







开始学爬虫了,记录一下这两天的瞎鼓捣
抓取一个网页
先从最简单的来,指定一个url,把整个网页代码抓下来,这里就拿csdn的主页实验
# -*- coding: UTF-8 -*-
from urllib import request
url = 'http://www.csdn.net/'
html = request.urlopen(url)
# 注意这里要以utf-8编码方式打开
with open('123.txt', 'w', encoding='utf-8') as f:
f.write(html.read().decode('utf-8'))
# 和读文件的操作类似的read()方法,打开url后用read()方法整个页面代码就抓下来了
# 抓下来后需要将编码转换为与所抓取页面相同的utf-8编码
爬到一个网页后,可以找出网页里的链接,然后再继续往下爬,大概就这个思路。先从简单的来,给出我博客的目录链接,把第一页我写的博文全部爬下来。
利用博客目录爬取博文
先把博客目录网页爬下来看看该怎么找出博文的链接
# -*- coding: UTF-8 -*-
from urllib import request
url = 'http://blog.csdn.net/specter11235'
html = request.urlopen(url)
with open('123.txt', 'w', encoding='utf-8') as f:
f.write(html.read().decode('utf-8'))
打开爬出来的源代码,可以看见每个文章的链接都是这种格式


于是就可以利用正则表达式来爬取a href=”“之间的链接了,但是由于在页面中还有其他的链接,如果只是用正则写成a href=”(.*)”,很容易抓到其他的链接去,我试了试发现连着前面span标签里的一大串一块匹配,找到的链接都是文章的,于是代码就这么写
# -*- coding: UTF-8 -*-
from urllib import request
import re
# 博客目录的url
url = 'http://blog.csdn.net/specter11235'
html = request.urlopen(url)
html = html.read().decode('utf-8')
# 构造正则表达式,'.'表示匹配任意字符,'*'表示匹配前一个字符0或无限次
# '(.*)'总之这样配合就是匹配两边字符,把中间的全部取出来
# 构造正则表达式
reurl = re.compile('<span class="link_title"><a href="(.*)">')
# 将构造好的规则与抓取好的网页源代码html进行匹配并输出结果
print(reurl.findall(html))放上输出结果
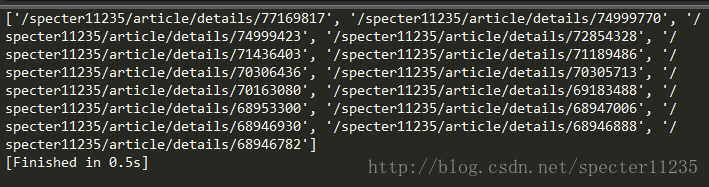
可以看到,页面上的文章链接都出来了,需要加上开头的url处理一下,不过这都很简单。
拿到了这些文章的url之后我们只要把这个url列表遍历,把网址挨个抓取下来保存到文件中即可
# -*- coding: UTF-8 -*-
from urllib import request
import re
import os
url = 'http://blog.csdn.net/specter11235'
html = request.urlopen(url)
html = html.read().decode('utf-8')
reurl = re.compile('<span class="link_title"><a href="(.*)">')
# 判断目录是否存在与创建目录
if not os.path.isdir('./htmltest'):
os.mkdir('./htmltest')
# 遍历url目录
for i in reurl.findall(html):
text_url = 'http://blog.csdn.net' + i
print(text_url)
html = request.urlopen(text_url)
html = html.read().decode('utf-8')
# 构造正则表达式获取文章的标题
rename = re.compile('%s">\s+(.+?)\s+</a>' % i)
# findall()获取到的是列表,需要把字符串内容取出
filename = rename.findall(html)[0]
print(filename)
# 将文章的标题作为文件名进行保存
with open('./htmltest/%s.html' % filename, 'w', encoding='utf-8') as f:
f.write(html)
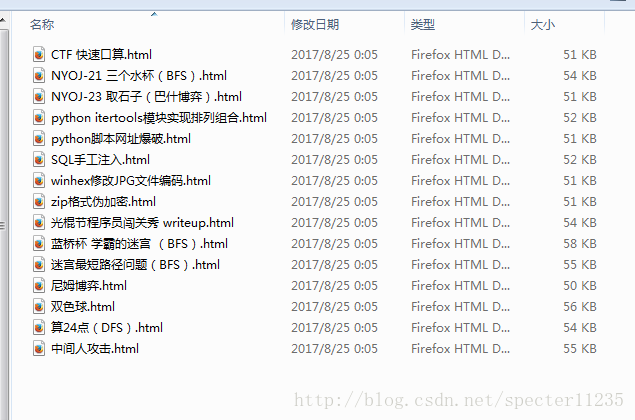
任意打开一篇文章源代码,发现标题格式跟上面目录中是一样的,根据刚刚,只需要用正则将文章链接与/a标签之间的就是标题,中间的空白符可以用\s进行匹配,每篇文章的链接是变化的,不过我们已经保存到i中了,用i进行匹配一下即可,于是就得到上面的代码。
运行后的结果















 2483
2483

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









