







这里是Ai写论文的链接
https://arxiv.org/pdf/2503.04629
开源地址
这篇论文和我去年写的专利中的思路很像,流程也基本一样。但是细节工作做的更扎实一些。
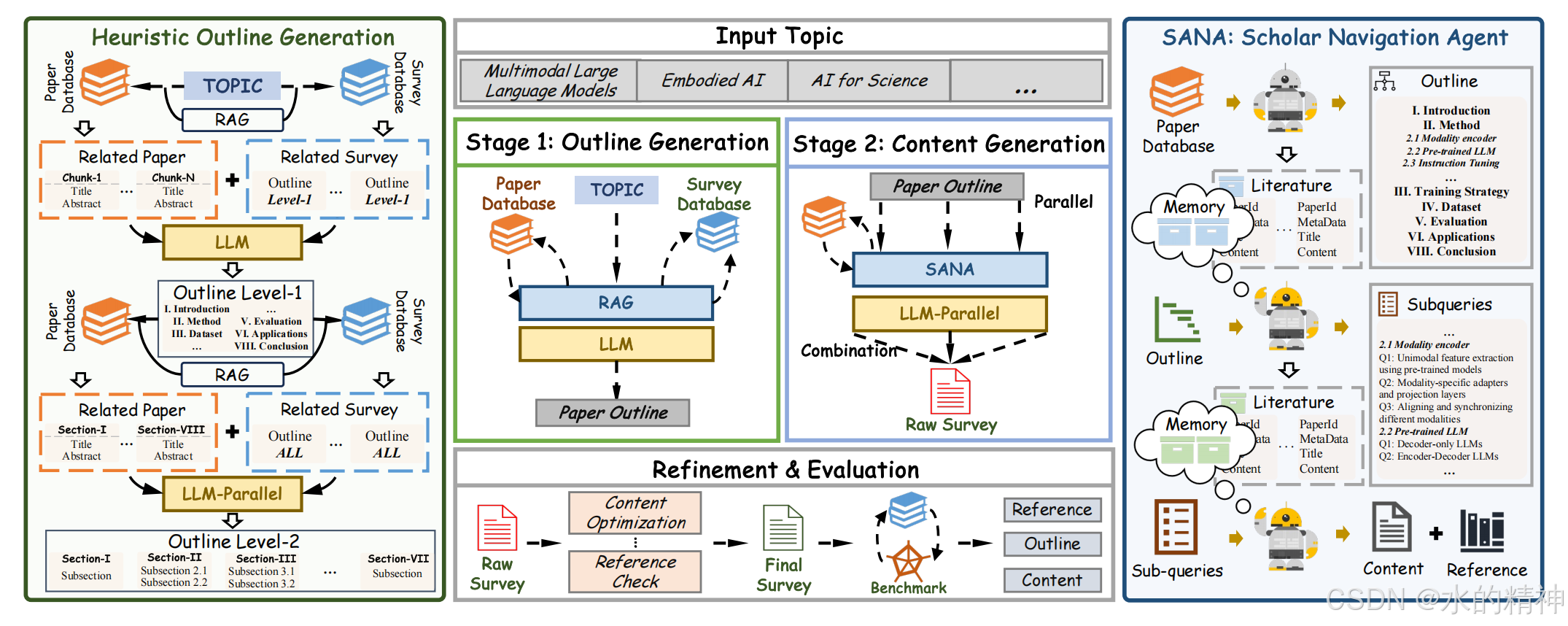
论文中有几个亮点
1. 生成大纲的时候,用到了类似于记忆的机制。人工提前构建好一些大纲,在给定写作topic的时候,利用RAG检索技术,找到相似的大纲,交给模型生成新的大纲。
2. 在写作过程中,利用到了RAG技术,去检索某个章节相关的段落,然后用于参考。
3. 论文中提出了评估写作的效果,这个工作蛮不错的。构建多维度综述评估基准SurveyBench。引入参考文献覆盖率指标(SAM-R)
4. 提出 时域感知重排序引擎(Temporal-aware Reranking Engine, TRE),提到的这个点挺好的,用于解决检索的时候的相关性问题。兼顾语义相关性,引用量,时间这几个因素。来对做论文的top排序。
这是生成survey的伪代码,很好理解

不足(个人观点)
1. 论文中提到的各个章节的写作是并行的,这虽然会给写作加速,但是这样生成的整篇内容会有非常大的割裂感,不连贯。还会出现写重的部分。
2. 感觉上这个写作,并没有全面的研究,没有深度。
surveyBench 测试框架
这是比较吸引我的地方,之前确实没看到过什么对ai生成的论文进行系统评估的方法。
生成质量指标
- SAM-R(参考文献覆盖率):统计论文引文中与主题高度相关的比例,目标值≥80%。
- SAM-O(大纲结构合理性):基于LaTeX章节完整性和逻辑连贯性评分(0-100分),要求涵盖引言、方法、实验、结论等必要部分。
- SAM-C(内容深度):通过LLM评估技术细节(如数学推导、实验参数)的描述深度,分为低/中/高三档。
测试数据集
https://huggingface.co/datasets/U4R/SurveyBench
10个主题,100篇论文
关于评测细节,可以详细看论文中的附录,有每个评测的prompt


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









