







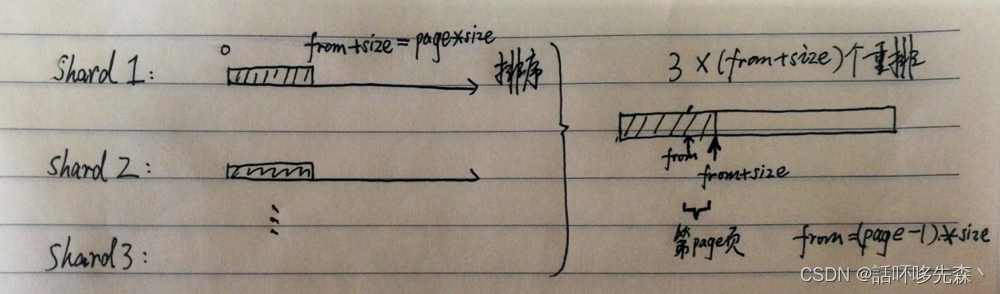
1、from-size浅分页
from表示初始偏移量,默认为0。size表示单页返回最大文档条数,默认为10。假设我们在有5个主分片的索引中搜索,查询第一页数据,即前10条数据,那么es会从每个分片中生成排序好的结果,取出前10条,然后返回给请求节点,请求节点再将这50条记录再次排序选出前10条。
ps:使用ElasticSearch的form+size方式分页时,当查询记录超过10000时,会保如下错:
Result window is too large, from + size must be less than or equal to: [10000] but was [10025]. See the scroll api for a more efficient way to request large data sets. This limit can be set by changing the [index.max_result_window] index level parameter.查询文档可知:
index.max_result_window The maximum value of from + size for searches to this index. Defaults to 10000. Search requests take heap memory and time proportional to from + size and this limits that memory. See Scroll or Search After for a more efficient alternative to raising this.解决办法:
// 修改最大条数限制
PUT index/_settings
{
"index":{
"max_result_window":200000
}
}但是如果请求的是第1000页的数据,即第10001至第10010条数据。那么es会从5个分片中取出各个分片顶端的10010条数据,然后将这总共50050条数据返回给请求节点,请求节点再次对这50050条数据进行一次全局排序,取出第10001至10010条数据,抛弃50040条数据,而且每次翻页都需要重新排序,这就造成了很大的浪费。
在分布式系统中排序的花费会随着分页的深度而成倍增长,如果数据特别大对CPU和内存的消耗会非常巨大甚至会导致OutOfMemory,所以这也是为什么网络搜索引擎不能返回多于10000个结果的原因。ES使用index.max_result_window:10000作为保护措施 ,即默认 from + size 不能超过10000,虽然这个参数可以动态修改,也可以在配置文件配置,但是不推荐这么做。
2、scroll方式
Request body search | Elasticsearch Guide [8.3] | Elastic
http://lxwei.github.io/posts/使用scroll实现Elasticsearch数据遍历和深度分页.html
可以看出上述from/size的分页方式当分页深度很深时是存在问题的,因此很多业务直接限制了过深的分页。但是某些业务是需要遍历全量数据的,例如把某个索引下的文档reindex到一个新的不同配置的索引下,再例如消息的群发等。
scroll API 就适用于这种期望一次请求返回大量数据甚至全部数据的情况。为了更好的说明scroll的工作方式,首先说明一下ES搜索的内部执行原理,默认的query then fetch类型检索分为query和fetch两个阶段,query阶段较为轻量级,由每个shard返回排序后的前N各文档的id和排序需要的score值,然后进行全局排序,fetch阶段再去对应分片取符合条件的全部文档,以减小网络开销。
scroll API就利用这个特点,使用scroll方式做检索分为两个阶段,首次查询和后续查询。首次查询时,会对按查询条件query的结果做一个快照,并指定这个快照的维持时间(见:Keeping the search context alive),返回结果包含一个scroll_id。在后续查询时,仅需要此scroll_id即可找到上次查询的退出地点,接着取出下一页的值,并返回新的scroll_id用于接下来的查询。当某次返回的结果[hits][hits]为空,即返回了所有的结果时,scroll查询终止。因为采用了这种快照的方式,在首次查询结束后,对ES里文档的(更新、建索引、删除)都不会影响查询的结果,也即对实时性要求高的查询并不适合使用scroll。
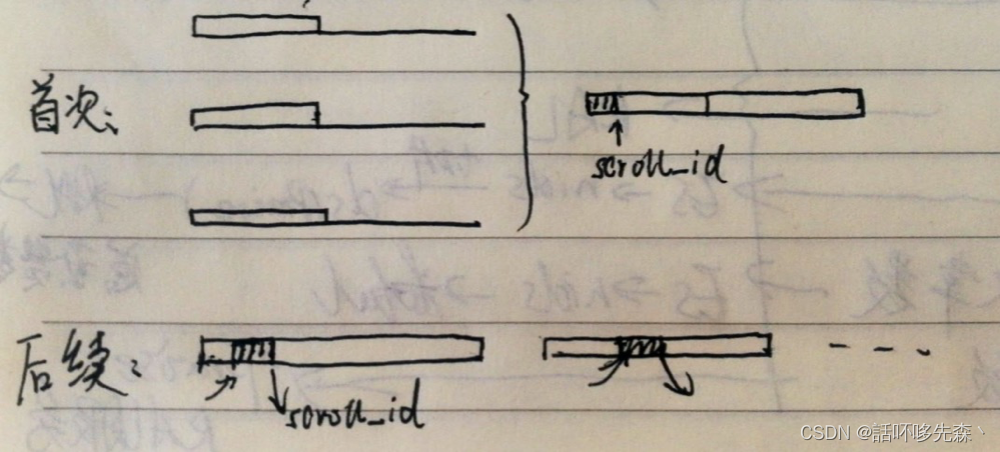
ps:
- scroll首次查询设置的一分钟,不是指整个查询限时为1分钟,而是到下一次查询还有1分钟的时间。每次查询都会指定新的维持时间,并重新计时。如果超时,清除context此次查询失效,需重新执行首次查询。
- 后续请求时url中不应该有index和type,这些都在初始请求中,后续只需要使用scroll_id和scroll两个参数即可,其中scroll_id可以放在url中也可以放在请求体中。
- 当只需要获得全部数据而不考虑数据排序时,可以使用 '_id'(见下代码)作为排序依据,es对此做了优化,会很大的提高速度。
- 需要将每次将返回的scroll_id用于下次查询。
- 清除scroll,虽然scroll的有效时间到后,context会清除,但是如果能在使用完后手动删除,可以提早释放资源,降低ES的负担。
//首次查询
curl -u $user:$password -H "Content-Type:application/json" -XGET "http://$ip:$port/$index/type/_search?scroll=1m' -d ' //scroll=1m 即快照有效时间为1分钟
{
"query":{
"match":{
"name":"LEMON"
},
"size":1000 //可以指定size大小,就是每页的文档数,当回传到没有数据时,仍会返回200成功,只是hits里的hits是空List
}
}
//后续查询
curl -XGET 'http://$ip:$port/$index/_search/scroll' -d'
{
"scroll":"1m",
"scroll_id":"c2Nhbjs2OzM0NDg1ODpzRlBLc0FXNlNyNm5JWUc1"
}
//手动释放多个scroll
curl -XDELETE /_search/scroll
{
"scroll_id":[
"DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAAD4WYm9laVYtZndUQlNsdDcwakFMNjU1QQ==",
"DnF1ZXJ5VGhlbkZldGNoBQAAAAAajZkTGlIYkJWZDFhQQAAAAMWFB"
]
}
//释放所有
DELETE /_search/scroll/_all3、search after方式
from/size的方式在用于深分页代价高昂,scroll可以高效的深分页,但是维持上下文开销较大,而且存在实时性的问题。search after参数通过设置一个活动游标(a live cursor),这种方法的思想和scroll很像,只是在首次query得到查询结果排序后,并不保存这个快照,而是只保存用于排序的最后一个的值。在下次查询时,每个分片只返回这个排序值之后的值,因此需要使用文档里唯一的字段作为排序依据,推荐将_id字段复制到另一个字段,并enable doc_value(tie_breaker_id)。如下图,红色部分为当次查询总排序后,在分片中取的数据。结合图片可以看出,不同于from/size方式,search_after每次全局排序的量不会随着页数增加而增加,而且每次查询均是实时的。
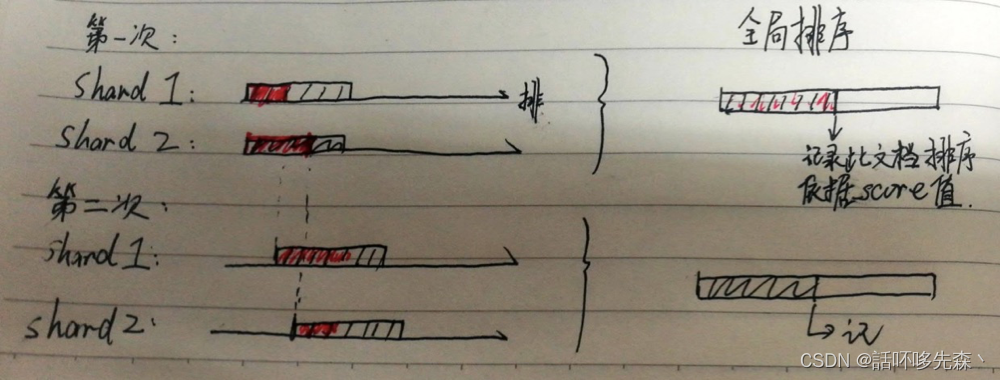
ps:from值需要设置为0或-1
GET index/_search
{
"size":10,
"query":{
"match":{
"name":"LEMON"
}
},
"search_after":[
"123456789" //上页末尾文档排序依据值
],
"sort":[
{
"tie_breaker_id":"asc"
}
]
}4、id与_uid
区别:_id在特定query中可以被获取,如term, terms, query_string,但在聚合统计、自定义脚本以及排序时,不可以被使用,此时只能通过_uid来代替
联系:_uid实际上是index下的type与_id拼接,格式为_uid=type#_id
-
6.0版本之前,可以用 _uid去代替 _id,_id是不支持排序的,因为_id默认是not index的,而_uid其实是一个 _type + _id的字符串。

- 6.0版本之后,_id会被建索引,也可以支持aggregate和sort了,_uid不再单独存在,而是_id的别名。如果要按_id排序,不建议直接用_id,而是可以拷贝_id值到另一个新字段,新字段启用docvalue,这样可以节省内存使用
- 如果_id是123456789,并且也搜索了123。。,它仍然会匹配该文档并返回在它后面找到的结果。此字段上的文档值被禁用,因此对其进行排序需要在内存中加载大量数据。相反,建议在另一个启用了doc value的字段中复制id字段的内容,并使用此新字段作为排序的分条符。
- 如果_id是123456789,并且也搜索了123。。,它仍然会匹配该文档并返回在它后面找到的结果。此字段上的文档值被禁用,因此对其进行排序需要在内存中加载大量数据。相反,建议在另一个启用了doc value的字段中复制id字段的内容,并使用此新字段作为排序的分条符。
5、form_size / scroll / search_after 性能比较
假设执行如下查询:
GET index/_search
{
"query":{
"match":{
"name":"LEMON"
}
}
}| es分页性能对比表 | 【1 - 10】 | 【49000 - 49010】 | 【 99000 - 99010】 |
|---|---|---|---|
| form_size | 8ms | 30ms | 117ms |
| scroll | 7ms | 66ms | 360ms |
| search_after | 5ms | 8ms | 7ms |
6、总结
| 实时性 | 跳页查询 | 应用场景 | |
|---|---|---|---|
| from/page | Y | Y | 列表展示、浅分页 |
| scroll | N | N | 查询大量(全部)数据、reindex |
| search_after | Y | N | 滚动下拉 |


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









