







目录
先看整体架构:

四层架构,先明白怎样干活的,干活的流程,然后才能知道要优化哪里。

MySql的优势所在(高内聚,低耦合)

一张表对比两种引擎:
 附加:MyISAM适合读密集的表;InnoDB适合写密集的表。
附加:MyISAM适合读密集的表;InnoDB适合写密集的表。
SQL语句加载顺序
机读的顺序一般和我们写的sql语句的顺序不一致:
手写顺序:

以下是mysql机读的顺序:(这个过程正是由第二层里边的parser来完成的)

总结SQL的加载顺序

JOIN的七种情况
- 内连接

- 左外连接
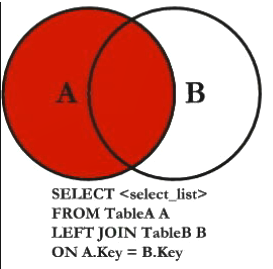
- 右外连接
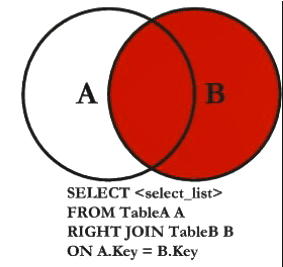
- 取左表独有部分

- 取右表独有部分

- 另外两种,取全部和取各自独有部分,然后求和

索引带来的优化
通俗的来讲,索引就像是字典目录,目录是排好序的从a到z,你在查找的时候可以根据目录快速定位。也就是说提高访问速度。
那么mysql里边的索引就是:排好序的快速查找数据结构。
索引用到的数据结构式BTree(多路搜索树,并不一定是二叉的)
索引的问题:索引会大大的提高查询的速度,但是也会降低插入,更新,删除的速度。
索引的一些概念和用法
单值索引:对一个字段建立索引。create index idx_tablename_字段名 on tablename(字段名)
唯一索引:要求不可以重复出现。create index unique idx_tablename_字段名 on tablename(字段名)
复合索引:对于多条件查询sql,
使用复合索引比较不错,就是对多个字段建立。create index idx_tablename_字段名 on tablename(字段名,字段名)
SQL调优问题诊断
先使用 explain + sql语句,查看可优化的地方。
得到如下:

接着分析这张表的各个字段 ,分析每一个可以优化的点,什么情况是有问题,什么情况没有问题。
- id字段:分三种情况,数字一样,按需执行。数字不一样,数字越大优先级越高。
- select_type: 有以下几种

- table :显示数据是关于哪张表的
- type :索引的访问类型。常见常用的有 system > const >eq_ref >ref >range >index >ALL 最好是能到range ref级别
const:where后边,直接是根据id去查询。

eq_ref :唯一性索引扫描,返回一条数据。
![]()
ref:返回多行
range:范围扫描

index:全索引扫描,从索引中直接取出数据
![]()
就像下边这样。对查询的内容建立索引。

ALL:在磁盘上全表扫描。这是最慢的。
- key:实际上用的索引。如果这个一旦为null,那就是索引失效了,和没建索引一样。
- possible_keys:可能会用到的索引。
- key_len:索引用到的长度。
这个索引长度因为是越短越好,所以我们在定义表结构的时候,就要慎重考虑字段类型 了。
这个和数据库版本有关系,和字段类型有关系,和字段是否允许为空,编码格式有关系。
比方说在定义为char的情况下,允许为空,和不允许为空就差一个字节。最后不允许为空。
在定义为varchar的情况下,不允许为空,就比允许为空多一个字节,因为不允许为空需要补两位。
- ref:
- rows:代表用这个索引,得到想要的结果需要查找的行数。也就是扫描的行数。
- extra: 这个出现 Using filesort 是很危险的,意味着原来有索引但是不用,自己重新建,这是不好的现象。
还会出现 Using temporary 这个是更危险的,使用临时表保存中间结果,常见排序 order by 和分组 group by
查询中排序的字段,排序字段如果通过索引去访问,将大大提高排序速度。order by 的顺序最好和建立的索引的顺序一致。
还会出现的其他的情况

SQL优化——避免索引失效
- 最佳左前缀匹配原则:如果索引了多列,要遵循最左前缀原则,查询从最左前列开始且不跳过索引字段,
比如创建了索引 create index index_id_name_age on student (id, name, age)
那么在查询的时候:select * from student where id= ,name= ,age= ;这是最正确的用法
select * from student where name= ,age= ; 索引会失效
select * from student where id= ,age= ; 索引会失效
- 不在索引列上进行任何操作(计算,函数,或者类型转换)否则导致索引失效。
- 存储引擎不能使用索引中范围条件右边的列
比如创建了索引 create index index_id_age_name on student (id, age , name)
select * from student where id= ,age> , name = 因为第二个是条件,所以后边字段索引会失效
- 尽量使用覆盖索引,也就是在extra那一项出现 Using index,也就是从索引上查询值,不再去扫描数据库表。
比如创建了索引 create index index_id_name_age on student (id, name, age)
那么在查询的时候:select id,name,age from student where id= ,name= ,age= ;这是最好的情况,这就是全覆盖了。
- where条件使用 != ,可能会导致索引失效而扫描全表。
- where条件 使用 is null 或者 is not null 会让索引失效的情况
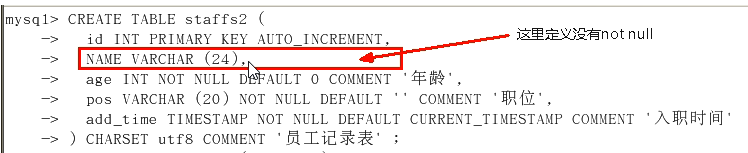
这种情况不会让索引失效。
如果上边定义了 not null,但是条件查询,where name is null ,就肯定会使索引失效。
- 模糊查询 like ‘%’ 百分号挂前边会使索引失效。所以能挂右边挂右边。如果实在是需要前边出现%,那就覆盖索引,建一个特殊的索引,能够使查询覆盖索引。
- 字符串不加单引号,因为数据库底层给你转型,所以会使索引失效。
- or 可能会使索引失效,在数据量小的情况下,就算用or,索引失效影响也不大,但是一旦多了,就要考虑使用 union or 来代替
优化技巧总结:

数据库为什么会慢呢?
所谓的数据库慢,不是IO慢就是CPU慢。写要用到IO,读要用到CPU















 143
143











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









