






王迅 sg5050
实验内容:
- 参考进程初探 编程实现fork(创建一个进程实体) -> exec(将ELF可执行文件内容加载到进程实体) -> running program
- 参照C代码中嵌入汇编代码示例及用汇编代码使用系统调用time示例分析fork和exec系统调用在内核中的执行过程
- 注意task_struct进程控制块,ELF文件格式与进程地址空间的联系,注意Exec系统调用返回到用户态时EIP指向的位置。
- 动态链接库在ELF文件格式中与进程地址空间中的表现形式
- 通过300-500字总结以上实验和分析所得,实验情况和分析的关键代码可以作为总结后面的附录以提供详细信息。
实验分析总结:
这次的实验,总体上感觉对我还是偏难。进程方面的东西,暑假补课的时候就有所了解,所以这次实验狠狠得再学习了一下fork()的工作机制,返回父进程ID>0,子进程ID=0。exec函数族用来替换当前正在运行的进程,包括正文,数据,和堆栈段。与一般情况不同,exec函数族的函数执行成功后不会返回,只有调用失败了,它们才会返回一个-1,从原程序的调用点接着往下执行。在Linux下每当有进程认为自己不能为系统和用户做出任何贡献了,就可以调用任何一个exec,让自己以新的面貌重生;更普遍的情况是,如果一个进程想执行另一个程序,它就可以fork出一个新进程,然后调用任何一个exec,这样看起来就好像通过执行应用程序而产生了一个新进程一样。
参照C代码中嵌入汇编代码示例及用汇编代码使用系统调用time示例分析fork和exec系统调用在内核中的执行过程这一块,我参考了不少同学的博客,但是感觉还是不知道该怎么分析,有同学也只是把两段代码编译执行了一下,或者就是写了大段大段的我看不懂的代码分析。
另外两点要求,我也只是看着学一点点东西,对一些概念有所了解,没什么创造性的想法跟难忘的收获。
总之,通过写博客的方式,我能感觉到自己在慢慢学一点东西,慢慢来吧。
附录:
一,进程
当用户敲入一个命令来执行程序的时候,系统就会启动一个进程来执行相应的程序,而在执行程序的这个进程中,系统可能需要再次启动一个或多个进程来完成任务。其中两个基本的操作(fork,exec)用于创建和修改进程。
1,fork()
函数fork()用来创建一个新的进程,该进程是当前进程的拷贝。由fork创建的新进程被成为子进程,fork函数被调用一次,但返回两次,两次返回的区别是子进程的返回值是0,而父进程的返回值则是新子进程的进程ID,出错则返回-1。子进程是父进程的副本,子进程获得父进程数据空间、堆和栈,但是父子进程并不共享这些存储空间部分,父子进程共享正文段。
看下面这个有趣的例子:
/*********fork2.c*********/
#include <sys/types.h>
#include <unistd.h>
int main() {
fork();
fork() && fork() || fork();
fork();
while(1){
}
} 使程序在后台运行,查看生成的新进程的数量,如下:
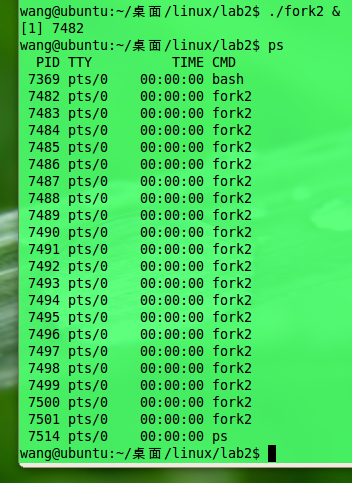
共计生成了20个新进程。
仔细分析,第一个fork和最后一个fork肯定是会执行的。主要在中间3个fork上,可以画一个图进行描述。注意&&和||运算符。
A&&B,如果A=0,就没有必要继续执行&&B了;A非0,就需要继续执行&&B。
A||B,如果A非0,就没有必要继续执行||B了,A=0,就需要继续执行||B。
fork()对于父进程和子进程的返回值是不同的,按照上面的A&&B和A||B的分支进行画图,可以得出5个分支。如下图:
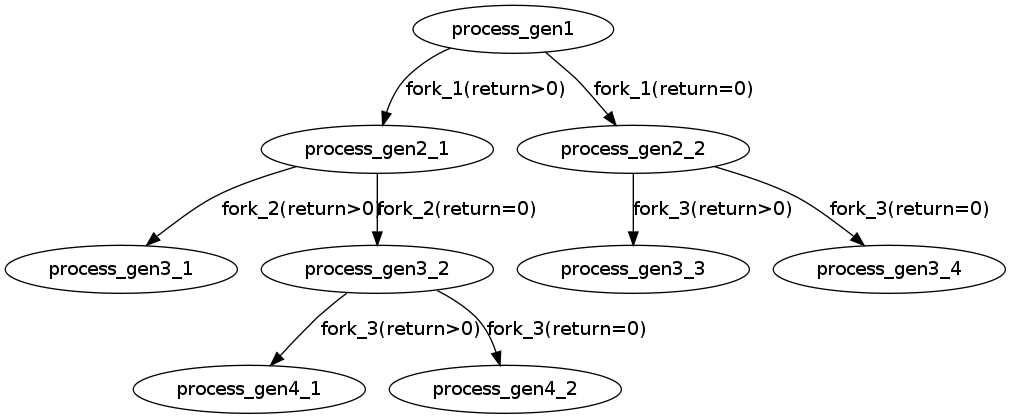
加上前面的fork和最后的fork,总共4*5=20个进程。详情请摸我
2,exec()
函数族exec()用来启动另外的进程以取代当前运行的进程,该进程执行的程序完成替换为新程序,而新程序则从其main函数开始执行。因为调用exec并不创建新进程,所以今后的进程ID并不会
变,exec只是用一个全新的程序替换了当前进程的正文、数据、堆和栈段。
有6个不同的exec函数可供使用,如下所示,这些exec函数使进程控制原语更加完美。用fork创建新进程,用exec可以执行新程序。exec()若成功则不返回值,若出错则返回-1。
int execl(const char *path, const char *arg, ...);
int execlp(const char *file, const char *arg, ...);
int execle(const char *path, const char *arg, ..., char *const envp[]);
int execv(const char *path, char *const argv[]);
int execvp(const char *file, char *const argv[]);
int execve(const char *path, char *const argv[], char *const envp[]); 我们首先编写一个程序,来打印一句话:
childp.c
#include<stdio.h>
int main()
{
printf("子进程运行新程序\n");
return 0;
}然后通过编译生成可执行文件childp
接着我们编写进程创建程序,在子进程中调用该执行文件:
fork.c
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
void main()
{
int i;
if ( fork() == 0 )
{
/* 子进程程序 */
printf("child process starts!\n");
execl("./childp","childp",NULL);
printf("child process ends!\n");
}
else
{
/* 父进程程序*/
printf("parent start\n");
printf("parent end\n");
}
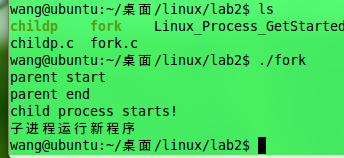
} 下图是执行结果:
其流程如图:
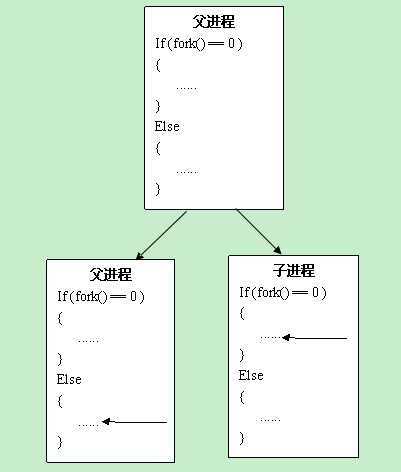
所以由运行结果可知调用childp函数,未能输出”child process ends!”语句,当执行exec时新的程序完全替代的原有的程序,其进程也被替代.
3,fork和exec在内核中的执行过程
fork()
fork()是通过clone( )实现的,clone( )再调用do_fork( )。具体过程如下:
1)通过查找pidmap_array位图,为子进程分配新的PID.
2)检查父进程的ptrace字段.
3)调用copy_process()复制进程描述符,如果所有必须的资源是可用的,该函数返回刚创建的task_struct描述符地址.
4)根据CLONE_STOPPED标志进行不同的操作.
5)如果设置了CLONE_VFORK标志,则把父进程插入等待队列,并挂起父进程直到子进程释放自己的内存地址空间.
6)结束并返回子进程PID.
exec()执行过程
系统中存在一个formats链表,其链表结构分别对应一种可执行文件的执行方法,execl()函数对应的系统调用sys_exec()函数会分配一个linux_binprm数据结构并将可执行文件的数据拷贝到其中,并依次扫描formats链表试图执行这个可执行文件,一旦找到了就执行链表结构中的load_binary方法,其主要步骤为:
1)将可执行文件的首部拷贝至内存;
2)根据动态链接程序路径名将共享库对应函数映射到内存;
3)释放原进程的内存描述符、线性区描述符、所有页框;
4)选择线性区的布局;
5)为可执行文件的代码段、数据段以及动态链接程序的代码段、数据段分别进行内存映射;
6)修改内核态堆栈中eip、esp寄存器的值,使其分别指向程序的入口点以及新的用户态堆栈顶并返回;
二,task_struct进程控制块,ELF文件格式与进程地址空间的联系,注意Exec系统调用返回到用户态时EIP指向的位置
1, task_struct进程控制块结构
在linux 中每一个进程都由task_struct 数据结构来定义。task_struct 就是我们通常所说的PCB.她是对进程控制的唯一手段也是最有效的手段. 当我们调用fork() 时, 系统会为我们产生一个task_struct 结构体。然后从父进程,那里继承一些数据, 并把新的进程插入到进程树中, 以待进行进程管理。task_struct的结构如下:
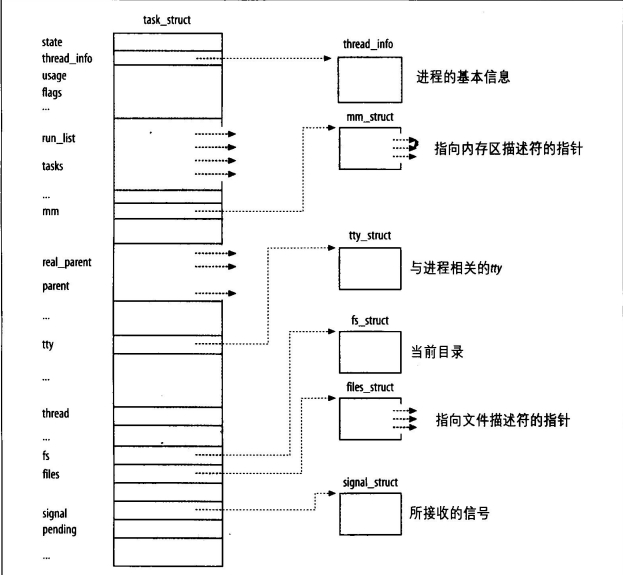
2,ELF文件格式
ELF文件里面,每一个 sections 内都装载了性质属性都一样的内容,.text section 里装载了可执行代码; .data section 里面装载了被初始化的数据; .bss section 里面装载了未被初始化的数据;以.rec 打头的 sections 里面装载了重定位条目; .symtab 或者 .dynsym section 里面装载了符号信息;.strtab 或者 .dynstr section 里面装载了字符串信息; 其他还有为满足不同目的所设置的section,比方满足调试的目的、满足动态链接与加载的目的等等。如下图:

3, ELF文件格式与进程地址空间的关系
进程地址空间中典型的存储区域分配情况如下:
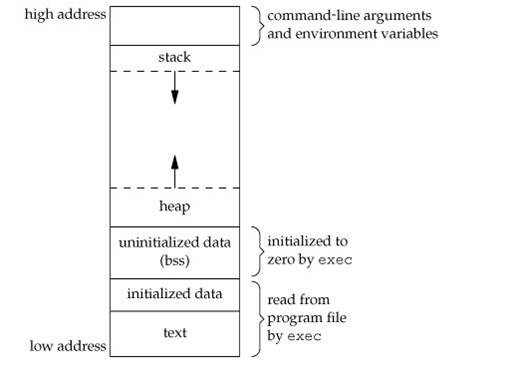
从低地址到高地址分别为:代码段、(初始化)数据段、(未初始化)数据段(BSS)、堆、栈、命令行参数和环境变量。其中堆向高内存地址生长,栈向低内存地址生长。
task_struct进程控制块中的mm字段所指向的mm_struct结构描述了进程地址空间的信息,包括代码段、数据段、堆段、栈段所在地址空间里的起始和结束地址等信息。
ELF文件格式中的 ELF头部、段头部表、.init、.text、.rodata段对应进程地址空间中的代码段,在加载可执行文件时,会把它们映射到进程地址空间中的代码段区域。
ELF文件格式中的 .data、.bss段 对应 进程地址空间中的 数据段,在加载可执行文件时,会把它们映射到进程地址空间的数据段区域。
对于相同权限的段,把它们合并在一起当作一个段进行映射。如.text和.init,它们包含的分别的是程序的可执行代码和初始化代码,并且它们的权限相同,都是可读并且可执行。假设.text为4097字节,.init为512字节,这两个段分别映射的话需要占用三个页面,因为一个页面的大小为4KB。如果把它们合并成一起映射的话只需占用两个页面。

三、动态链接库在ELF文件格式中与进程地址空间中的表现形式
库有动态与静态两种,动态通常用.so为后缀,静态用.a为后缀。例如:libhello.so libhello.a
为了在同一系统中使用不同版本的库,可以在库文件名后加上版本号为后缀,例如: libhello.so.1.0,由于程序连接默认以.so为文件后缀名。所以为了使用这些库,通常使用建立符号连接的方式。
ln -s libhello.so.1.0 libhello.so.1
ln -s libhello.so.1 libhello.so
当要使用静态的程序库时,连接器会找出程序所需的函数,然后将它们拷贝到执行文件,由于这种拷贝是完整的,所以一旦连接成功,静态程序库也就不再需要了。然 而,对动态库而言,就不是
这样。动态库会在执行程序内留下一个标记‘指明当程序执行时,首先必须载入这个库。由于动态库节省空间,linux下进行连接的 缺省操作是首先连接动态库,也就是说,如果同时存在静态和动态库,不特别指定的话,将与动态库相连接。
动态连接的本质,就是对ELF文件进行重定位和符号解析。重定位可以使得ELF文件可以在任意的执行(普通程序在链接时会给定一个固定执行地址);符号解析,使得ELF文件可以引用动态数据(链接时不存在的数据)。从流程上来说,我们只需要进行重定位。而符号解析,则是重定位流程的一个分支。
动态链接库在ELF文件中对应着.dynamic段所包含的信息:包括动态链接器所需要的相关信息,比如依赖于哪些共享对象(例如libc.so)、动态链接符号表位置、动态链接重定位表的位置、共享对象初始化代码的地址等信息。动态链接库最后被映射到进程地址空间的共享库区域段。















 1641
1641











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









