






问题描述
我遇到的问题是:
- 在Windows系统中,本地部署ChatGLM3时,在命令行中执行streamlit run web_demo_streamlit.py这条命令,出现TypeError: stat: path should be string, bytes, os.PathLike or integer, not NoneType这个错误。具体的错误信息如下所示:
Traceback (most recent call last): File "D:\dailysoftware\anaconda\envs\chatglm3\Lib\site-packages\streamlit\runtime\scriptrunner\exec_code.py", line 88, in exec_func_with_error_handling result = func() ^^^^^^ File "D:\dailysoftware\anaconda\envs\chatglm3\Lib\site-packages\streamlit\runtime\scriptrunner\script_runner.py", line 579, in code_to_exec exec(code, module.__dict__) File "D:\projects\ChatGLM3\ChatGLM3-main\basic_demo\web_demo_streamlit.py", line 49, in <module> tokenizer, model = get_model() ^^^^^^^^^^^ File "D:\dailysoftware\anaconda\envs\chatglm3\Lib\site-packages\streamlit\runtime\caching\cache_utils.py", line 217, in __call__ return self._get_or_create_cached_value(args, kwargs) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "D:\dailysoftware\anaconda\envs\chatglm3\Lib\site-packages\streamlit\runtime\caching\cache_utils.py", line 242, in _get_or_create_cached_value return self._handle_cache_miss(cache, value_key, func_args, func_kwargs) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "D:\dailysoftware\anaconda\envs\chatglm3\Lib\site-packages\streamlit\runtime\caching\cache_utils.py", line 299, in _handle_cache_miss computed_value = self._info.func(*func_args, **func_kwargs) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "D:\projects\ChatGLM3\ChatGLM3-main\basic_demo\web_demo_streamlit.py", line 43, in get_model tokenizer = AutoTokenizer.from_pretrained(TOKENIZER_PATH, trust_remote_code=True) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "D:\dailysoftware\anaconda\envs\chatglm3\Lib\site-packages\transformers\models\auto\tokenization_auto.py", line 905, in from_pretrained return tokenizer_class.from_pretrained( ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "D:\dailysoftware\anaconda\envs\chatglm3\Lib\site-packages\transformers\tokenization_utils_base.py", line 2213, in from_pretrained return cls._from_pretrained( ^^^^^^^^^^^^^^^^^^^^^ File "D:\dailysoftware\anaconda\envs\chatglm3\Lib\site-packages\transformers\tokenization_utils_base.py", line 2447, in _from_pretrained tokenizer = cls(*init_inputs, **init_kwargs) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "C:\Users\srr\.cache\huggingface\modules\transformers_modules\chatglm3-6b\tokenization_chatglm.py", line 109, in __init__ self.tokenizer = SPTokenizer(vocab_file) ^^^^^^^^^^^^^^^^^^^^^^^ File "C:\Users\srr\.cache\huggingface\modules\transformers_modules\chatglm3-6b\tokenization_chatglm.py", line 17, in __init__ assert os.path.isfile(model_path), model_path ^^^^^^^^^^^^^^^^^^^^^^^^^^ File "<frozen genericpath>", line 30, in isfile TypeError: stat: path should be string, bytes, os.PathLike or integer, not NoneType Using model path: D:/projects/models/chatglm3-6b Using tokenizer path: D:/projects/models/chatglm3-6b 2024-11-13 16:51:25.569 Uncaught app exception Traceback (most recent call last): File "D:\dailysoftware\anaconda\envs\chatglm3\Lib\site-packages\streamlit\runtime\scriptrunner\exec_code.py", line 88, in exec_func_with_error_handling result = func() ^^^^^^ File "D:\dailysoftware\anaconda\envs\chatglm3\Lib\site-packages\streamlit\runtime\scriptrunner\script_runner.py", line 579, in code_to_exec exec(code, module.__dict__) File "D:\projects\ChatGLM3\ChatGLM3-main\basic_demo\web_demo_streamlit.py", line 49, in <module> tokenizer, model = get_model() ^^^^^^^^^^^ File "D:\dailysoftware\anaconda\envs\chatglm3\Lib\site-packages\streamlit\runtime\caching\cache_utils.py", line 217, in __call__ return self._get_or_create_cached_value(args, kwargs) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "D:\dailysoftware\anaconda\envs\chatglm3\Lib\site-packages\streamlit\runtime\caching\cache_utils.py", line 242, in _get_or_create_cached_value return self._handle_cache_miss(cache, value_key, func_args, func_kwargs) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "D:\dailysoftware\anaconda\envs\chatglm3\Lib\site-packages\streamlit\runtime\caching\cache_utils.py", line 299, in _handle_cache_miss computed_value = self._info.func(*func_args, **func_kwargs) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "D:\projects\ChatGLM3\ChatGLM3-main\basic_demo\web_demo_streamlit.py", line 43, in get_model tokenizer = AutoTokenizer.from_pretrained(TOKENIZER_PATH, trust_remote_code=True) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "D:\dailysoftware\anaconda\envs\chatglm3\Lib\site-packages\transformers\models\auto\tokenization_auto.py", line 905, in from_pretrained return tokenizer_class.from_pretrained( ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "D:\dailysoftware\anaconda\envs\chatglm3\Lib\site-packages\transformers\tokenization_utils_base.py", line 2213, in from_pretrained return cls._from_pretrained( ^^^^^^^^^^^^^^^^^^^^^ File "D:\dailysoftware\anaconda\envs\chatglm3\Lib\site-packages\transformers\tokenization_utils_base.py", line 2447, in _from_pretrained tokenizer = cls(*init_inputs, **init_kwargs) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "C:\Users\srr\.cache\huggingface\modules\transformers_modules\chatglm3-6b\tokenization_chatglm.py", line 109, in __init__ self.tokenizer = SPTokenizer(vocab_file) ^^^^^^^^^^^^^^^^^^^^^^^ File "C:\Users\srr\.cache\huggingface\modules\transformers_modules\chatglm3-6b\tokenization_chatglm.py", line 17, in __init__ assert os.path.isfile(model_path), model_path ^^^^^^^^^^^^^^^^^^^^^^^^^^ File "<frozen genericpath>", line 30, in isfile TypeError: stat: path should be string, bytes, os.PathLike or integer, not NoneType -
我尝试将MODEL_PATH和TOKENIZER_PATH的路径打印出来,确认其值是否为空 (
None) 或者路径是否正确import os MODEL_PATH = os.environ.get('MODEL_PATH', 'D:/projects/models/chatglm3-6b') TOKENIZER_PATH = os.environ.get('TOKENIZER_PATH', MODEL_PATH) # 检查路径是否正确 if not MODEL_PATH or not os.path.exists(MODEL_PATH): raise ValueError(f"Invalid model path: {MODEL_PATH}") if not TOKENIZER_PATH or not os.path.exists(TOKENIZER_PATH): raise ValueError(f"Invalid tokenizer path: {TOKENIZER_PATH}") print(f"Using model path: {MODEL_PATH}") print(f"Using tokenizer path: {TOKENIZER_PATH}")路径结果如下:显示路径正确传递。

问题解释
我尝试通过下面两种git命令拉取模型文件到本地,打开本地下载好的模型文件时,发现少了很多文件,
#从modelscope下载模型文件
git clone https://www.modelscope.cn/ZhipuAI/chatglm3-6b.git
#从Huggingface下载模型文件
git clone https://huggingface.co/THUDM/chatglm3-6b少的文件有:
| model-00001-of-00007.safetensors | ||
| model-00002-of-00007.safetensors | ||
| model-00003-of-00007.safetensors | ||
tokenizer.model 文件是一个包含分词规则、词汇表和分词算法的文件,当你加载一个使用 SentencePiece 训练的分词器时,你需要加载这个 tokenizer.model 文件。比如,使用 transformers 库加载模型时,通常会看到以下代码:
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained('path_to_tokenizer_model')
model-00001-of-00007.safetensors 和 model-00002-of-00007.safetensors 等:这些是模型权重文件的分片,其中:
model-00001-of-00007.safetensors:第 1 个文件,共 7 个文件,包含了部分模型参数。safetensors格式是一个高效且安全的二进制格式,用于存储大规模的张量(模型权重)model-00002-of-00007.safetensors:第 2 个文件,依此类推,直到第 7 个文件。
pytorch_model-00001-of-00007.bin 和 pytorch_model-00002-of-00007.bin 等:这些是 PyTorch 版本的模型权重文件,也以分片的形式存储,文件名通常以 .bin 结尾。
-
00001-of-00007指的是分片的编号,00007表示总共有 7 个分片。因此,模型总共有 7 个文件,分别包含模型的不同部分。
如何使用这些文件:
- 当加载这些模型时,框架(如 Hugging Face 的
transformers)会自动识别这些分片文件并将它们组合在一起,以还原出完整的模型。这是通过文件名中的分片编号来实现的,框架会根据这些分片顺序依次加载。 - 加载示例:例如,当你调用
AutoModel.from_pretrained时,它会自动加载所有这些文件并合并它们为一个完整的模型。
解决问题
因此,需要去modelscope或者huggingface中,找到chatglm3的模型文件库(chatglm3链接:魔搭社区),把上述缺失的文件下载到本地模型文件夹中。如下图最简单的方法,点击缺失文件对应的下载按钮即可。
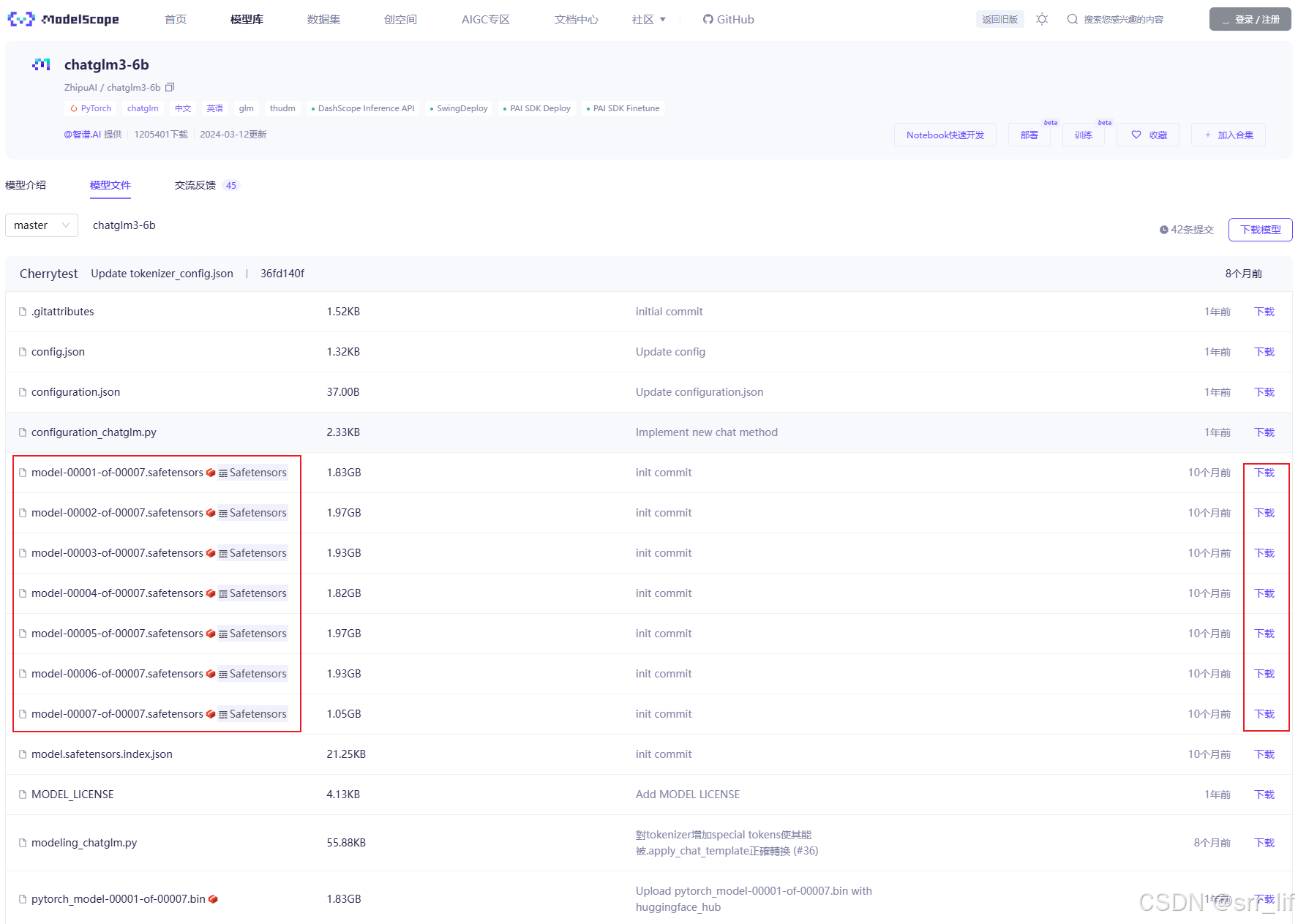
推荐在命令行中下载缺失的文件,速度会快一些,在你创建的conda虚拟环境中执行下面的命令,记得先切换目录到你的模型文件中:
#请先通过如下命令安装ModelScope
pip install modelscope
#下载多个文件到指定本地文件夹(以下载pytorch_model-00003-of-00007.bin和pytorch_model-00005-of-00007.bin到D盘路径下“chatglm3-6b”目录为例)
modelscope download --model ZhipuAI/chatglm3-6b pytorch_model-00003-of-00007.bin pytorch_model-00005-of-00007.bin --local_dir D:\projects\models\chatglm3-6b注:模型SDK下载方法
使用 modelscope 中的snapshot_download函数下载模型,第一个参数为模型名称,参数cache_dir(可选参数)为模型的下载路径。
在 /home/kai路径下新建 download.py 文件并在其中输入以下内容,粘贴代码后记得保存文件,如下图所示。并运行 python /home/kai/download.py 执行下载,模型大小为14 GB,下载模型大概需要10~20分钟。
import torch
from modelscope import snapshot_download, AutoModel, AutoTokenizer
import os
model_dir = snapshot_download('ZhipuAI/chatglm3-6b',cache_dir='/home/kai/models')
代码执行后的操作:
- 当
snapshot_download函数执行后,它会从指定的URL下载模型文件,并将其保存到cache_dir指定的目录中。 - 如果指定的
cache_dir目录不存在,函数可能会尝试创建它。 - 如果模型已经存在于指定的缓存目录中,函数将不会重新下载模型,而是直接使用缓存的模型。
- 函数返回值
model_dir是一个字符串,表示下载后的模型文件所在的目录路径。
请注意,要成功运行这段代码,你需要有网络连接,并且modelscope库需要提前安装在你的环境中。如果modelscope没有安装,你可以使用以下命令来安装:
pip install modelscope
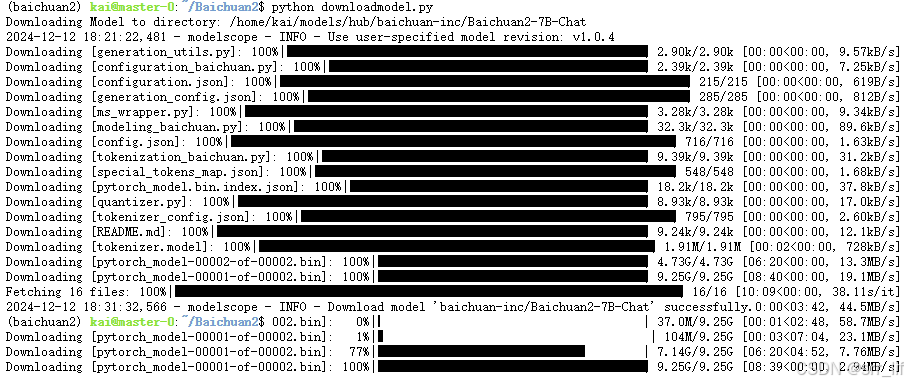
下面展示一下我使用SDK下载baichuan2大模型的场景:可以实时看到下载进度

















 1063
1063

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









