







今天给大家分享的内容非常实用,是干货中的干货,建议收藏~
微信公众号没有官方API,想批量获取文章构建AI知识库太痛苦了!
所以,我利用 n8n 实现了一套自动化工作流,现在可以轻松让知识库“吞下”多个公众号(可配置)的所有历史文章,并能实现监听多个公众号的最新文章自动同步到AI知识库。
比如可以同时监控卡兹克、差评、袋鼠帝AI客栈等任何你喜欢的公众号。也可以添加Agent节点,让AI筛选指定内容(比如只想同步Dify、n8n相关的文章)
以Fastgpt和Dify的知识库为例。
这套工作流(共有2个),我花了不少时间和精力来搭建,现在掰开揉碎了分享给你。
只想换你免费的三连(点赞、转发、推荐)
学完本期内容,你将收获

1.批量导出公众号历史文章存入AI知识库的方法;
2.自动更新公众号最新文章到AI知识库的思路;
3.免费获取2个n8n工作流文件。

同时,基于这篇文章的工作流和思路,你还可以搭建其他别的跟公众号内容相关的AI工作流,比如AI分析公众号爆文,AI提取各领域热点,让AI筛选优质文章等等。
这套n8n工作流重写一下,也可以丢到Dify里面运行。
工作流在文末获取,是json文件,可以直接导入n8n使用
好了,好不多说,我们直接开始喂饭!

公众号历史文章导出

在看这篇之前最好先看看上一篇
主要讲了如何把公众号的历史文章批量存入Fastgpt和Dify的知识库。
批量获取公众号历史文章存到AI知识库
袋鼠帝,公众号:袋鼠帝AI客栈Dify接入这套n8n自动化方案后,能吞下整个微信公众号了(可自动更新),直接封神!【一】
同时上篇文章中承若的n8n工作流(如下图,批量获取公众号历史文章)也可以在文末一并获取
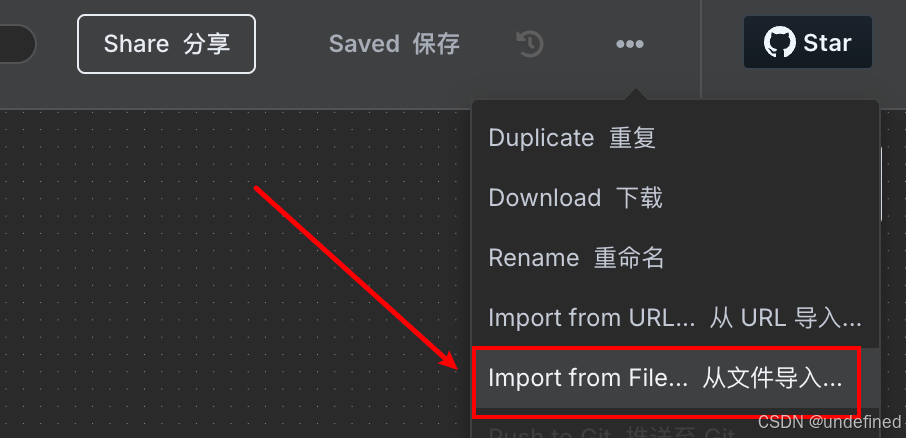
这个工作流雏形由Gemini生成,经过我的二次修改才正常运行。
这个工作流中,「循环获取每页数据」节点需要配置两个参数biz和apikey
biz和apikey在上一篇有介绍,这里就不重复赘述了

整个流程的左半部分:通过循环分页请求极致了API,获取某个公众号的历史文章,因为每次只会返回5篇文章,所以需要循环请求,直到拿到所有文章。
整个流程的右半部分:拿到所有文章信息后,经过处理保存到本地,最终会产生两个文件,urls.txt和all_data.json
由于我们的n8n是docker部署
不清楚如何使用docker一键部署n8n的朋友可以先看看下面这篇
开源n8n介绍和本地部署
袋鼠帝,公众号:袋鼠帝AI客栈狂揽75K Star!最强开源AI Workflow平台【内置1500+工具和模板】效率起飞~
导出的文章信息文件只会存储在n8n的docker容器内部
我们需要在n8n的docker-compose.yml文件中添加一个容器路径和本机电脑路径映射的配置(如下图红框中的配置)
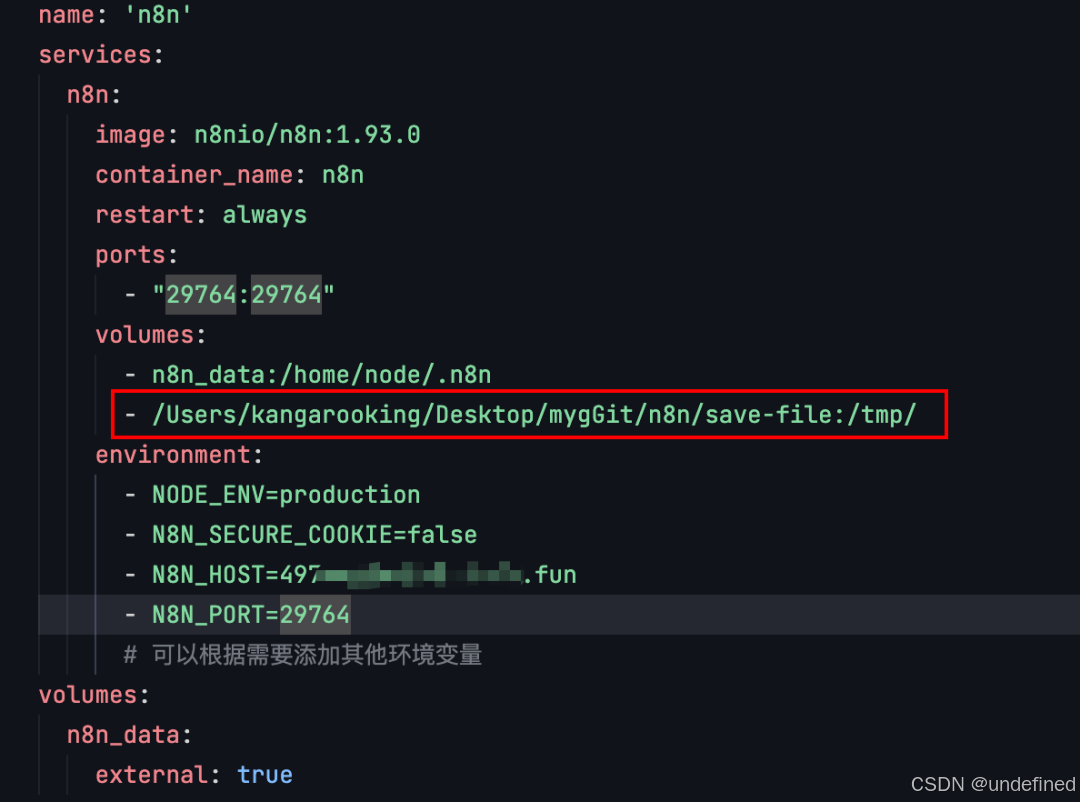
左边是本地电脑路径(自行选择一个文件夹),右边是n8n的docker容器路径(我选的tmp文件夹)
这样导出到docker容器/tmp/下的文件,就能自动同步一份到我们配置好的本地电脑文件夹中
注意:修改docker-compose.yml文件之后,需要在该文件所在目录的控制台或终端执行docker-compose up -d,重置一下服务,才能让配置生效
这一部分只讲如何使用历史文章信息导出的n8n工作流,导入知识库的整套流程需结合上一篇一起看哦。

公众号最新文章自动同步知识库

上面解决了公众号历史文章,接下来我们看看公众号后续新发布的文章如何自动同步到Fastgpt和Dify的知识库。配置了两个公众号,差评和刘聪NLP,整个工作流执行只花了不到两秒,就把这两个公众号当天的一共7篇文章同步到Fastgpt和Dify的知识库中了。
就算再来100篇也是几秒内完成。
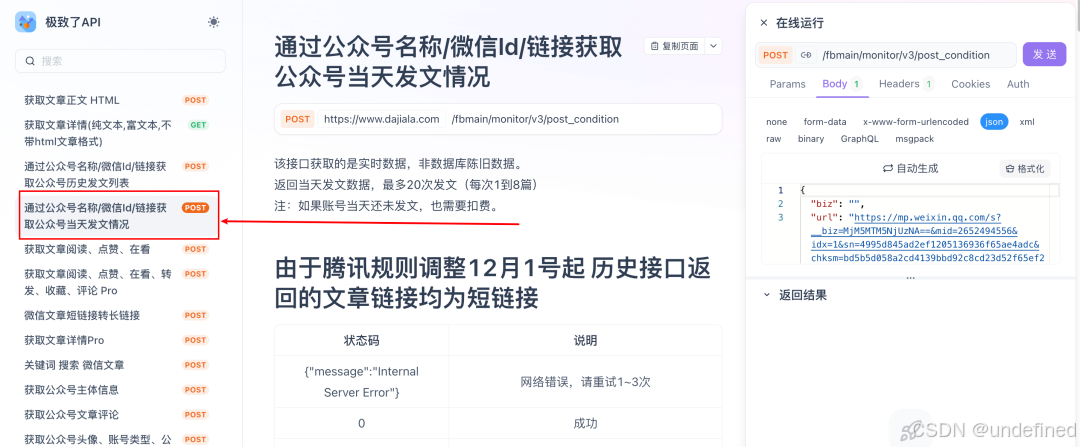
需要用到极致了的API(获取公众号当天发文)
dajiala.com
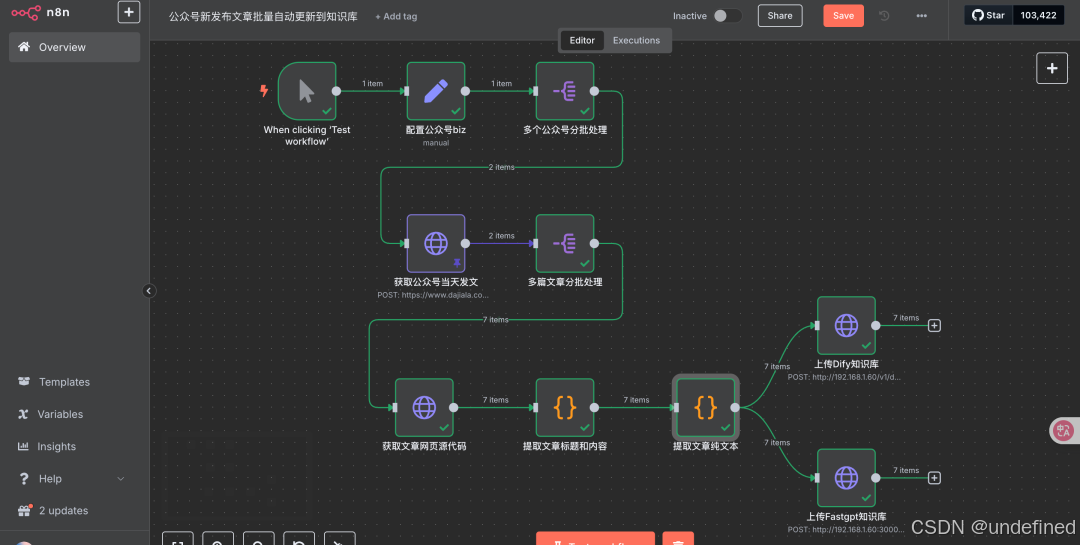
整个工作流也不复杂

首先通过极致了API,获取多个公众号当天发文信息(拿到文章url链接),然后通过get请求获取每个文章的网页HTML源代码,在用代码解析出文章内容和标题,然后提取内容的纯文本(去掉了图片链接和一些特殊符号),最后把纯文本的内容通过Fastgpt和Dify各自的API接口上传到他们的知识库中。

需要一个极致了的apikey,以及公众号的唯一标识:biz
apikey和biz的获取方式都写在上一篇了
同时这个API是收费的,也不算贵,0.06元/次
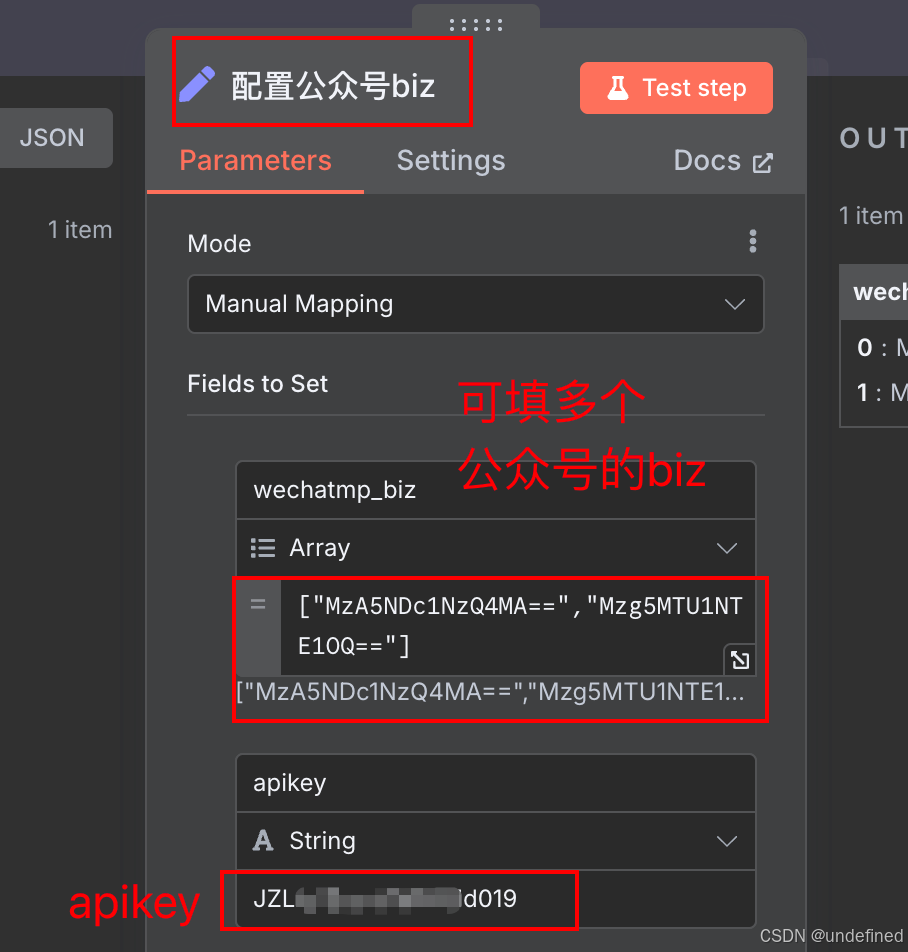
apikey和biz填写到工作流中的第一个节点(如下图)
注意,增加公众号biz也要保持下面的数组格式
然后就是配置Fastgpt和Dify的文本上传知识库API的请求参数了
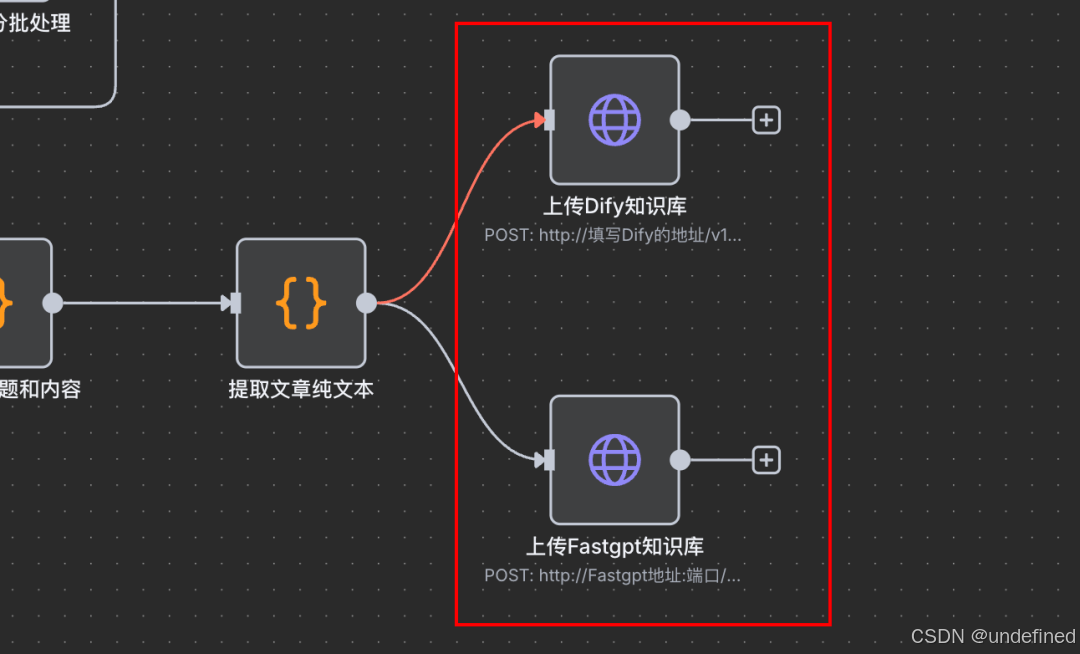
Dify在「上传Dify知识库」节点配置
请求参数还挺复杂(下面是curl的请求格式)
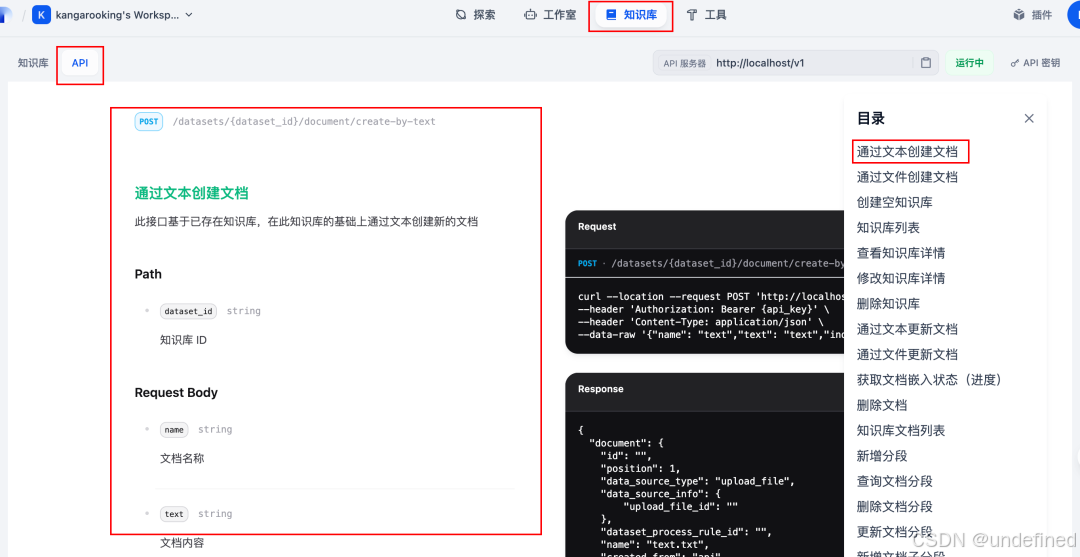
curl --location --request POST 'https://api.dify.ai/v1/datasets/你的知识库ID/document/create-by-text' \--header 'Authorization: Bearer 你的API密钥' \--header 'Content-Type: application/json' \--data-raw '{"name": "文档名称","text": "这是需要上传的文章内容。Dify将自动进行QA分段处理。","indexing_technique": "high_quality","doc_form": "qa_model","doc_language": "Chinese","process_rule": {"mode": "custom","rules": {"pre_processing_rules": [{"id": "remove_extra_spaces", "enabled": true},{"id": "remove_urls_emails", "enabled": true}],"segmentation": {"separator": "\n\n","max_tokens": 1000}}},"retrieval_model": {"search_method": "hybrid_search","reranking_enable": true,"reranking_mode": "reranking_model","reranking_model": {"reranking_provider_name": "siliconflow","reranking_model_name": "BAAI/bge-reranker-v2-m3"},"top_k": 5,"score_threshold_enabled": true,"score_threshold": 0.5,"semantic_weight": 0.7,"keyword_weight": 0.3},"embedding_model": "BAAI/bge-m3","embedding_model_provider": "siliconflow"}'
这些请求参数的含义可以在Dify的知识库API文档查看
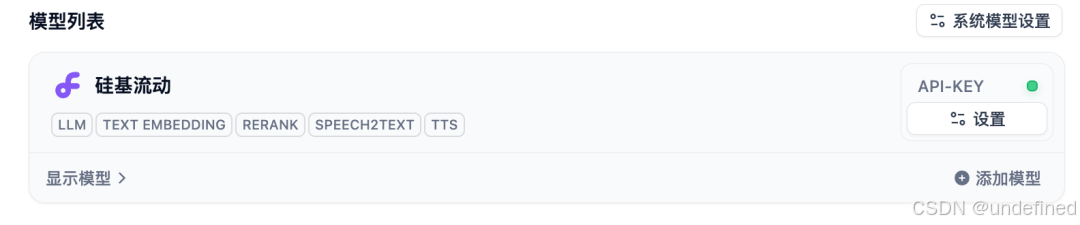
同时请给Dify配置一个硅基流动的模型供应商,默认用了硅基流动的嵌入模型和重排模型。
最后在「上传Dify知识库」节点中配置Dify的地址、apikey、知识库Id
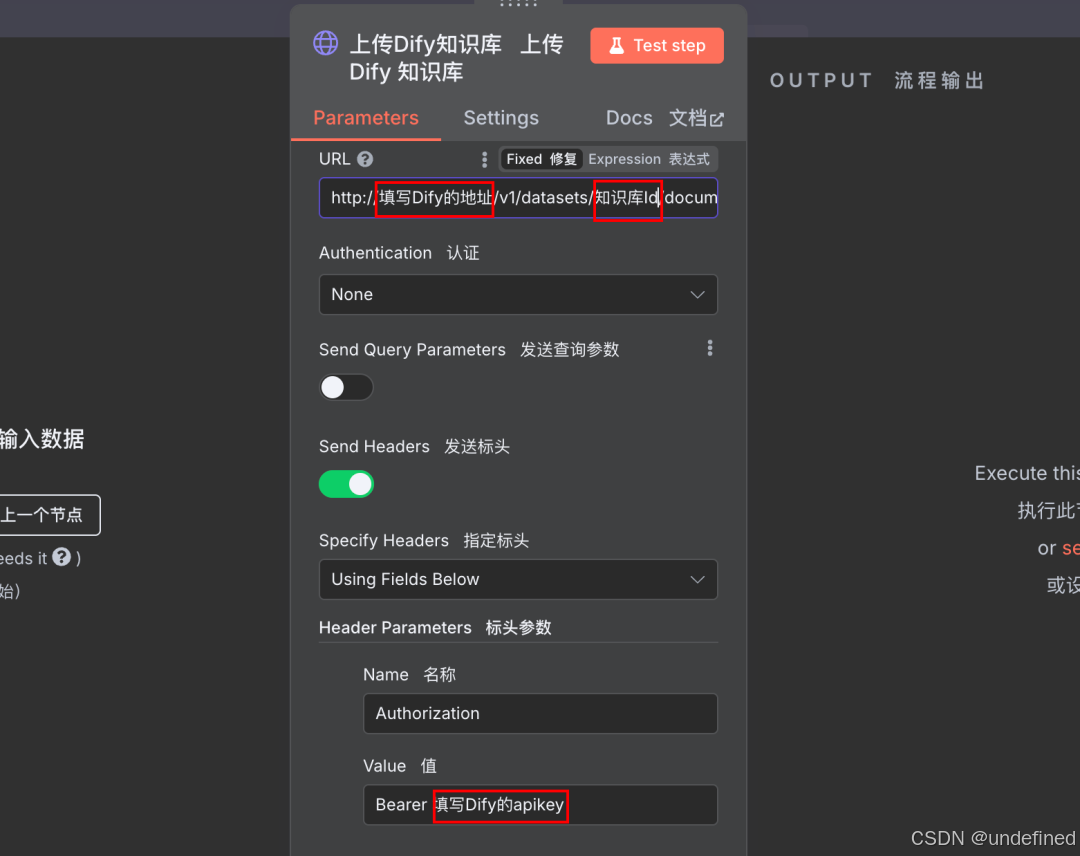
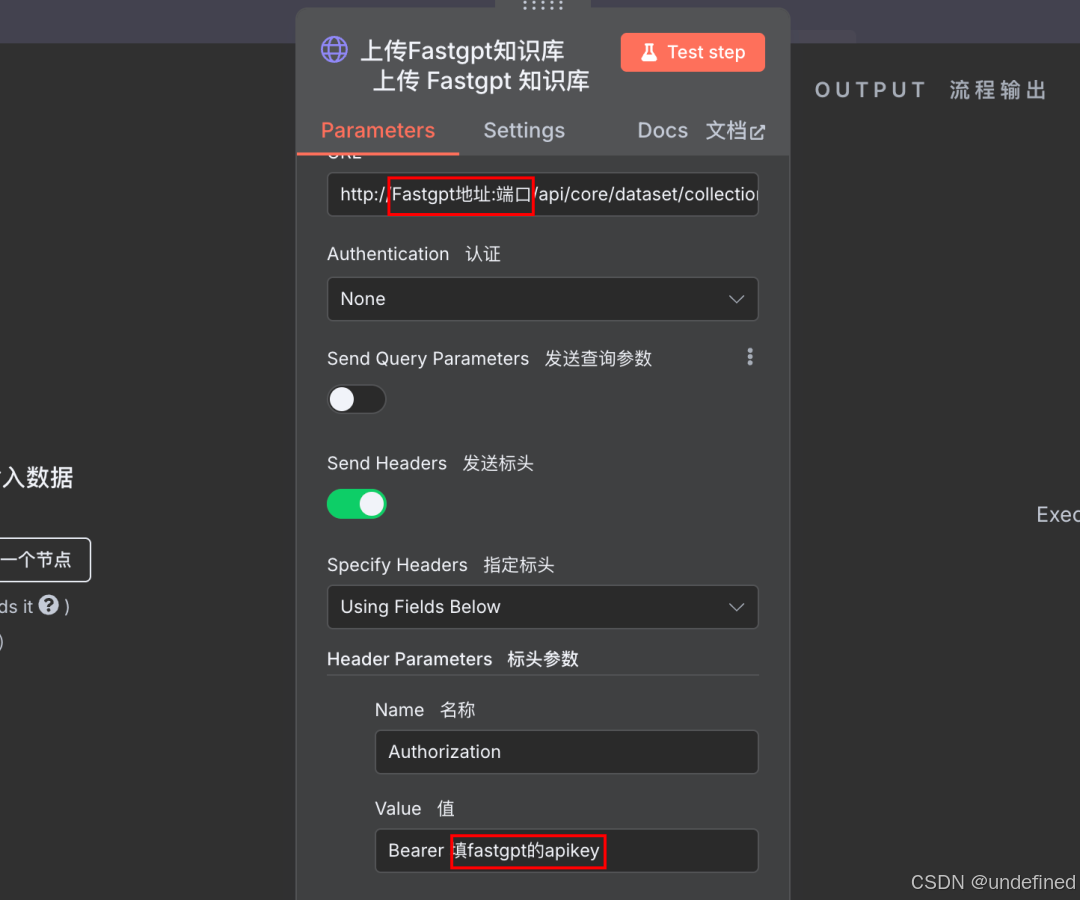
apikey请填写在Bearer空格的后面,一定要保留Bearer+空格!!!
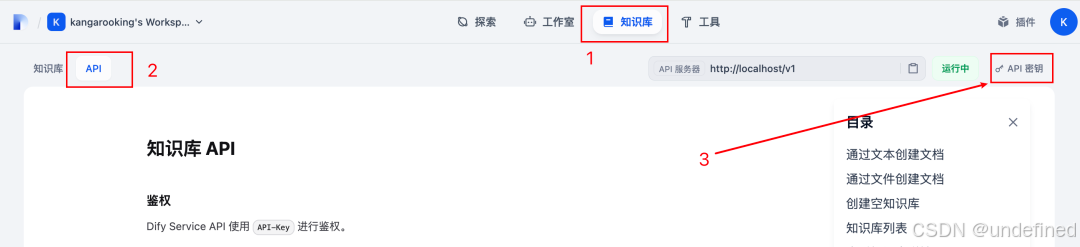
Dify apikey获取方式如下图(知识库->API->API密钥->创建apikey)
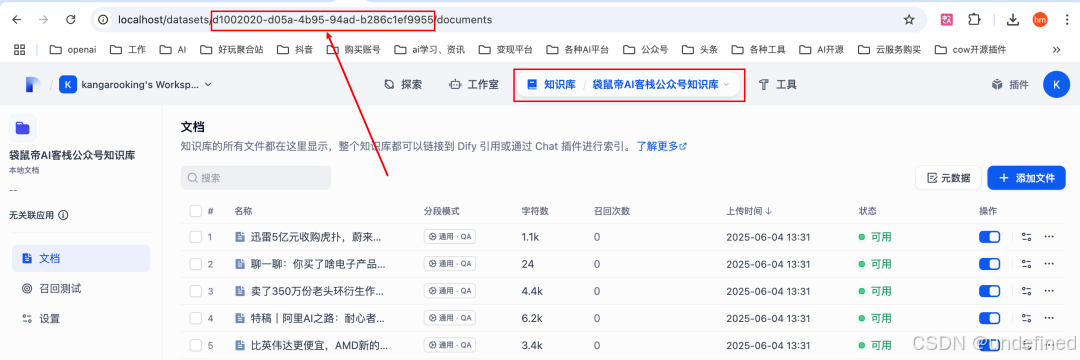
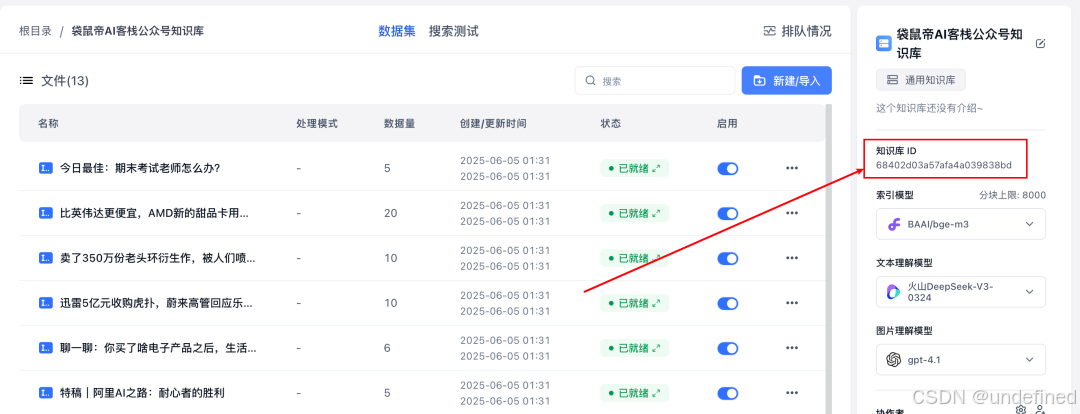
创建一个知识库,点进去之后,地址栏中间这部分就是知识库Id
接着配置Fastgpt的文本上传知识库API
同样需要Fastgpt的apikey、地址、知识库Id
Fastgpt的apikey获取方式(账号->API密钥->新建)
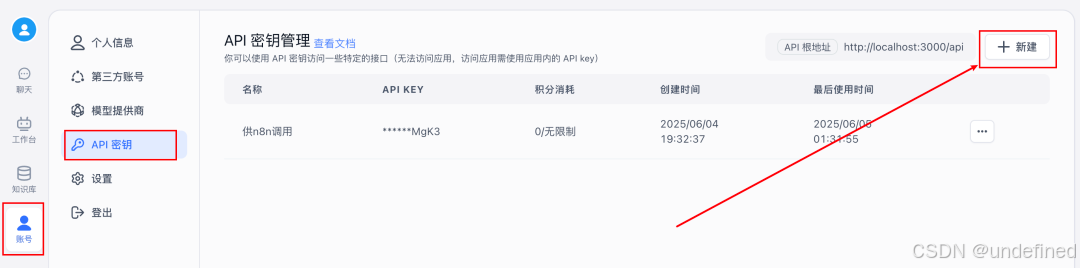
点进一个创建好的知识库详情页,右边就是知识库Id
Fastgpt的知识库上传API请求参数相对简单多了
curl --location --request POST 'https://api.fastgpt.in/api/core/dataset/collection/create/text' \--header 'Authorization: Bearer 你的API密钥' \--header 'Content-Type: application/json' \--data-raw '{"text": "这是需要上传的文章内容。可以是一整篇较长的文章,FastGPT会自动进行QA拆分。","datasetId": "你的知识库ID","parentId": null,"name": "文章标题或集合名称","trainingType": "qa","chunkSettingMode": "auto","qaPrompt": ""}'
apikey和地址+端口填写在下图位置
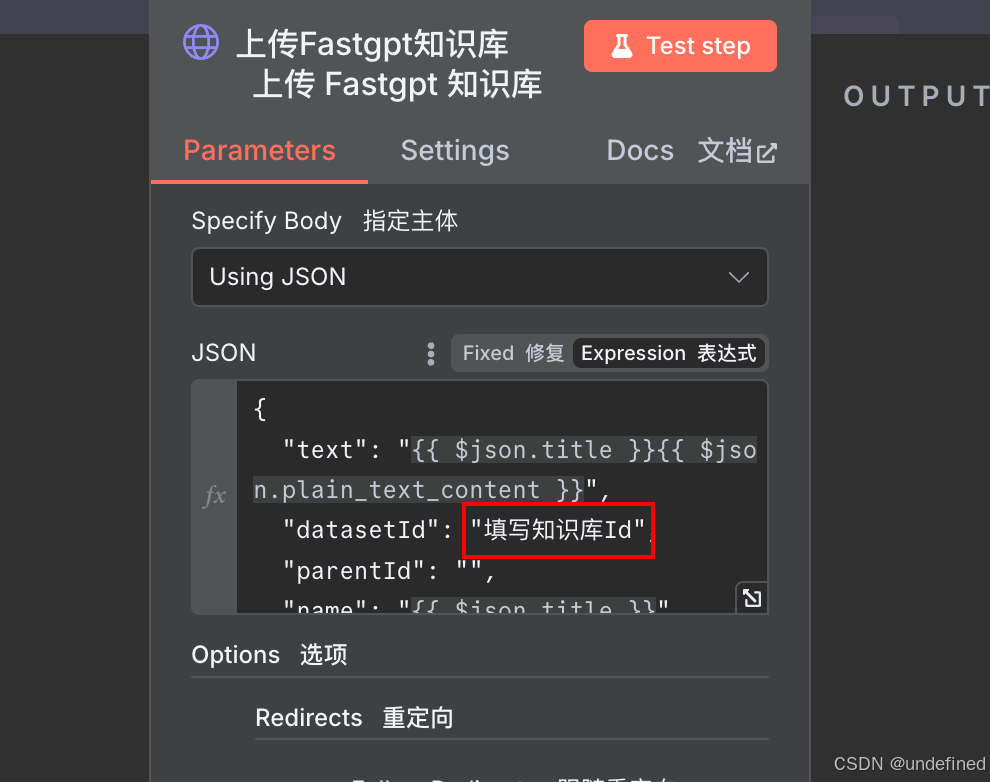
知识库Id填写在请求参数里面
到这里就大功告成了!
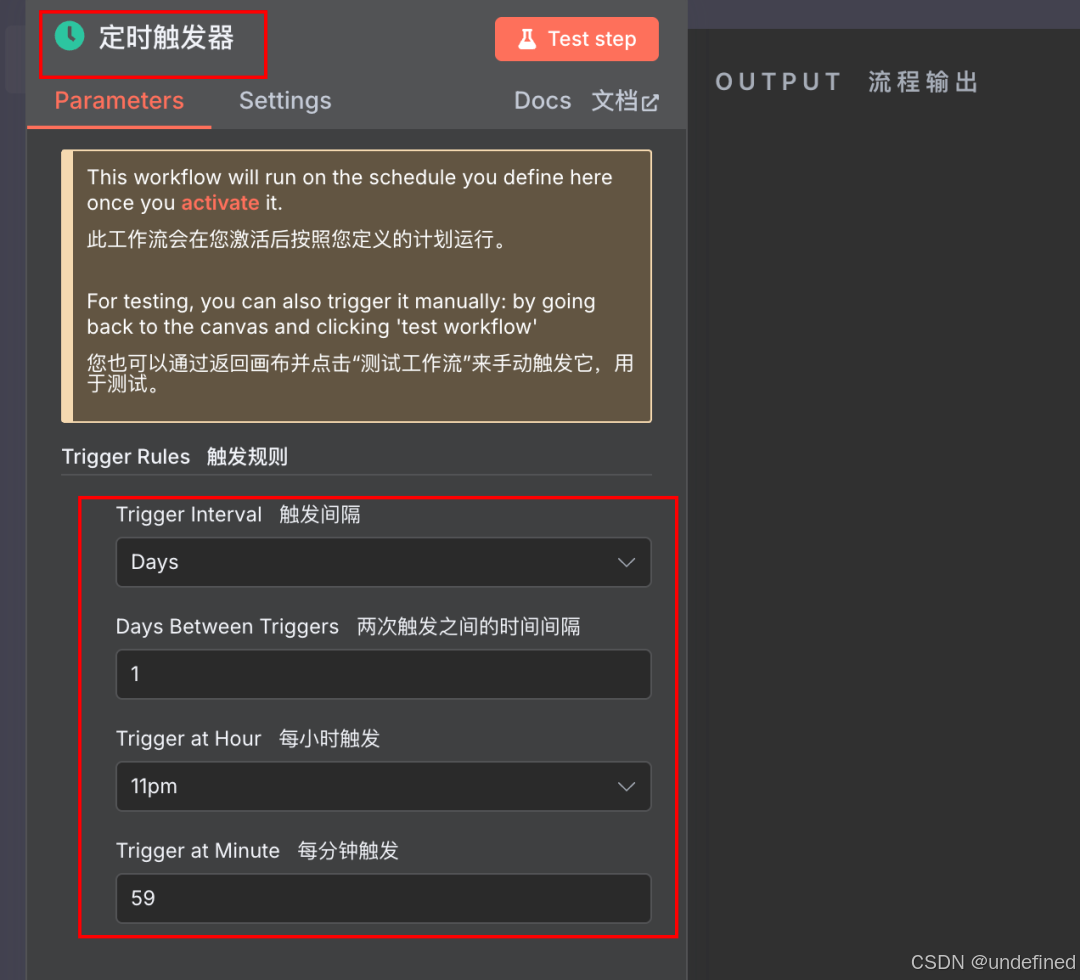
哦不,如果要它每天自动执行的话,设置定时触发器就好了,我这里设置的是每天晚上11点59分执行一次。
当然这个工作流目前是第一版,做的还比较简单,缺点就是一天执行一次,虽然能自动同步,但要接受延迟,最大延迟24小时。
如果每天轮询多次的话,还需要去重,比如判断已经成功同步到知识库的文章就不再执行同步了。
亲测,对于同一篇文章,Fastgpt会重复插入,Dify会重新跑一遍覆盖原来的。
晚上11.59分执行同步公众号当天的文章,基本不会漏。除非目标公众号刚好卡在晚上11.59~12.00之间发布新文章...
最后,别忘了保存、激活工作流

如果要加入Agent节点去分析、总结、筛选公众号文章。
又或者Dify、Fastgpt的对话、嵌入、重排模型需要自由切换更多种类。
可以使用我最近发现的一个宝藏API中转站:麻雀API
ismaque.org
api.apicore.ai
PS:以上两个域名都是同一个站点(都可用)

这个中转站基本做到了国内最低的价格,而且比较稳定。
中转API有逆向和官网的分组,逆向的分组只需要官方价格的十分之一或更低,官网API也只要官方价格的5-6折。
前段时间非常火的吉卜力图片逆向出图,只需0.02元一张图
现在更火的flux-kontext-pro,仅需一毛一次。
我的评价是划算、稳定、好用,有需要的朋友可以试试。
能看到这里的都是凤毛麟角的存在!
如果觉得不错,随手点个赞、在看、转发三连吧~
如果想第一时间收到推送,也可以给我个星标⭐



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









