






一,Hadoop介绍
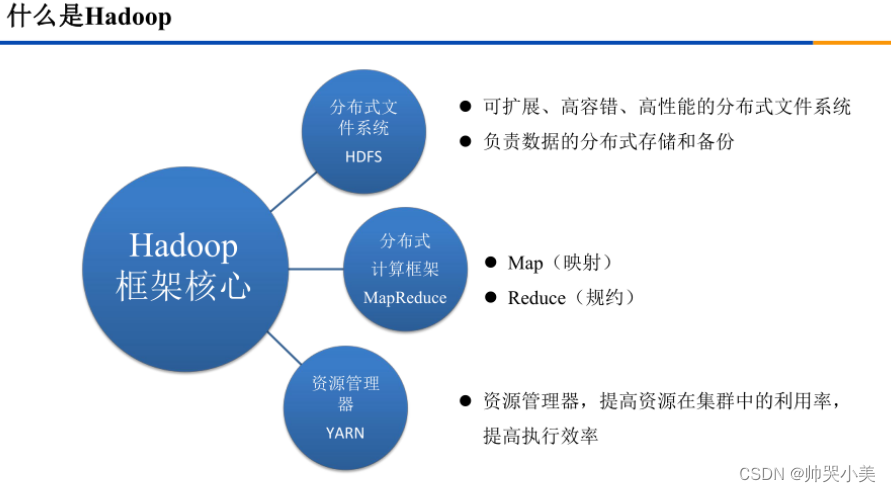
Hadoop是一个由Apache基金会所开发的分布式系统基础架构,主要用于海量数据的存储和海量数据的分析计算。用户可以在不了解分布式底层细节的情况下,开发分布式程序,充分利用集群的威力进行高速运算和存储。
Hadoop实现了一个分布式文件系统(Distributed File System),其中一个核心组件是HDFS(Hadoop Distributed File System)。HDFS具有高容错性的特点,并且设计用来部署在低廉的硬件上。它提供高吞吐量来访问应用程序的数据,适合那些有着超大数据集的应用程序。同时,HDFS放宽了POSIX的要求,可以以流的形式访问文件系统中的数据。
Hadoop的另一个核心组件是MapReduce,它为海量的数据提供了计算功能。MapReduce是Hadoop的分布式数据处理框架,也是Google MapReduce计算模型的开源实现,它支持大规模数据集的并行运算。
Hadoop的特点包括高可靠性、高拓展性、高效性、高容错性和低成本等。其高可靠性主要体现在Hadoop底层维持多个副本,即使Hadoop某个计算元素或存储出现故障,也不会导致数据丢失。高拓展性则体现在可以方便地在集群间分配任务数据,拓展数以千计的节点。高效性则源于MapReduce的并行工作思想,可以加快任务处理速度。
二,生态系统
Hadoop生态系统是一个庞大且复杂的集合,包含了多个组件和工具,它们共同协作以处理和分析大规模数据集。Hadoop生态系统的主要组成部分包括但不限于以下几个部分:
-
Hadoop Distributed File System (HDFS):这是Hadoop的核心组件之一,用于存储和管理大规模数据集。HDFS具有高容错性,并且设计用来部署在低廉的硬件上,提供高吞吐量的数据访问。
-
Hadoop MapReduce:MapReduce是Hadoop的计算框架,它支持大规模数据集的并行处理。通过将复杂的任务分解为两个主要阶段——Map阶段和Reduce阶段,MapReduce能够高效地处理和分析数据。
-
HBase:HBase是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,它利用HDFS作为其底层存储支持,在Hadoop之上提供了类似于BigTable的能力。
-
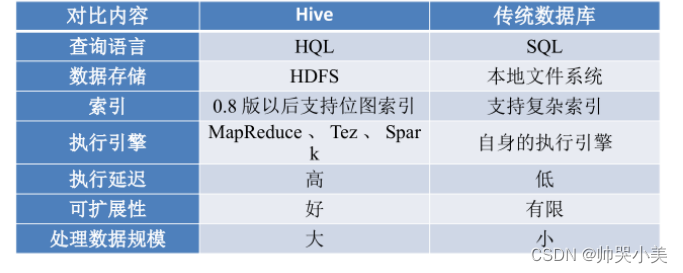
Hive:Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的SQL查询功能,使得数据查询和分析更加方便。
-
Pig:Pig是一个数据流语言和运行环境,用于在Hadoop上进行大规模数据处理。它允许用户编写简单的脚本来处理数据,而无需编写复杂的Java程序。
-

三,hadoop集群的搭建及配置
- Hadoop简介以及集群规划:
- 了解Hadoop的基本概念、特性和版本信息。
- 规划集群的架构,包括节点数量、角色分配等。
- 基础环境准备:
- 安装和配置Linux操作系统(如CentOS)。
- 确保网络配置正确,所有节点之间能够相互通信。
- 关闭防火墙和SELinux:
- 在所有节点上关闭防火墙,以确保Hadoop组件之间的通信不受阻碍。
- 关闭SELinux(Security-Enhanced Linux),以避免安全策略导致的问题。
- 配置IP地址映射:
- 设置并配置所有节点的IP地址。
- 配置主机名解析,确保各节点之间可以通过主机名相互访问。
- 添加Hadoop用户并赋予权限:
- 在所有节点上创建Hadoop用户。
- 为Hadoop用户配置SSH密钥,实现免密码登录。
- Hadoop安装包下载与解压:
- 从官方网站或其他可信来源下载Hadoop安装包。
- 在主节点上解压安装包,并准备配置文件。
- 配置文件修改:
- 修改Hadoop的核心配置文件(如hadoop-env.sh、core-site.xml等)。
- 配置HDFS(Hadoop Distributed File System)和MapReduce的相关参数。
- 集群文件分发:
- 将Hadoop安装目录和相关配置文件复制到其他节点。
- 格式化NameNode:
- 在主节点上执行NameNode格式化操作,初始化HDFS的文件系统。
- 启动Hadoop集群:
- 在主节点上启动Hadoop集群。
- 检查集群状态,确保所有组件正常运行。
- 测试与验证:
- 通过运行一些简单的Hadoop作业来测试集群的性能和稳定性。
在搭建和配置Hadoop集群时,还需要注意以下几点:
- 确保所有节点的硬件和软件环境一致,以避免因环境差异导致的问题。
- 在进行配置和修改时,务必仔细核对每个参数的值,避免配置错误。
- 在搭建过程中,及时查看和记录日志信息,以便在出现问题时能够快速定位和解决。

四,hadoop基本操作
- HDFS基本操作:
- 文件上传:使用
hdfs dfs -copyFromLocal或hdfs dfs -put命令将本地文件上传到HDFS(Hadoop Distributed File System)中。 - 查看文件:可以使用
hdfs dfs -ls命令查看HDFS上的文件列表。 - 获取文件:使用
hdfs dfs -get命令将HDFS上的文件下载到本地。 - 删除文件或目录:使用
hdfs dfs -rm命令删除HDFS上的文件或目录。 - 创建目录:使用
hdfs dfs -mkdir命令在HDFS上创建目录。
- 文件上传:使用
- MapReduce作业操作:
- 编写MapReduce程序:使用Java等编程语言编写MapReduce程序,实现数据的分布式处理。
- 提交作业:使用Hadoop命令行工具提交MapReduce作业到集群上执行。
- 查看作业状态:通过Hadoop提供的Web界面或命令行工具查看作业的执行状态和进度。
- 集群管理操作:
- 启动/停止集群:使用Hadoop提供的脚本或命令启动或停止整个Hadoop集群。
- 查看集群状态:通过Hadoop的Web界面查看集群的健康状况、资源使用情况等。
- 其他常用命令:
- 查看文件系统根目录的文件夹:使用
hdfs dfs -ls /命令。 - 显示hadoop上的文件的内容:使用
hdfs dfs -cat <文件名>命令。 - 重命名文件:使用
hdfs dfs -mv <原文件名> <新文件名>命令。 
- 查看文件系统根目录的文件夹:使用
五,MapReduce编程入门
一、理解MapReduce基本概念
-
MapReduce模型:MapReduce是一种编程模型,它将大数据处理任务分解为两个主要阶段:Map阶段和Reduce阶段。
-
Map阶段:Map阶段将输入数据(通常是键值对)转换为中间键值对列表。每个输入记录都会独立地通过Map函数进行处理。
-
Shuffle和Sort阶段:在Map阶段之后,MapReduce框架会自动对中间键值对进行排序和分组,以便相同的键能够传递给同一个Reduce函数。
-
Reduce阶段:Reduce阶段将具有相同键的中间值组合起来,并生成最终的输出键值对。
二、编写MapReduce程序
-
环境准备:确保已经安装了Hadoop,并配置了正确的环境变量。
-
编写Map函数:创建一个类,继承自
Mapper接口,并实现其map方法。该方法接受输入键值对,并产生中间键值对。 -
编写Reduce函数:创建另一个类,继承自
Reducer接口,并实现其reduce方法。该方法接受具有相同键的中间值列表,并生成输出键值对。 -
设置Job配置:创建一个
Job对象,并设置MapReduce作业的配置,包括输入/输出路径、Mapper和Reducer类、输入输出格式等。 -
运行作业:提交作业到Hadoop集群,并等待作业完成。
-
六,HBase分布式数据库
HBase是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,适用于存储大表数据,表的规模可以达到数十亿行以及数百万列,对大表数据的读、写访问可以达到实时级别。它利用Hadoop HDFS作为其文件存储系统,并提供实时读写的分布式数据库系统。同时,HBase利用ZooKeeper作为协同服务。
HBase的主要特点包括:
- 面向列存储:能够有效地处理大规模数据和高并发访问。
- 高可靠性:通过数据的复制和分布存储实现数据的备份和容错。
- 高可伸缩性:支持水平扩展,可以方便地扩展集群规模以处理更大量级的数据。
- 快速读写:能够支持高速的读写操作,适合于实时数据访问和处理。
- 强一致性:提供强一致性的数据读写操作,确保数据的准确性和完整性。
- 灵活的数据模型:支持灵活的数据模型,可以存储半结构化和无结构化的数据,适合于存储各种类型的数据。
HBase的架构建立在Hadoop HDFS之上,Hadoop HDFS为HBase提供了高可靠的底层存储支持,Hadoop MapReduce为HBase提供高性能的计算能力,而ZooKeeper为HBase提供稳定服务和容错机制。
在实际应用中,HBase的使用场景非常广泛,包括但不限于对象存储(如海量图片、网页、新闻等)、时空数据(如轨迹、气象网格等)、时序数据、用户画像、消息/订单等。在这些场景中,HBase都能够发挥其高可靠性、高性能和面向列存储的优势,为大规模数据的存储和处理提供强大的支持。
总的来说,HBase是一个功能强大、灵活且可伸缩的分布式数据库系统,适用于处理大规模、实时、高并发的数据访问场景。















 2310
2310











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









