







这篇文章是在对《编写高质量代码:改善Java程序的151个建议》这本书中提到的内容做笔记。
通用的方法和准则
三元操作符的类型务必唯一
<span style="font-size:18px;">public class Client {
public static void main(String[] args) {
int i = 80;
String s = String.valueOf(i<100?90:100);
String s1 = String.valueOf(i<100?90:100.0);
System.out.println("两者是否相等:"+s.equals(s1));
}
}</span>别人null值和空值影响变长方法
<span style="font-size:18px;">public class Client {
public void methodA(String str,Integer... is){
System.out.println("Integer");
}
public void methodA(String str,String... strs){
System.out.println("String");
}
public static void main(String[] args) {
Client client = new Client();
client.methodA("China", 0);
client.methodA("China", "People");
// client.methodA("China");
// client.methodA("China",null);
}
}</span>//client.methodA("China") 由于变长方法重载,都满足只有一个String的参数,编译器没办法知道选在哪个函数,因此编译不通过。
//client.methodA("China",null) null是没有类型的。编译器没办法知道选在哪个函数,因此编译不通过。
可以改用如下写法:明确告诉编译器strs类型,编译通过
public class Client {
public void methodA(String str,Integer... is){
System.out.println("Integer");
}
public void methodA(String str,String... strs){
System.out.println("String");
}
public static void main(String[] args) {
Client client = new Client();
Integer[] strs = null;
client.methodA("China",strs);
}
}警惕自增的陷阱
public static void main(String[] args) {
int count =0;
for(int i=0;i<10;i++){
count=count++;
}
System.out.println("count="+count);
}可以看到,count最终的输出值是0.
public static int mockAdd(int count){
//先保存初始值
int temp =count;
//做自增操作
count = count+1;
//返回原始值
return temp;
}基本类型
用偶判断,不用奇判断
public static void main(String[] args) {
//接收键盘输入参数
Scanner input = new Scanner(System.in);
System.out.print("请输入多个数字判断奇偶:");
while(input.hasNextInt()){
int i = input.nextInt();
String str =i+ "->" + (i%2 ==1?"奇数":"偶数");
System.out.println(str);
}
}可以看到,当输入数字 -1 时,运行结果为偶数。模拟下java %符号的运行代码
<span style="font-size:18px;">//模拟取余计算,dividend被除数,divisor除数
</span><span style="font-size:14px;">public static int remainder(int dividend,int divisor){
return dividend - dividend / divisor * divisor;
}</span>因此修改这段代码只需改为 i%2==0?"偶数":"奇数"就可以。
边界、边界、边界
public class Client {
//一个会员拥有产品的最大数量
public final static int LIMIT = 2000;
public static void main(String[] args) {
//会员当前拥有产品数量
int cur = 1000;
Scanner input = new Scanner(System.in);
System.out.print("请输入需要预定的数量:");
while(input.hasNextInt()){
int order = input.nextInt();
//当前拥有的与准备订购的产品数量之
if(order>0 && order+cur<=LIMIT){
System.out.println("你已经成功预定的"+order+"个产品!");
}else{
System.out.println("超过限额,预订失败!");
}
}
}
}优先使用整形池
ublic static void main(String[] args) {
Scanner input = new Scanner(System.in);
while(input.hasNextInt()){
int ii = input.nextInt();
System.out.println("\n===="+ii+" 的相等判断======");
//两个通过new产生的Integer对象
Integer i =new Integer(ii);
Integer j = new Integer(ii);
System.out.println("new产生的对象:" + (i==j));
//基本类型转为装箱类型后比较
i=ii;
j=ii;
System.out.println("基本类型转换的对象:" + (i==j));
//通过静态方法生成一个实例
i=Integer.valueOf(ii);
j = Integer.valueOf(ii);
System.out.println("valueOf产生的对象:" + (i==j));
}
}new产生的对象:false
基本类型转换的对象:true
valueOf产生的对象:true
====128 的相等判断======
new产生的对象:false
基本类型转换的对象:false
valueOf产生的对象:false
public static Integer valueOf(int i) {
assert IntegerCache.high >= 127;
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}private static class IntegerCache {
static final int low = -128;
static final int high;
static final Integer cache[];
static {
// high value may be configured by property
int h = 127;
String integerCacheHighPropValue =
sun.misc.VM.getSavedProperty("java.lang.Integer.IntegerCache.high");
if (integerCacheHighPropValue != null) {
int i = parseInt(integerCacheHighPropValue);
i = Math.max(i, 127);
// Maximum array size is Integer.MAX_VALUE
h = Math.min(i, Integer.MAX_VALUE - (-low));
}
high = h;
cache = new Integer[(high - low) + 1];
int j = low;
for(int k = 0; k < cache.length; k++)
cache[k] = new Integer(j++);
}
private IntegerCache() {}
}类、对象和方法
使用构造代码块精炼程序
public class Client {
{
//构造代码块
System.out.println("执行构造代码块");
}
public Client(){
System.out.println("执行无参构造");
}
public Client(String _str){
System.out.println("执行有参构造");
}
}public class Client {
public Client(){
System.out.println("执行构造代码块");
System.out.println("执行无参构造");
}
public Client(String _str){
System.out.println("执行构造代码块");
System.out.println("执行有参构造");
}
}是用匿名类的构造函数
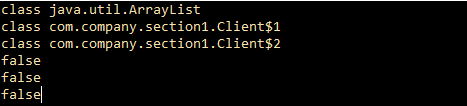
public static void main(String[] args) {
String[] strs = {"aaa","bbb","ccc"};
List l1 = new ArrayList();
List l2 = new ArrayList(){};
List l3 = new ArrayList(){{}};
System.out.println(l1.getClass());
System.out.println(l2.getClass());
System.out.println(l3.getClass());
System.out.println(l1.getClass() == l2.getClass());
System.out.println(l2.getClass() == l3.getClass());
System.out.println(l1.getClass() == l3.getClass());
}
public static void main(String[] args) {
//定义一个继承ArrayList的内部类
class Sub extends ArrayList{
}
//声明和赋值
List l2 = new Sub();
}public static void main(String[] args) {
//定义一个继承ArrayList的内部类
class Sub extends ArrayList{
{
//初始化块
}
}
//声明和赋值
List l3 = new Sub();
}字符串
正确使用String、StringBuffer、StringBuilder
自由使用字符串拼接
数组和集合
不同列表选择不同的遍历方式
public static int average(List<Integer> list) {
int sum = 0;
if (list instanceof RandomAccess) {
//可以随机存取,则使用下标遍历
for (int i = 0, size = list.size(); i < size; i++) {
sum += list.get(i);
}
} else {
//有序存取,使用foreach方式
for (int i : list) {
sum += i;
}
}
// 除以人数,计算平均值
return sum / list.size();
}优雅的使用对集合进行运算(并集、交集、差集)
枚举和注解
推荐使用枚举定义常量
泛型和反射
Java的泛型是类型擦除的
public static void main(String[] args) {
List<String> list = new ArrayList<String>();
list.add("abc");
String str = list.get(0);
}
public void doSomething(){
List list = new ArrayList();
list.add("abc");
String str = (String)list.get(0);
}public static void main(String[] args) {
List<String> ls = new ArrayList<String>();
List<Integer> li = new ArrayList<Integer>();
System.out.println(li.getClass() == li.getClass());
}建议采用的顺序是List<T>、List<?>、List<Object>
List<T>、List<?>、List<Object>这三者都可以容纳所有的对象,但使用的顺序应该首选List<T>、次之List<?>,最后List<Object>原因如下:
(1)List<T>是确定的某一个类型
List<T>表示的是list列表中的所有元素都是T类型,具体类型在运行时决定;List<?>表示是任意类型,与List<T>类似,而List<Object>则表示集合中所有元素都为Object类型,因为Object是所有类型的父类,所以List<Object>也可以容纳所有的类类型,从这一字面意义上分析,List<T>更符合习惯:编码者知道他是某一类型,只是在运行时期才确定而已。
(2)List<T>可以进行读写操作
List<T>可以进行add,remove等操作,因为他的类型是固定的T类型,在编码期不需要进行任何的转型操作。
List<?>是只读类型的,不能进行增加、修改的操作,因为编译器不知道List<?>中容纳的是什么类型的元素,也就无法类型是否安全了,而List<?>读出的全部都是Object类型,需要主动转型,所以它经常用于泛型方法的返回值。需要注意List<?>虽然无法添加修改,但是可以做删除操作。比如remove,clear,因为删除动作与泛型类型无关。
List<Object>也可以进行读写操作,但是他执行写入操作时需要向上转型(Up Cast),在读取数据后需要向下转型(Down Cast),而此时已经失去了泛型的意义了。
父类引用指向子类对象,而子类引用不能指向父类对象。
异常
提倡异常封装
public class Client {
public static void main(String[] args) {
try {
doStuff();
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
public static void doStuff() throws Exception {
InputStream is = new FileInputStream("无效文件.txt");
/*文件操作*/
}
public static void doStuff2() throws MyBussinessException{
try {
InputStream is = new FileInputStream("无效文件.txt");
} catch (FileNotFoundException e) {
//为方便开发和维护人员而设置的异常信息
e.printStackTrace();
//抛出业务异常
throw new MyBussinessException(e);
}
/*文件操作*/
}
}
class MyBussinessException extends Exception{
public MyBussinessException(Throwable t){
super(t);
}
}public class Client {
public static void main(String[] args) {
try {
doStuff();
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
public static void doStuff() throws MyException {
List<Throwable> list = new ArrayList<Throwable>();
// 第一个逻辑片段
try {
// Do Something
} catch (Exception e) {
list.add(e);
}
// 第二个逻辑片段
try {
// Do Something
} catch (Exception e) {
list.add(e);
}
if (list.size() > 0) {
throw new MyException(list);
}
}
}
class MyException extends Exception {
// 容纳所有的异常
private List<Throwable> causes = new ArrayList<Throwable>();
// 构造函数,传递一个异常列表
public MyException(List<? extends Throwable> _causes) {
causes.addAll(_causes);
}
// 读取所有的异常
public List<Throwable> getExceptions() {
return causes;
}
}不要再finally代码块中处理返回值
public class Client {
public static void main(String[] args) {
try {
doStuff(-1);
doStuff(100);
} catch (Exception e) {
System.out.println("这里是永远都不会到达的");
}
}
public static int doStuff(int _p) throws Exception {
try {
if (_p < 0) {
throw new DataFormatException("数据格式错误");
} else {
return _p;
}
} catch (Exception e) {
//异常处理
throw e;
} finally {
return -1;
}
}
}上面这段代码的doStuff(-1) 和doStuff(100)的返回值都是-1,导致这个问题的原因有两个:
public class Client {
public static void main(String[] args) {
System.out.println(doStuff());
System.out.println(doStuff2().getName());
}
public static int doStuff() {
int a = 1;
try {
return a;
} catch (Exception e) {
} finally {
//重新修改一下返回值
a = -1;
}
return 0;
}
public static Person doStuff2() {
Person person = new Person();
person.setName("张三");
try {
return person;
} catch (Exception e) {
} finally {
//重新修改一下返回值
person.setName("李四");
}
person.setName("王五");
return person;
}
}
class Person{
private String name;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
} public static void doSomething() {
try {
//正常抛出异常
throw new RuntimeException();
} finally {
return;
}
}
public static void main(String[] args) {
try {
doSomething();
} catch (RuntimeException e) {
System.out.println("这里永远都不会到达!");
}
}上面的finally代码块中的return已经告诉jvm,doSomething已经正常执行结束了,也没有任何异常,所以main中永远都不会捕获到异常。
多线程、并发
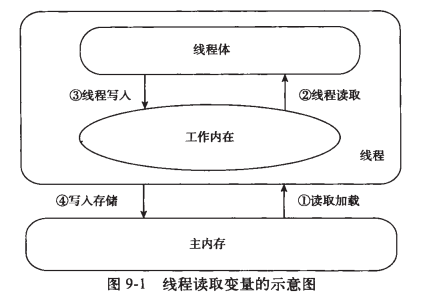
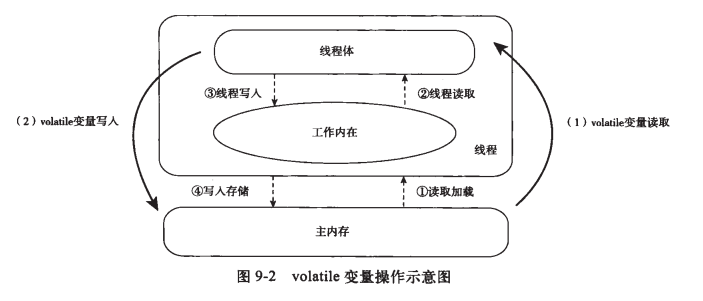
volatile不能保证数据同步
public static void main(String[] args) throws Exception {
// 理想值,并做为最大循环次数
int value = 1000;
// 循环次数,防止出现无限循环造成死机情况
int loops = 0;
//主线程组,用于估计活动线程数
ThreadGroup tg = Thread.currentThread().getThreadGroup();
while (loops++ < value) {
// 共享资源清零
UnsafeThread ut = new UnsafeThread();
for (int i = 0; i < value; i++) {
new Thread(ut).start();
}
// 先等15毫秒,等待活动线程数量成为1
do {
Thread.sleep(15);
} while (tg.activeCount() != 1);
// 检查实际值与理论值是否一致
if (ut.getCount() != value) {
// 出现线程不安全的情况
System.out.println("循环到第 " + loops + " 遍,出现线程不安全情况");
System.out.println("此时,count=" + ut.getCount());
System.exit(0);
}
}
System.out.println("循环结束");
}
}
class UnsafeThread implements Runnable {
// 共享资源
private volatile int count = 0;
@Override
public void run() {
// 为了增加CPU的繁忙程度
for (int i = 0; i < 1000; i++) {
Math.hypot(Math.pow(92456789, i), Math.cos(i));
}
// 自增运算
count++;
}
public int getCount() {
return count;
}
}
异步运算考虑使用Callable接口
public static void main(String[] args) throws Exception {
//生成一个单线程的异步执行器
ExecutorService es = Executors.newSingleThreadExecutor();
//线程执行后的期望值
Future<Integer> future = es.submit(new TaxCalculator(100));
while(!future.isDone()){
//还没有运算完成,等待10毫秒
TimeUnit.MILLISECONDS.sleep(200);
//输出进度符号
System.out.print("#");
}
System.out.println("\n计算完成,税金是:"+ future.get() + " 元");
//关闭异步执行器
es.shutdown();
}
}
//税款计算器
class TaxCalculator implements Callable<Integer> {
//本金
private int seedMoney;
//接收主线程提供的参数
public TaxCalculator(int _seedMoney) {
seedMoney = _seedMoney;
}
@Override
public Integer call() throws Exception {
//复杂计算,运行一次需要10秒
TimeUnit.MILLISECONDS.sleep(10000);
return seedMoney /10;
}
}此类异步计算的好处是:
使用CountDownLatch协调子线程
import java.util.ArrayList;
import java.util.List;
import java.util.Random;
import java.util.concurrent.Callable;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Future;
import java.util.concurrent.TimeUnit;
public class Client {
static class Runner implements Callable<Integer> {
//开始信号
private CountDownLatch begin;
//结束信号
private CountDownLatch end;
public Runner(CountDownLatch _begin, CountDownLatch _end) {
begin = _begin;
end = _end;
}
@Override
public Integer call() throws Exception {
// 跑步的成绩
int score = new Random().nextInt(25);
// 等待发令枪响起
begin.await();
// 跑步中……
TimeUnit.MILLISECONDS.sleep(score);
// 跑步者已经跑完全程
end.countDown();
return score;
}
}
public static void main(String[] args) throws Exception {
//参加赛跑人数
int num = 10;
// 发令枪只响一次
CountDownLatch begin = new CountDownLatch(1);
// 参与跑步有多个
CountDownLatch end = new CountDownLatch(num);
// 每个跑步者一个跑道
ExecutorService es = Executors.newFixedThreadPool(num);
// 记录比赛成绩
List<Future<Integer>> futures = new ArrayList<Future<Integer>>();
// 跑步者就位,所有线程处于等待状态
for (int i = 0; i < num; i++) {
futures.add(es.submit(new Runner(begin, end)));
}
// 发令枪响,跑步者开始跑步
begin.countDown();
// 等待所有跑步者跑完全程
end.await();
int count = 0;
// 统计总分
for (Future<Integer> f : futures) {
count += f.get();
}
System.out.println("平均分数为:" + count / num);
}
}CyclicBarrier让多线程齐步走
public class Client {
static class Worker implements Runnable {
// 关卡
private CyclicBarrier cb;
public Worker(CyclicBarrier _cb) {
cb = _cb;
}
@Override
public void run() {
try {
Thread.sleep(new Random().nextInt(1000));
System.out.println(Thread.currentThread().getName() + "-到达汇合点");
// 到达汇合点
cb.await();
} catch (Exception e) {
// 异常处理
}
}
}
public static void main(String[] args) throws Exception {
// 设置汇集数量,以及汇集完成后的任务
CyclicBarrier cb = new CyclicBarrier(2, new Runnable() {
public void run() {
System.out.println("隧道已经打通!");
}
});
// 工人1挖隧道
new Thread(new Worker(cb), "工人1").start();
// 工人2挖隧道
new Thread(new Worker(cb), "工人2").start();
}
}CyclicBarrier可以让全部线程处于等待状态(阻塞),然后在满足条件的情况下全部执行,这就好比是一条起跑线,不管是如何达到起跑线的,只要到达这条起跑线就必须等待其他人员,在人员到齐后再各奔东西,CyclicBarrier关注的是汇合点的信息,而不在乎之前或之后如何处理。
性能和效率
提升java新能的基本方法
public static String toChineseNum(int num){
//中文数字
String[] cns = {"零","壹","贰","叁","肆","伍","陆","柒","捌","玖"};
return cns[num];
} //中文数字
final static String[] cns = {"零","壹","贰","叁","肆","伍","陆","柒","捌","玖"};
public String toChineseNum(int num){
return cns[num];
}(2)缩小变量的作用范围















 1437
1437

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









