







在使用查询语句时,inner join,left join,right join等这些联接语句,想必大家并不陌生,而且经常会用到,联接达到了我们想要的结果,可是当数据越大越大的时候,会发现查询很慢,往往只是加索引进行优化,可是有时候,索引并不能解决问题,这时就束手无策了!
下面以真实的例子说明这个问题,下面有二张表,一张rank(排行榜),10000余条数据,一张person(人物)3条数据
CREATE TABLE joye_rank (
rank_id int(10) NOT NULL AUTO_INCREMENT,
rank_personId int(10) NOT NULL, '玩家上传分数使用的人物ID'
rank_score int(10) NOT NULL COMMENT '最高分',
rank_uploaduser varchar(50) NOT NULL COMMENT '上传用户',
rank_uploadtime datetime NOT NULL COMMENT '上传时间',
rank_regtime timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (rank_id),
UNIQUE KEY idx_uploaduser (rank_uploaduser) USING BTREE,
KEY idx_score_time (rank_score,rank_uploadtime) USING BTREE,
KEY idx_personid (rank_personId) USING BTREE
)
CREATE TABLE joye_person(
person_id int(10) NOT NULL AUTO_INCREMENT,
person_name varchar(10) NOT NULL COMMENT '人物名称',
person_sort int(10) NOT NULL COMMENT '排列序号',
person_regtime timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (person_id),
)
接下来,有个需求是这样,查询排名前100的用户有哪些,此时需要返回人物名称,分数,上传用户,按时最高分倒序排列,如果最高分相同则按人物排列序号(person_sort字段,暂时不考虑用它排序)升序排列,最后再按照上传时间倒序排列。
先说下我的思路,在这里,我需要二个字段进行排序,rank_score,rank_uploadtime,为了使查询更快,我需要以rank_score,rank_uploadtime建立联合索引,以免mysq使用文件排序,(using filesort)以下就是这个需求的SQL语句:
SELECT rank.rank_score,rank.rank_uploaduser FROM joye_rank AS rank
INNER JOIN joye_person as person ON rank.rank_personId=person_id WHERE rank_score > 0
ORDER BY rank.rank_score DESC,rank_uploadtime DESC LIMIT 100;
看完这条SQL语句,相信大家都知道这条SQL完全没有问题,可以达到我们相要的结果,
可是平均查询费时0.010s!如果我去掉SQL语句中的第二行,即inner join这一行,会发现,平均查询费时0.000s!OK,现在我们知道问题了,开始进行优化,个人进行优化的第一步使用EXPLAIN命令,查看mysql是如何执行的,结果如下:

就注意红圈处,这里的意思是:mysql先通过where条件过滤掉最高分小于0的,然后把查询结果放到了临时表里(在内存里面),最后按照文件对结果进行排序!这就是导致查询慢的原因。(如果你不了解上图中每一列的意思,请点击:http://blog.csdn.net/spring_yyy/article/details/12971183)。
下面问题就是,我明明建了rank_score,rank_uploadtime的索引,为什么这里使用文件排序?但是索引它确实又用到了!百思不得其解,之前说到,去掉inner join查询会变快,现在看看,去掉它是什么情况:

这里,我们发现,没有inner join时,没有使用文件排序,我们大致知道原因所在了,那么,为什么用了inner join后,mysql用使用文件排序呢?
Mysql在遇到inner join联接语句时,MySQL表关联的算法是 Nest Loop Join(嵌套联接循环),Nest Loop Join就是通过两层循环手段进行依次的匹配操作,最后返回结果集合。SQL语句只是描述出希望连接的对象和规则,而执行计划和执行操作要切实际将一行行的记录进行匹配。Nest Loop Join的操作过程很简单,很像我们最简单的排序检索算法,两层循环结构。进行连接的两个数据集合(数据表)分别称为外侧表(驱动表)和内侧表(非驱动表)。Mysql又会怎样去确定,哪张表是驱动表,哪张表又是非非驱动表呢?mysql它以表中数据最小的一张表作为驱动表(也就是基表),而另一张表就叫做非驱动表,首先处理驱动表中每一行符合条件的数据,之后的每一行数据和非驱动表进行连接匹配操作,直到循环结束,最后合并结果、返回结果给用户。对于驱动表的字段它是可以直接排序的,然而对于非驱动表的字段排序需要通过循环查询的合并结果(临时表)进行排序,因此,order by rak_score desc,rank_uploadtime desc 时,就先产生了 using temporary(使用临时表),而我们都知道,数据库的底层就是IO操作,数据库无法对表排序,所以最后要借助于磁盘,那么产生using filesort(使用文件排序)就不难理解了!任何问题都是有解决方法的,接下来就是要解决这个问题,要达到相同的结果,使用一条SQL语句,那么该如何解决这个问题呢?
回想一下,前面说过,在查询中去掉inner join,它就会对排序走索引,不会出现文件排序,既然是这样,试想一下,我们是不是可以把去掉inner join的语句在子查询中先查出来(在这里也称派生表),然后在用这个结果去做两张表的关联呢?
SELECT person_id,person_name,rank.rank_person,rank.rank_score,rank.rank_uploaduser FROM(
SELECT rank.rank_personId,rank.rank_score,rank.rank_uploaduser
FROM joye_rank AS rank
WHERE rank_score > 0
ORDER BY rank_score DESC,rank_uploadtime DESC LIMIT 100
) tmp
INNER JOIN joye_person as person ON person.person_id=tmp.rank_personId ;
这条SQL,首先在form中的子查询采用没有inner join的语句查出结果,这个结果会产生临时表,存在于内存当中,我们在内存当中就对它进行排好序,所以不会出现using temporary,using filesort。最后在用这个临时表tmp去关联person表,在tmp 后面的语句只是一个以inner join以及联接条件on的简单语句,并没有排序和其它操作。所以,最后可以完全可以肯定,mysql不会产生问题using temporary,using filesort,那这样问题就已经得到解决了!
上面红色的部份mysql在执行时会产生派生表,因为它是form子句中的子查询!由于它存在于内存当中,所以使用的时候,千万不要用*号,只取需要用到的数据,以免占用太多内存!
同时也要避免使用派生表,最好采用其他方式来编写查询语句,大部分情况都比派生表来的快。很多情况下,甚至连独立的临时表都来的快,因为派生表无法增加索引。
可以考虑使用视图来取代派生表如果确实需要在 FROM子句中使用到子查询,可以考虑在查询时创建试图,当查询完之后删除试图。
所以,上面的SQL也可以用以下的视图来解决
首先创建视图,
CREATE VIEW view_rank AS SELECT rank.rank_personId,rank.rank_score,rank.rank_uploaduser
FROM joye_rank AS rank
WHERE rank_score > 0
ORDER BY rank_score DESC,rank_uploadtime DESC LIMIT 100;
改写后的SQL语句:
SELECT person_id,person_name,person_sort,person_head,rank_score,rank_uploaduser
FROM view_rank as rank INNER JOIN joye_person as person ON person.person_id=rank.rank_personId ;
注意,上面这条SQL语句from后面跟的是视图名而不是表名
用以上两条SQL,最终产生的结果一下!用EXPLAIN命令查看一下它的执行计划:
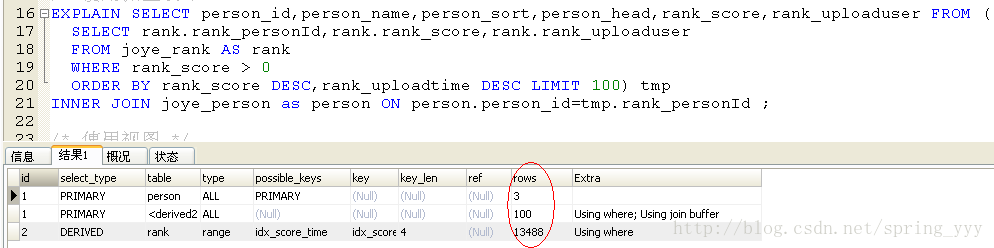
这里,我们发现已经没有using temporary, using filesort说明我们已经解决了这个问题,最后看看rows这一列的数据.
第一行为3:全表示扫描person表,共3条数据,没有任何条件,所以主键索引,没用上!
第二行为100:全表扫描from子句中的子查询,共100条数,因是派生表,所以没有索引!
第三行为13488:通过索引score扫表rank表,共扫出13488条数据!

















 1868
1868

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









