






创建/显示/选中/删除数据库

显示
show databases;
创建
create database xxx;
使用
use xxx;
删除
drop database xxx;
创建/显示所有表/显示指定表结构/删除表

在创建是加上if not exists ,在重复创建时避免报错
查表看
show 表;
创表建
create table 表名(
字段1 类型1,
字段2 类型2,
…
);
删除表
drop talbe 表名;
显示指定表的结果
desc 表名;
常用数据类型:
INT:整型
DECIMAL(M, D):浮点数类型
VARCHAR(SIZE):字符串类型
TIMESTAMP:日期类型
给表中增加新内容
–表中每一行对应的内容都要添加
insert into values (新增内容)
– 单行插入(更好)
insert into 表(字段1, …, 字段N) values (value1, …, value N);
– 多行插入
insert into 表(字段1, …, 字段N) values
(value1, …),
(value2, …),
(value3, …);

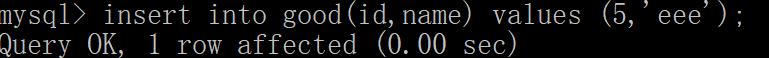
查询
(可以理解为根据原来的表生成一个新表,新标的结果和结构与原来的表机构不一样,新表中记录行数也不一定与原表一一对应)
查看表中的内容

– 全列查询
select * from 表(*是通配符,代替所有列)
这个命令在测试时经常用,在生产时千万不要用,很可能使数据库卡死!!!

– 指定列查询
select 字段1,字段2… from 表

– 查询表达式字段
select 字段1+100,字段2+字段3 from 表(这里相加之后,对应数据的指定长度可能会变化)



– 别名
select 字段1 别名1, 字段2 别名2 from 表(可以再别名前面加一个as);

– 去重DISTINCT(针对某一列)
select distinct 字段 from 表
(也可以指定多列,但是这三列的相等的值必须是在对应位置的)



– 排序ORDER BY
select * from 表 order by 排序字段(这是升序排序,可以在后面加上asc)
1.这个中可以使用列的别名
2.也可以指定多个列来排序,越靠前的优先级越高.
3.NULL字段视为比任何值都小



– 条件查询WHERE:where后面不能使用别名,条件为真的将被筛选出来
按照条件去查询
(1)比较运算符
运算符 说明
, >=, <, <= 大于,大于等于,小于,小于等于
= 等于,NULL 不安全,例如 NULL = NULL 的结果是 NULL
<=> 等于,NULL 安全,例如 NULL <=> NULL 的结果是 TRUE(1)
!=, <> 不等于




(2)BETWEEN … AND … [a1,a2),这个是表示前闭后开的区间(between and 可以和and起相同的作用)


(3)IN(在in这个词的后面有好几个数据,只要表中有一个能和括号里面的对应,就会被筛选出来,这个效果也可以用or表示出来,相互转换)

(4)IS NULL

(5)LIKE (模糊匹配)(实际工作中,效率比较低,不经常出现)
%或者_作为通配符
%表示任意字符出现任意次数
_表示任意字符出现一次
下面第一个表示找到以b开头的人
第二个是找到在字符中间有c的人
像’_c%’ 是找第二个字符是c的人

(6)AND

(7)OR


分页查询(offset 后面的数表示 查询的起始位置,如果没有就表示冲第一行开始)

order by 必须在 where后面

修改(Update)
update [表名] set [要修改的值] where [筛选条件];
修改前

修改后

修改多列
修改前
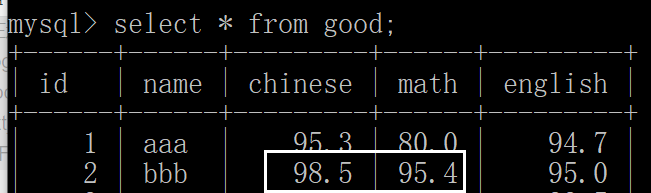
修改后

先排序在修改
修改前

修改后

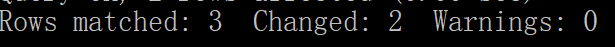
实际匹配了三项,但是只修改了两项,如95加上10之后就超过decimal表示的范围,所以就没有修改
语文除二

删除表中数据(删除要特别注意,删除后无法恢复!!!)
delete from [表名] where [删除条件]
1)删除name为 aaa的数据
2)杀出数学成绩小于95的人

3)删除英语语文成绩之在190到195之间的
删除前

删除后


删除整个表
















 1598
1598











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









