







Python数据预处理技术与实践
1. 概述
-
数据预处理:
- 数据清理
- 数据集成
- 数据规约
- 数据变换(按照预先设计好的规则对抽取的数据进行转换,如把数据压缩到0.0~1.0区间)
- 数据降维
-
原始数据存在数据不完整、数据偏态、数据噪声、数据特征维度高、数据缺失值、数据错误值等问题
-
搜索引擎是中文分词的一个应用
-
相关度排序:把最相关的结果排在最前面。受中文分词的准确度影响。
2. Python科学计算工具
- NumPy
- SciPy
- Pandas
3. 数据采集与存储
-
数据形式:
-
结构化数据:存储和排列有规律,但扩展性差。
-
半结构化数据:
- 扩展性很好
- 邮件系统、档案系统、新闻网站等
- 网络爬虫、数据解析等方式采集。
-
非结构化数据:
-
文档、图片、音视频等,存储为二进制的数据格式
-
图片识别、人脸识别、医疗影像、文本分析等
-
网络爬虫、数据存档等方式采集。
-
-
-
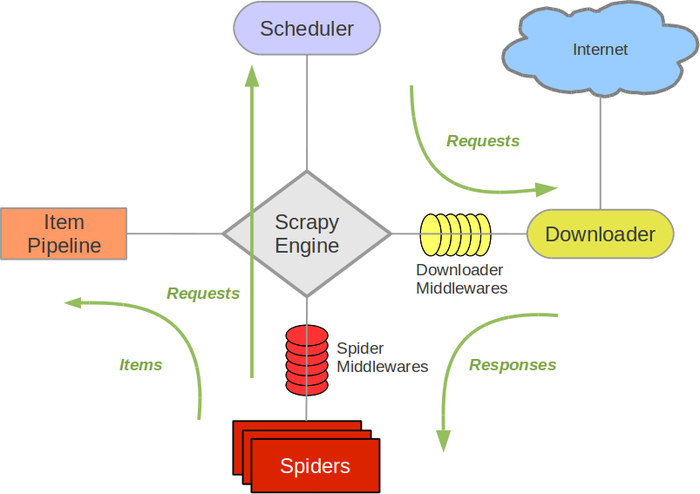
Scrapy:一个为爬取网络数据、提取结构化数据而设计的应用程序框架。
-
-
新建爬虫项目
-
# 1.安装scrap pip install scrap # 2.创建爬虫项目 scrapy startproject BoLeSpider # scrapy.cfg:项目的配置文件 # BoLeSpider/:项目的python模块,将会从这里饮用代码 # BoLeSpider/items.py:项目的目标文件 # BoLeSpider/popelines.py:项目的管道文件 # BoLeSpider/settings.py:项目的设置文件 # BoLeSpider/spiders/:存储爬虫代码的目录 # 3.BoLeSpider下创建爬虫目录 >> cd BoLeSpider >> scrapy genspider jobbole http://www.jobbloe.com/ # 4.在同级目录下,调用爬虫主程序 scrapy crawl jobbole # 5.在BoLeSpider目录下创建main.py,与4.执行效果一致,单独封装是为了调试和运行的便利 # -*- coding: utf-8 -*- import sys,os from scrapy.cmdline import execute sys.path.append(os.path.dirname(os.path.abspath(_file_))) execute(["scrapy", "crawl", "jobble"]) -
# 1.跳过错误页面继续爬取,更改setting.py文件 ROBOTSTXT_OBEY = False ITEM_PIPELINES = { 'BoLeSpider.pipelines.BolespiderPipeline': 1, } # BoLeSpider.pipelines.BolespiderPipeline BolespiderPipeline必须与pipilines中类名一致 # 2.http://www.jobbole.com/zhengquan/xg/184330/ 爬取内容 # 3.http://www.jobbole.com/zhengquan/xg/184330/ 查看源代码 cd BoLeSpider scrapy shell http://www.jobbole.com/zhengquan/xg/184330/ # 4.开始对每个特征进行测试 title = response.xpath('/html/body/div[3]/div[1]/div[3]/div[1]/h1/text()').extract() # 5.使用xpath方法获取 # 6.使用CSS方法- 获取文章的数据有两种方式:基于xpath和CSS。
-
-
4. 文本信息抽取
- 文本抽取形式:将采集到的不同类型文档统一处理成文本信息或者特征矩阵,得到高质量的数据集,然后将数据集放进算法模型中来挖掘其背后的价值。
- Pywin32:从Python访问Windows API的功能。
- 文本批量编码:UTF-8
5. 文本数据清洗
-
正则表达式:被用来检索、替换那些匹配某个模式的文本。
-
设计思想:用一种描述性的语言来给字符串定义一个规则,凡是符合规则的字符串,就认为它“匹配”了
-
清洗文本数据、处理HTML网页数据
-
-
简繁字体转换:zhtools工具包
6. 中文分词技术
-
关于统计模型的中文分词方法:
-
基于字符串匹配的分词方法:基于词典匹配,将待分词的中文文本根据一定的规则切分和调整,然后跟词典中的词语进行匹配,匹配成功则按照词典的词进行分词,匹配失败则调整或者重新选择,如此反复循环即可。代表方法:基于正向最大匹配和基于逆向最大匹配以及双向匹配法。
-
基于理解的分词方法:通过专家系统或者机器学习神经网络模拟人的理解能力。
前者是通过专家对分词规则的 逻辑推理并总结形成特征规则,不断迭代完善规则,其受到资源消耗大和算法复杂度高的制约。
后者通过机器模拟人类理解的方式,虽可以去的不错的效果,但是依旧受训练时间长和过度拟合的那个因素困扰。
-
基于统计的分词方法:
-
基于隐马尔可夫模型的中文分词方法:通过文本作为观测序列去确定隐藏序列的过程。
该方法采用Viterbi算法对新词的识别效果不错,但是具有生成式模型的特点,需要计算联合概率,因此随着文本的增大存在计算量大的问题。
-
基于最大熵模型的中文分词方法:学习概率模型时,在可能的概率分布模型中,以熵最大的进行切分。
该法可以避免生成模型的不足,但是存在偏移量问题。
-
基于条件随机场模型的中文分词方法:基本思想主要来源于最大熵马尔可夫模型,主要关注的字跟上下文标记位置有关,进而通过解码找到词边界。
需要大量训练语料,而训练和解码又非常耗时。
-
关于词典和规则的方法其分词速度较快,但是在不同领域取得的效果差异很大,还存在构造费时费力、算法复杂度高、移植性差等缺点。基于统计的痛次,虽然相较于规则的方法能取得不错的效果,但也依然存在模型训练时间长、分词速度慢等问题。
本文提出基于隐马尔可夫统计模型和自定义词典结合的方法,其在分词速度、歧义分析、新词发现和准确率方面都具有良好的效果。
-
-
结巴分词:基于Python的中文分词工具。
-
特征:
- 三种分词模式:可以实现自定义调整词典、关键词提取、词性标注和句法分析等功能。
- 全模式分词:把所有可以成词的词语都扫描出来,速度非常快,但不能解决歧义。
- 精确模式分词:试图将句子最精确地切开,适合文本分析。
- 搜索引擎模式分词:在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
- 支持繁体分词
- 支持自定义词典
- MIT授权协议
- 三种分词模式:可以实现自定义调整词典、关键词提取、词性标注和句法分析等功能。
-
核心方法:
- jieba.cut方法:可接受三个输入参数,分词的字符串、cut_all参数(用来控制是否采用全模式)和HMM参数(用来控制是否使用HMM模型(隐马尔可夫模型))
- jieba.cut_for_search:接收两个参数,一是需要分词的字符串,二是是否使用HMM模型(该方法使用于搜索引擎构建倒排索引的分词,粒度比较细)
- 待处理的字符串:unicode、UFTF-8、GBK编码格式。不建议直接输入GBK字符串,可能会出现无法预料的错误——解码成UFTF_8。
- 这两个方法返回的结构都是一个可迭代的generator,可以使用for循环来获得分词后得到的每一个词语(Unicode编码)
- 两个方法直接返回列表(List)
- 可以使用jieba.Tokenizer(dictionary=DEFAULT_DICT)新建自定义分词器,用于同时使用不同的词典。jieba.dt 为默认的分词器,所有全局分词相关的函数都是该分词器的映射。
-
自定义调整词典:使用add_word(word, freq=None, tag=None)在程序中动态修改词典。
-
关键词提取:extract_tags 三个参数:待处理的字符串、提取前n个词和是否根据权重设置。
import jieb
-
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4112
4112











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









