







缓冲区
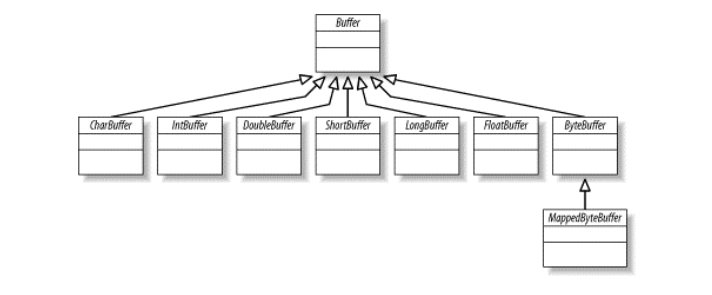
对于每个非布尔原始数据类型都有一个缓冲区类。尽管缓冲区作用于它们存储的原始数据类型,但缓冲区十分倾向于处理字节。非字节缓冲区可以在后台执行从字节或到字节的转换,这取决于缓冲区是如何创建的这涉及到按字节排序问题.Buffer的类层次图,如下图所示,在顶部是通用Buffer类。Buffer定义所有缓冲区类型共有的操作,无论是它们所包含的数据类型还是可能具有的特定行为。
缓冲区基础
概念上,缓冲区是包在一个对象内的基本数据元素数组。Buffer 类相比一个简单数组的优点是它将关于数据的数据内容和信息包含在一个单一的对象中。Buffer 类以及它专有的子类定义了一个用于处理数据缓冲区的 API。
属性
- 容量(Capacity):缓冲区能够容纳的数据元素的最大数量。这一容量在缓冲区创建时被设定,并且永远不能被改变。
- 上界(Limit):缓冲区的第一个不能被读或写的元素。或者说,缓冲区中现存元素的计数。
- 位置(Position):下一个要被读或写的元素的索引。位置会自动由相应的 get( )和 put( )函数更新。
- 标记(Mark):一个备忘位置。调用 mark( )来设定 mark = postion。调用 reset( )设定 position =mark。标记在设定前是未定义的( undefined) 。
这四个属性之间总是遵循以下关系:0 <= mark <= position <= limit <= capacity
缓冲区API
package java.nio;
public abstract class Buffer {
public final int capacity( )
public final int position( )
public final Buffer position (int newPosition)
public final int limit( )
public final Buffer limit (int newLimit)
public final Buffer mark( )
public final Buffer reset( )
public final Buffer clear( )
public final Buffer flip( )
public final Buffer rewind( )
public final int remaining( )
public final boolean hasRemaining( )
public abstract boolean isReadOnly( );
}像 clear()这类函数,您通常应当返回 void,而不是 Buffer 引用。这些函数将引用返回到它们在自身(this)上被引用的对象。这是一个允许级联调用的类设计方法。
对于 API 还要注意的一点是 isReadOnly()函数。所有的缓冲区都是可读的,但并非所有都可写。每个具体的缓冲区类都通过执行 isReadOnly()来标示其是否允许该缓存区的内容被修改。一些类型的缓冲区类可能未使其数据元素存储在一个数组中。例如MappedByteBuffer 的内容可能实际是一个只读文件。您也可以明确地创建一个只读视图缓冲区,来防止对内容的意外修改。对只读的缓冲区的修改尝试将会导致ReadOnlyBufferException 抛出。但是我们要提前做好准备。
存取
Buffer类中含有一个位置属性,它在调用 put()时指出了下一个数据元素应该被插入的位 ,或者当 get()被调用时指出下一个元素应从何处检索。Buffer API 并没有包括 get()或 put()函数。每一个 Buffer 类都有这两个函数,但它们所采用的参数类型,以及它们返回的数据类型,对每个子类来说都是唯一的,所以它们不能在顶层 Buffer 类中被抽象地声明。它们的定义必须被特定类型的子类所遵从.例如Bytebuffer类:
public abstract class ByteBuffer extends Buffer implements Comparable<ByteBuffer>
{
public abstract byte get();
public abstract byte get(int index);
public abstract ByteBuffer put(byte b);
public abstract ByteBuffer put(int index, byte b);
}Get和put可以是相对的或者是绝对的。在前面的程序列表中,相对方案是不带有索引参数的函数。当相对函数被调用时,位置在返回时前进一。如果位置前进过多,相对运算就会抛出异 常 。 对于put() , 如果运算会导致位置超出上界 , 就会抛出BufferOverflowException 异 常 。 对于 get() , 如果位置不小于上界, 就会抛出BufferUnderflowException 异常。绝对存取不会影响缓冲区的位置属性,但是如果您所提供的索引超出范围(负数或不小于上界),也将抛出 IndexOutOfBoundsException异常.
填充
我们将代表”Hello”字符串的 ASCII 码载入一个名为 buffer 的ByteBuffer 对象中。
buffer.put((byte)'H').put((byte)'e').put((byte)'l').put((byte)'l').put((byte)'o');注意本例中的每个字符都必须被强制转换为 byte。我们不能不经强制转换而这样操做:
buffer.put('H');因为我们存放的是字节而不是字符。记住在 java 中,字符在内部以 Unicode 码表示,每个 Unicode 字符占 16 位。此处使用包含 ascii 字符集数值的字节。通过将char 强制转换为 byte,我们删除了前八位来建立一个八位字节值。这通常只适合于拉丁字符而不能适合所有可能的 Unicode 字符。为了让事情简化,我们暂时故意忽略字符集的映射问题。
翻转
我们已经写满了缓冲区,现在我们必须准备将其清空。我们想把这个缓冲区传递给一个通道,以使内容能被全部写出。但如果通道现在在缓冲区上执行 get(),那么它将从我们刚刚插入的有用数据之外取出未定义数据。如果我们将位置值重新设为 0,通道就会从正确位置开始获取,但是它是怎样知道何时到达我们所插入数据末端的呢?这就是上界属性被引入的目的。上界属性指明了缓冲区有效内容的末端。我们需要将上界属性设置为当前位置,然后将位置重置为 0。我们可以人工用下面的代码实现:
buffer.limit(buffer.position()).position(0);但这种从填充到释放状态的缓冲区翻转是 API 设计者预先设计好的,他们为我们提供了一个非常便利的函数:
Buffer.flip();flip()函数将一个能够继续添加数据元素的填充状态的缓冲区翻转成一个准备读出元素的释放状态。
rewind()函数与 flip()相似,但不影响上界属性。它只是将位置值设回 0。
如果将缓冲区翻转两次会怎样呢?它实际上会大小变为 0。因为第二次把上界设为位置的值,并把位置设为 0。上界和位置都变成 0。尝试对缓冲区上位置和上界都为0的get()操作会导致 BufferUnderflowException 异常。而 put()则会导致 BufferOverflowException 异常。
释放
布尔函数 hasRemaining()会在释放缓冲区时(即用get函数读取数据)告诉您是否已经达到缓冲区的上界。remaining()函数将告知您从当前位置到上界还剩余的元素数目。
for (int i = 0; buffer.hasRemaining( ), i++) {
myByteArray [i] = buffer.get( );
}缓冲区并不是多线程安全的。如果您想以多线程同时存取特定的缓冲区,您需要在存取缓冲区之前进行同步(例如对缓冲区对象进行跟踪)。
clear()函数将缓冲区重置为空状态。它并不改变缓冲区中的任何数据元素,而是仅仅将上界设为容量的值,并把位置设回0
压缩
您可能只想从缓冲区中释放(使用get函数读取之后不再使用的数据)一部分数据,而不是全部,然后重新填充。为了实现这一点,未读的数据元素需要下移以使第一个元素索引为 0。尽管重复这样做会效率低下,但这有时非常必要,而 API 对此为您提供了一个 compact()函数。这一缓冲区工具在复制数据时要比您使用get()和put()函数高效得多。所以当您需要时,请使用 compact()。下图显示了一个我们已经释放了一些元素,并且现在我们想要对其进行压缩的缓冲区。
这样操作:
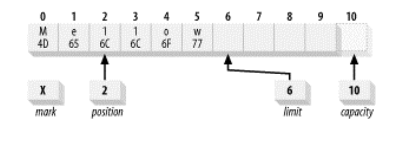
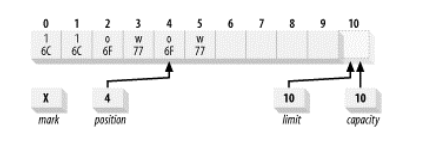
buffer.compact();会导致缓冲区状态如下:
可以看到这里数据元素 2-5 被复制到 0-3 位置。位置 4 和 5 不受影响,但现在正在或已经超出了当前位置,因此是“死的”。它们可以被之后的 put()调用重写。还要注意的是,位置已经被设为被复制的数据元素的数目。也就是说,缓冲区现在被定位在缓冲区中最后一个“存活”元素后插入数据的位置。最后,上界属性被设置为容量的值,因此缓冲区可以被再次填满。调用 compact()的作用是丢弃已经释放的数据,保留未释放的数据,并使缓冲区对重新填充容量准备就绪。
标记
缓冲区的标记在 mark( )函数被调用之前是未定义的,调用时标记被设为当前位置的值。reset( )函数将位置设为当前的标记值。如果标记值未定义,调用 reset( )将导致 InvalidMarkException 异常。一些缓冲区函数会抛弃已经设定的标记(rewind( ),clear( ),以及 flip( )总是抛弃标记)。如果新设定的值比当前的标记小,调用limit( )或 position( )带有索引参数的版本会抛弃标记。
比较
如果每个缓冲区中剩余的内容相同,那么 equals( )函数将返回 true,否则返回 false。\
两个缓冲区被认为相等的充要条件是:
- 两个对象类型相同。包含不同数据类型的 buffer 永远不会相等,而且 buffer绝不会等于非 buffer 对象。
- 两个对象都剩余同样数量的元素。Buffer 的容量不需要相同,而且缓冲区中剩余数据的索引也不必相同。但每个缓冲区中剩余元素的数目(从位置到上界)必须相同。
- 在每个缓冲区中应被 Get()函数返回的剩余数据元素序列必须一致。
如果不满足以上任意条件,就会返回false.
与 equals( )相似,compareTo( )不允许不同对象间进行比较。但 compareTo( )更为严格:如果您传递一个类型错误的对象,它会抛出 ClassCastException 异常,但 equals( )只会返回false。
批量移动
buffer API 提供了向缓冲区内外批量移动数据元素的函数。
public abstract class CharBuffer extends Buffer implements CharSequence, Comparable
{
// This is a partial API listing
public CharBuffer get (char [] dst)
public CharBuffer get (char [] dst, int offset, int length)
public final CharBuffer put (char[] src)
public CharBuffer put (char [] src, int offset, int length)
public CharBuffer put (CharBuffer src)
public final CharBuffer put (String src)
public CharBuffer put (String src, int start, int end)
}有两种形式的 get( )可供从缓冲区到数组进行的数据复制使用。第一种形式只将一个数组作为参数,将一个缓冲区释放到给定的数组。第二种形式使用 offset 和 length 参数来指定目标数组的子区间。这些批量移动的合成效果与前文所讨论的循环是相同的,但是这些方法可能高效得多,因为这种缓冲区实现能够利用本地代码或其他的优化来移动数据。批量传输的大小总是固定的也即移动固定数量的数据元素。省略长度意味着整个数组会被填满。例如:
buffer.get(myArray);等价于:
buffer.get(myArray,0,myArray.length);如果您所要求的数量的数据不能被传送,那么不会有数据被传递,缓冲区的状态保持不变,同时抛出 BufferUnderflowException 异常。因此当您传入一个数组并且没有指定长度,您就相当于要求整个数组被填充。如果缓冲区中的数据不够完全填满数组,您会得到一个异常。这意味着如果您想将一个小型缓冲区传入一个大型数组,您需要明确地指出缓冲区中剩余的数据长度。比如:
char [] bigArray = new char [1000];
// Get count of chars remaining in the buffer
int length = buffer.remaining( );
// Buffer is known to contain < 1,000 chars
buffer.get (bigArrray, 0, length);
// Do something useful with the data
processData (bigArray, length);记住在调用 get( )之前必须查询缓冲区中的元素数量(因为我们需要告知 processData( )被放置在 bigArray 中的字符个数)。调用 get( )会向前移动缓冲区的位置属性,所以之后调用remaining( )会返回 0。get( )的批量版本返回缓冲区的引用,而不是被传送的数据元素的计数,以减轻级联调用的困难。
另一方面,如果缓冲区存有比数组能容纳的数量更多的数据,您可以重复利用如下文所示的程序块进行读取:
char [] smallArray = new char [10];
while (buffer.hasRemaining( )) {
int length = Math.min (buffer.remaining( ), smallArray.length);
buffer.get (smallArray, 0, length);
processData (smallArray, length);
}Put()的批量版本工作方式相似,但以相反的方向移动数据,从数组移动到缓冲区。他们在传送数据的大小方面有着相同的语义:
buffer.put(myArray);等价于
buffer.put(myArray,0,myArray.length);如果缓冲区中没有足够的空间,那么不会有数据被传递,同时抛出一个 BufferOverflowException 异常。
创建缓冲区
有七种主要的缓冲区类,每一种都具有一种 Java 语言中的非布尔类型的原始类型数据(MappedByteBuffer,是ByteBuffer 专门用于内存映射文件的一种特例。)。这些类没有一种能够直接实例化。它们都是抽象类,但是都包含静态工厂方法用来创建相应类的新实例。
以CharBuffer类为例,下面是创建一个缓冲区的关键函数,对所有的缓冲区类通用(要按照需要替换类名):
public abstract class CharBuffer
extends Buffer implements CharSequence, Comparable
{
// This is a partial API listing
public static CharBuffer allocate (int capacity)
public static CharBuffer wrap (char [] array)
public static CharBuffer wrap (char [] array, int offset,int length)
public final boolean hasArray( )
public final char [] array( )
public final int arrayOffset( )
}














 109
109

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









