







 本文通过泰勒公式和几何直观解释了梯度下降法的基本原理,阐述了如何沿负梯度方向更新参数以达到损失函数最小化的目的。
本文通过泰勒公式和几何直观解释了梯度下降法的基本原理,阐述了如何沿负梯度方向更新参数以达到损失函数最小化的目的。
以下内容整理于高数课本以及李宏毅老师的视频:

我们想要利用梯度下降来求得损失函数的最小值。也就是每次我们更新参数,当前的损失函数总比上一次要小。
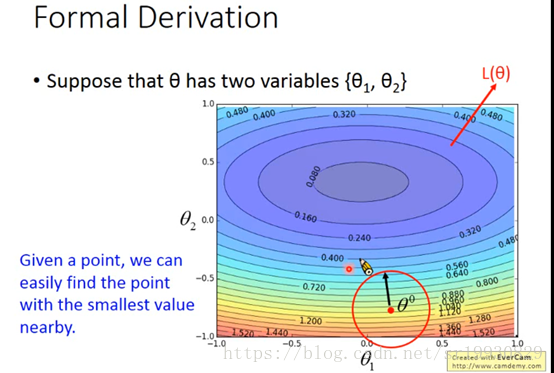
假设只有两个参数θ1和θ2,上图是损失函数的等值线,红色点是初始值当前的状态。以红色点为圆心画圆,在这个圆的范围内,我们想要找到一个损失函数更小的值。如下图:
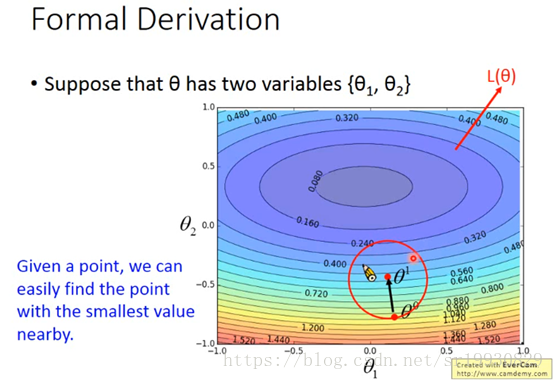
这样我们就更新了一次参数,损失函数值变小了。再进行相同的操作,以当前点为圆心,画圆,再找一个圆内范围的最小值。如下图:
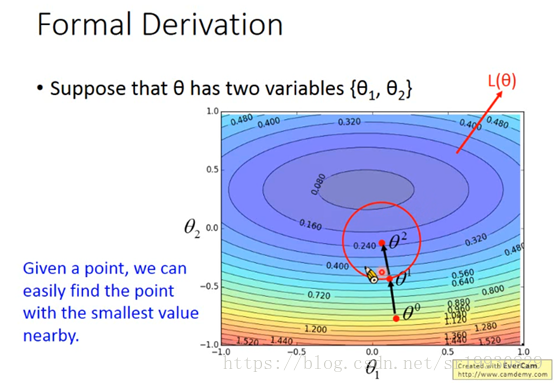
这样我们进行了第二次参数更新,损失函数又变小了。接着我们再进行同样的操作,就会很容易找到损失函数最小值附近的点。
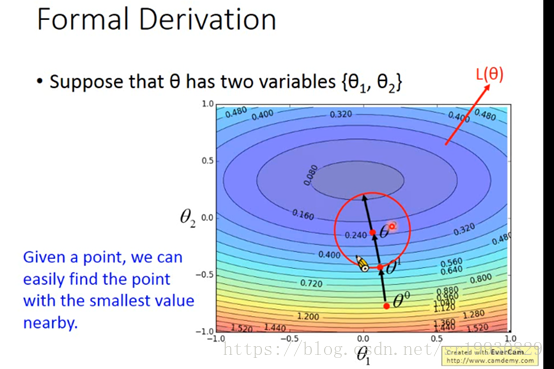
总体思想是这样,但是具体要怎么操作呢,在一个圆的范围内,哪个方向的点才是我们想要的值最小的点呢?首先从泰勒公式说起:

一元泰勒公式。

二元泰勒公式。
泰勒公式是用来利用一个函数在某点的信息描述该点附近点的取值信息。
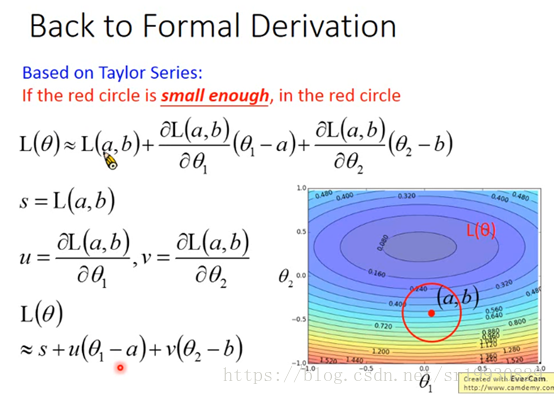
前面假设只有两个参数θ1和θ2,假设当前参数的取值点为(a, b),如上图,将损失函数L在(a, b)点一阶展开,u表示损失函数对θ1的偏导,v表示损失函数对θ2的偏导,也就是说向量(u, v)即是现在的梯度方向。损失函数L在(a,b)附近的取值信息可由上图最下面的式子表示。我们想要的就是在这个附近取一个最小值。
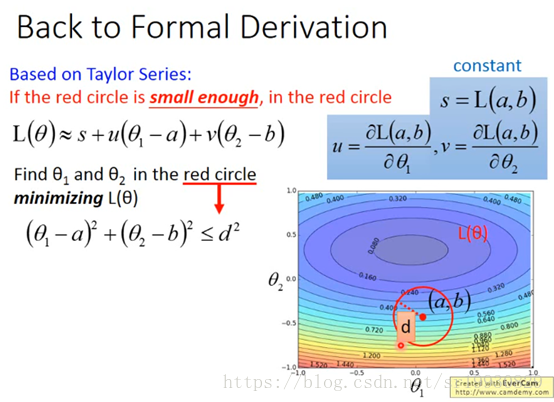
如上图,做法是以当前点(a, b)为圆心,半径为d(假设这个d足够小)画圆,那么该点的附近范围就是满足这样的参数取值(θ1,θ2), 且(θ1 - a) ^2 + (θ2 - b)^2 <= d^2。也就是在这个小圆圈范围内。

将θ1 - a 记作Δθ1, θ2 - b记作Δθ2, 我们的目标就是找到最优的θ1和θ2,使得上面的损失函数L最小。上图中的s是常数,不用管, 也就是让 u * Δθ1 + v * Δθ2最小,它可以看成是两个向量的内积,即向量(u, v)和向量(Δθ1, Δθ2)最小。这里先说出结论,最小的情况是(Δθ1, Δθ2)与(u, v)反向,下面详细解释。
要想u * Δθ1 + v * Δθ2最小,也就是两个向量的内积最小。考虑内积的直观意义:两个向量的内积等于向量1在向量2上面的投影乘以向量2的长度。投影可正可负,当两向量夹角大于90度时,投影是负的,投影可以表示为正负号乘以投影的长度
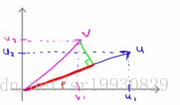 ,比如左图v在u上面的投影就等于红色线段的长度。要想(Δθ1, Δθ2)与(u, v)内积最小(这里的u,v和上面那个小例子中的u, v没关系,是上面图中圆圈中的(u,v)向量),因为(u,v)的长度是一定的,那么只需要(Δθ1, Δθ2)在(u,v)上的投影最小就可以了。投影最小,首先保证是负号,也就是二者向量夹角大于90度,接下来只要投影长度最大就行,因为有负号。(Δθ1, Δθ2)的投影长度是小于等于(Δθ1, Δθ2)向量的长度的,像上面那个小例子中的v。要求投影长度最大,那么肯定是与(u,v)反向的时候最大,这时候投影长度就等于(Δθ1, Δθ2)向量的长度。如下图所示:
,比如左图v在u上面的投影就等于红色线段的长度。要想(Δθ1, Δθ2)与(u, v)内积最小(这里的u,v和上面那个小例子中的u, v没关系,是上面图中圆圈中的(u,v)向量),因为(u,v)的长度是一定的,那么只需要(Δθ1, Δθ2)在(u,v)上的投影最小就可以了。投影最小,首先保证是负号,也就是二者向量夹角大于90度,接下来只要投影长度最大就行,因为有负号。(Δθ1, Δθ2)的投影长度是小于等于(Δθ1, Δθ2)向量的长度的,像上面那个小例子中的v。要求投影长度最大,那么肯定是与(u,v)反向的时候最大,这时候投影长度就等于(Δθ1, Δθ2)向量的长度。如下图所示:

此时我们可以得出这样的结论:当向量(Δθ1, Δθ2)是与(u,v)反向的时候,损失函数L取最小值。上图中的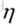 就像是一个步长,它可以伸展到圆的边界上去。前面说(u, v)是梯度方向,那么(Δθ1, Δθ2)则是负梯度方向。又因为Δθ1 = θ1 - a,Δθ2 = θ2 - b,可以推出上图中的梯度下降公式。
就像是一个步长,它可以伸展到圆的边界上去。前面说(u, v)是梯度方向,那么(Δθ1, Δθ2)则是负梯度方向。又因为Δθ1 = θ1 - a,Δθ2 = θ2 - b,可以推出上图中的梯度下降公式。

这种方法要求我们画的圆圈范围足够小,从上可知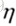 (步长,学习率)的大小是和圆圈半径成正比的,所以
(步长,学习率)的大小是和圆圈半径成正比的,所以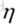 也要足够小,理论上,
也要足够小,理论上,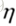 无穷小时,上面式子才成立。至此我们可以得出结论,每一次参数更新,沿着负梯度方向,损失函数值下降最快。
无穷小时,上面式子才成立。至此我们可以得出结论,每一次参数更新,沿着负梯度方向,损失函数值下降最快。
下面来自高数课本:




















 2401
2401

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









