









背景:
服务和中间件巡检时,数据已经上传到grafana,所以从grafana中取数据是一个不错的选择;部分内容如:中间件mysql数据,从grafana中获取时,取到的内容为加密内容,需要解密(grafana自己研发的一种数据压缩格式,为一种json压缩算法)
现象:
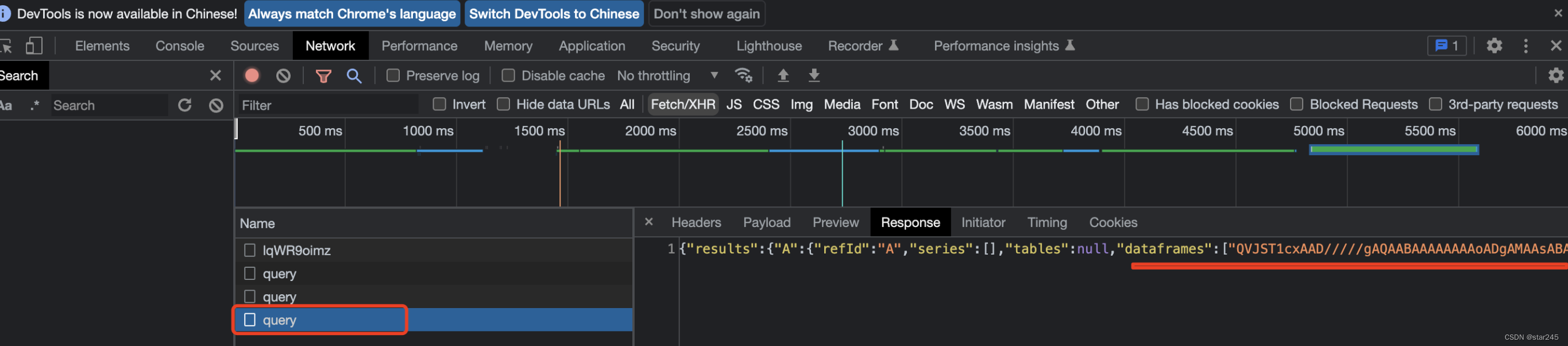
解密方案:使用Base64位decode后再使用 Arrow 解码
代码:
private static List<List<String>> parseChinaQuery(String encodeValue) {
// 解码
byte[] base64decodedBytes = java.util.Base64.getDecoder().decode(encodeValue);
RootAllocator allocator = new RootAllocator(Long.MAX_VALUE);
try (ArrowFileReader reader = new ArrowFileReader(
new ByteArrayReadableSeekableByteChannel(base64decodedBytes), allocator)) {
// read the 4-th batch
if (CollectionUtils.isEmpty(reader.getRecordBlocks())) {
return null;
}
for (ArrowBlock block : reader.getRecordBlocks()) {
reader.loadRecordBatch(block);
VectorSchemaRoot readBatch = reader.getVectorSchemaRoot();
List<FieldVector> fieldVectors =
readBatch.getFieldVectors();
Schema schema = readBatch.getSchema();
List<List<String>> points = new ArrayList<>(fieldVectors.get(0).getValueCount());
for (FieldVector fieldVector : fieldVectors) {
int index = 0;
String fieldName = fieldVector.getField().getName();
int count = fieldVector.getValueCount();
while (index < count) {
List<String> point = null;
if (points.size() <= index) {
point = Arrays.asList(new String[2]);
points.add(index, point);
} else {
point = points.get(index);
}
String value = null;
if (fieldName.equals("Time")) {
value = ((TimeStampNanoVector) fieldVector).get(index) / 1000000 + "";
point.set(1, value);
} else {
value = ((Float8Vector) fieldVector).get(index) + "";
point.set(0, value);
}
index++;
}
}
return points;
}
} catch (Exception e) {
log.error("parse arrow data error", e);
}
return null;
}调用如下:
public static List<CountBean> parseMysqlServerData(List<String> resultDatas) {
List<CountBean> list = new ArrayList<>();
if(!CollectionUtils.isEmpty(resultDatas)) {
for(int i=0;i<resultDatas.size();i++) {
String resultData = resultDatas.get(i);
Map bean = JsonUtils.toBean(resultData, Map.class);
Map resultsMap = (Map) bean.get("results");
Map aMap = (Map) resultsMap.get("A");
List<String > dataframes = (List<String>) aMap.get("dataframes");
List<List<String>> points = parseChinaQuery(dataframes.get(0));
if(!CollectionUtils.isEmpty(points)) {
for(List<String> point:points) {
CountBean cb = new CountBean();
if(point!=null&&point.size()==2&&point.get(0)!=null) {
try {
cb.setCountValue(new BigDecimal(point.get(0)+""));
cb.setCountKey(Long.parseLong(point.get(1)+""));
list.add(cb);
}catch(Exception ex) {
log.error("error:{}",point,ex);
}
}
}
}
}
}
return list;
}maven包:
<dependency>
<groupId>org.apache.arrow</groupId>
<artifactId>arrow-vector</artifactId>
<version>9.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.arrow</groupId>
<artifactId>arrow-memory-unsafe</artifactId>
<version>9.0.0</version>
</dependency>














 2205
2205











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









