







温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
作者简介:Java领域优质创作者、CSDN博客专家 、CSDN内容合伙人、掘金特邀作者、阿里云博客专家、51CTO特邀作者、多年架构师设计经验、多年校企合作经验,被多个学校常年聘为校外企业导师,指导学生毕业设计并参与学生毕业答辩指导,有较为丰富的相关经验。期待与各位高校教师、企业讲师以及同行交流合作
主要内容:Java项目、Python项目、前端项目、PHP、ASP.NET、人工智能与大数据、单片机开发、物联网设计与开发设计、简历模板、学习资料、面试题库、技术互助、就业指导等
业务范围:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码编写、论文编写和辅导、论文降重、长期答辩答疑辅导、腾讯会议一对一专业讲解辅导答辩、模拟答辩演练、和理解代码逻辑思路等。
收藏点赞不迷路 关注作者有好处
文末获取源码
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
基于spark的微博访问分析系统设计与实现
摘要
随着信息化的发展, 特别是移动通信和社交网络的迅速发展, 网络己经成为人们交流、 娱乐等活动的主要工具。 互联网的内容越来越丰富, 数据规模也愈加庞大。 作为互联网重要内容之一的微博从诞生到如今, 就以惊人的速度发展着。 新浪微博每日发博量超过一亿条, 如何从庞大的微博数据中发掘出有价值的信息成为时下研究的一个热点。本文设计并实现的微博数据处理系统,在 Spark 等技术基础上完成了海量微博数据的实时查询,有效分类,热点检测等工作,为社交网络分析的相关研究提供了平台支撑。本文的主要工作和贡献如下:
1) 本文以 HBase, ES 为存储索引,Spark 为分布式计算框架, Yarn/Hadoop 为资源调度与计算平台, 用最新的大数据处理技术为构建了一个面向微博的分布式数据处理系统,有效地解决了微博数据查询,微博数据分析与计算的问题。
2) 本文针对微博数据的特点, 以 HBase 和 ES 为基础设计了合理的微博数据存储与查询方案,实现了统一的查询接口。在系统内部打通了各个组件访问数据的通道,使Spark可以访问 HBase和ES的数据,扩展了系统的能力。
3) 在本文的系统上,设计了两个应用,微博分类和热点检测。首先,本文用 SVM算法将微博流实时分为财经、体育、科技、娱乐等类别;其次,本文设计了一种微博热点事件检测的方案,并实现了热词检测,热词聚类,最终检测出微博热点,验证了本系统在处理微博数据方面的能力。
4) 本文的系统有效地支持了其他的相关研究如微博情感分析,评论观点分析,地理位置分析等, 是微博相关研究的共性平台。
关键词: 大数据, 微博, Spark, Hadoop, 热点检测
Design and Implementation of Distributed processing system of
microblog data based on Spark
Abstract
With the development of information technology, especially the rapid development of mobile communication and social networks, Internet has become the main tool for communication, entertainment and other activities. Content on the Internet has become increasingly diverse, increasingly large scale of data. As an important part of the Internet,microblog is developing at an alarming rate from birth to now. Sina microblog produces over one hundred million microblogs a day, how to discover valuable information from the huge data of microblog become a hotspot in research. Building an effective big data processing platform is the foundation to support related research. This microblog data processing system basis on the technology of Spark has complete some work like real-time microblog querying,effective data classification and microblog hotspots detection, is to providing a platform support to related research about social network analysis.
The main contributions of this paper are as follows:
1) In this paper, we use HBase and Elasticsearch for storing and indexing, use Spark as a distributed computing framework, use Hadoop and Yarn as the resource scheduling and computing platform. By these latest big data processing tools, we build a distributed data processing system for microblog, the system has an efficient data indexing and query engine
that supports some of the analysis and computing jobs based on microblog data.
2) According to the characteristics of the microblog data and based on HBase and Elasticsearch, we designed a reasonable microblog data storage and query scheme with a unified query interface. The system open up access of data to the various components, so that the query, the calculation, and the analysis of microblog are more efficient.
3) On the system of this paper, two applications are designed, micro-blog classification and hotspot detection. Firstly, this paper uses SVM algorithm to classify microblog streams into finance and economics, sports, science and technology, entertainment and other categories in real time. Secondly, this paper designs a scheme of microblog hot event detection, and realizes hot word detection, hot word clustering, and finally detects microblog hot spots, which verifies the ability of this system in processing microblog data.
4) The system in this paper effectively supports other related studies, such as sentiment analysis, opinion analysis and geographical location analysis on Weibo, and is a common platform for related studies on Weibo.
Keywords: Big data, Weibo, Spark, Hadoop, hotspot detection
目 录
1 引言 ………………………………………………………………………………*
1.1国内研究动态……………………………………………………………………………*
1.2国外研究动态…………………………………………………………………*
1.3研究的趋势……………………………………………………………………*
2开发环境 ……………………………………………………………………*
2.1开发环境及工具介绍…………………………………………………………*
2.2算法及解决方案…………………………………………………………*
2.3实施方案……………………………………………………………………*
3 技术逻辑 ………………………………………………………………………*
3.1微博分类设计…………………………………………………………………*
3.2热点检查算法设计……………………………………………………………*
3.3热词检测…………………………………………………………………*
6 结束语 …………………………………………………………………………*
致谢 …………………………………………………………………………………*
主要参考文献 ………………………………………………………………………*
附录A ………………………………………………………………………………*
附录B ………………………………………………………………………………*
1 引言
随着信息化的发展,特别是移动通信和社交网络的迅速发展,网络已经成为人们交流、娱乐等活动的主要工具。互联网的内容越来越丰富,数据规模也愈加庞大。作为互联网重要内容之一的微博从诞生到如今,就以惊人的速度发展着。新浪微博每日发博量超过一亿条,如何从庞大的微博数据中发掘出有价值的信息成为时下研究的一个热点。本文设计并实现的微博数据处理系统,在Spark等技术基础上完成了海量微博数据的实时查询,有效分类,热点监测等工作,为社交网络分析的相关研究提供了平台支撑。
1.1国外研究状况
大数据时代的到来,使得原有的数据挖掘方法和 BI (Business Intelligence)工具已不能满足实际需要,计算机科学界迫切需要寻求新的数据挖掘解决方案。2012年 3月,美国白宫发布了其大数据计划,计划历时五年,建立一个可扩展数据管理分析研究中心(SDAV),在整合六个美国国家级实验室和七个大学的科研力量的基础上,开发一套新的数据挖掘系统,利用超级计算机对大数据进行管理和可视化研究。传统的数据挖掘技术已经很难满足如此的需求,最突出的矛盾体现在系统的可扩展性(Scalability)、运行效率(Efficiency)以及对异构(Heterogeneous)数据的处理能力等方面。当前对分布式环境下大数据的分析处理的研究非常必要,发展前景广阔。
对传统的社交网络和微博应用等方面的研究,是最近一两年的热点。国内外这方面的研究主要集中在对Facebook 和 Twitter 的分析上,得到了不少积极成果。总体来看,国外相关的研究主要关注微博用户社区及其用户关系、微博中社会网络结构、特征与规律、微博信息传播、社交网络中的事件分析与话题分析等。
针对社交网络中的事件分析与话题分析,近年来也取得了不少进展。如2011年2月的研究报告表明,微博内容反映的用户情感特征可以用于对某些特定事件进行分析,甚至产生影响!在中文平台上的成果还相对较少,但清华大学、哈工大、北大、北航等课题组和研究团队已在这方面开展了深入研究,并取得了一些卓有成效的工作。
目前针对微博已经有一些分析工具和研究成果。如新浪官方提供的工具知微,该工具免费版提供2000以下转发传播分析;提供可视化的微博传播路径图,传播关键人物分析,转发粉丝属性分析、传播层级比例分析等。再如独到的分析工具,提供可视化的微博传播路径图,传播关键人物、转发粉丝属性分析、传播。层级分析等,与“知微”功能基本相同;还有北大PKUVIS开发的微博可视化分析工具 WeiboEvents,可以根据自己的需求选择各种形状的转发图,并可以自由设置条件对转发者进行过滤。
传播工具所提供的分析维度:
各个分析工具都有自己的特点,有些工具分析维度比较全面的,如知微、独到;有些工具分析工具是针对某一点的,如北大PKUVIS都是针对传播路径图;目前微博传播分析工具所能提供的分析主要是以下几个方面:
1、整体展现:以可视化的表现方式展现微博传播路径,展现关键人物、统计覆盖人群。
2、粉丝属性:性别比例、地域分布、加V认证比例、僵尸粉比例、转发者粉丝数量。
3、转发层级:单次转发、每层级转发趋势。
4、时间分析:转发传播时间趋势图。
5、其他分析:在转发数据分析的基础上,可以延伸设计出许多有趣的角度,比如知微提供的情感值分析,可以测试这条微博的正负能量值。
在大数据处理流程中,最核心的部分就是对于数据信息的分析处理,所以其中所运用到的处理技术就至关重要,“云计算”是大数据处理的基础,也是大数据分析的支撑技术,分布式文件系统为整个大数据提供了底层的数据贮存支撑架构;为了方便数据管理,在分布式文件系统的基础上建立分布式数据库,使访问数据更方便,更高效;为了对不同种类,不同需求的数据进行分析整理得出有益信息,需要一个分布式的计算引擎对数据进行分析和计算,最终利用各种可视化技术将结果呈现给需要的用户。
Google作为大数据应用最为广泛的互联网公司之一,2006年率先提出“云计算”的概念,云计算是一种大规模的分布式模型,通过网络将抽象的、可伸缩的、便于管理的数据能源、服务、存储方式等传递给终端用户,国内的“阿里云”、“百度云”以及国外的Facebook、Google、Amazon、Intel和 IBM等都是云计算的忠实开发者和使用者。
Google内部的各种大数据处理技术和应用平台都是基于云计算,最典型的就是以分布式文件系统GFS、批处理技术MapReduce,分布式数据库 BigTable为代表的大数据处理技术。
受到GFS和 MapReduce启发,Apache开源组织开发了一个云计算平台Hadoop,现在 Hadoop已经发展为一个包括分布式文件系统(Hadoop Distributed File System,HDFS)、分布式数据库(HBase、Cassandra)以及数据分析处理 MapReduce等模块在内的完整生态系统(Ecosystem),Hadoop现已经发展成为目前最流行的大数据处理平台,在很多大公司如 Facebook15、雅虎、IBM被广泛使用。
加州伯克利大学AMP实验室提出了一种基于内存的分布式计算框架 spark17,目标是解决在大规模的特定数据集上的迭代运算或重复查询检索,其声称在某些运算时,速度比MapReduce快百倍以上。Spark 发展迅速,2014年2月,该项目成为Apache 顶级项目,Spark 的用户包括阿里巴巴、Cloudera、Databricks、IBM、英特尔和雅虎。Hadoop的Cloudera (CDH)发行版的默认流处理框架已经替换成了Spark,Mahout 的支持平台也从MapReduce迁移到Spark。Spark 正在成为新一代的分布式计算框架的事实标准。
本研究的主要研究内容是要面向微博的分布式数据处理系统,设计出并搭建出系统,针对系统各个组件进行整合优化,实现高效的查询和计算引擎,以及在该系统上运行几个样例算法,最终达到本研究的研究目标。
首先需要搭建这样一套分布式存储与处理框架,支持大量微博数据的实时查询,查询的内容包括,按关键字查询微博,查询微博的转发树,查询用户信息。查询的条件可以是用户名,日期,关键字,并且可以统计出查询微博集合的地域分布,年龄分布,用户类型分布等统计信息。
其次实现统一的查询接口,各个查询结果整合,统一接口,以便于上层应用的查询。针对微博数据的特点,设计合理的存储与查询方案,配合统一的查询接口,从而实现高效的微博数据查询。
深度整合各组件,使各组件可以方便地互相访问数据。
最后以微博分类和微博热点检测为应用示例,测试系统的查询与计算性能。
1.2国内研究状况
微博从诞生到如今,以惊人的速度发展着,国内最大的两大微博平台新浪和腾讯的注册人数早已超过5亿。CNNIC 第33次中国互联网络发展状况调查统计报告截至2013年12月,我国微博用户规模为2.81亿,网民中微博使用率为45.5%。尤其是在突发和热点事件中,微博的影响规模和传播速度超越了普通博客和传统的新闻媒体。事件的传播,相较于之前的类似事件,传播速度更加迅速,引起的人群线下活动也发生得更加频繁,微博已经成为不可小觑的舆论平台。
微博内容的文本精简、主题突出、聚焦性好,是用户情感和意见的直接表达。这种依赖于所有者社会资源的信息传播方式,可以方便信息的主动、快速推送;同时,多终端的信息获取方式提高了事件的采集时效性;而带有follow(跟随、关注)特征的用户关联方式,使微博内容得以在关键用户的影响下,被迅速、广泛传播。微博这些特点使其内容的传播成本(包括时间成本、资源占用成本和用户使用成本)很低,其直接结果就是:容易产生爆炸性内容,但易受到关键用户的影响、消失很快、噪声较多。
2018年李宁登录纽约时装周,子品牌“中国李宁”走红。2021年,有市场调查数据显示,李宁品牌的市场占比为7.7%,仅次于耐克(17.3%),以及阿迪达斯(13%)。2022年9月20日李宁在湖北的新品发布会的服装,造型设计酷似日本的军服,网友称这些秀款是“大佐服”,并纷纷表达了对李宁呼吁抵制的情绪性言论,事件发酵之初,李宁官方并没有第一时间进行回应,随着舆情进一步走热,在面对这样的舆论困境,李宁缺乏起码的舆情敏感性,没有在的第一时间进行处理,从19日到20日,李宁股价跌去10%,市值蒸发了150亿港币。互联网的飞速发展促成了很多新媒体的发展,不论是知名大v,明星还是围观群众都可以通过手机在微博发表状态,分享自己的所见所得。无论是热点新闻还是娱乐八卦,传播速度远超想象。在如此海量的信息得到爆炸式的传播时,我们如何能够实时得把握民情并及时做出对应的处理而这一切也意味着传统的舆情系统升级为大数据舆情分析预警系统。
1.3研究趋势
2019年10月28日,中国共产党第十九届四中全会提出:“坚持党管媒体原则,坚持正面宣传为主。改进和创新正面宣传,完善舆论监督制度,健全重大舆情和突发事件舆论引导机制。建立健全网络综合治理体系,加强和创新互联网内容建设,落实互联网企业信息管理主体责任,全面提高网络治理能力,营造清朗的网络空间”因此微博作为媒体宣传报道的重要阵地,在媒体报道重大公共事件的过程中发挥着重要的传播作用。传统的单向传播格局因新媒体时代的全面到来被打破,微博平台凭借其传播内容丰富、传播覆盖面广等特点,在新闻信息的传递、评论以及发布方面占据着优势。当出现重大公共事件时,微博不仅能报道整个事件的相关进程,更能推动舆情的发酵。
本系统预期实现对主流微博平台的热点,评论自动采集分析,得出热点词,关键字。并对负面,消极以及虚假的信息及时管控,再输入关键词后对该关键词进行相关的微博评论评估预警,以便于提醒使用者及时做出应对措施,以免错过最佳时间。对预警热点进行监管规范,再从中获得有用的价值,例如商业价值,信息传播以及社会学方面的研究价值,并从中满足人们的需求,同时对于社会的和谐,网络舆论生态的健康,公司管理层的正确决策,国家的发展都有重要的现实意义。
2开发环境
2.1开发环境以及工具介绍
开发环境使用Win10操作系统,开发工具使用IDEA,Navicat,PyCharm等,数据爬取利用python的Requests框架进行,情感分析使用LSTM算法,数据库服务器使用MySql,数据处理技术使用Spark和Flink,Web端架构使用Springboot和vue等技术,可视化展示使用Echarts技术。
舆情预警系统是对新浪微博的近期热点相关的评论数据进行爬取,利用Requests框架获得海量数据。再对获取的数据进行数据预处理后导入到MySQL数据库,基于数据集利用LSTM(Long Short Term Memory)技术训练神经网络模型,对句子进行情绪上的分类和识别,对负面情绪消极数据和正面积极数据进一步分析,得到具体比值,当某种情绪到达阈值时进行预警,做到数字化的情感反馈。使用Spark和Flink等技术对相关数据进行数据实时处理,Web端框架使用Springboot和Vue等技术完成,大屏可视化展示用Echarts实现可视化。
2.2算法及解决方案
1、数据爬取模块理论依据
使用urllib获取微博的cookie伪装成人类访问,从而点击微博新闻首页,根据爬取的热搜词条,抓取热搜词条对应的新闻数据,使用requests框架获取数据,当抓取到html以后,用BeautifulSoup进行解析,抓取到需要的数据如:用户名、微博名称、点赞量、转发量、发布时间、地区等关键信息,存储到mysql数据库作为数据集使用;
2、微博情感分析模块理论依据
抓取大概十多万微博数据,分析的数据较大,需要使用lstm批量情感分析,可以利用Java的多线程技术以及Python的lstm情感分析算法的技术优势,将Python编写好的分析算法代码集成到Java中,使用IDEA的Python插件进行调用,这样多线程处理情感分析速度快。对于分析后的数据使用Flink实时计算框架导入实时分析结果表,提供给前端调用。
3、数据可视化模块理论依据
数据统计分实时统计和静态统计,热词使用websocket技术与SpringBoot后台实时通信获取热词动态显示,静态数据通过vue发送http请求与后端SpringBoot交互获取json数据。所有分析的数据使用echarts进行大屏显示。实时计算的时候使用Spark大数据框架的SparkSQL模块进行数据分析。
2.3实施方案
舆情预警的分析需要海量的数据采集,并需要保证数据的精准度,而新浪微博平台的反爬机制具有一定的难,因此在数据挖掘时会影响爬取进度,虽说微博对爬取的频率做了限制,不过站在微博官方的角度同时想让搜索引擎爬取数据,又要防止其他爬虫对服务器带来的压力。
- 舆情预警系统的重点时舆情的分析,其中要涉及到的技术有文本分类,聚类,倾向性识别,主题检测和追踪,自动摘要等计算机文本信息内容识别技术。其中基于关键词统计分析方法的技术相对比较成熟,但在关键词的有效性有很大的提升。
(3)面对网站的反爬机制从三个方面着手,第一是对用户请求的Headers反爬虫,这是较为常见的反爬机制,我们需要伪装Header,直接在爬虫中添加Headers即可(其中Headers是一个字典,通过这种可以将爬虫模拟成浏览器对网站访问)。第二种是基于用户行为的反爬虫,有一部分网站是通过检测用户行为,列如同一个IP短时间多次访问同一个页面,或者同一个账户短时间内进行多次相同操作,面对这种防爬则需要有足够多的IP来应对也可以在每次访问后间隔一定的时间再进行下一次请求。最后一种则是动态页面的反爬虫一些应用ajax的网站会采用,这样增大了爬取的难度(防止静态爬虫使用ajax技术动态加载页面),我们需要爬取的数据是通过ajax请求得到,或者通过Java生成的,解决方案是使用Selenium(自动化Web测试解决方案,模拟用户操作)和PhantomJS(一个没有图形界面的浏览器)来实现对微博网站的爬取。
(4)文本情感分析(Sentiment Analysis)是自然语言处理(NLP)方法中常见的应用,尤其是以提炼文本情绪内容为目的的分类。它是对带有情感色彩的主观性文本进行分析、处理、归纳和推理的过程。情感分析中的情感极性(倾向)分析。所谓情感极性分析,指的是对文本进行褒义、贬义、中性的判断。在大多应用场景下,只分为两类。例如对于“喜爱”和“厌恶”这两个词,就属于不同的情感倾向,本项目将使用深度学习模型中的LSTM(Long-Short Term Memory,长短期记忆人工神经网络)模型来实现文本的情感分析。LSTM能够很好的表达出句子中词的关系,能将句子当做一个整体来看待,而不是一个个单独的词,由此不难看出再情感分析上面LSTM对于其他算法具有一定的优势。
(5)舆情情感分析预警系统不同于传统的舆情分析系统,舆情分析预警系统使我们能够实时地检测网民对时事热点的不同看法,面对海量地数据无法做到人工的方式对互联网舆情进行全面监控的难度。因此结合网络评论采集和文本信息自动化处理等技术研发一个热点舆情的情感分析趋势,因而可以对早发现的热点舆情及时进行干预,引导疏通网民的情绪和心理,避免矛盾进一步恶化而造成更大的社会损失。对预警热点进行监管规范网络行为,净化网络环境,再从中获得有用的价值,例如商业价值,信息传播以及社会学方面的研究价值,并从中满足人们的需求,同时对于社会的和谐,网络舆论生态的健康,公司管理层的正确决策,国家的发展都有重要的现实意义。之后还可以对增加近年来网民的素质以及看法的分析和对热点的关注点推荐系统。
(6)舆情情感分析预警系统预期对微博的新闻头条和热搜排行进行自动采集,进行对话题热度的趋势变化和发布分析,对网民的热点评论数据进行情感分析,得出最近热点关键词,输入关键词后可对该关键词有关的微博消息进行评估预警,提醒使用者以便于做出应对措施。
3技术逻辑
3.1微博分类设计
微博分类设计从SVM的原理中可以看出来,SVM是一种典型的两类分类器,即它只回答属于正类还是负类的问题。而现实中要解决的问题,往往是多类的问题,比如本系统要实现的微博分类。如何由两类分类器得到多类分类器,是一个值得研究的问题。文本分类为例,现成的方法有很多,本文用一种所谓“一类对其余”的方法,就是每次仍然解一个两类分类的问题。我们要把微博分成有5个类别,第一次就把类别1的样本定为正样本,其余2,3,4,5的样本合起来定为负样本,这样得到一个两类分类器,它能够指出一篇文章是还是不是第1类的:第二次我们把类别2的样本定为正样本,把1,3,4,5的样本合起来定为负样本,得到一个分类器,如此下去,我们可以得到5个这样的两类分类器(总是和类别的数目一致)。微博分类的时候,我们需要将该条微博去5个分类器中分别检测,是否是某类的分类。这种方法的好处是每个优化问题的规模比较小,而且分类的时候速度很快(只需要调用5个分类器就知道结果)。但是此方法要注意本来各个类别的样本数目相差无几,但“其余”的那一类样本数总是要数倍于正类(因为它是除正类以外其他类别的样本之和),这就人为的造成了的数据集偏斜”问题,会导致分类准确率下降。所以我们要调整分类训练集各类的样本数量,保证每次分类的时候,正类和负类的数量大致相当。
3.2热点检查算法设计
按照本文的研究内容,需要对微博热点事件发现与检测,本文提出了一种较为朴素的算法对微博热点进行检测,即通过监测微博流的热词变化情况,这里提及的热词实际是“突发词”,即短时间内微博上上升最快的词,每隔一段时间将近期的微博分词统计词频后与历史比较,分析哪些词热度变化明显,再由这些热词在系统中搜索出对应的微博集合,将这些微博聚类,分析出发生的热点事件。
3.3热词检测
热词的检测需要分词,统计,比较三个步骤,整个算法设计成了 Spark 任务,分布式运行提高效率。
1.分词,原始的微博是文本信息,需要将文本进行分词处理。
2.词的汇总统计,分词完成后,先将所有微博的分词结果按秒汇总,即统计每一秒内的微博中出现每个词的个数,再以每秒的词频数据,汇总出每一分钟的词频,继而统计出每一小时,每一天的词频数据。至此,可以得到任意时间内的微博的词频统计。
3.比较当前时段词频与历史时段词频,将变化最大的词挑选出来即为此时段的突发热词,此过程中会需要设置过滤条件,将一些噪音词去除。
4 结束语
在论文的撰写和资料搜集期间,前人的.资料对我提供了莫大的帮助,这里再次感谢。值此即将完成学业之际,我要衷心地感谢导师唐任仲教授两年来在学习和生活中给予的谆谆教诲和悉心的关怀。在论文的选题、研究以及撰写过程中,自始至终得到了导师的精心指导和热情帮助,其中无不凝聚着导师的心血和汗水。导师严谨求实和一丝不苟的学风、扎实勤勉和孜孜不倦的工作态度时刻激励着我努力学习,并将鞭策我在未来的工作中锐意进取、奋发努力。导师的指导将使我终生受益。
致谢
在此感谢指导老师许庆星老师在论文选题、开题、中期检查、初稿、定稿、查重等各阶段期间所提出的宝贵意见,与老师的每一次交流都受益匪浅。本设计(论文)在导师的耐心指导下完成撰写的。在整个论文的写作过程,收获了思考和成长,也经历了生命的孕育过程,虽有不易,却倍感珍惜。
主要参考文献
[1]张洋,何楚杰,段俊文,杨春程.《微博舆情热点分析系统设计研究》.信息网络安全.2019.09
[2]王艺.《重大突发公共事件的微博舆情监测与引导初探》。贵州民族学院学报.2019.05
[3]杨涛.《智能信息处理技术在互联网舆情分析中的应用》(硕士学位论文).同济大学.2020.05
[4]张超.《文本倾向性分析在舆情监控系统中的应用研究》(硕士学位论文).北京邮电大学.2021.02
[5]唐晓波宋承伟.《基于复杂网络的微博舆情分析》.情报学报.2019.11
[6]刘恒文.《基于网络语义挖掘的舆情监测预警研究》(硕士学位论文).武汉理工大学.2020.05
[7]王晶,朱珂,汪斌强.《基于信息数据分析的微博研究综述》.计算机应用。2020.07
[8]莫溢,刘盛华,刘悦,程学旗.《一种相关话题微博信息的筛选规则学习算法》。中文信息学报.2019.09
[9]谭俊武.《面向网络舆情分析的文本倾向性分类技术的研究与实现》(硕士学位论文).国防科技大学。2019.11
[10]陆浩.《网络舆情监测研究与原型实现》。北京邮电大学。2019.02
[11]M.Spitters,W.Kraaij.Using Language Models for Tracking Events of Interest over Time Proceedings of the Workshop on Language Models for Information.Retrieval(LMIR),Pinsburgh,2021.
[12]Larsen B,Aone C.Fast and effective text mining using linear-time document clustering.In:Proceedings of the Fifth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,San Diego:CA,2019.16-22.
[13]J.Yi,T.Nasukawa,R Bunescu,and w.Niblack.Sentiment Analyzer:Extracting Sentiment S about a Given Topic using Natural Language Processing Techniques[A].In:Proceedings of the 3rd IEEE International Conference on Data Mining(ICDM2020)[C].
[14]黄微.网络舆情传播与监测的理论和方法研究[J].情报资料工作,2019(06):5.
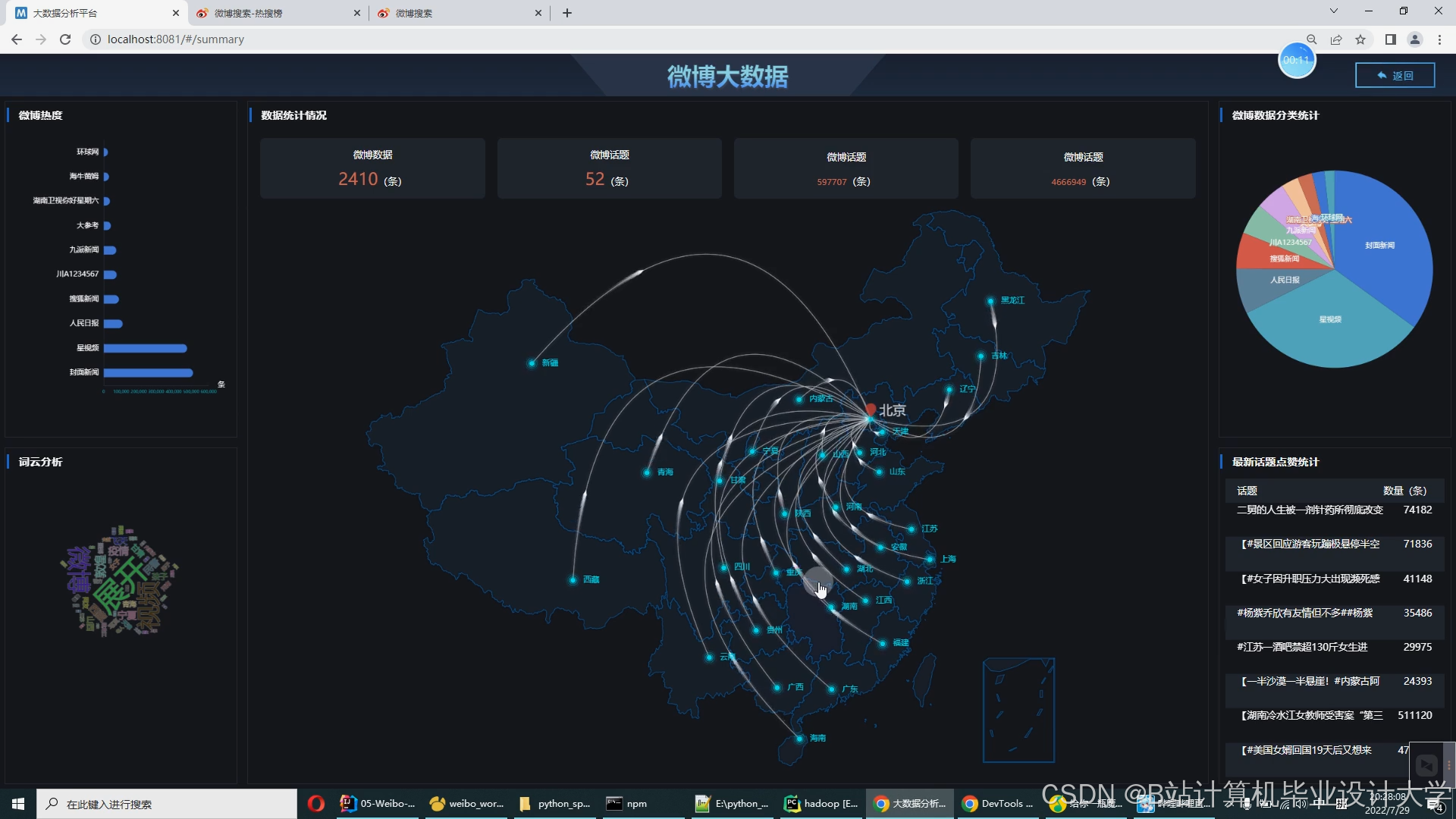
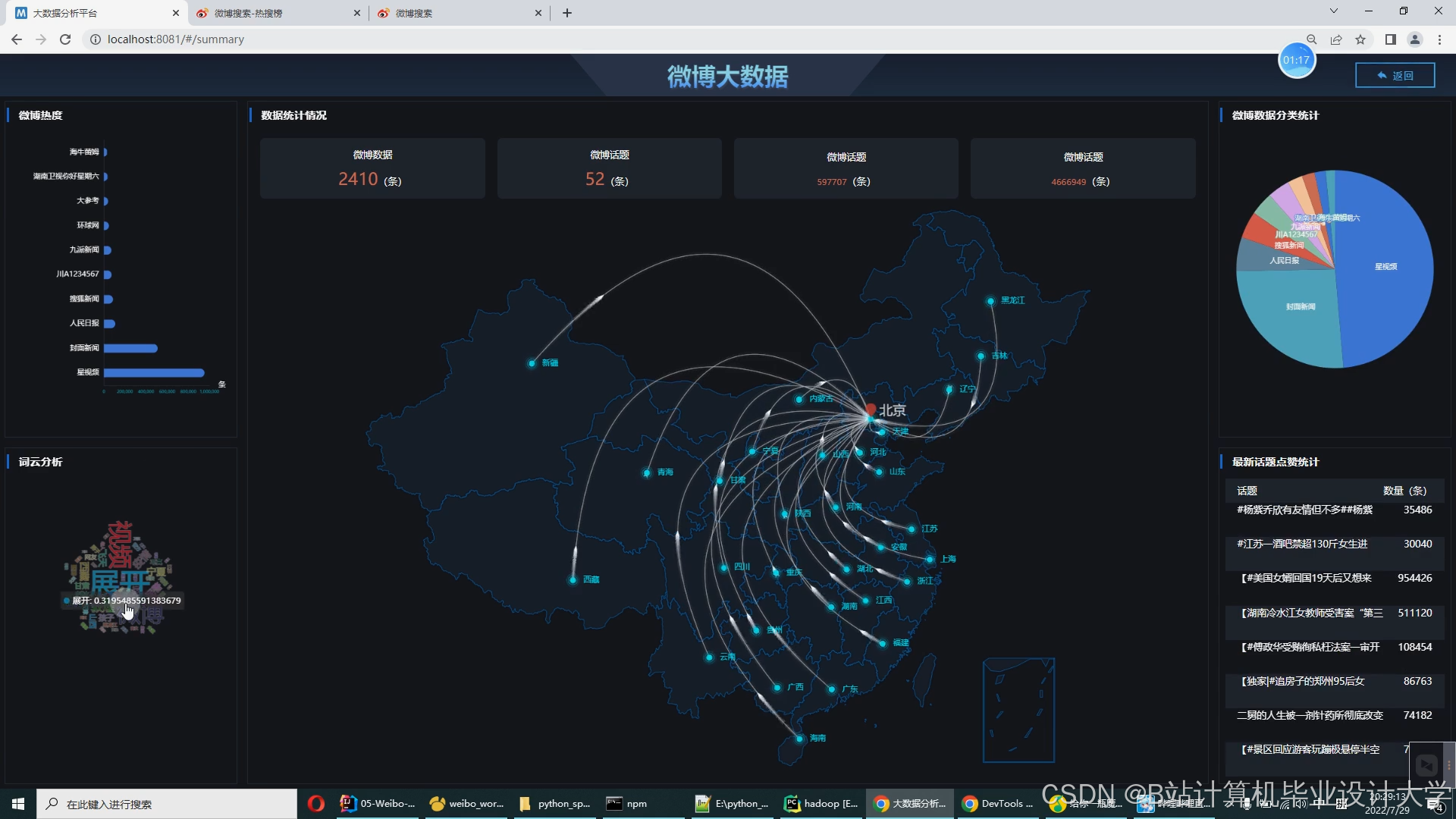
运行截图



推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











