






项目有一个需求,需要对16万缅甸语新闻做词频统计。首先是分词工具的选择和使用,然后是词频统计。
分词:
工具有voyant-tools、myanmar-tokenizer以及我使用的es的icu_analyzer。
结果是voyant-tools基于java,看不懂怎么用,听闻和myanmar-tokenizer一样会把词分得很细。icu_analyzer可以分得粗,音标会消失。经过尝试,原来正确的分词是这样,音标不会消失:
"tokenizer":"icu_tokenizer"
经老师检查,用icu_tokenizer。由于es不能频繁访问,所以考虑直接用icu_tokenizer。pip install 失败。
只能去官网下载包,解压后放在site-packages。
打开控制台。
python setup.py build
python setup.py install
然后发现又要下载pyicu。用whl的方式下载。
whl
pip install xxx.whl
终于可以用了
from icu_tokenizer import Tokenizer
tokenizer = Tokenizer(lang='th')
# text = "မရေရာမှုများကြားက CDM မြန်မာသံတမန"
text="အောင်;တရုတ်"
print(tokenizer.tokenize(text))
th是泰语,其实参数有没有都行。
词频统计:
原本想利用es进行词频统计
{
"size":0,
"aggs":{
"messages" : {
"terms" : {
"size":1000
"field" : "body",
}
}
}
}
然而只能显示前几个,要是太多则报太多分桶的错误。
查询可以对聚合结果分页(分桶)查看。
{
"size":0,
"aggs":{
"messages" : {
"terms" : {
"field" : "body",
},
"aggs": {
"myBucketSort": {
"bucket_sort": {
"from": 0,
"size": 5,
"gap_policy": "SKIP"
}
}
}
}
}
}
size表示一次显示5个桶,from等于pageNum*size。然而对于词频统计似乎在25个之后就没有数据了。没有用。
经过查询好像可以用hadoop的mapreduce做词频统计。算是有新思路。
后续
icu_tokenizer的分词质量很差,而icu_analyzer好像包括几个过程。

它是elasticsearch的插件,不可能频繁访问,所以即使在请求参数里配置也没用。要单独拿出来用于分词,只能用它的源码analysis-icu,源码的jar包管理基于gradle,导包的时候也是会报错,gradle的问题。
即使所有包下载好了,也不懂怎么使用analyzer得到分词结果。测试代码如下
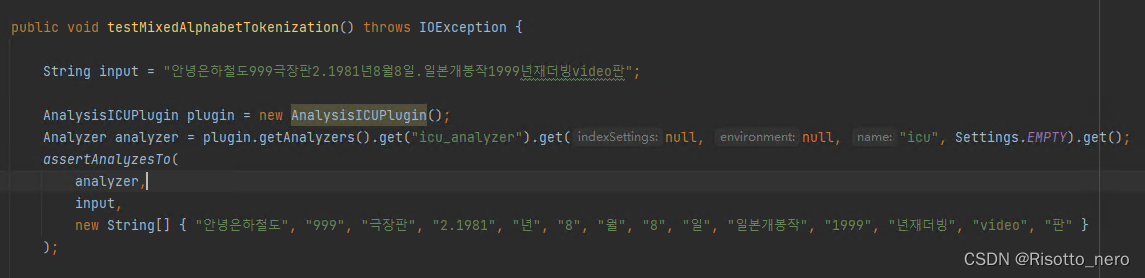
更别说用这个上方的音节会消失,也不知道能不能调参数解决,以及怎么调参数,涉及看es源码那实在得不偿失。这个先放弃。留两篇博客分词1,分词2。
然后尝试voyant-tools。官网首先下载源码,找到这个github,导包的时候发现
<dependency>
<groupId>org.voyant-tools</groupId>
<artifactId>trombone</artifactId>
<version>5.2.0-SNAPSHOT</version>
</dependency>
这个在中央仓库已经没有了,然后又想到之前看到过一个trombone,就拿来用,按指示打包jar包,再手动导入项目中,看到可以用了。
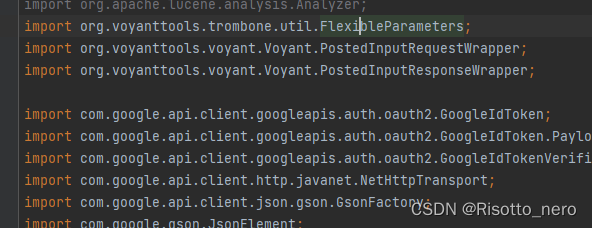
但是jsp文件爆红。
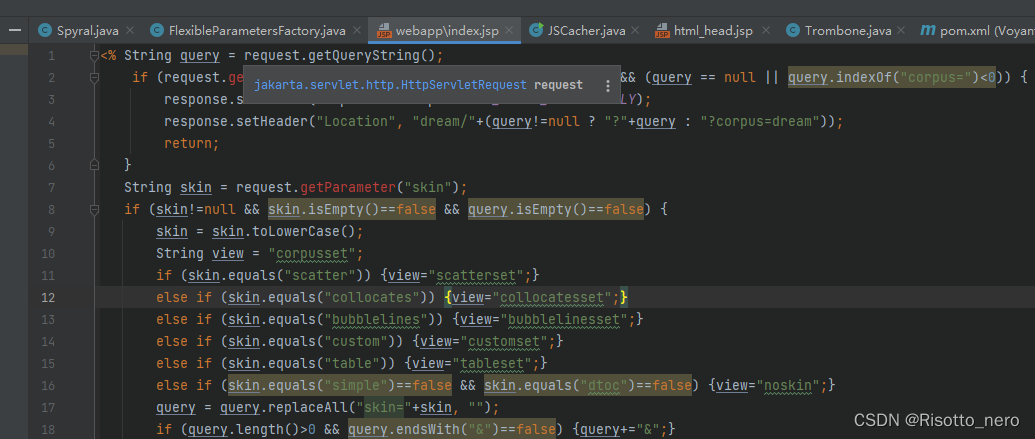
可以看到这个servlet属于jakata包下,而项目里的servlet在javax下。调查发现在tomcat10以后就是这样。但是项目里为什么又是javax呢,先不管。
用tomcat7跑一下,有页面但是500错误,原因是找不到编译的java文件。这个很奇怪。
我只能下载tomcat11来跑,这次找到文件了,但是报错说找不到javax.servlet.xx的类,和我之前想的一样。
我试了很多方法,在pom.xml中导入jakata.servlet相应的jar包,这次jsp没有红,但是启动服务器依然找不到,因为它的项目是基于javax的,jsp文件里却是jakata。我兜兜转转试了很多方法,这个问题依然没有解决。从上午搞到晚上,别说睡午觉了,吃饭也只是吃了两个包。
期间各种问题,像build乱码,tomcat控制台和日志乱码,任务管理器结束任务白屏等等,还有注意maven对应java版本,tomcat对应java版本
后面我想起它之前还有个仓库,是一个旧版本已被归档的仓库,我就想能不能降低版本呢。用这个依然要自己生成和导入trombone,然后要用tomcat8,太高版本是不行的,反而jsp没有爆红了,所用的servlet也是javax的,有点希望,但是启动tomcat已经报错了。大意如此 org.apache.catalina.LifecycleException:无法启动组件[StandardEngine [Catalina]
其实更应该关注后面的错误,它说找不到trombone下有一个Storage类,我看了下没问题,想应该是通用的错误,不关这个包事,解决
晚上七点多,终于能在本地看到这个界面了
本来我早就不想干了,只是一种执念。但是上传文件后报错了,这真是源码的问题了,我不想费时费力动源码。
后面问师兄他一下载就能用了,才知道是voyant server
下载之后解压运行jar文件就可以?界面报错了,无论用java18还是java8都是,非常让我失望。不过我已经尽力了,真要用这个分词的话直接上传到官网让它帮我做就行。
然后老师又说voyant的分词质量也是不行。
我又用了老师们新发的分词器,seanlp。这个就很友善,只是百度云盘太慢了,不仅有六种模式的分词,还有词性标注。也不知道最后选择哪个分词器。
小小缅甸语分词搞那么久,费了那么大劲,前后试了5个分词器,真是没想到,赶快结束吧。也有我的问题,原来icu_analyzer和icu_tokenizer完全不同。
从这篇文章得知python的ployglot包和es的icu原理一样,就尝试了一下。先安装了这个包。在输入缅甸语进行测试时出现错误。解决后又出现错误。要安装三个包,前两个包都在这里下载吧。然后终于可以用了。结果和icu_tokenizer一样,没什么用。
比现阶段分词效果好的只有icu_analyzer了。两个问题待解决。一是上面的符号消失,二是es不能频繁访问。
关于问题一我看了一些可以自定义分词器,其中有filter等等。1、2、3,ascii_folding的过滤很像,然而试了一下 “très” "tres"是可以,但不能解决我问题。我怀疑是icu这个过滤器。
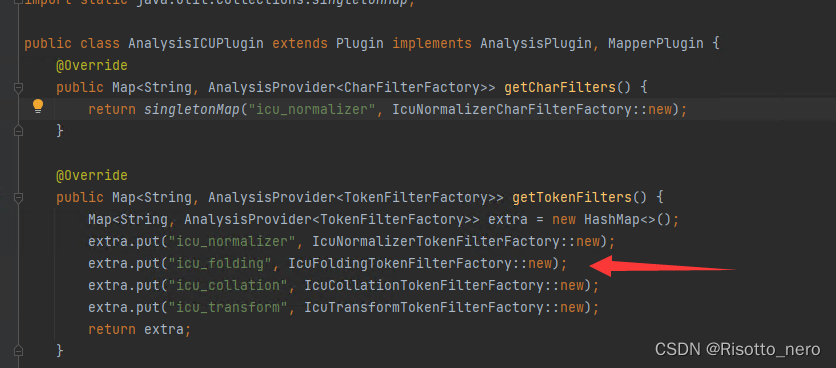
这就要涉及源码了。org.apache.lucene.analysis.Analyzer
如果肯钻研源码的话,应该是可以用icu_analyzer的,可是得不偿失。希望得到指教,感激。
再后续
在eval(分词结果)的时候出现ValueError: source code string cannot contain null bytes,困扰许久,应该是字面意思出现空字符了,最后用replace(“\0”,“”)解决。
然后list类型转字符串的时候分隔是", “这样,所以split(” ")的时候会报错,replace一下就好了














 1862
1862











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









