









在sql*plus环境中使用oracle数据库,除了使用sql语句外,用户接触比较多的是sql*plus命令。
sql*plus工具提供了许多操作oracle数据库的命令,具体如下:
help命令:
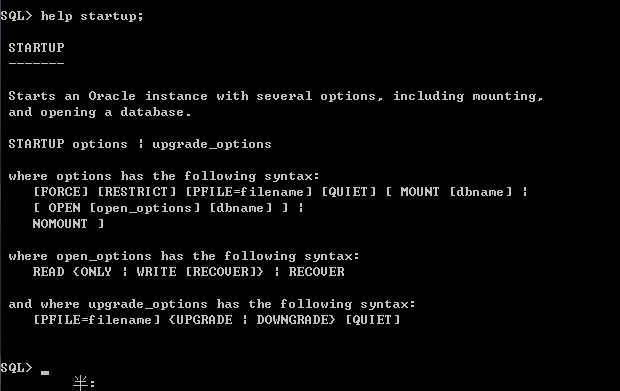
每个命令都有许多的选项,把所有命令都记住是不科学的,通过help命令就可以帮助用户去查询指定的命令选项,它可以向用户提供被查询命令的标题、功能描述、缩写形式和参数选项,如查询startup命令相关描述:
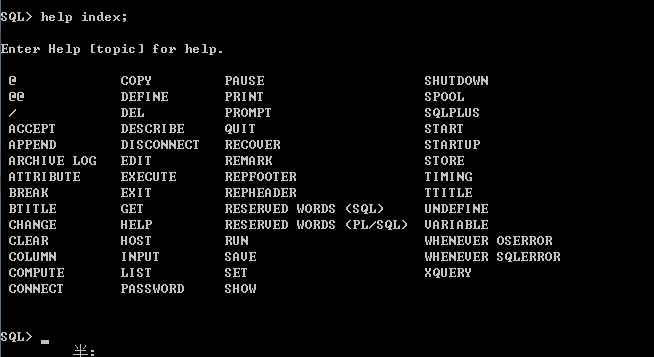
再比如index命令,它是用来查看sql*plus命令清单的:
discribe命令
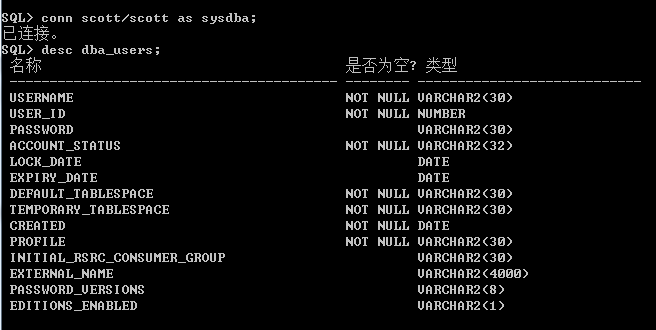
它是sql*plus中用到比较频繁的一个命令,它用来查看指定数据对象的组成结构,比如通过discribe命令可以查询表或是视图的结构,可以缩写为desc,查看如dba_users表:
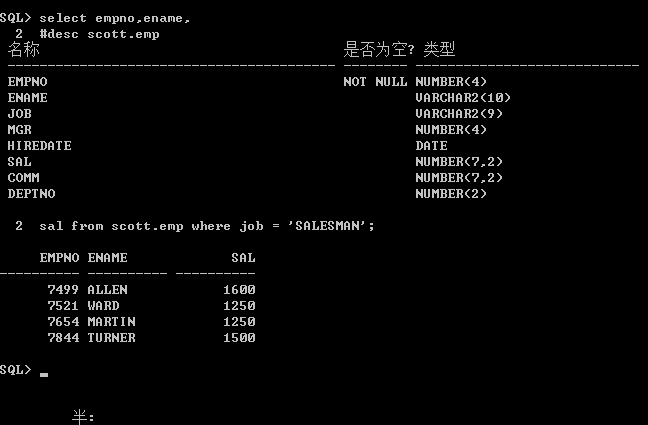
平常可以会遇到这样的问题:想查询某张表几个列的信息,有时列名记不清了,如emp表中薪水的列名忘记了,当查询时,可以这么做:
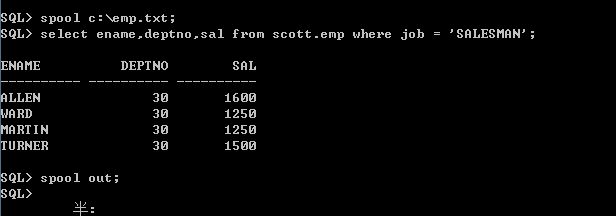
spool命令
它可以把sql语句和查询结果输出到指定文件中,如spool c:\emp.txt,最后要用spool out 或off,将缓冲区中的内容保存到指定的文件中,如下:
c盘目录下将会出现emp.txt文件,文件内容如下:
define命令
它可以定义一个用户变量,并赋给一个char值,如:define vjob = ‘SALESMAN’它其实和java中的定义变量相似,后面会有相应的举例,这里就是不说了。
show 命令
它用于显示sql*plus中环境变量的值或系统变量的值,如查看数据块的大小:
edit
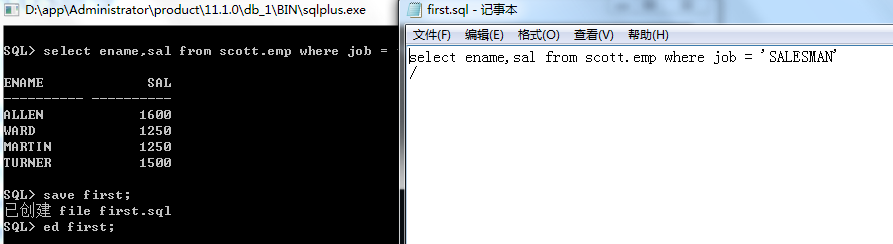
pl*sql块在执行完成后,可以被存储于sql缓冲区的内存中,用户可以重新从缓冲区中调用或编辑那些最输入的sql语句,也可以把sql语句切换到记事本中编辑,并且可以编辑多个sql语句,放入缓冲区中,指定名字,通过名字来调用,如下:
现有两条sql语句:
select ename,sal from scott.emp where job = ‘SALESMAN’
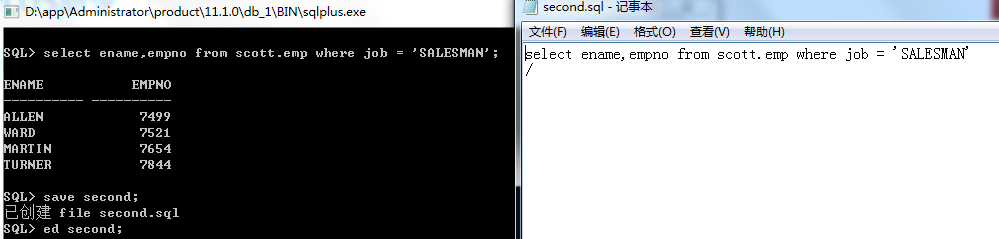
select ename,empno from scott.emp where job = ‘SALESMAN’
保存好后可以通过名字来编辑指定的sql语句
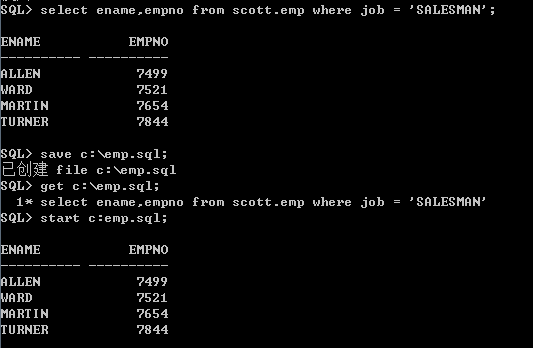
save、get、start 命令
上文中已经用到save 命令。但是上文中只是保存到了缓冲区中,save命令还可以将sql语句及查询结果保存到指定的文件中,如同上文中的spool命令,而get命令相当于对save命令的逆向操作,相当于读取操作,把读取到的内容放到sql缓冲区中,接下来用start命令或@命令来完成执行sql语句的操作


















 533
533

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









