠性。
三、预期成果
本研究预期将开发出一个基于Python和大模型的微博舆情分析系统,该系统能够自动从微博上获取数据,并进行情感分类和情感趋势分析。通过可视化的方式展示分析结果,为政府、企业和学术界提供有价值的参考。该系统具有较高的应用价值,可以帮助政府和企业及时发现舆情危机,制定应对策略;同时也可以为学术界提供实证数据支持,推动舆情分析领域的研究和发展。
四、研究进度安排
- 第1-2周:进行文献调研和需求分析,明确系统的功能需求和非功能需求,形成详细的需求规格说明书。
- 第3-4周:进行技术选型和系统设计,确定系统的整体架构、功能模块和数据库结构等。
- 第5-8周:进行系统开发,实现数据抓取模块、数据预处理模块、情感分析模块和Web展示模块的功能。
- 第9-10周:进行系统测试,包括功能测试、性能测试和安全测试等。同时,准备论文撰写和答辩材料。
五、参考文献
由于实际参考文献在此无法直接列出,但相关研究可以参考以下方向和内容:
- 基于Python的社交媒体舆情分析系统设计与实现。
- 微博大数据舆情分析系统的设计与实现。
- 大模型在自然语言处理任务中的应用。
- 情感分析算法(如VADER、BERT)的原理与应用。
通过本研究,我们将利用Python和深度学习大模型技术,构建一个高效、准确的微博舆情分析系统,为社会各界提供有力的决策支持。


import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout
from tensorflow.keras.utils import to_categorical
# 假设我们有一个CSV文件包含流量数据
# 数据格式:时间戳, 源IP, 目标IP, 源端口, 目标端口, 协议, 数据包长度, 数据包数量, 标签(0表示正常,1表示恶意)
data_path = 'traffic_data.csv'
# 读取数据
df = pd.read_csv(data_path)
# 特征选择(排除时间戳和IP地址)
features = ['source_port', 'destination_port', 'protocol', 'packet_length', 'packet_count']
X = df[features].values
y = df['label'].values
# 数据预处理
# 将协议从文本转换为数值(假设协议只有TCP, UDP, ICMP三种)
protocol_mapping = {'TCP': 0, 'UDP': 1, 'ICMP': 2}
X[:, 2] = [protocol_mapping[protocol] for protocol in df['protocol'].values]
# 数据标准化
scaler = StandardScaler()
X = scaler.fit_transform(X)
# 将标签转换为one-hot编码
y = to_categorical(y)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 构建模型
model = Sequential()
model.add(Dense(64, input_dim=X_train.shape[1], activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(32, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(y_train.shape[1], activation='softmax'))
# 编译模型
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# 训练模型
model.fit(X_train, y_train, epochs=50, batch_size=32, validation_split=0.2)
# 评估模型
loss, accuracy = model.evaluate(X_test, y_test)
print(f'Test Accuracy: {accuracy:.4f}')
# 使用模型进行预测(示例)
sample_data = np.array([[1234, 80, 0, 500, 10]]) # 示例数据(需先经过同样的预处理)
sample_data = scaler.transform(sample_data)
prediction = model.predict(sample_data)
predicted_class = np.argmax(prediction)
print(f'Predicted Class: {predicted_class} (0: Normal, 1: Malicious)')


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











