






要清楚要分析可变参数函数实现的原理,至少要清楚以下内容:
[1]函数调用栈的生长方向,栈元素大小和对齐方向
[2]C语言的调用约定
由于不同的CPU会对实现有不同,在此以Intel 32位的CPU为分析基础。在Intel CPU中,栈的生长方向是向下的,即栈底在高地址,而栈顶在低地址;从栈底向栈顶看过去,地址是从高地址走向低地址的,因为称它为向下生长,图1显示了这种特性。

图1 某系统或应用程序执行push e语句,栈的变化图。
从上面压栈前后的两个图可明显看到栈的生长方向,在Intel 32位的CPU中,windown或linux都使用了它的保护模式,ss指定栈所有在的段,ebp指向栈基址,esp指向栈顶。显然执行push指令后,esp的值会减4,而pop后,esp值增加4。 栈中每个元素存放空间的大小决定push或pop指令后esp值增减和幅度。Intel 32位CPU中的栈元素大小为16位或32位,由定义堆栈段时定义。在Window和Linux系统中,内核代码已定义好栈元素的大小为32位,即一个字长(sizeof(int))。因此用户空间程栈元素的大小肯定为32位,这样每个栈元素的地址向4字节对齐。
C语言的函数调用约定对编写可变参数函数是非常重要的,只有清楚了,才更欲心所欲地控制程序。在高级程序设计语言中,函数调用约定有如下几种,stdcall,cdecl,fastcall ,thiscal,naked call。cdel是C语言中的标准调用约定,如果在定义函数中不指明调用约定(在函数名前加上约定名称即可),那编译器认为是cdel约定,从上面的几种约定来看,只有cdel约定才可以定义可变参数函数。下面是cdel约定的重要特征:如果函数A调用函数B,那么称函数A为调用者(caller),函数B称为被调用者(callee)。caller把向callee传递的参数存放在栈中,并且压栈顺序按参数列表中从右向左的顺序;callee不负责清理栈,而是由caller清理。 我们用一个简单的例子来说明问题,并采用Nasm的汇编格式写相应的汇编代码,程序段如下:
void callee(int a, int b)
{
int c = 0;
c = a +b;
}
void caller()
{
callee(1,2);
}
来分析一下在调用过程发生了什么事情。程序执行点来到caller时,那将要执行调用callee函数,在跳到callee函数前,它先要把传递的参数压到栈上,并按右到左的顺序,即翻译成汇编指令就是
push 2
push 1
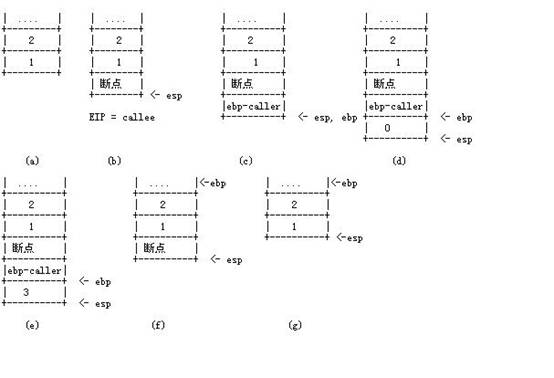
图2 函数栈的变化图
函数栈如图2(a)所示。接着跳到callee函数,即指令call calle。CPU在执行call时,先把当前的EIP寄存器的值压到栈中,然后把EIP值设为callee(地址),这样,栈的图变为如图2(b)。程序执行点跳到了callee函数的第一条指令。C语言在函数调用时,每个函数占用的栈段称为stack frame。用ebp来记住函数stack frame的起始地址。故在执行callee时,最前的两条指令为:
push ebp
mov esp, ebp
经过这两条语句后,callee函数的stack frame就建好了,栈的最新情况如图2(c)所示。 函数callee定义了一个局部变量int c,该变量的储存空间分配在callee函数占用的栈中,大小为4字节(insizeof int)。那么callee会在如下指令:
sub esp, 4
mov [ebp-4], 0
这样栈的情况又发生了变化,最新情况如图2(d)所示。注意esp总是指向栈顶,而ebp作为函数的stack frame基址起到很大的作用。ebp地址向下的空间用于存放局部变量,而它向上的空间存放的是caller传递过来的参数,当然编译器会记住变量c相对ebp的地址偏移量,在这里为-4。跟着执行c = a + b语句,那么指令代码应该类似于:
mov eax , [ebp + 8] ;这里用eax存放第一个传递进来的参数,记住第一个参数与ebp的偏移量肯定为8
add eax, [ebp + 12] ;第二个参数与ebp的偏移量为12,故计算eax = a+b
mov [ebp -4], eax ;执行 c = eax, 即c = a+b
栈又有了新了变化,如图2(e)。至此,函数callee的计算指令执行完毕,但还要做一些事情:释放局部变量占用的栈空间,销除函数的stack-frame过程会生成如下指令:
mov esp, ebp ;把局部变量占用的空间全部略过,即不再使用,ebp以下的空间全部用于局部变量
pop ebp ;弹出caller函数的stack-frame 基址
在Intel CPU里上面两条指令可以用指令leave来代替,功能是一样。这样栈的内容如图2(f)所示。最后,要返回到caller函数,因此callee的最后一条指令是
ret
ret指令用于把栈上的保存的断点弹出到EIP寄存器,新的栈内容如图2(g)所示。函数callee的调用与返回全部结束,跟着下来是执行call callee的下一条语句。
从caller函数调用callee前,把传递的参数压到栈中,并且按从右到左的顺序;函数返回时,callee并不清理栈,而是由caller清楚传递参数所占用的栈(如上图,函数返回时,1和2还放在栈中,让caller清理)。栈元素的大小为4个字节,每个参数占用栈空间大小为4字节的倍数,并且任何两个参数都不能共用同一个栈元素。
到这里,函数调用与栈的故事似乎讲完了,要开始分析可变参数函数的原理了。从C语言的函数调用约定可知,参数列表从右向左依次压栈,故可变参数压在栈的地址比最后一个命名参数还大,如下图3所示:
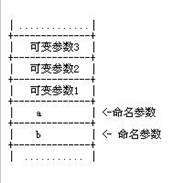
图3 函数调用时参数压栈图
由图3可知,最后一个命名参数a上面都放着可变参数,每个参数占用栈的大小必为4的倍数。因此:可变参数1的地址 = 参数a的地址 + a占用栈的大小,可变参数2的地址 = 可变参数1的地址 + 可变参数1占用栈的大小,可变参数3的地址 = 可变参数2的地址 + 可变参数2占用栈的大小,依此类推。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









