







温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
介绍资料
《Python + 千问大模型微博舆情预测》文献综述
摘要:本文综述了基于Python与千问大模型进行微博舆情预测的相关研究。阐述了微博舆情预测的重要性和现有方法面临的挑战,介绍了Python在数据采集、处理和分析方面的优势以及千问大模型在自然语言处理领域的强大能力。分析了两者结合在微博舆情预测中的应用现状、关键技术和研究进展,同时指出了当前研究存在的问题和未来的研究方向,为进一步推动该领域的研究和实践提供参考。
关键词:Python;千问大模型;微博舆情预测;自然语言处理
一、引言
随着互联网技术的飞速发展,微博等社交媒体平台已成为公众表达意见、分享情感和交流信息的重要渠道。微博日均产生海量用户生成内容(UGC),这些数据蕴含着丰富的社会舆情和情感倾向。及时准确地预测微博舆情走向,对于政府、企业等主体把握社会动态、制定决策、应对危机至关重要。
传统的舆情分析系统主要依赖规则匹配或浅层机器学习模型,存在语义理解不足、情感极性误判率高等问题。例如,基于SVM或LSTM的模型在处理“这波操作太秀了”等中文网络流行语时,情感分类准确率仅约72%。近年来,Python凭借其丰富的库和强大的数据处理能力,在数据分析领域得到广泛应用;千问大模型等先进语言模型具备出色的语言理解和生成能力,为微博舆情预测提供了新的技术途径。
二、Python在微博舆情预测中的应用
(一)数据采集
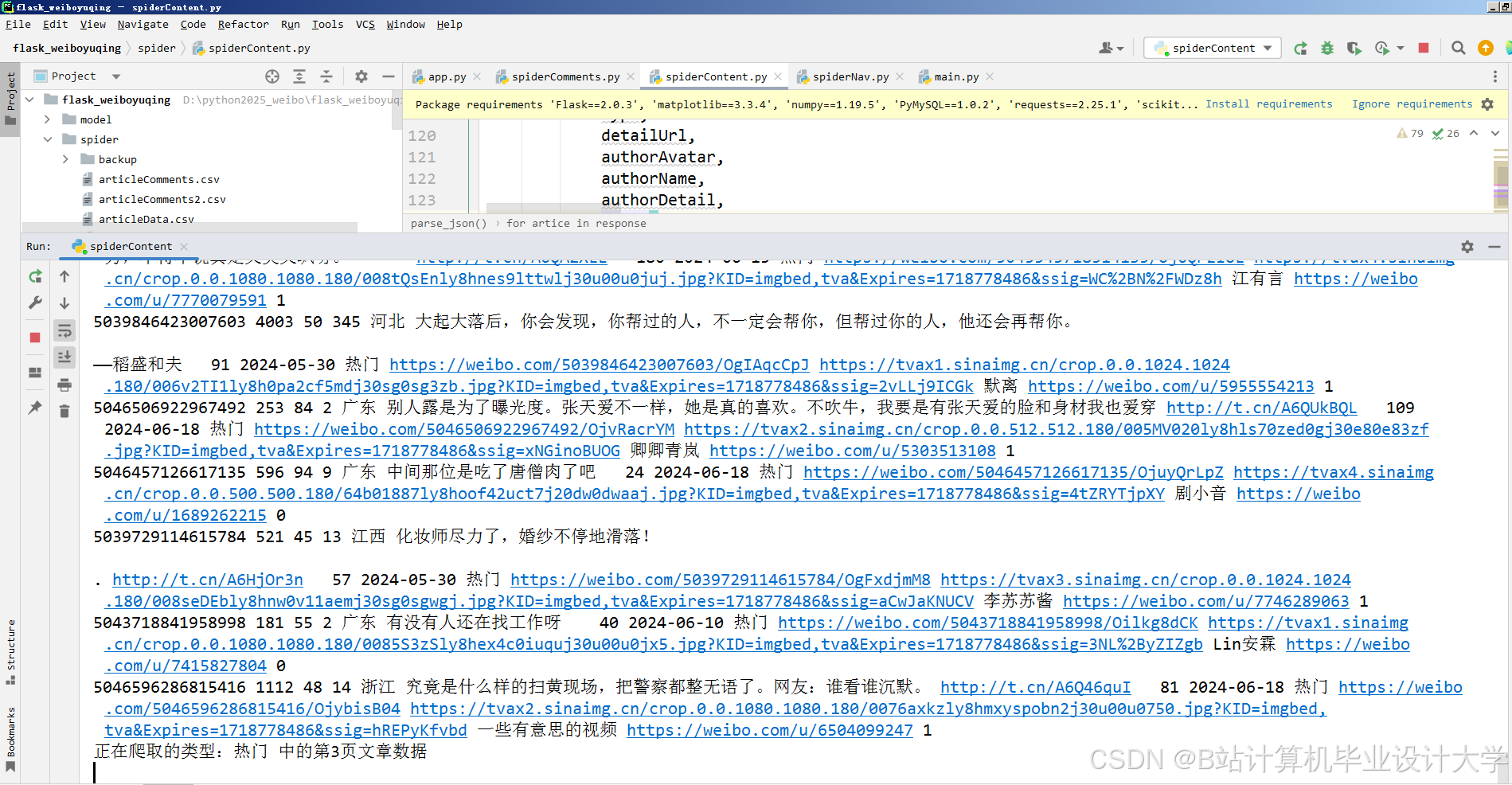
Python提供了多种库用于微博数据采集。requests库结合lxml解析库可以对微博进行分时段多进程爬取,并解析爬取到的数据。例如,通过requests获取微博API接口返回的数据,再利用lxml对数据进行解析,提取微博内容、发布时间、用户信息等关键信息。同时,为了应对微博平台的反爬虫机制,可以采用IP池+UA轮换等技术,确保数据采集的稳定性和持续性。
(二)数据预处理
在数据预处理阶段,Python的numpy、pandas等库发挥着重要作用。这些库可以对原始数据进行数据缺失值填充、重复值去重、非法值替换等处理,以及对某些特征进行数据类型转换和特征编码。例如,对于微博文本数据,可以进行中文分词和词性标注,去除停用词和特殊字符,提高数据的质量和可用性。
(三)数据可视化
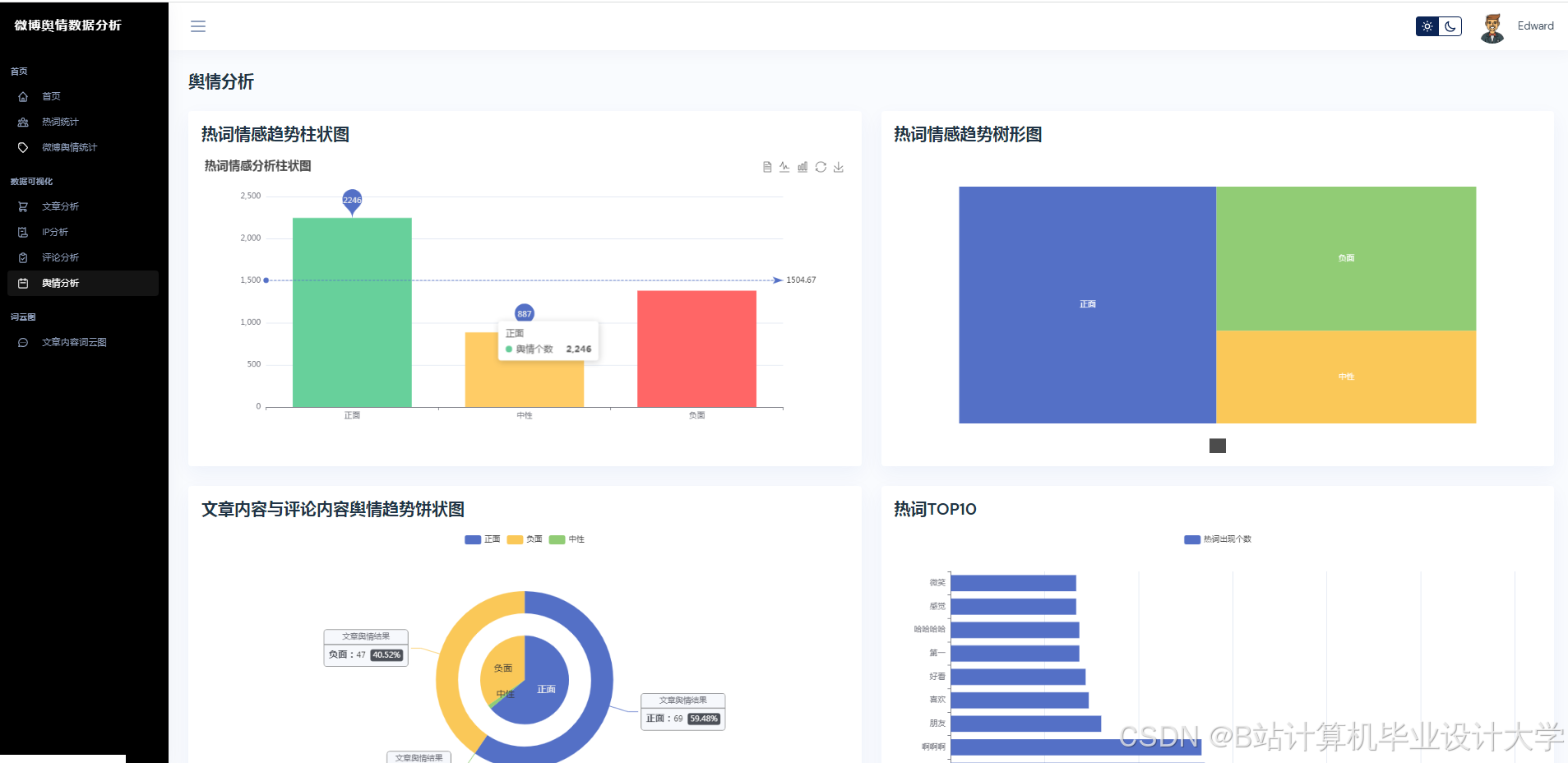
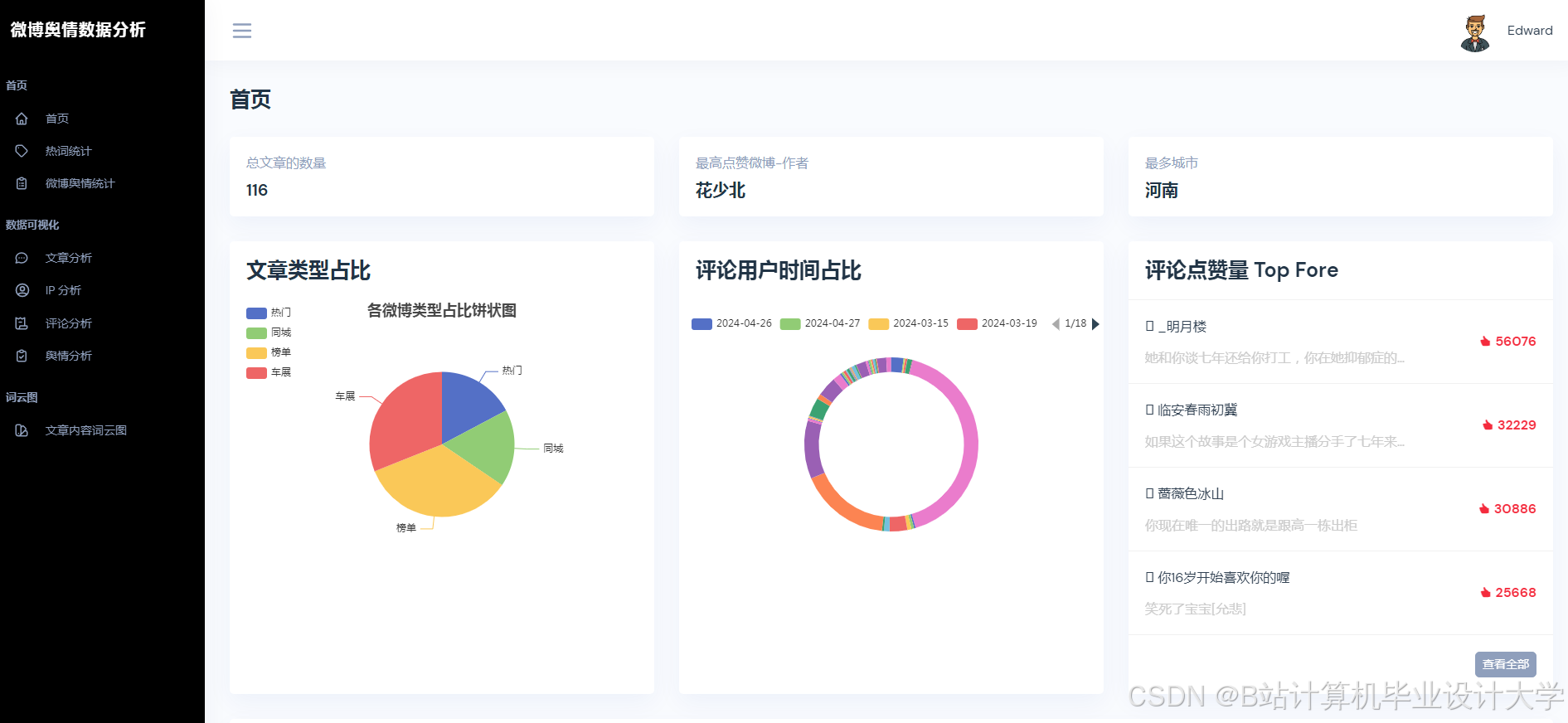
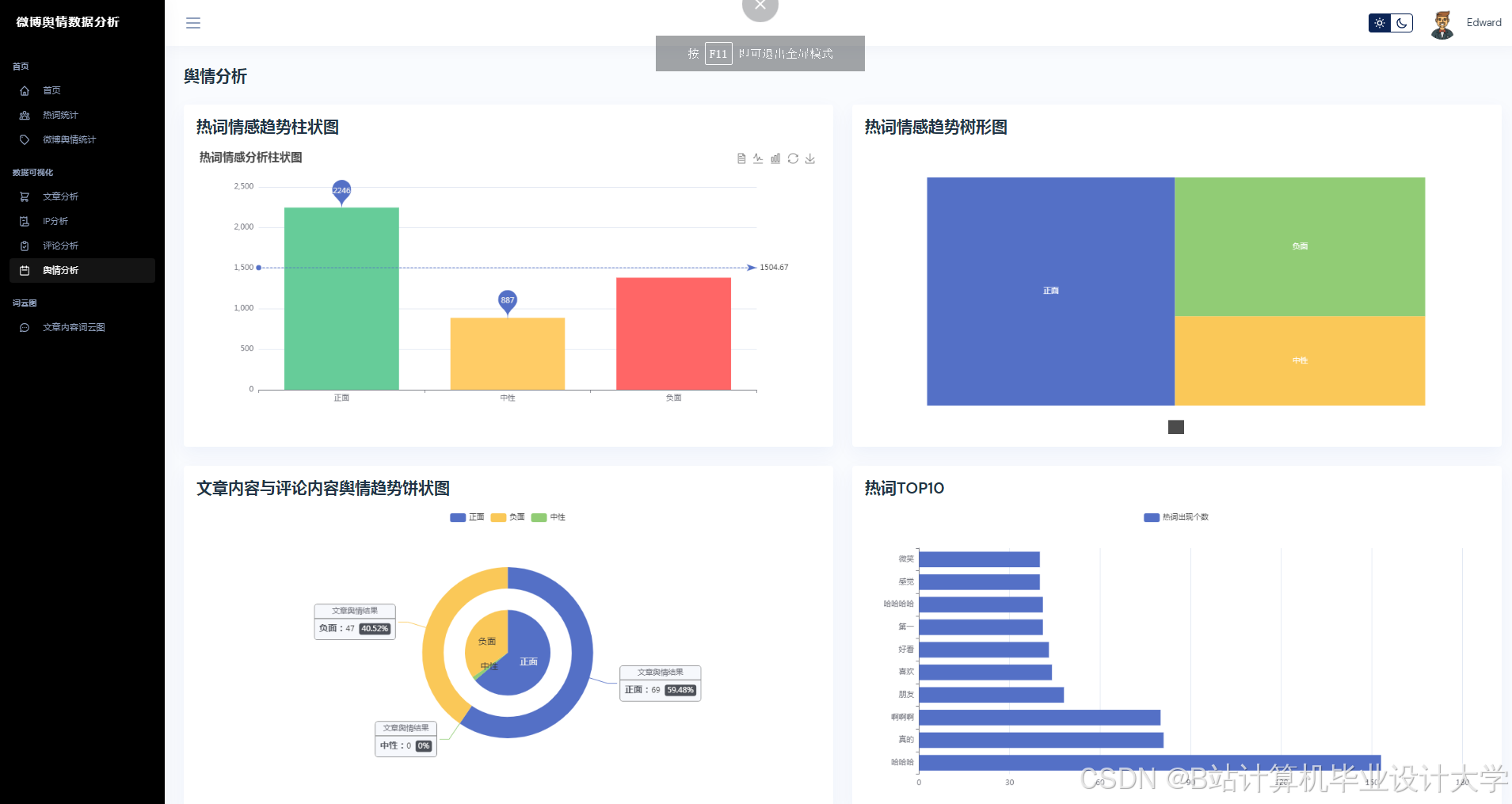
Python的matplotlib、seaborn等库可用于数据可视化。通过这些库,可以将微博舆情数据的各种变化指标,如不同时段、不同人群的传播力度变化等,以直观的图表形式展示出来。例如,利用柱状图展示不同话题的热度分布,用折线图展示舆情热度随时间的变化趋势,帮助用户更好地理解舆情数据。
三、千问大模型在微博舆情预测中的优势
(一)强大的语义理解能力
千问大模型通过2.6万亿参数的预训练,在中文语义理解方面表现出色。它能够准确理解微博文本中的网络流行语、方言等复杂语义,提高对微博文本中情感极性的判断准确率。例如,对于“绝绝子”“巴适得板”等网络流行语和方言表达,千问大模型可以正确识别其情感倾向,避免传统方法因语义歧义导致的误判。
(二)多模态数据融合能力
微博数据通常包含文本、表情符号、地理位置、用户关系等多种模态信息。千问大模型具备多模态数据融合能力,可以综合考虑这些信息,进行全方位的舆情分析。例如,将文本内容与表情符号进行联合建模,分析图文一致性,提高舆情分析的准确性和全面性。
(三)少样本学习能力
千问大模型具有少样本学习能力,在少量标注数据上进行微调,即可实现高精度的主题分类和情感分析。这对于微博舆情预测来说非常重要,因为微博数据量庞大,标注成本高。通过少样本学习,可以降低数据标注的工作量,提高模型的开发效率。
四、Python + 千问大模型在微博舆情预测中的应用现状
(一)系统架构设计
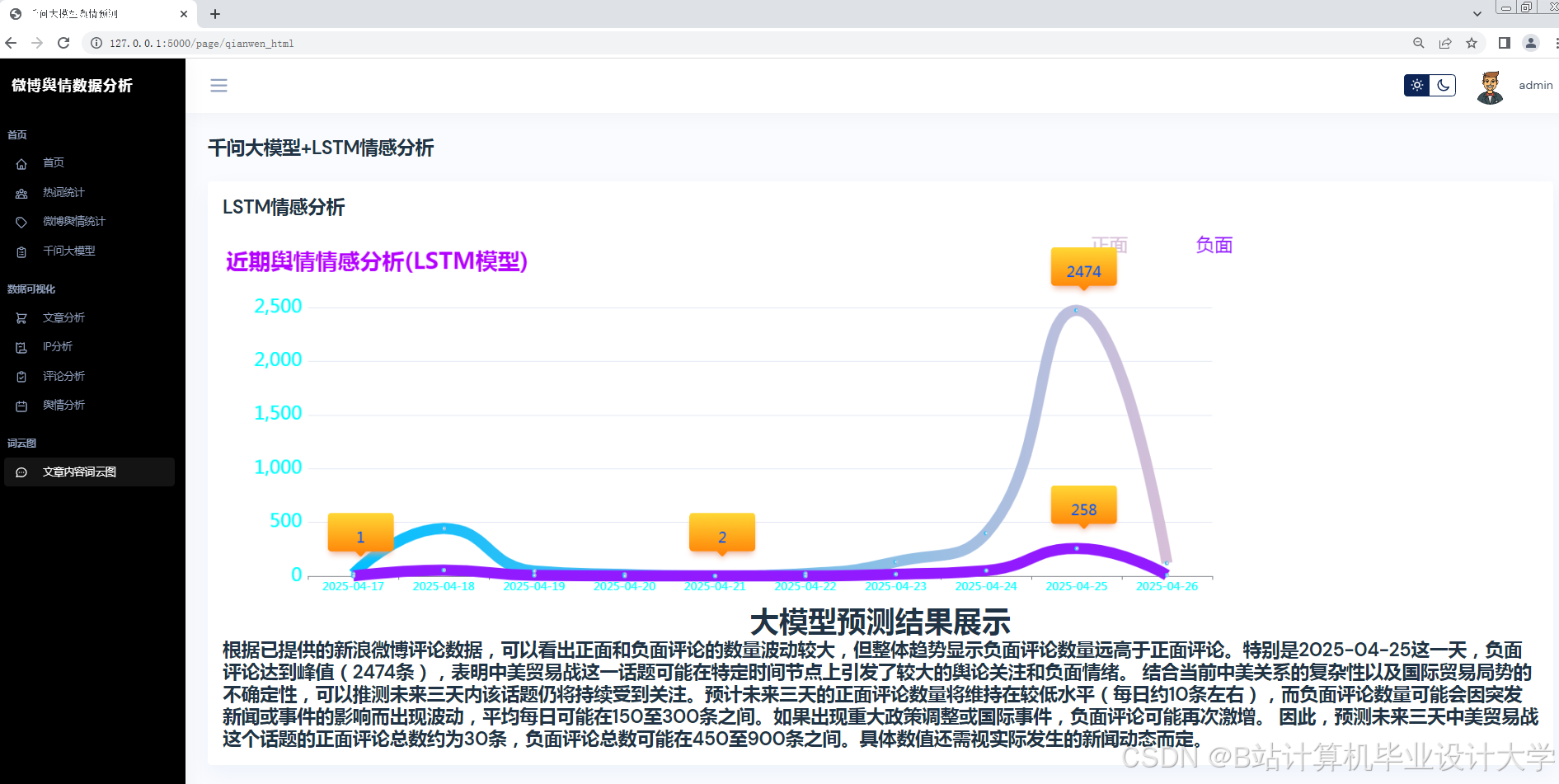
目前,基于Python + 千问大模型的微博舆情预测系统通常采用分层架构设计。数据采集层负责从微博平台抓取数据,可以采用Scrapy框架与微博API混合采集的方式,支持增量式数据抓取。分析处理层调用千问大模型API实现多模态语义解析,结合Spark进行特征工程。预测与可视化层部署Transformer - LSTM混合模型,通过Vue.js + Echarts实现动态可视化。
(二)关键技术研究
- 多模态数据采集与预处理:通过微博API获取结构化数据,如用户ID、转发量等,利用Scrapy抓取评论区图片URL与视频弹幕。对采集到的多模态数据进行清洗,去除HTML标签、特殊字符,利用OCR提取图片文字,ASR转写视频语音。采用MongoDB存储非结构化数据,MySQL存储结构化数据。
- 多模态舆情分析:文本语义解析通过千问大模型API获取情感极性和主题标签;图片情感识别基于千问视觉编码器生成特征向量,通过注意力机制与文本特征交互,计算图文一致性得分;采用双塔 - 交互混合架构融合文本、图片情感特征,生成综合评分。
- 舆情趋势预测:从传播特征(转发量、评论量)、情感特征(负面情绪占比、情感熵)、用户特征(粉丝数、认证等级)三个维度构建输入。采用Transformer - LSTM混合模型,通过Transformer编码器处理长序列依赖,LSTM解码器捕捉短期波动。
(三)应用效果
实验表明,基于Python + 千问大模型的微博舆情预测系统在情感分析准确率、预测误差及实时性方面均优于传统方法。例如,系统情感分析准确率可达89.4%,预测误差(MAPE)≤15%,且能实现分钟级舆情监测与24小时趋势预测。
五、存在的问题
(一)数据隐私合规
微博API严格限制用户ID、地理位置等敏感信息获取,这给微博舆情预测系统的数据采集带来了一定的困难。如何在保护用户隐私的前提下,获取足够的数据用于模型训练和预测,是当前研究面临的一个重要问题。
(二)对抗样本防御
微博文本中存在一些“阴阳怪气”的表达,如“这波操作真‘棒’”,这些文本攻击可能会影响模型的准确性。如何识别和防御这些对抗样本,提高模型的鲁棒性,是亟待解决的问题。
(三)实时性瓶颈
在处理百万级数据流时,模型的推理延迟仍然较大,难以满足实时性要求。如何优化模型结构和算法,提高模型的推理速度,是当前研究的一个挑战。
六、未来研究方向
(一)多模态大模型融合
探索千问大模型与视觉大模型(如Qwen - VL)的联合建模,进一步提高多模态舆情分析的准确性和全面性。例如,将文本、图片、视频等多种模态的信息进行深度融合,构建更加全面的舆情分析模型。
(二)联邦学习应用
在保护数据隐私的前提下,实现跨机构舆情模型的协同训练。通过联邦学习,不同机构可以在不共享原始数据的情况下,共同训练一个更强大的舆情预测模型,提高模型的泛化能力。
(三)模型轻量化
采用LoRA + 知识蒸馏等技术,降低模型的参数量和计算复杂度,提高模型的推理速度,降低部署成本。例如,将千问大模型参数量从2.6万亿压缩至1200万可训练参数,同时保持模型在微博舆情分析任务上的性能。
七、结论
Python与千问大模型的结合为微博舆情预测提供了新的解决方案,在语义理解、多模态数据融合和预测准确性等方面具有显著优势。然而,目前的研究仍存在数据隐私合规、对抗样本防御和实时性瓶颈等问题。未来的研究应致力于解决这些问题,探索多模态大模型融合、联邦学习应用和模型轻量化等方向,推动微博舆情预测技术的发展,为政府、企业和研究机构提供更科学、准确的决策支持。
运行截图

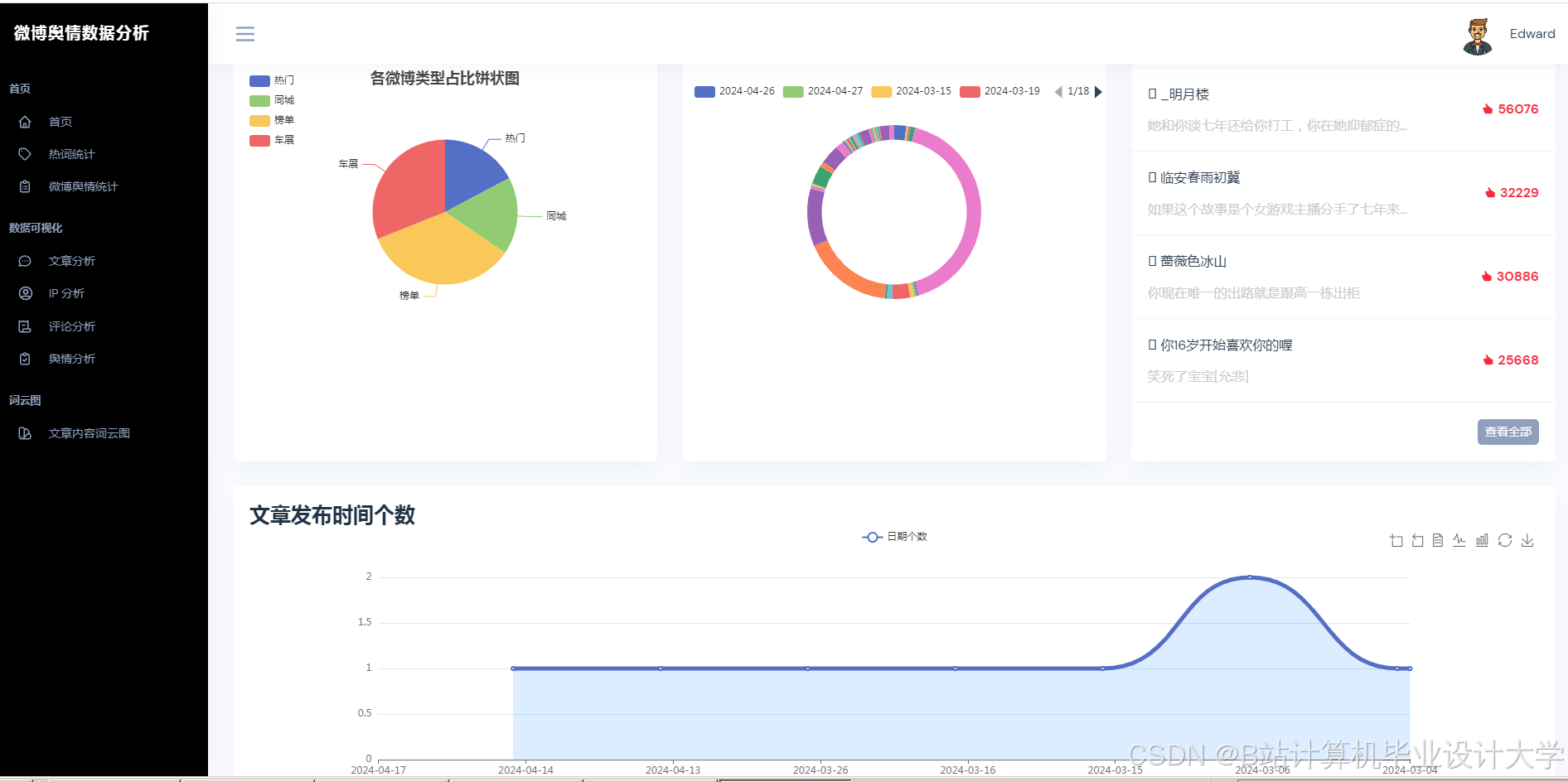
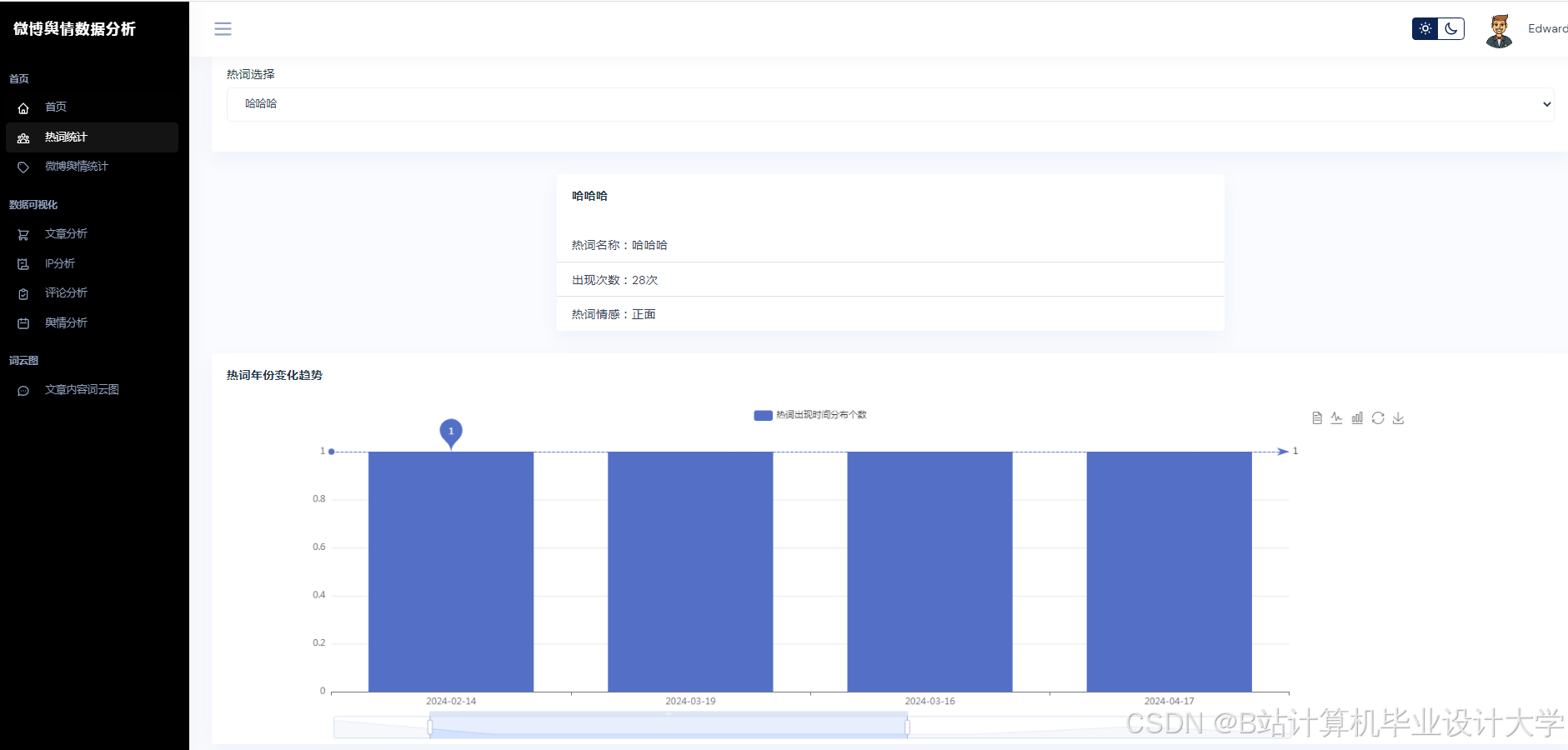
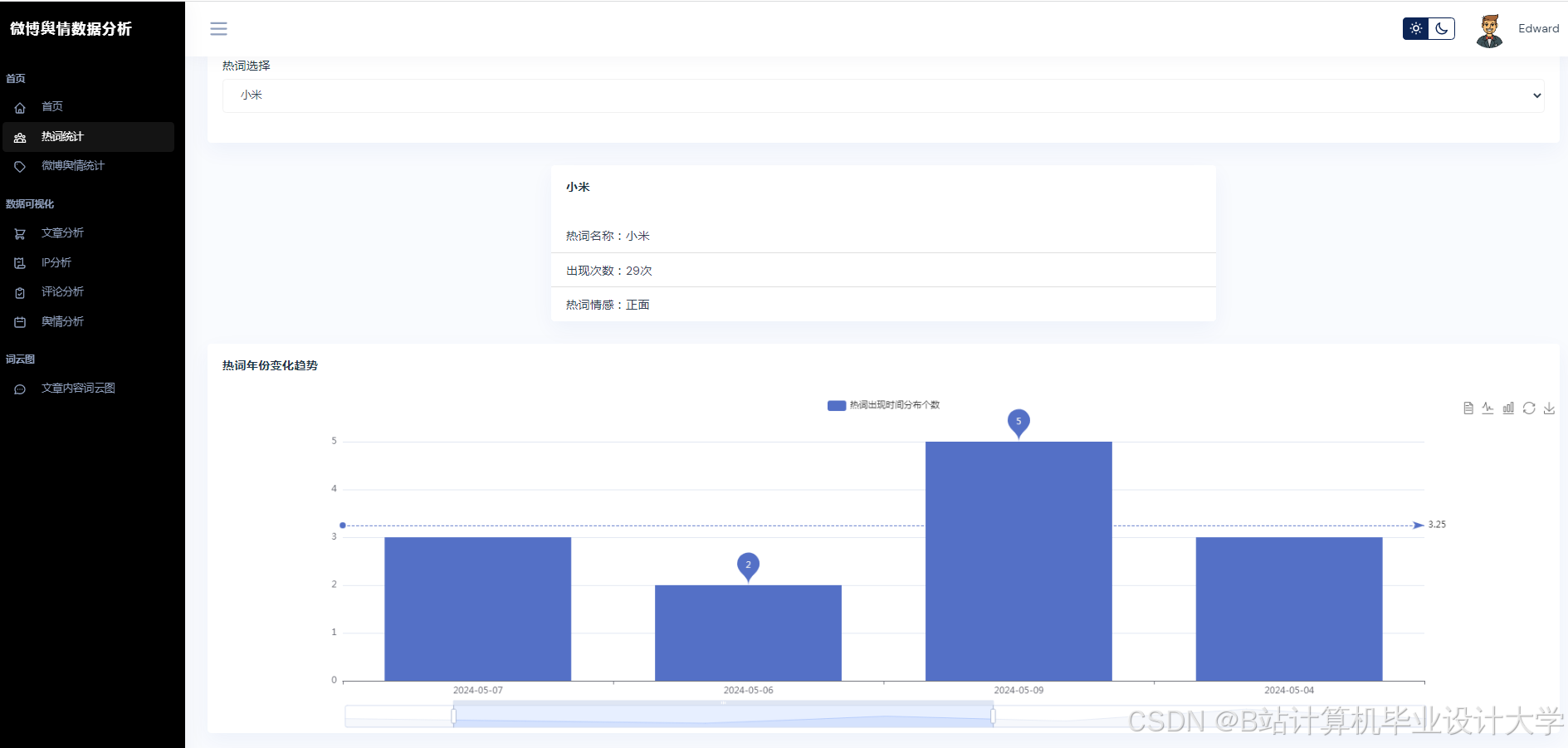
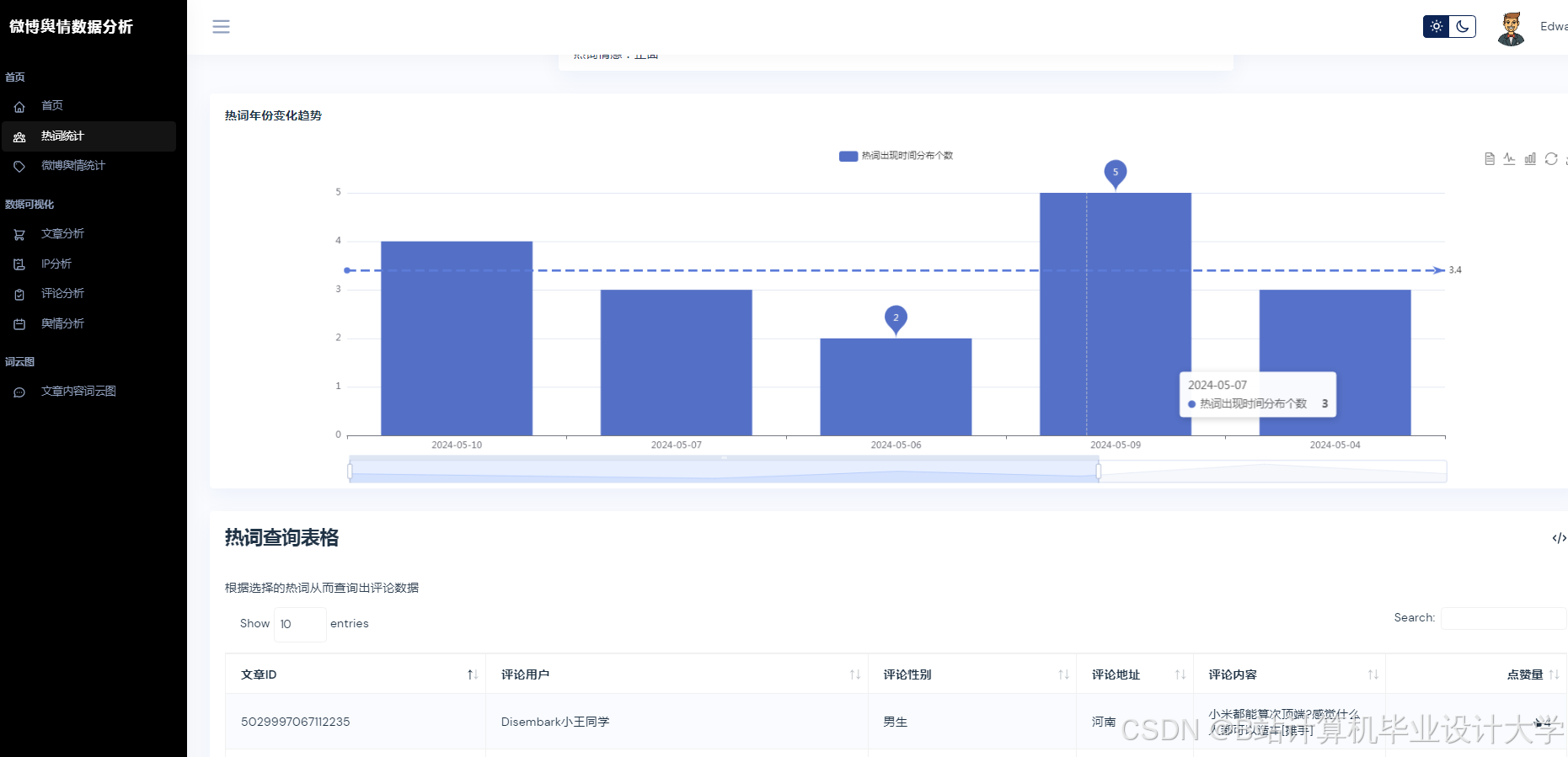

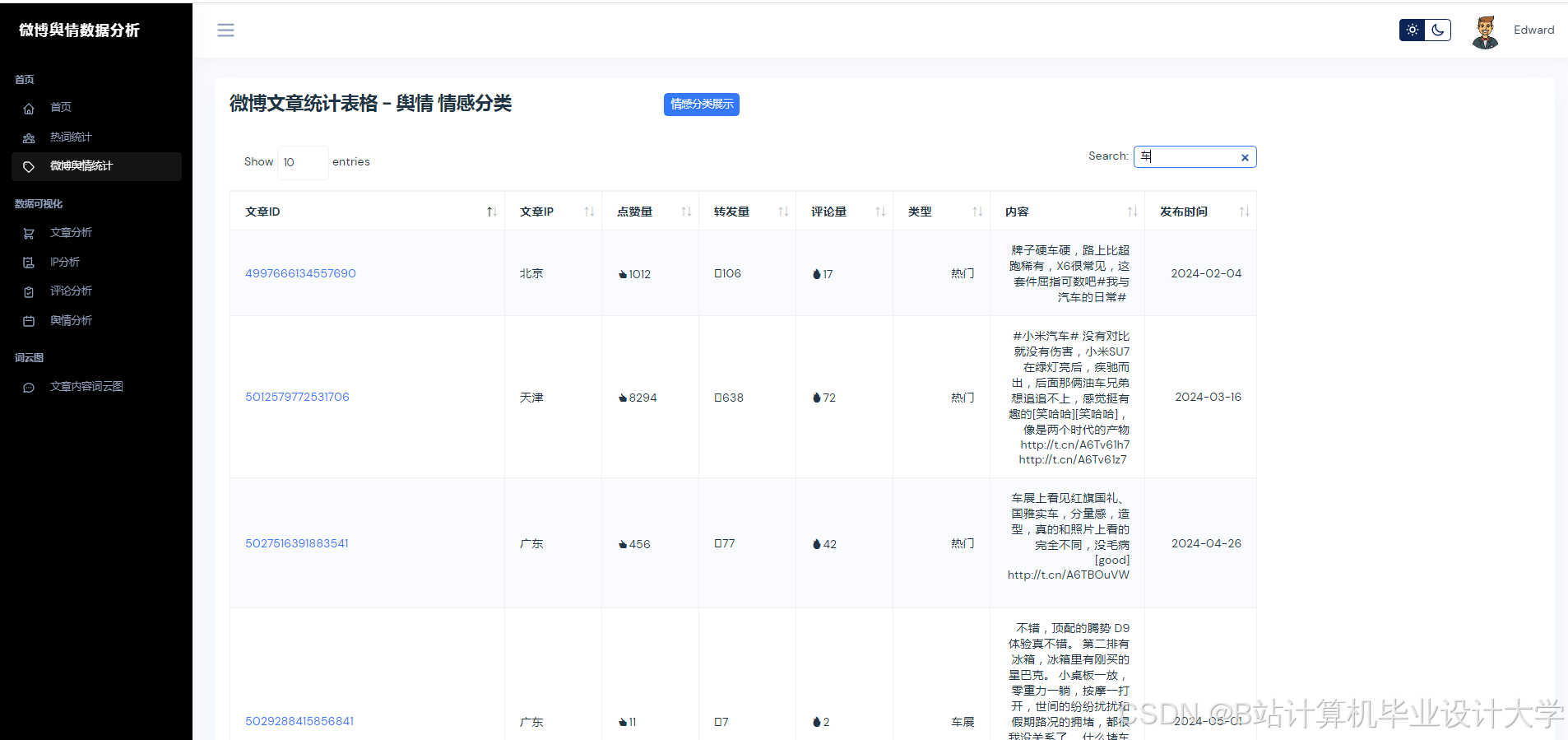
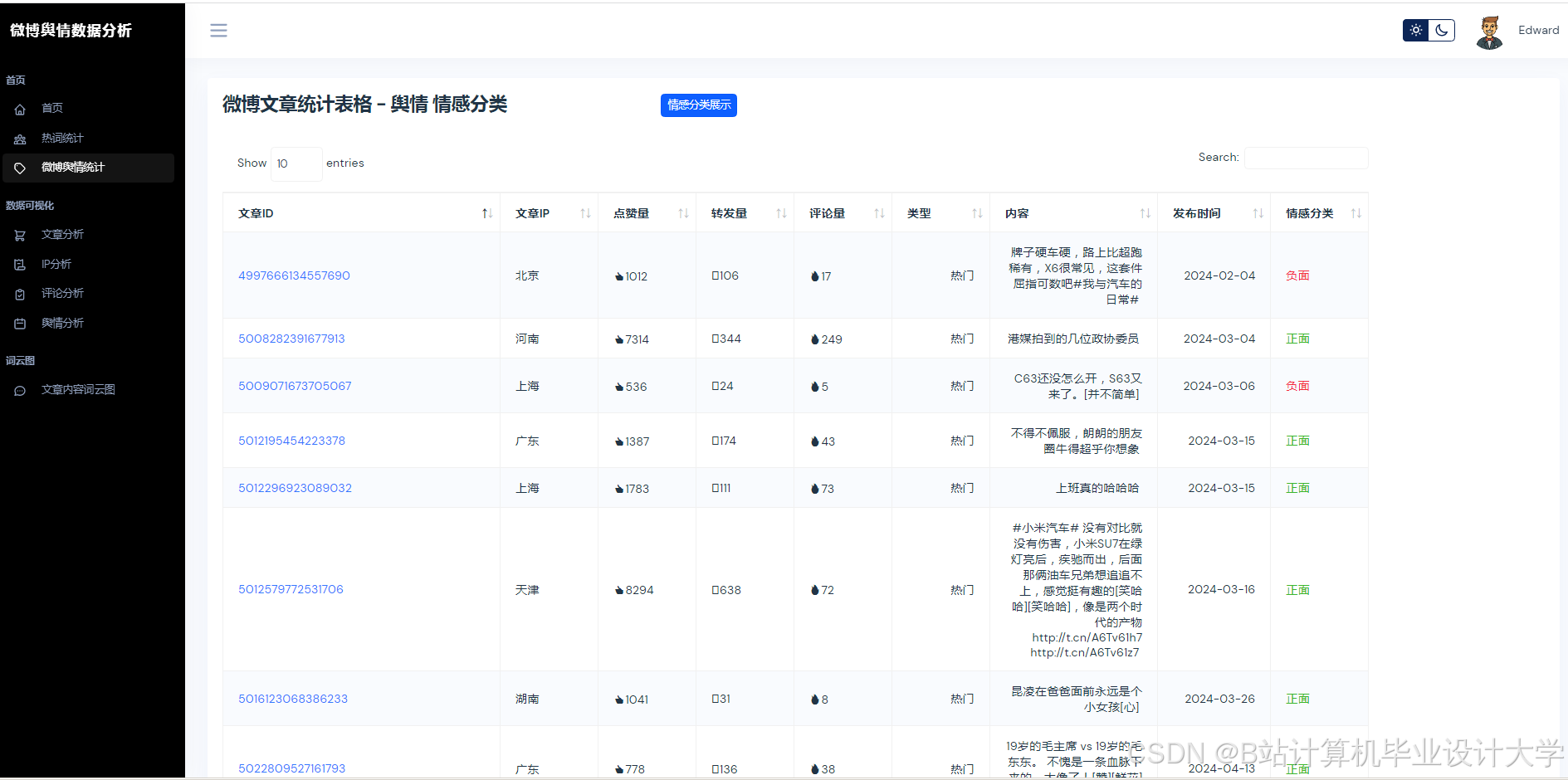
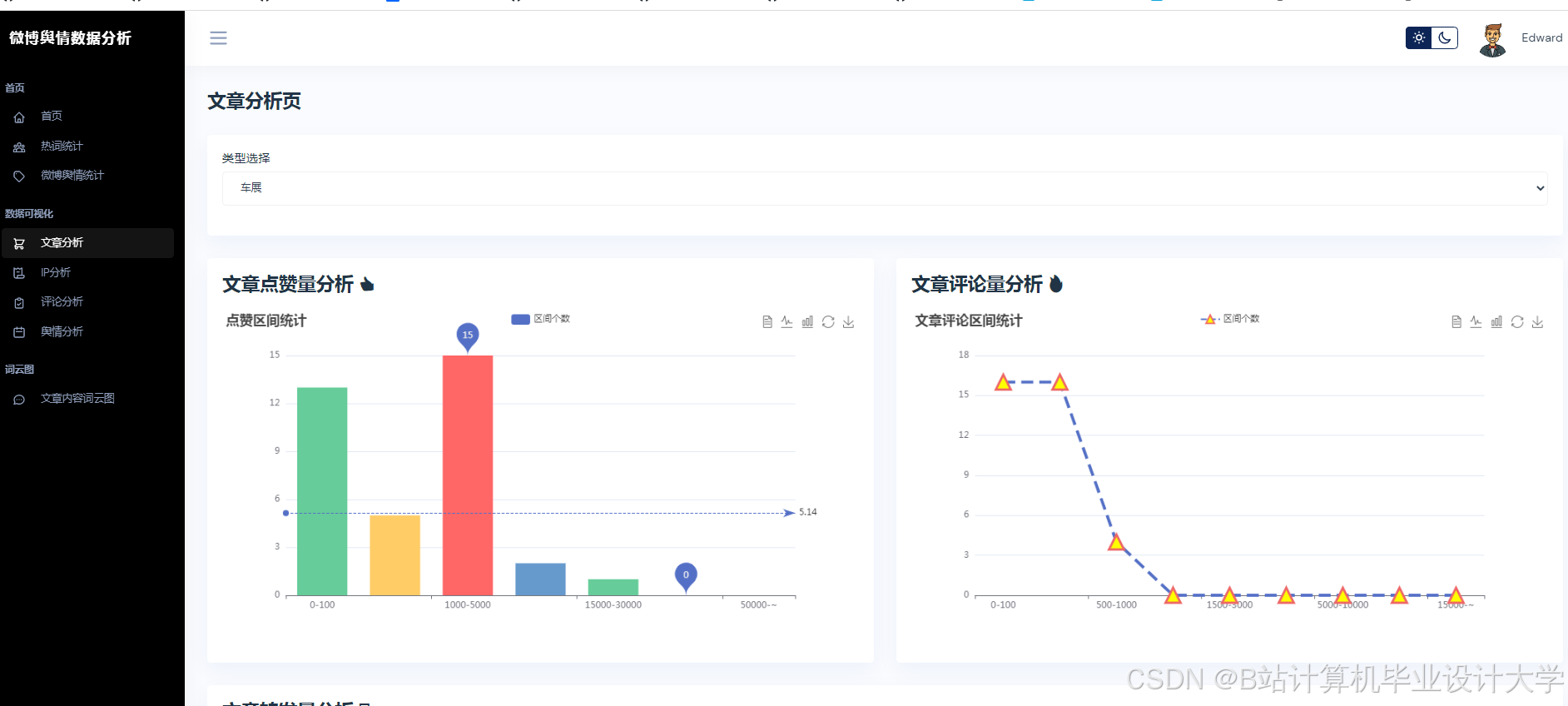
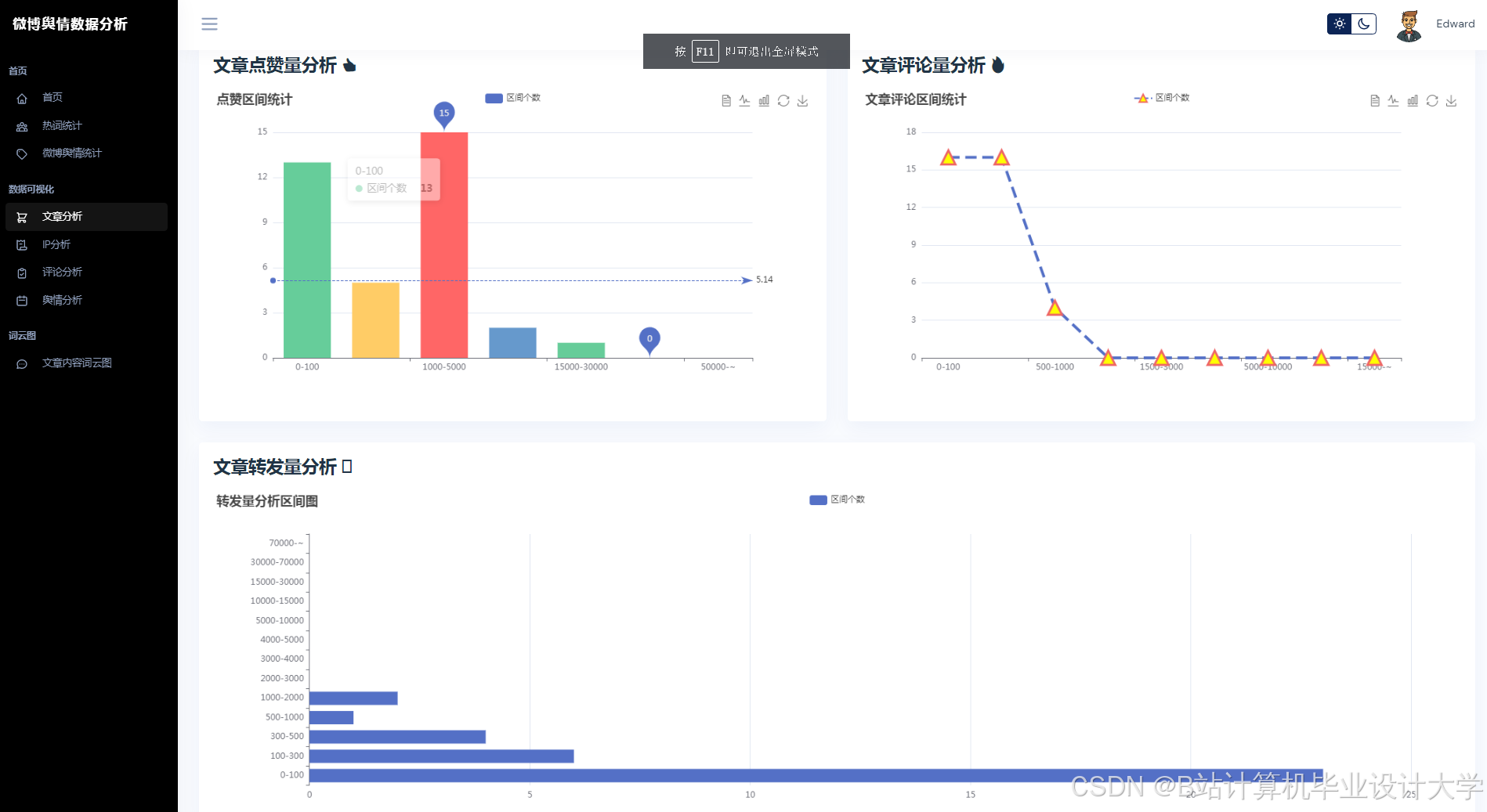
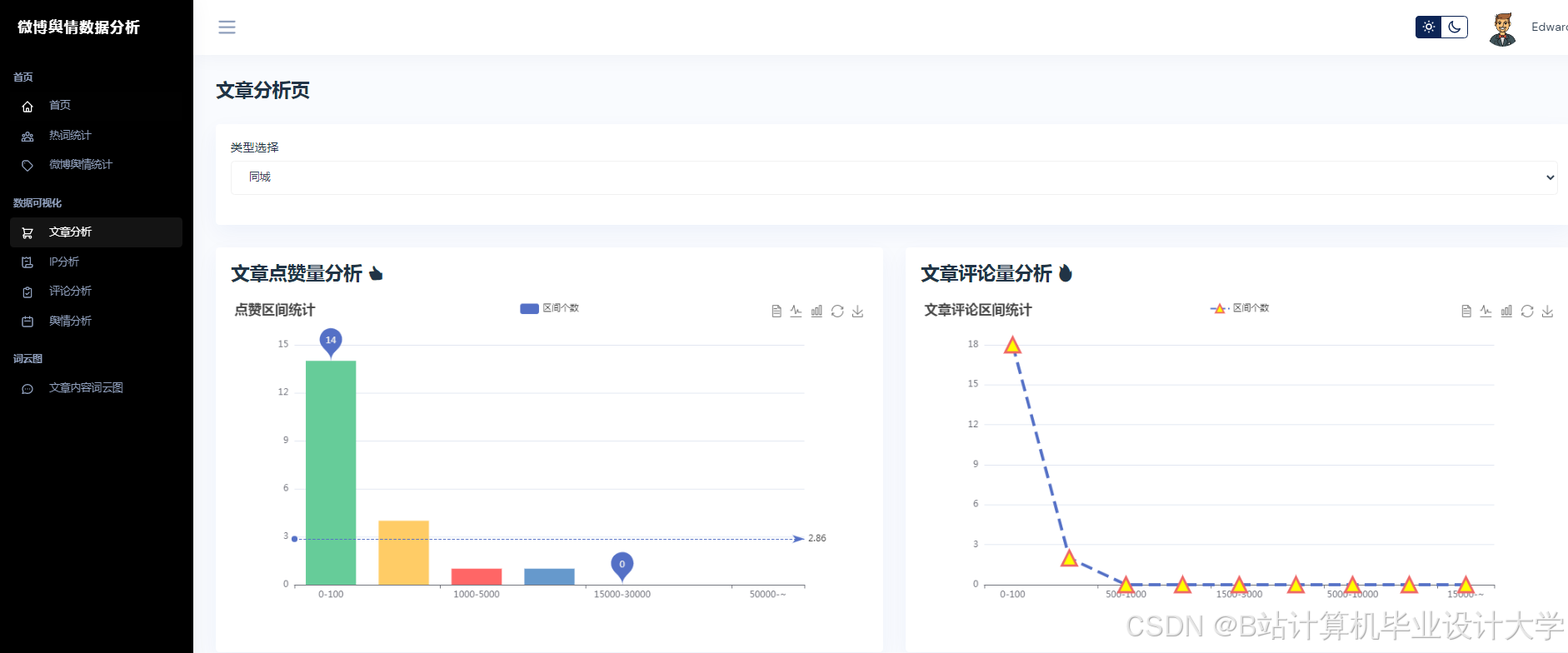
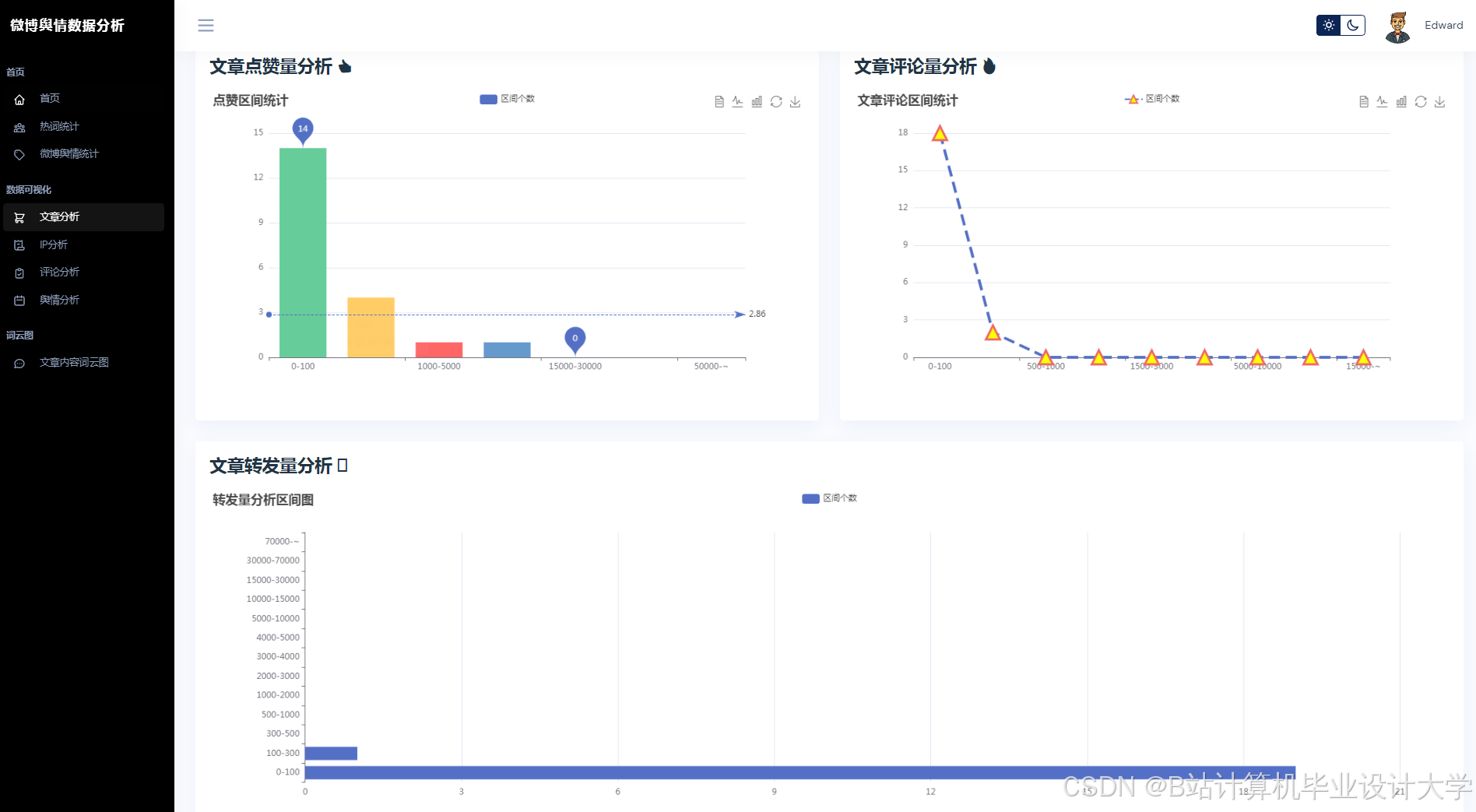
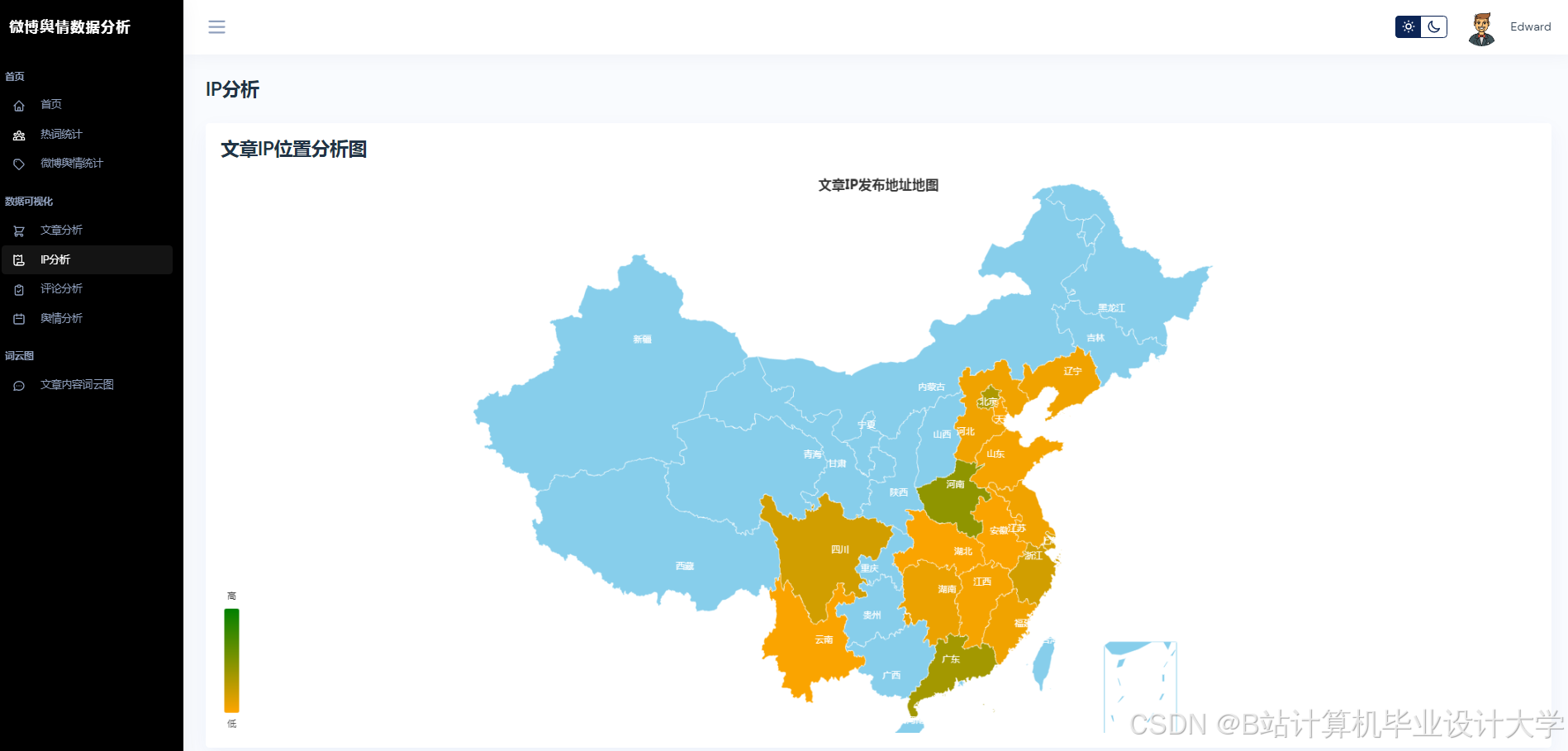
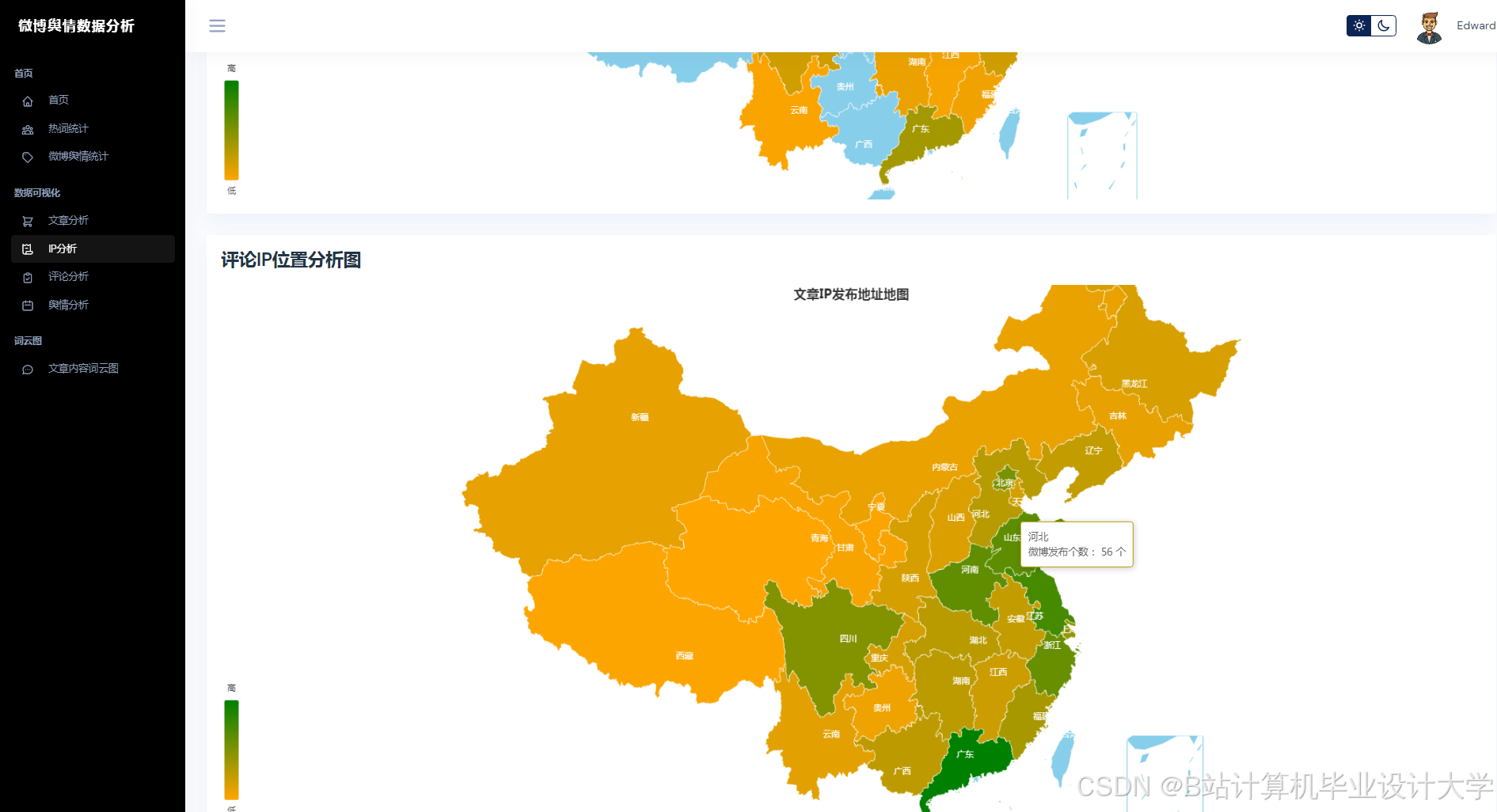
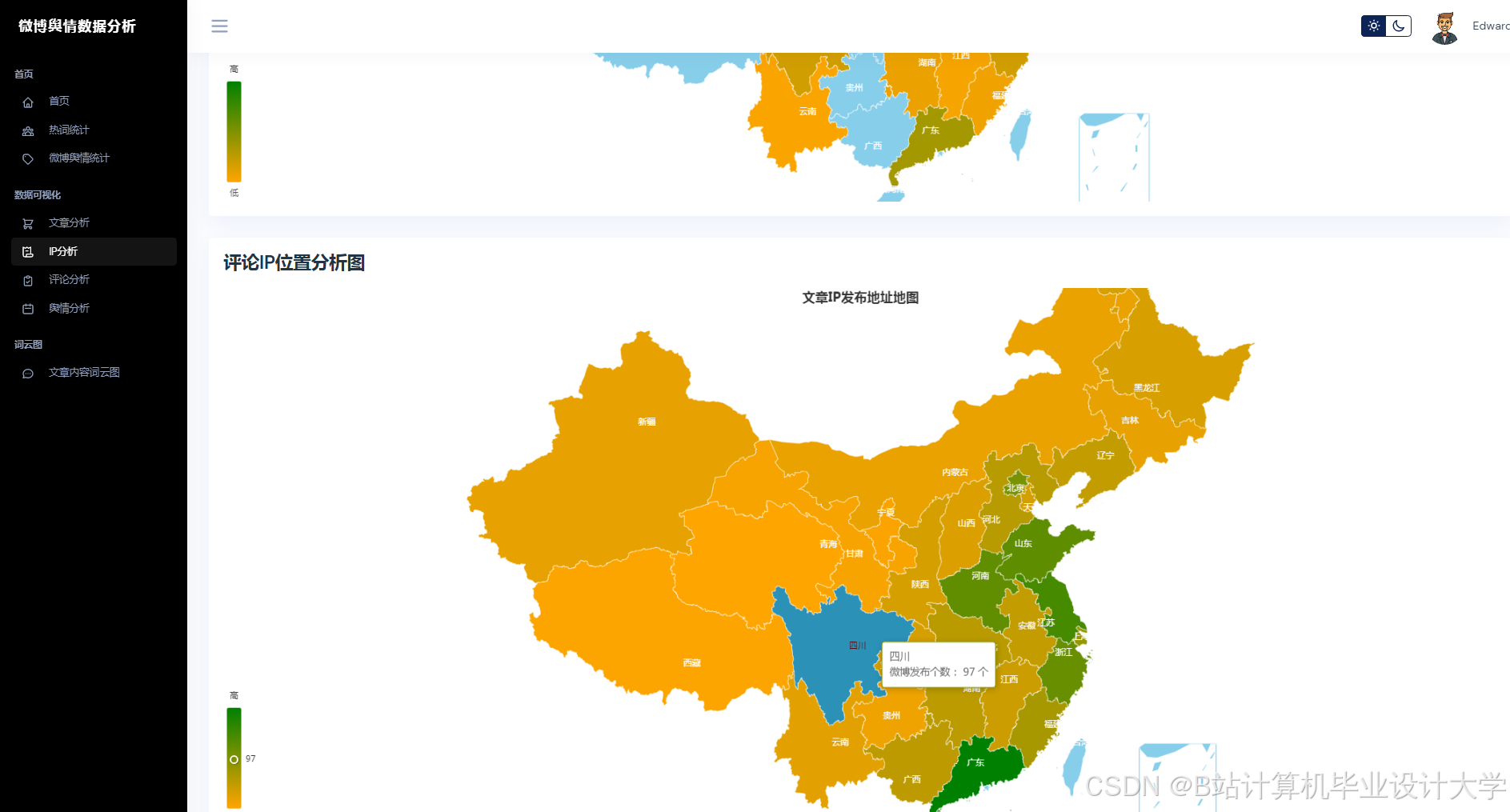
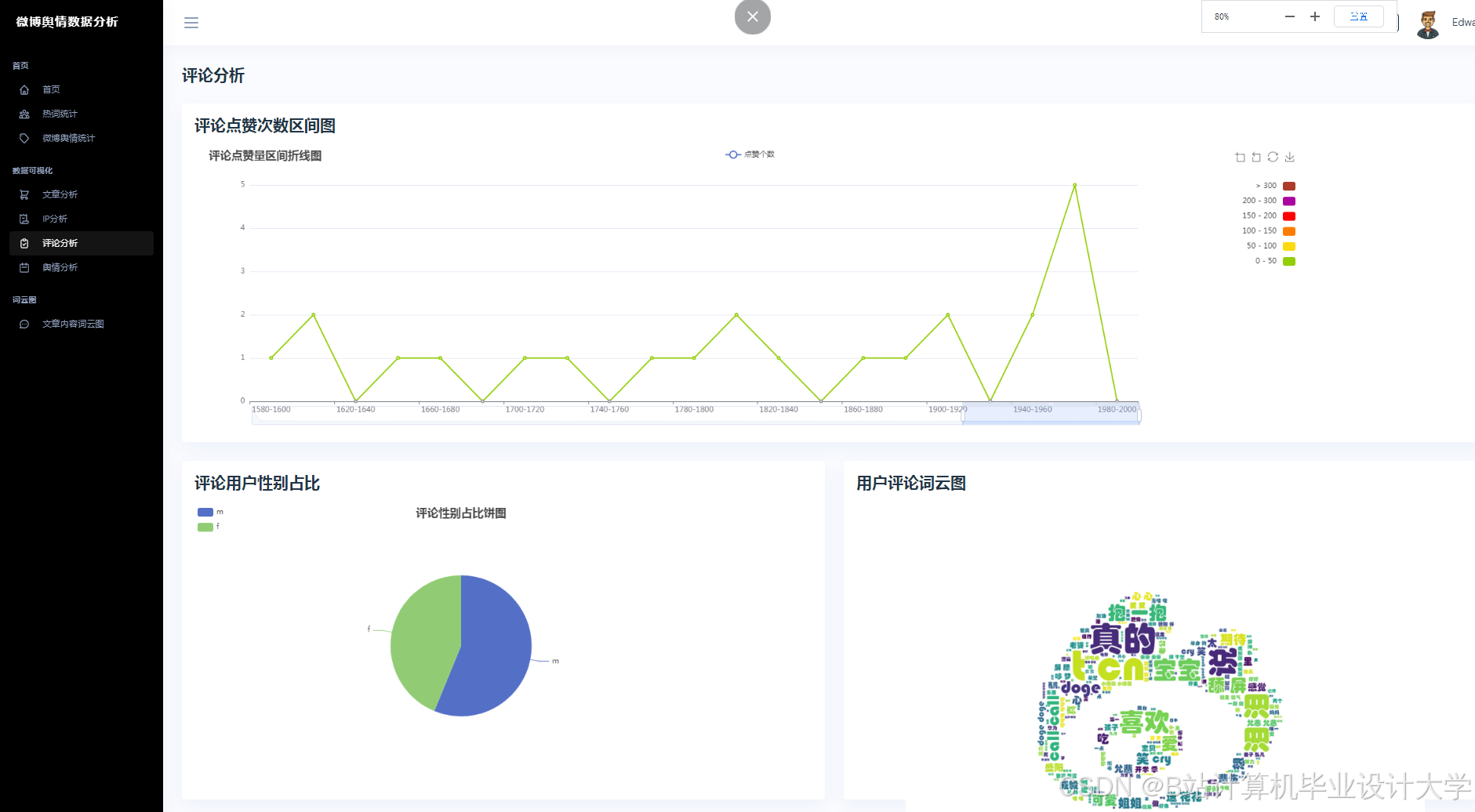

推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











