







文章转自:http://blog.csdn.net/v_july_v/article/details/7041827
作者:July
记得第一次接触KMP算法的时候是在初中,那个时候搞NOIP的竞赛。直到上了高中搞NOI,都一直没有搞清楚KMP算法的原理。现在正好有时间,可以理一理对KMP算法的理解。
KMP算法大家应该不陌生,主要的精髓集中在对Next[ ]数组的求解,下面借助大神JULY的文章,一起研究研究高大上的KMP算法。
咱们首先给出KMP算法的结论:
1.假设现在S串匹配到 i 位置,T串匹配到 j 位置
如果当前字符匹配成功,即S[i] == T[j] 令i++,j++,继续匹配下一个字符;
如果失配,即S[i] != T[j] 令i不变,j = next[j],(next[j] <= j - 1),即模式串T相对于原始串S向右移动了至少1位
(换言之,当匹配失败时,模式串向右移动的位数为:失配字符所在位置 - 失配字符对应的next 值,即移动的实际位数:j-next[j] >= 1)
步骤
- ①寻找最长前缀、后缀
- 对于Pj = p0 p1 ...pj-1 pj,查找字符串Pj的最大相等k前缀和k后缀
- 即查找满足条件的最大的k,使得p0 p1 ...pk-1 pk = pj-k pj-k+1...pj-1 pj
- 对于Pj = p0 p1 ...pj-1 pj,查找字符串Pj的最大相等k前缀和k后缀

- ②求next数组
- 根据第①步骤中求得的各个最大前缀后缀的公共元素长度求得next 数组,相当于前者右移一位且初值赋为-1

- ③匹配失配
- 向右移动位数:j - next[j] (注:j 是位置,next数组中,j 从0开始计数。)
前缀后缀
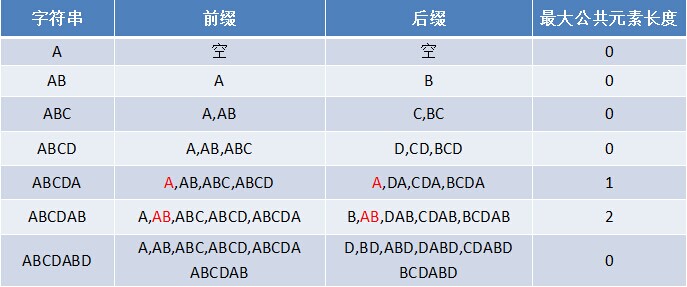

基于《最大长度表》匹配
下面,咱们就结合之前的最大长度表和上述结论,进行字符串的匹配。给定如下图所示的原始串和模式串

失配时,模式串向右移动的位数为:已匹配字符数 - 失配字符的上一位字符所对应的最大长度值
- ①当模式串最后一个字符D跟原始串匹配时失配,显而易见,模式串需要向右移动。但向右移动多少位呢?
- 如果利用最原始的朴素匹配算法,那么把模式串不断的向右移动一位,直到全部字符实现匹配;
- 事实上,因为此时已经匹配的字符数为ABCDAB,然后根据《最大长度表》可得字符B对应的长度值为2,所以根据之前的结论,可知需要向右移动6 - 2 = 4 位。

- ②模式串向右移动4位后,发现C处再度失配,因为此时已经匹配了AB两个字符,且上一个字符B对应的最大长度值为0,所以向右移动:2 - 0 =2 位。

- ③A与空格失配,向右移动一位。
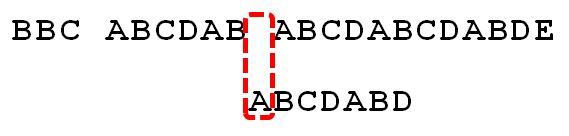
- ④继续比较,发现D与C 失配,故向右移动的位数为:已匹配的字符数减去上一位字符B对应的最大长度,即向右移动6 - 2 = 4 位。

- ⑤经历第④步后,发现匹配成功,过程结束。

最大长度表引出next 数组
由上文,我们已经知道,字符串“ABCDABD”各个前缀后缀的最大公共元素长度分别为:

而且,根据这个表可以得出下述结论
- 失配时,模式串向右移动的位数为:已匹配字符数 - 失配字符的上一位字符所对应的最大长度值

把next 数组跟之前求得的最大长度表对比后,不难发现,next 数组相当于“最大长度值” 整体向右移动一位,然后初始值赋为-1。意识到了这一点,你会惊呼原来next 数组的求解竟然如此简单!从而有
失配时,模式串向右移动的位数为:失配字符所在位置 - 失配字符对应的next 值
而后,你会发现,无论是基于最大长度表的匹配,还是基于next 数组的匹配,两者得出来的向右移动的位数是一样的。不信的话,咱们可以来看看具体过程。
基于《next 数组》匹配
下面,我们来基于next 数组进行匹配。

- ①匹配到字符D时失配,由于 j 从0开始计数,故数到失配的字符D时 j 为6,且字符D对应的next 值为2,所以向右移动的位数为:j - next[j] = 6 - 2 =4 位
- ②向右移动4位后,C再次失配,向右移动:j - next[j] = 2 - 0 = 2 位
- ③移动两位之后,A 对应着空格导致不匹配,再次后移一位
- ④D处失配,向右移动 j - next[j] = 6 - 2 = 4 位
- ⑤匹配成功,过程结束。
匹配过程一模一样。也从侧面佐证了,next 数组确实是只要将各个最大前缀后缀的公共元素的长度值右移一位,且把初值赋为-1 即可。
基于《最大长度表》与基于《next 数组》等价
其实,利用next 数组进行匹配失配时,模式串向右移动 j - next [ j ] 位,等价于已匹配字符数 - 失配字符的上一位字符所对应的最大长度值。为什么呢?
- j 从0开始计数,那么当数到失配字符时,j 的数值就是已匹配的字符数;
- 由于next 数组是由最大长度值表整体向右移动一位(且初值赋为-1)得到的,那么失配字符的上一位字符所对应的最大长度值,即为当前失配字符的next 值。
那为何本文不直接利用next 数组进行匹配呢?因为next 数组不好求,而一个字符串的前缀后缀的公共元素的最大长度值很容易求,例如若给定字符串“abab”,要你求其next 数组,则乍一看,无从求起,而要你求其前缀后缀公共元素的最大长度,则很容易得出是:0 0 1 2,如下表格所示:
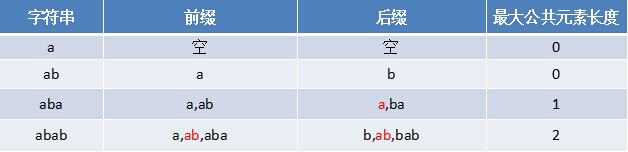
然后这4个数字 全部整体右移一位,且初值赋为-1,即得到其next 数组:-1 0 0 1。















 600
600

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









