







1、python中的字符串
(1)创建、访问、更新字符串
字符串是 Python 中最常用的数据类型。我们可以使用引号( ' 或 " )来创建字符串。 创建字符串很简单,只要为变量分配一个值即可。例如:

需要注意,这与C和C++不同的是,Python 不支持单字符类型,单字符在 Python 中也是作为一个字符串使用。 Python 访问子字符串,可以使用方括号来截取字符串,如下实例:
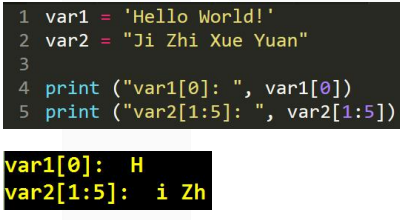
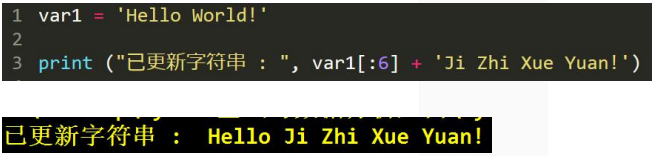
更新字符串:
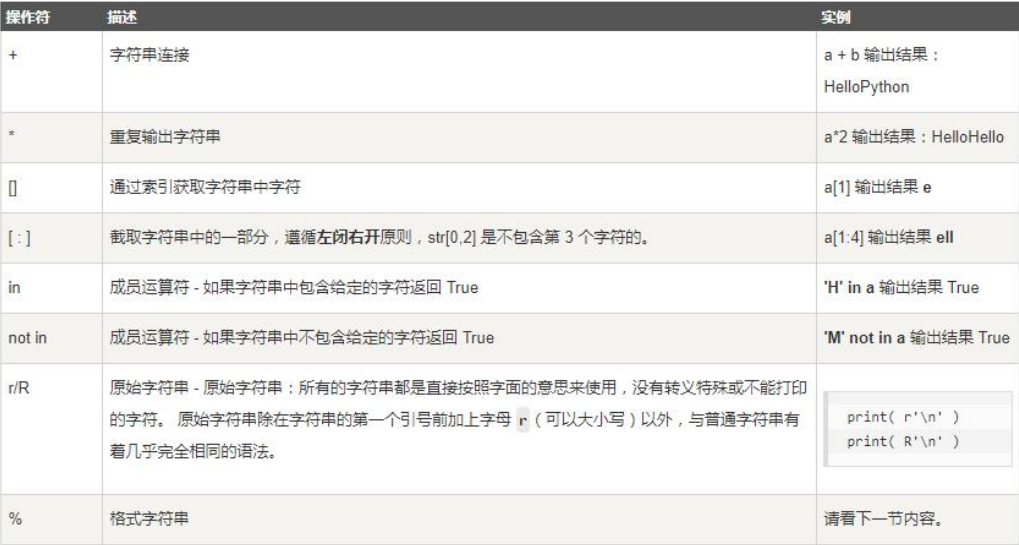
(2)字符串运算符
下表实例变量a值为字符串 "Hello" ,b变量值为 "Python"
代码示例:
a = "Hello"
b = "Python"
print("a + b 输出结果:", a + b)
print("a * 2 输出结果:", a * 2)
print("a[1] 输出结果:", a[1])
print("a[1:4] 输出结果:", a[1:4])
if( "H" in a) :
print("H 在变量 a 中")
else :
print("H 不在变量 a 中")
if( "M" not in a) :
print("M 不在变量 a 中")
else :
print("M 在变量 a 中")
print (r'\n')
print (R'\n')输出结果:
a + b 输出结果: HelloPython a * 2 输出结果: HelloHello a[1] 输出结果: e a[1:4] 输出结果: ell H 在变量 a 中 M 不在变量 a 中 \n \n
(3)格式化字符串
Python 支持格式化字符串的输出 。尽管这样可能会用到非常复杂的表达式,但最基本 的用法是将一个值插入到一个有字符串格式符 %s 的字符串中。 在 Python 中,字符串格式化使用与 C 中 sprintf 函数一样的语法

总结:


(4)三引号
python三引号允许一个字符串跨多行,字符串中可以包含换行符、制表符以及其他特殊 字符。实例如下:
para_str = """这是一个多行字符串的实例
多行字符串可以使用制表符
TAB ( \t )。
也可以使用换行符 [ \n ]。
"""
print (para_str)结果:
这是一个多行字符串的实例 多行字符串可以使用制表符 TAB ( )。 也可以使用换行符 [ ]。
2、python的字符串内建函数
capitalize(): 将字符串的第一个字符转换为大写 center(width, fillchar): 返回一个指定的宽度 width 居中的字符串,fillchar 为填充的字符,默认为空格。 count(str, beg= 0,end=len(string)): 返回 str 在 string 里面出现的次数,如果 beg 或者 end 指定则返回指定范围内 str 出现的次数。 bytes.decode(encoding= "utf-8" , errors= "strict") Python3 中没有 decode 方法,但我们可以使用 bytes 对象的 decode() 方法来解码给定的 bytes 对象, 这个 bytes 对象可以由 str.encode() 来编码返回。
encode(encoding= 'UTF-8' ,errors= 'strict'): 以 encoding 指定的编码格式编码字符串,如果出错默 认报一个ValueError 的异常,除非 errors 指定的是'ignore'或者'replace' endswith(suffix, beg=0, end=len(string)): 检查字符串是否以 obj 结束,如果beg 或者 end 指定则 检查指定的范围内是否以 obj 结束,如果是,返回 True,否则返回 False. expandtabs(tabsize=8): 把字符串 string 中的 tab 符号转为空格,tab 符号默认的空格数是 8 。 find(str, beg=0, end=len(string)): 检测 str 是否包含在字符串中,如果指定范围 beg 和 end ,则检 查是否包含在指定范围内,如果包含返回开始的索引值,否则返回-1 index(str, beg=0, end=len(string)): 跟find()方法一样,只不过如果str不在字符串中会报一个异常
isalnum(): 如果字符串至少有一个字符并且所有字符都是字母或数字返回 True, 否则返回 False isalpha(): 如果字符串至少有一个字符并且所有字符都是字母则返回 True, 否则返回 False isdigit(): 如果字符串只包含数字则返回 True 否则返回 False.. islower(): 如果字符串中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都 是小写,则返回 True,否则返回 False isnumeric(): 如果字符串中只包含数字字符,则返回 True,否则返回 False upper(): 转换字符串中的小写字母为大写 zfill (width): 返回长度为 width 的字符串,原字符串右对齐,前面填充0 isdecimal(): 检查字符串是否只包含十进制字符,如果是返回 true,否则返回 fals
lower(): 转换字符串中所有大写字符为小写. lstrip(): 截掉字符串左边的空格或指定字符。 maketrans(): 创建字符映射的转换表,对于接受两个参数的最简单的调用方式,第一 个参数是字符串,表示需要转换的字符,第二个参数也是字符串表示转换的目标。 max(str): 返回字符串 str 中最大的字母。 min(str): 返回字符串 str 中最小的字母。 replace(old, new [, max]): 把 将字符串中的 str1 替换成 str2,如果 max 指定,则替 换不超过 max 次。 rfind(str, beg=0,end=len(string)): 类似于 find()函数,不过是从右边开始查找
rindex( str, beg=0, end=len(string)): 类似于 index(),不过是从右边开始. rjust(width,[, fillchar]): 返回一个原字符串右对齐,并使用fillchar(默认空格)填充至长 度 width 的新字符串 rstrip(): 删除字符串字符串末尾的空格. split(str= "" , num=string.count(str)) num=string.count(str)) 以 str 为分隔符截取字符串,如果 num 有指定值,则仅截 取 num+1 个子字符串 splitlines([keepends]): 按照行('\r' , '\r\n' , \n')分隔,返回一个包含各行作为元素的列 表,如果参数 keepends 为 False,不包含换行符,如果为 True,则保留换行符。
startswith(substr, beg=0,end=len(string)): 检查字符串是否是以指定子字符串 substr 开头,是则返回 True,否则返回 False。如果beg 和 end 指定值,则在指定范 围内检查。 strip([chars]): 在字符串上执行 lstrip()和 rstrip() swapcase(): 将字符串中大写转换为小写,小写转换为大写 title(): 返回"标题化"的字符串,就是说所有单词都是以大写开始,其余字母均为小写(见 istitle()) translate(table, deletechars= ""): 根据 str 给出的表(包含 256 个字符)转换 string 的字符, 要过滤掉的字符放到 deletechars 参数中
3、实战:统计一个文档中的字符的数量
在本次实战中将运用到python的re模块
代码与运行结果:
.txt文件:

#re模块,实现正则匹配
import re
str_test = open('2019年北京高考满分作文.txt',encoding="UTF-8").read()
#把正则表达式编译成对象,如果经常使用该对象,此种方式可提高一定效率
num_regex = re.compile(r'[0-9]')
zimu_regex = re.compile(r'[a-zA-z]')
hanzi_regex = re.compile(r'[\u4E00-\u9FA5]')
print('输入字符串:',str_test)
#findall获取字符串中所有匹配的字符
num_list = num_regex.findall(str_test)
print('包含的数字:',num_list)
zimu_list = zimu_regex.findall(str_test)
print('包含的字母:',zimu_list)
hanzi_list = hanzi_regex.findall(str_test)
print('包含的汉字:',hanzi_list)
print('包含的数字个数为:',len(num_list))
print('包含的字母个数为:',len(zimu_list))
print('包含的汉字个数为:',len(hanzi_list))程序运行结果:

代码解读:
(1)compile函数
compile 函数用于编译正则表达式,生成一个正则表达式( Pattern )对象,语法格式如下:
re.compile(pattern[, flags])
参数:
-
pattern : 一个字符串形式的正则表达式
-
flags 可选,表示匹配模式,比如忽略大小写,多行模式等,具体参数为:
-
-
re.I 忽略大小写
-
re.L 表示特殊字符集 \w, \W, \b, \B, \s, \S 依赖于当前环境
-
re.M 多行模式
-
re.S 即为' . '并且包括换行符在内的任意字符(' . '不包括换行符)
-
re.U 表示特殊字符集 \w, \W, \b, \B, \d, \D, \s, \S 依赖于 Unicode 字符属性数据库
-
re.X 为了增加可读性,忽略空格和' # '后面的注释
-
(2)findall函数
在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果有多个匹配模式,则返回元组列表,如果没有找到匹配的,则返回空列表。
语法格式为:
re.findall(pattern, string, flags=0) 或 pattern.findall(string[, pos[, endpos]])
参数:
-
pattern 匹配模式。
-
string 待匹配的字符串。
-
pos 可选参数,指定字符串的起始位置,默认为 0。
-
endpos 可选参数,指定字符串的结束位置,默认为字符串的长度。
例子:查找字符串中的所有数字
import re
result1 = re.findall(r'\d+', 'runoob 123 google 456')
pattern = re.compile(r'\d+') # 查找数字
result2 = pattern.findall('runoob 123 google 456')
result3 = pattern.findall('run88oob123google456', 0, 10)
print(result1)
print(result2)
print(result3)
输出结果:
['123', '456'] ['123', '456'] ['88', '12']
三、自动作诗
tangshi.txt

代码与运行结果:(每一次运行结果不一样)
import re
from collections import Counter
dic = []
data = open('tangshi.txt','r') #下载的唐诗三百首
for i in data.readlines(): # 读取每一行
dic.append(i.strip().replace(':','').replace(',','').replace('。','').replace('?','').replace('!','').replace('[','').replace(']','')) #去除一些不用的符号
word = ''.join(dic) # 把文字联合起来
word_str = re.sub(r"(?<=\w)","",word) # 把所有文字分开
word_list = list(word_str)
a = [v for v in word_list if not str(v).isdigit()] #删除数字
c = Counter(a)
s = c.most_common(300) #取了前300个最常见的汉字
tangshi = []
for i in s:
tangshi.append(i[0])
import random
i = random.sample(tangshi,20) #从300个最常见的汉字中拿出20个
print(i[0]+i[1]+i[2]+i[3]+i[4]+','+i[5]+i[6]+i[7]+i[8]+i[9]+'。'+'\n'+i[10]+i[11]+i[12]+i[13]+i[14]+','+i[15]+i[16]+i[17]+i[18]+i[19]+'。') 欲得为溪书,隐复浩望怀。 尘颜过阴青,清还道已散。
















 2846
2846











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











