







数组
1.数组基础概念
1.1为什么要引入数组
首先我们引入一个例子:当我们需要输出5个学生的成绩Score(假设为10,20,30,40,50)时,我们首先想到的是使用sout的方式直接输出对应的五个数据。即
System.out.println(10);
System.out.println(20);
System.out.println(30);
System.out.println(40);
System.out.println(50);
那么首先我们可以发现,Score中的数据类型都是相同的。在只有五个数据的时候我们使用sout的方式可以很快的输出,那么当数据量为成百上千的时候呢?
因此,我们引入了数组。我们可以在数组中存储相同类型的多个数据。
1.2数组的概念
数组:可以看成是相同类型元素的一个集合。在内存中是一段连续的空间。
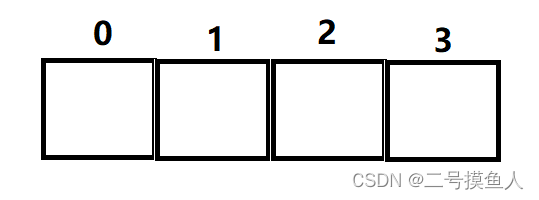
在内存中,由于数组的排列是连续的。因此我将他转化为上图的排列方式。而数组的每个数据都有自己的一个存储空间。为了获取对应空间中的数据,我们就需要进入到对应内存地址,最终获取到这段内存中的数据。
在Java中,底层代码已经为我们解决了这件事情,同时Java为数组中的每个数据进行了以0开始计数的编号,这个编号也是数组的下标。
1.3 数组的创建及初始化
1.3.1数组的创建
数组的基础创建公式为
T[] array = new T[N]; // T:数组中存放的数据类型,array为数组名,N为数据个数(数组长度)。
//举例
int[] array2 = new int[10];//在数组array中存放数据类型为int,数组长度为10
1.3.2 数组的初始化
数组的初始化主要分为静态初始化和动态初始化。
动态初始化:在创建数组的时候直接指定数组中元素个数。
int[] array = new int[10];
静态初始化:在创建数组的时候不直接指定数组数据个数,而直接将数据内容固定。
int[] array1 = new int[]{1,2,3,4};
【注意事项】
1.在静态初始化过程中,{1,2,3,4}表示为数组中的内容,我们在定义的过程中并没有明确表示数组的长度为4。但是不用担心,Java在编译过程中会为我们自己计算数组的元素个数。
2.在静态初始化中,因为直接存入数据的原因,需要注意的是存入的数据类型必须与[]前的数据类型一致。
3.静态初始化可以进行简写:
int[] array1 = {0,1,2,3,4,5,6,7,8,9};
double[] array2 = {1.0, 2.0, 3.0, 4.0, 5.0};
String[] array3 = {"hell", "Java", "!!!"};
虽然在简写过程中省略了new T[],但是在编译器编译代码时还是会还原的。
4.静态和动态初始化可以分为两步,但是不可以省略格式。
int[] array4;
array4 = new int[4];
int[] array5;
array5 = new int[]{1,2,3};
5.如果创建数组的过程中没有对数组进行初始化,数组中的元素存在默认值。
- 如果数组中存在的元素类型为基本元素类型,默认值为基类类型对应的默认值。
| 类型 | 默认值 |
|---|---|
| byte | 0 |
| int | 0 |
| short | 0 |
| long | 0 |
| float | 0.0f |
| double | 0.0 |
| boolean | false |
| char | /u0000 |
在基本类型默认值中,char类型是比较特殊的“0”值,在编译运行后可能打印不出来,为空。
- 当数组类型为引用类型时,默认值为null
String[] str = new String[5];
System.out.println(str[1]);//null

1.4数组的使用
1.4.1 数组的访问
在上文中我们知道,数组在内存中是一段连续的空间,Java通过数字对数组进行编号。空间的编号从0开始并逐渐递增,这个编号称为数组的下标,我们可以通过下标访问数组的任一元素。
int[]array = new int[]{10, 20, 30, 40, 50};
System.out.println(array[0]);
System.out.println(array[1]);
System.out.println(array[2]);
System.out.println(array[3]);
System.out.println(array[4]);
同理,我们也可以通过下标修改对应数据的值。
array[3] = 99;
数组下标从0开始,介于[0,N)之间的而不包含N。//N为元素个数,不能越界,否则会报出数组越界异常。
int[] arr = new int[3];
System.out.println(array[4]);//error

在报错信息中,我们大致可以发现错误原因为ArrayIndexOutOfBoundException,即数组越界,因此在使用数组时一定要注意数组的范围。
1.4.2 数组长度的获取
在Java中,由于数组是**引用类型**,底层代码中已经为我们实现了获取数组长度的方法:array.length 。因此我们可以通过Array.length直接获取到数组的长度。
int[] array1 = new int[]{1,2,3,4};
System.out.println(array1.length);//4
1.4.3 数组数据的存放
在前面我们已经学会了访问数组中的元素,那么我们直接查看数组会出现什么情况呢?
int[] arr = new int[3];
System.out.println(arr);
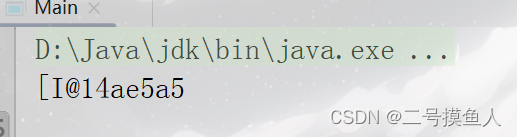
如上图所示,直接输出数组的值是一段不知道什么东西的字符串。
我们姑且可以这么认为:"["代表着这是一个数组;"I"代表着这是一个int类型;而@后面的字符串我们可以认为是数组的地址(以哈希值的形式表现)。
数组arr中存放的就是对象的地址。
1.4.4数组数据的获取(遍历)
1.for循环
通过array.length这个方法我们可以获得数组的长度,也因此我们可以通过循环获取数组中的数据。(直接看下面的代码)
int[] array = {1,2,3,4};
//遍历数组的方式
for (int i = 0; i < array.length; i++) {
System.out.print(array[i] +" ");
}
2.for-each循环
在for循环的基础上Java还创建了一个for-each循环(增强for循环).
这种增强for循环的基本语法格式为for(数据类型 变量名 : 数组)
应用如下列代码所示:
for (int x:array) {
System.out.print(x + " ");
}
for循环和for-each循环都是很好的遍历方式,而在上面的应用中我们可以知道,for循环便于我们对各个下标进行精确获取,而for-each只能适用于全局遍历的方式,因此在遍历过程中我们要注意二者的区别。
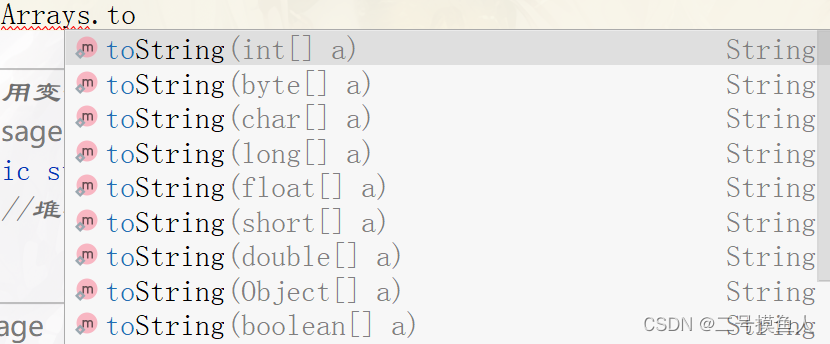
3.Java自带的方式Arrays.toString()
我们直接看下列代码:
//1.第一种写法
String ret = Arrays.toString(array);//将数组转换成字符串
System.out.println(ret);
//2.第二种写法
System.out.println(Arrays.toString(array));
结果:

在上面的代码演示中,我们可以发现toString是一个十分好用的方法,通过联想(见下图)我们可以看到toString方法已经完成重载,适配了各种类型的数组,使用起来简直无脑,而且运行的结果我们可以发现和数组的构造是一样的,这真是太好用辣!!!
1.4.5 自制一个toString()
我们在前文中已经知道了Arrays.toString()方法的便利性,身为智慧的程序猿,我们怎么不能写出一个和他一样的toString()方法呢?那么接下来我们自制一个toString().
首先我们看看Arrays.toString打印出来的是什么样的。
public static void main(String[] args) {
int[] array = {1,2,3,4};
System.out.println("Java自带toString");
System.out.println(Arrays.toString(array));
}
结果是这样的
接下来我们依葫芦画瓢,首先toString方法返回的是字符串,本着字符串“万物皆可拼”的想法,我们设置一个MytoString方法,形参为数组,返回值为String.即
public static String MytoString(int[] array){}
思路如下:
1.在官方的输出中是以[数据1,数据2……]的形式打印的,因此首先设定字符串ret=“[”;
2.为了获取每个数据,我们可以使用for循环遍历数组并打印;
3.在每个数据后面都加上了", “直到最后一个元素,因此我们可以得出:当 i != array.length - 1时,获取数组元素后就可以加上”,“;
4.在遍历完数组后,我们用ret拼接上”]"即可
那么说做就做,我们看看下列代码:
public static String myToString(int[] array){
String ret = "[";
for (int i = 0; i < array.length; i++) {
ret += array[i];
if (i != array.length -1){
ret += ", ";
}
}
ret += "]";
return ret;
}
public static void main(String[] args) {
int[] array = {1,2,3,4};
System.out.println("Java自带toString");
System.out.println(Arrays.toString(array));
System.out.println("MytoString");
System.out.println(MytoString(array));
}
结果如下图所示:

在经历过上面的代码以及运行结果我们可以看出来,似乎没有问题了
我们再验证其他情况下的数据,请看:
public static void main(String[] args) {
// int[] array = {1,2,3,4};
int[] array = null;
System.out.println("Java自带toString");
System.out.println(Arrays.toString(array));
System.out.println("MytoString");
System.out.println(MytoString(array));
}

请看好了,当array = null (即没有引用时),Java自带的toString方法返回值为null,而MytoString方法则报错为空指针异常,原因是在MytoString方法中默认是数组不为空的情况,当数组为空时,MytoString方法找不到堆中的数组空间,因此无法获取数据,最终导致空指针异常报错。
接下来我们讨论当array = null并进行代码的改进。
public static String MytoString(int[] array){
if (array == null){
return null;
}
String ret = "[";
for (int i = 0; i < array.length; i++) {
ret += array[i];
if (i != array.length -1){
ret += ", ";
}
}
ret += "]";
return ret;
}
重新运行后,代码正常运行,我们算是做出来了一个属于自己的MytoString()方法。大成功大成功!!!
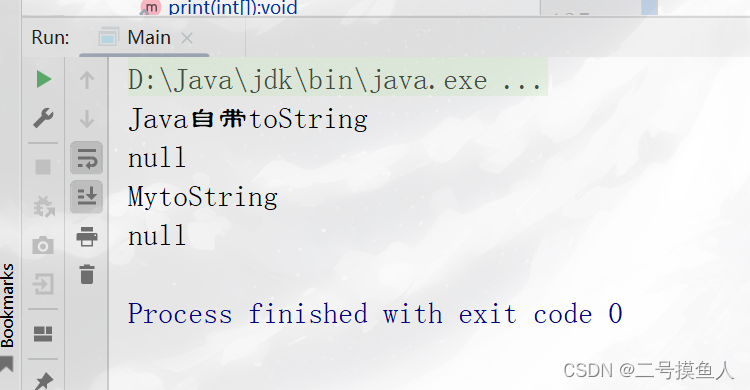
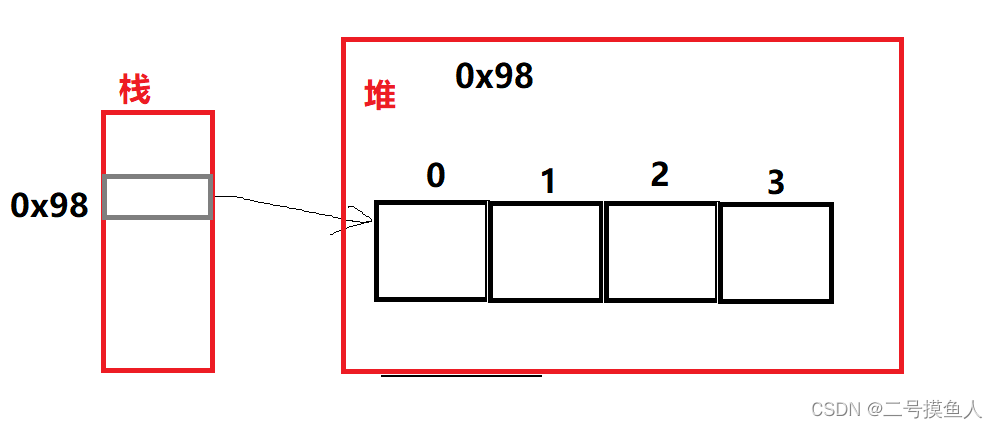
1.4.6 什么是引用类型?
Java当中的数组在栈中被使用,而数组指向堆中的数据才是真实的数据。数组只是引用了这些数据,因此,我们称数组为引用类型。当数组指向对应的数据时,我们称为”引用指向对象“。如下图所示,我们假设0x99是堆中的数据,数组array在栈中存放着这些数据的地址,通过调用指向堆中各自对应的数据,这就是”引用“。
那么有没有可能存在数组不指向对象呢?
int[] arr2 = null;
System.out.println(array[0]);

在上面的代码中,arr2并不存在引用的情况,arr2这个引用不指向任何一个对象,只对数组进行了初始化。在运行了array[0]之后,则数组出现空指针异常报错,这也从侧面证明了数组是引用类型。
1.4.7 数组的初始化
int[] arr2 = new int[10];
int[] arr3;
System.out.println(arr3);
上面的代码中,arr2是我们已经熟练使用的定义方法,在new int[10] 之后,在堆中将会开辟一个长度为10,元素值为0的数组空间。
如果像arr3这样的写法定义数组,既没有设置null表示数组指向为空,又没有存放数组地址,这样的写法是否能过关呢?

我们知道,如果直接打印arr3的话,理论上会出现一串我们难以理解的数值(类似哈希值,见1.4.2图示),这串数值里面存放着数组引用的数值。而在我们运行arr3的时候,编译器提示我们未初始化变量arr3.因此我们结合之前所学过的知识点可以得出原因:在main方法中,变量arr3属于局部变量,一定是需要初始化的。
2.Java虚拟机运行时的数据区
我们在使用Java语言的时候,都会配置jdk和jre,而当我们编译运行的时候需要将程序数据进行存储。如果内存中的数据随意划分,不加以管理,将会对我们日后的程序引起很大的麻烦。
因此,Java设置了jvm虚拟机用以存储数据,同时jvm也对所使用的内存按照功能进行了不同区域的划分。(如图)
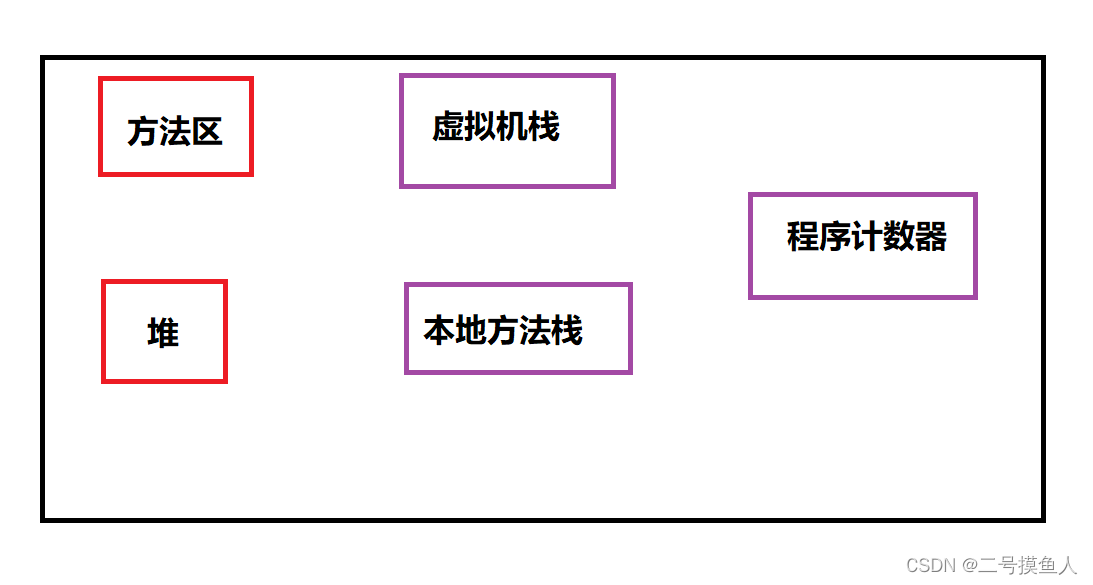
- 程序计数器 (PC Register): 只是一个很小的空间, 保存下一条执行的指令的地址。
- 虚拟机栈(JVM Stack): 与方法调用相关的一些信息,每个方法在执行时,都会先创建一个栈帧,栈帧中包含有:局部变量表、操作数栈、动态链接、返回地址以及其他的一些信息,保存的都是与方法执行时相关的一些信息。比如:局部变量。当方法运行结束后,栈帧就被销毁了,即栈帧中保存的数据也被销毁了。
- 本地方法栈(Native Method Stack): 本地方法栈与虚拟机栈的作用类似. 只不过保存的内容是Native方法的局部变量. 在有些版本的 JVM 实现中(例如HotSpot), 本地方法栈和虚拟机栈是一起的。
- 堆(Heap): JVM所管理的最大内存区域. 使用 new 创建的对象都是在堆上保存 (例如前面的 new int[]{1, 2,3} ),堆是随着程序开始运行时而创建,随着程序的退出而销毁,堆中的数据只要还有在使用,就不会被销毁。
- 方法区(Method Area): 用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据. 方法编译出的的字节码就是保存在这个区域。
2.1 数组在jvm的形态
老规矩,直接上代码
public static void main(String[] args) {
//堆栈概念
int[] arr1 = new int[]{1,2,3};
int[] arr2 = new int[5];
arr2[0] = 100;
arr2[1] = 200;
arr2[2] = 300;
arr1 = arr2;
arr1[3] = 40;
arr1[4] = 500;
System.out.println(Arrays.toString(arr1));
}
为了方便大家理解,我画了一个好图
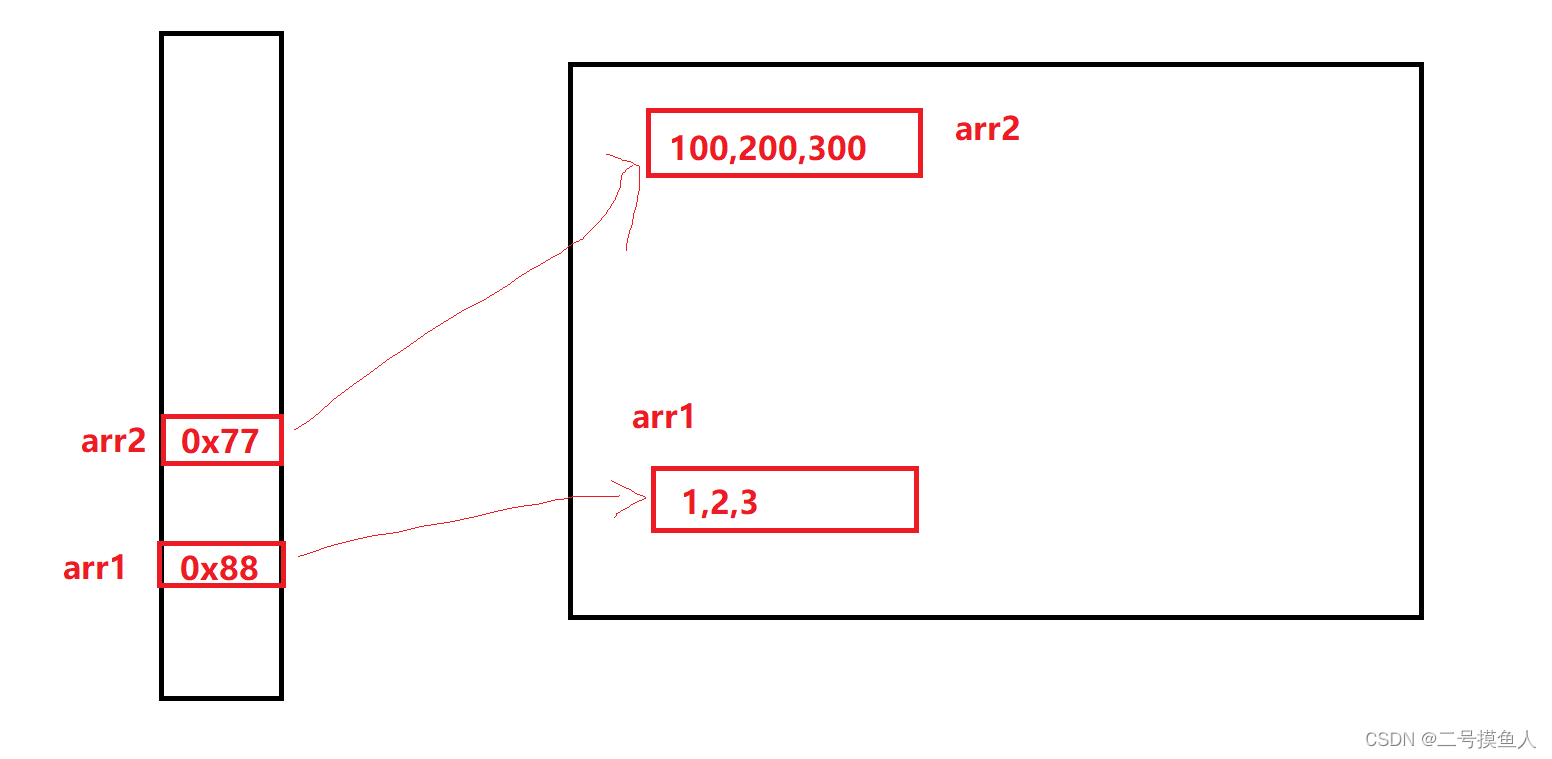
在这个图中,一开始对arr1和arr2进行初始化后,在栈中存放了各自对应数据的地址。堆中两个数组都有被引用到,因此jvm无法回收。
在之后,出现了一段代码:arr1 = arr2,很明显,这是将arr2的地址赋值给了arr1,用人话解释就是arr1指向堆中的数据已经不再是[1,2,3]了,而是和arr2一样的元素集合。
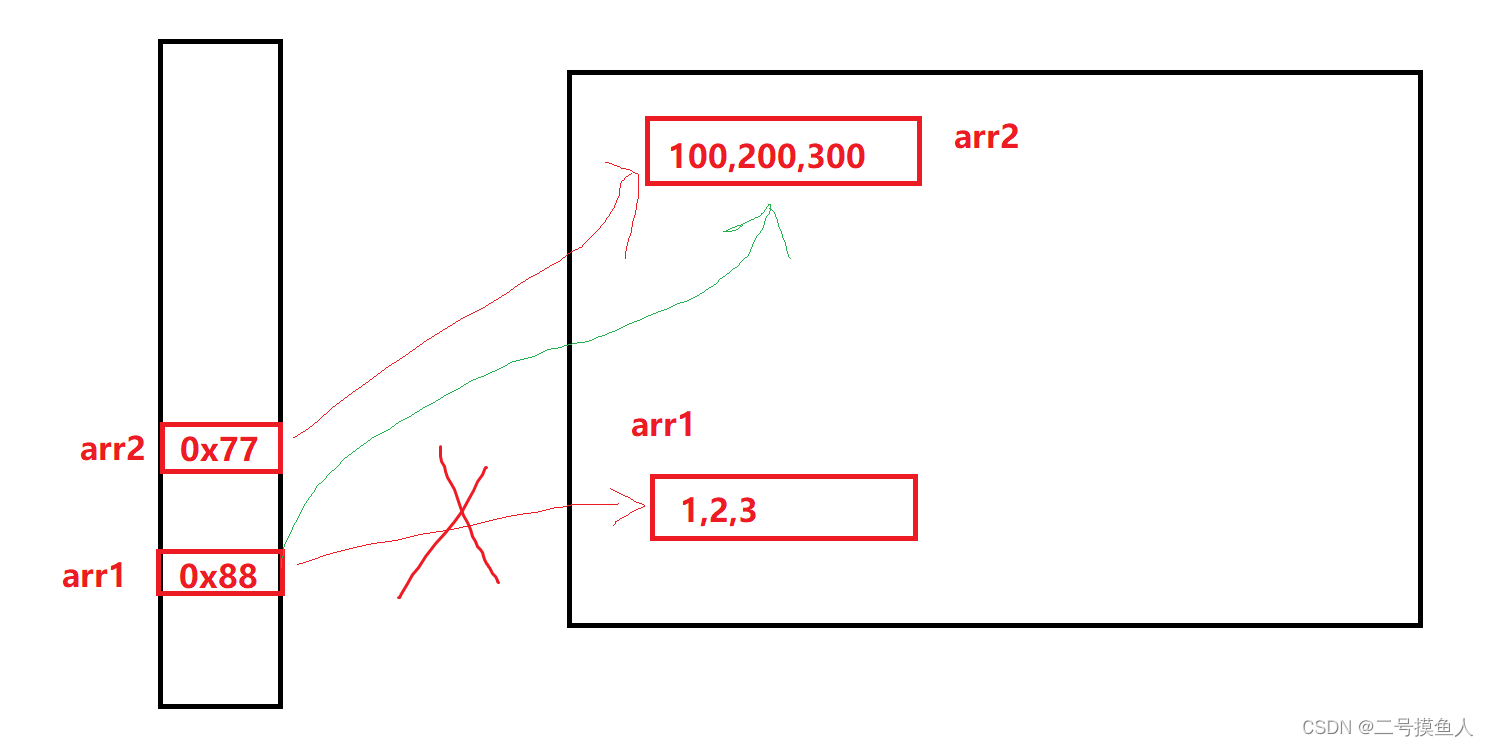
那么这时候,有意思的就来了,后面的arr1[3]和arr1[4]的值是到哪个地方去了?显而易见是arr2的数据空间了,否则arr1的数组长度为3,超过长度则编译器报错。
最后我们润一下代码。

在编译完成后,由于堆中的arr1没有人引用,arr1这个引用指向arr2这个引用所指向的对象,因此堆中的arr1将会被jvm回收。因此,最终无论是arr1打印数组还是arr2打印数组,最终值都是相同的。
3.数组的应用场景
3.1 数组的保存(见1.4.3)
3.2 数组作为参数传递
数组作为一个引用类型的数据类型,也是可以作为形参实参进行传递的。那么在这种地方,数组的行为会有什么变化?
3.2.1 数组作为形参传递
public static void print(int[] arr){
for (int x :
arr) {
System.out.print(x + " ");
}
System.out.println();
}
public static void main(String[] args) {
int[] array = {1,2,3,4};
print(array);
}
在上面的代码中,arr是print方法中的形参,在main方法中,向print方法传递数组array。编译过程中,jvm为print方法开辟一个栈帧,在其中存入arr内存地址。既然将array作为参数传递过去,也意味着array的“地址”赋值给了arr(arr = array)(如图示)
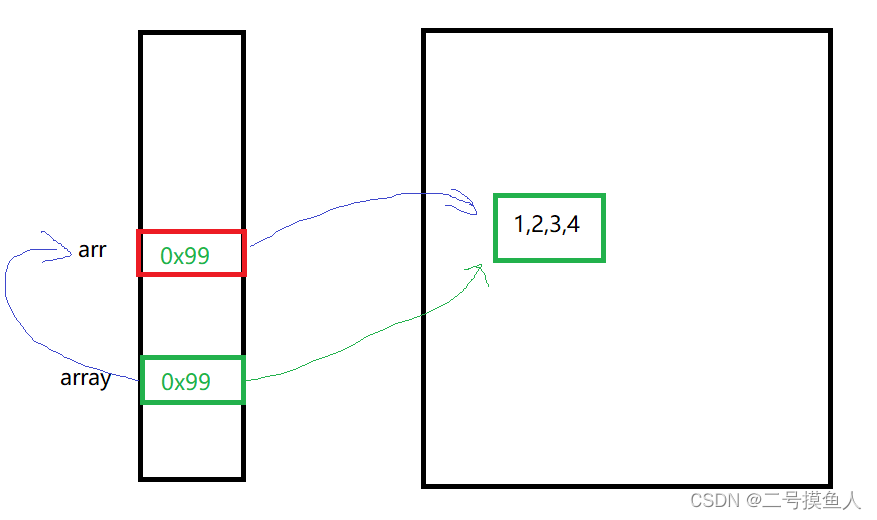
因此在代码块中我们通过for-each循环获取的数值就是数组array中的元素啦。
虽然但是,不是传了引用就一定能修改实参的值,
public static void func1(int[] array){
array = new int[]{11,22,33,44};
}
public static void func2(int[] array){
array[0] = 11;
}
public static void main6(String[] args) {
int[] array = {1,2,3,4};
func1(array);
//func2(array)
System.out.println(Arrays.toString(array));
}
在运行了上面的代码后,我先后运行func1()和func2(),让我们看看二者有何区别:


这就奇怪了 从上面我们知道数组是引用类型,并且通过画图我们也能够大致明白数组在栈和堆中的运行过程。为什么func1()运行后array值不变呢?func2()又为什么可以成功修改array的值。让我再画图试试:
在func1()中,我们传入main方法中的数组array,按道理来说这时候的形参array应该是相等于实参array 的。
我们发现func1的代码中多了一个 “new int[]”,我们也可以从中看出端倪,在func1()方法中,原本传入的是实参array的地址,但是在这时候new了一个新的数组,于是func1在堆中又开辟了一个新的空间,用来存放这组数据,同时引用了这组数据。
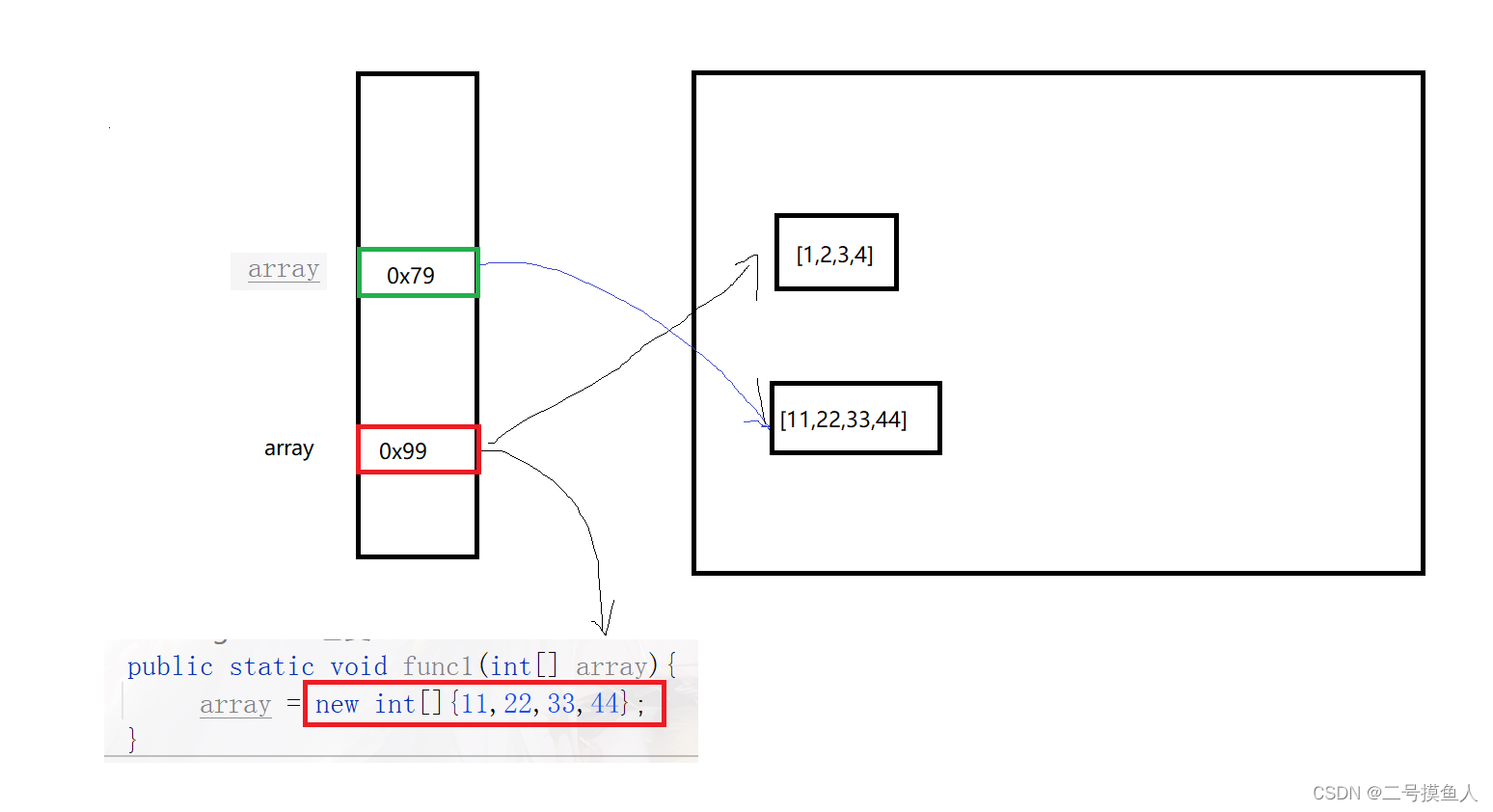
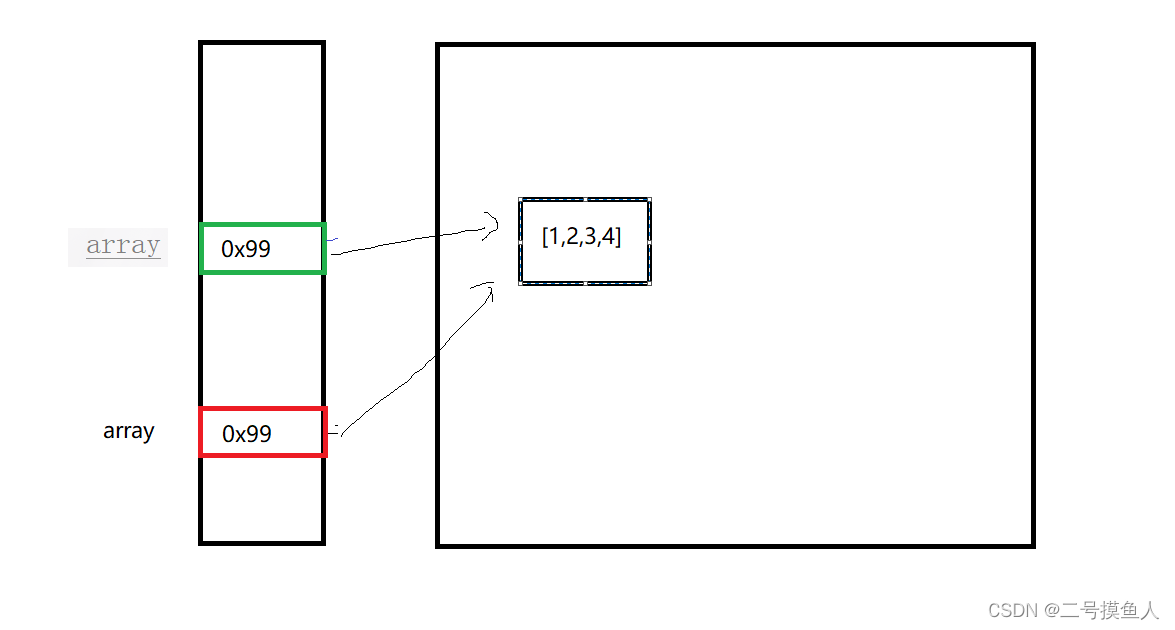
在func2中,并没有设置new int[] 在堆中重新开辟一个新的空间,因此func2能够成功的修改实参中array的值。
3.3基本类型和引用类型在形参中的区别
通过以上的例子,我们已经理解了引用类型在堆栈中的情况,那么举一反三,基本数据类型能不能通过形参在方法中修改呢?
public static void func9(int n ){
n = 100;
}
public static void main(String[] args) {
int n = 11;
func9(n);
System.out.println(n);
}
在运行这段代码之后,我们发现输出值n=11,值不变。
因此,和引用数据类型不同,基本数据类型如int,double……是不能通过形参改变数值的!!!。
基本数据类型在定义后已经在栈中开辟栈帧,但是并没有在堆中重新开辟一段新的空间,所以不能像数组那样通过形参修改数值。
结尾
数组是在学习Java中最先学到的引用数据类型之一,是十分常见的一种数据结构。
源码需求可以到——>数组基础获取源码
感谢观看!!!















 979
979











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









