







一、正则表达式理解
正则即是正确的规则。
正则表达式通过一些特殊的符号来操作字符串数据,可以简化书写,不过定义太多也不便于阅读。
| 字符 | |
|---|---|
| x | 字符 x |
| \\ | 反斜线字符 |
| \0n | 带有八进制值 0 的字符 n (0 <= n <= 7) |
| \0nn | 带有八进制值 0 的字符 nn (0 <= n <= 7) |
| \0mnn | 带有八进制值 0 的字符 mnn(0 <= m <= 3、0 <= n <= 7) |
| \xhh | 带有十六进制值 0x 的字符 hh |
| \uhhhh | 带有十六进制值 0x 的字符 hhhh |
| \t | 制表符 ('\u0009') |
| \n | 新行(换行)符 ('\u000A') |
| \r | 回车符 ('\u000D') |
| \f | 换页符 ('\u000C') |
| \a | 报警 (bell) 符 ('\u0007') |
| \e | 转义符 ('\u001B') |
| \cx | 对应于 x 的控制符 |
| 字符类 | |
| [abc] | a、b 或 c(简单类) |
| [^abc] | 任何字符,除了 a、b 或c(否定) |
| [a-zA-Z] | a 到 z 或 A 到 Z,两头的字母包括在内(范围) |
| [a-d[m-p]] | a 到 d 或 m 到 p:[a-dm-p](并集) |
| [a-z&&[def]] | d、e 或 f(交集) |
| [a-z&&[^bc]] | a 到 z,除了 b 和 c:[ad-z](减去) |
| [a-z&&[^m-p]] | a 到 z,而非 m 到 p:[a-lq-z](减去) |
| 预定义字符类 | |
| . | 任何字符(与行结束符可能匹配也可能不匹配) |
| \d | 数字:[0-9] |
| \D | 非数字: [^0-9] |
| \s | 空白字符:[ \t\n\x0B\f\r] |
| \S | 非空白字符:[^\s] |
| \w | 单词字符:[a-zA-Z_0-9] |
| \W | 非单词字符:[^\w] |
| POSIX 字符类(仅 US-ASCII) | |
| \p{Lower} | 小写字母字符:[a-z] |
| \p{Upper} | 大写字母字符:[A-Z] |
| \p{ASCII} | 所有 ASCII:[\x00-\x7F] |
| \p{Alpha} | 字母字符:[\p{Lower}\p{Upper}] |
| \p{Digit} | 十进制数字:[0-9] |
| \p{Alnum} | 字母数字字符:[\p{Alpha}\p{Digit}] |
| \p{Punct} | 标点符号:!"#$%&'()*+,-./:;<=>?@[\]^_`{|}~ |
二、常见操作:
1,匹配:其实用的就是String类中的matches方法。
String reg = “[1-9][0-9]{4,14}”;
boolean b = qq.matches(reg);//将正则和字符串关联对字符串进行匹配。
2,切割:其实用的就是String类中的split方法。
3,替换:其实用的就是String类中的replaceAll();
4,获取:
1),先要将正则表达式编译成正则对象。使用的是Pattern中静态方法 compile(regex);
2),通过Pattern对象获取Matcher对象。
Pattern用于描述正则表达式,可以对正则表达式进行解析。
而将规则操作字符串,需要从新封装到匹配器对象Matcher中。
然后使用Matcher对象的方法来操作字符串。
如何获取匹配器对象呢?
通过Pattern对象中的matcher方法。该方法可以正则规则和字符串想关联。并返回匹配器对象。
3),使用Matcher对象中的方法即可对字符串进行各种正则操作。
5、组和捕获
捕获组可以通过从左到右计算其开括号来编号。例如,在表达式 ((A)(B(C)))中,存在四个这样的组:
1 ((A)(B(C)))
2 \A
3 (B(C))
4 (C)
组零始终代表整个表达式。在替换中常用$匹配组的内容。
三、案例演示:
案例1:演示简单的正则操作
package myDemo;
/*
正则
*/
import java.util.regex.*;
public class Regex
{
public static void sop(Object obj)
{
System.out.println(obj);
}
public static void main(String[] args)
{
functionDemo_1();
sop("---------------------------");
functionDemo_2();
sop("---------------------------");
functionDemo_3();
sop("---------------------------");
functionDemo_4();
sop("---------------------------");
functionDemo_5();
sop("---------------------------");
functionDemo_6();
sop("---------------------------");
}
public static void functionDemo_1()
{
//匹配手机号码
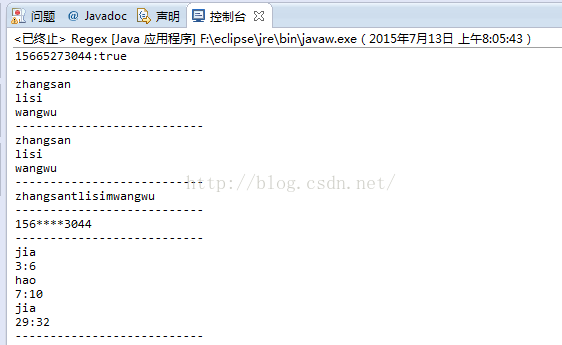
String tel = "15665273044";
String regex = "1[358]\\d{9}";
Boolean b = tel.matches(regex);
sop(tel+":"+b);
}
public static void functionDemo_2()
{
//演示切割
String tel = "zhangsan lisi wangwu";
String[] gex = tel.split("\\s+");
for(String str : gex)
{
sop(str);
}
}
public static void functionDemo_3()
{
//演示切割
//(.)表示一组,\\1+表示与第1组相同的出现1次以上
String tel = "zhangsanttttttlisimmmmmmmmmmmwangwu";
String[] gex = tel.split("(.)\\1+");
for(String str : gex)
{
sop(str);
}
}
/*
* 演示替换
*/
public static void functionDemo_4()
{
//$表示前一个参数的第一组
String tel = "zhangsanttttttlisimmmmmmmmmmmwangwu";
String gex = tel.replaceAll("(.)\\1+","$1");
sop(gex);
}
public static void functionDemo_5()
{
String tel = "15665273044";
tel = tel.replaceAll("(\\d{3})(\\d{4})(\\d{4})","$1****$3");
sop(tel);
}
/*
* 演示获取
* 将正则规则进行对象的封装。
* Pattern p = Pattern.compile("a*b");
* 通过正则对象的matcher方法字符串相关联。获取要对字符串操作的匹配器对象Matcher。
* boolean b = m.matches();
*/
public static void functionDemo_6()
{
//打印三个字符的单词
// \\b表示单词边界
String tel = "da jia hao,ming tian bu fang jia";
//1. 将正则封装成对象
String regex = "\\b[a-z]{3}\\b";
Pattern p = Pattern.compile(regex);
//2. 通过正则对象获取匹配器对象
Matcher m = p.matcher(tel);
//使用Matcher对象的方法对字符串进行操作。
//既然要获取三个字母组成的单词。
//查找:find();
while (m.find())
{
sop(m.group());//获取匹配的子序列
sop(m.start()+":"+m.end());//字符在字符串中的索引位置
}
}
}<strong>
</strong>结果:
案例2:
package regexTest;
import java.util.TreeSet;
/**
* @author LinP
* 1.治疗口吃:我...我我...我我我..我我我我......
* 我我我我..要要要...要要要..学学学.编编..编...编.编.编编..编程..程程程
*
* 2 ip地址排序。
* 192.168.10.34 127.0.0.1 3.3.3.3 105.70.11.55
*
* 3.//对邮件地址校验
*/
public class RegexDemo {
public static void main(String[] args) {
function_Test1();
System.out.println("-------------------------");
function_Test2();
System.out.println("-------------------------");
function_Test3();
}
private static void function_Test3() {
//对邮件地址校验。
String mail = "995676373@qq.com";
String regex = "[a-zA-Z0-9_]+@[a-zA-Z0-9]+(\\.[a-zA-Z]{1,3})+";
boolean b = mail.matches(regex);
System.out.println(mail + ":" + b);
}
private static void function_Test2() {
String ip_str = "192.168.10.34 127.0.0.1 3.3.3.3 105.70.11.55";
//1. 为了让ip可以按照字符串顺序比较,只要让ip的每一段的位数相同。
//所以,补零,按照每一位所需最多0进行补充,每一段都加两个0。
ip_str = ip_str.replaceAll("(\\d+)","00$1");
System.out.println(ip_str);
//然后每一段保留数字3位。
ip_str = ip_str.replaceAll("0*(\\d{3})","$1");
System.out.println(ip_str);
//1. 将ip地址切出。
String[] ips = ip_str.split(" +");
TreeSet<String> ts = new TreeSet<String>();
for(String ip : ips){
ts.add(ip);
}
for(String ip : ts){
System.out.println(ip.replaceAll("0*(\\d+)","$1"));
}
}
private static void function_Test1() {
String str = "我...我我...我我我..我我我我......我我我我我..要要要...要要..学学学.编编..编...编.编.编编..编程..程程程";
//1. 将字符串中.去掉,用替换。
String s = str.replaceAll("\\.+", "");
//2. 替换叠词
String s1 = s.replaceAll("(.)\\1+","$1");
System.out.println(s1);
}
}
结果:
案例演示3:

网络爬虫
/**
*
*/
package regexTest;
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URL;
import java.util.ArrayList;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* @author LinP
* 网络爬虫
* 网页爬虫:其实就是一个程序用于在互联网中获取符合指定规则的数据。
* 爬取需要获取的信息。
*/
public class RegexDemo4 {
/**
* @param args
* @throws IOException
*/
public static void main(String[] args) throws IOException {
// TODO 自动生成的方法存根
//getMailAddress();
getMailAddressByWeb();
}
private static void getMailAddressByWeb() throws IOException {
// TODO 自动生成的方法存根
URL url = new URL("http://bbs.itheima.com/thread-200600-1-1.html");
BufferedReader bufr = new BufferedReader(new InputStreamReader
(url.openStream()));
Pattern p = Pattern.compile("\\w+(\\.\\w+)+");
String line = null;
while((line = bufr.readLine())!=null){
Matcher m = p.matcher(line);
while(m.find()){
System.out.println(m.group());
}
}
}
private static void getMailAddress() throws IOException {
//1. 读取源文件。
BufferedReader bufr = new BufferedReader(new FileReader
("C:/Users/LinP/Desktop/gaoxin/3-反射/3-反射.html"));
//2. 对读取的数据进行规则的匹配。从中获取符合规则的数据。
Pattern p = Pattern.compile("\\b\\.[a-zA-Z]{6}\\b");
ArrayList<String> list = new ArrayList<String>();
String line = null;
while((line = bufr.readLine())!=null){
Matcher m = p.matcher(line);
while(m.find()){
System.out.println(m.group());
}
}
}
}
结果:

美好的一天!
-















 909
909

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









