






 文章讲述了作者在处理单变量表达式时,从1.0版本的初步设计到2.0版本的优化,涉及括号展开、自定义函数处理、内存优化、架构重构和复杂度分析。作者强调了模块化设计的重要性以及在后续迭代中如何提高可扩展性和性能,同时分享了Bug的发现与修复策略。
文章讲述了作者在处理单变量表达式时,从1.0版本的初步设计到2.0版本的优化,涉及括号展开、自定义函数处理、内存优化、架构重构和复杂度分析。作者强调了模块化设计的重要性以及在后续迭代中如何提高可扩展性和性能,同时分享了Bug的发现与修复策略。
BUAA OO Unit1 总结
问题描述
将一个含有加、减、乘、乘方以及括号的单变量表达式展开括号,化为更加简洁的表达式,保证正确性的同时尽可能缩短表达式
-
第一次作业保证括号至多一层,不会出现括号嵌套(其实对采用递归下降法的同学影响不大)
但仍然是开学王炸
-
第二次迭代允许多层括号嵌套,新增指数函数、自定义函数
-
第三次迭代新增求导算子,允许自定义函数中出现已定义函数
度量分析 & 架构设计
由于在第二次作业强测内存爆了(后面将具体分析),所以进行了重构并完成了第三次作业,因此整体架构大致分为两种,将分别对两种架构进行度量和设计分析
1.0版本
UML

- Parser与Lexer类不做过多叙述,值得一提的是对于自定义函数的处理,我没有将其当做单独的因子,而是在字符串层面将其进行替换,这种字符串层面的处理方法直接带来的好处就是在允许自定义函数中出现已定义函数后没有带来额外的工作量
- 在读入字符串后会先解决掉空格
input = input.replaceAll("\\s*","");
-
基本处理思路是将表达式完整解析读入后进行两次化简,第一次化简去除所有括号,将所有幂函数展开,使得所有因子以
*相连,形如:1*x*x*x+3*x*x+3*x*x*x*x*x*exp(x*x*x+2*x*x) -
第二次化简将所有
Term转化为SimpleTerm,即a*x^b*exp(c)的形式,将每个Term中的所有因子进行遍历,得到最简形式,然后加到表达式当中 -
利用
hashmap作为Expr中SimpleTerm的容器,以字符串作为key,以变量的次数a和指数函数的内容c组成a(c)形式的String -
重写
toString()方法保证相同的表达式不会因为项的顺序问题而出现合并失败的问题,将所有key取出进行sort(),之后再依次调用toString(),保证了相同表达式转化为相同顺序的字符串
Object[] keys = terms.keySet().toArray();
Arrays.sort(keys);
StringBuilder sb = new StringBuilder();
for (Object key1 : keys) {
....
}
复杂度分析
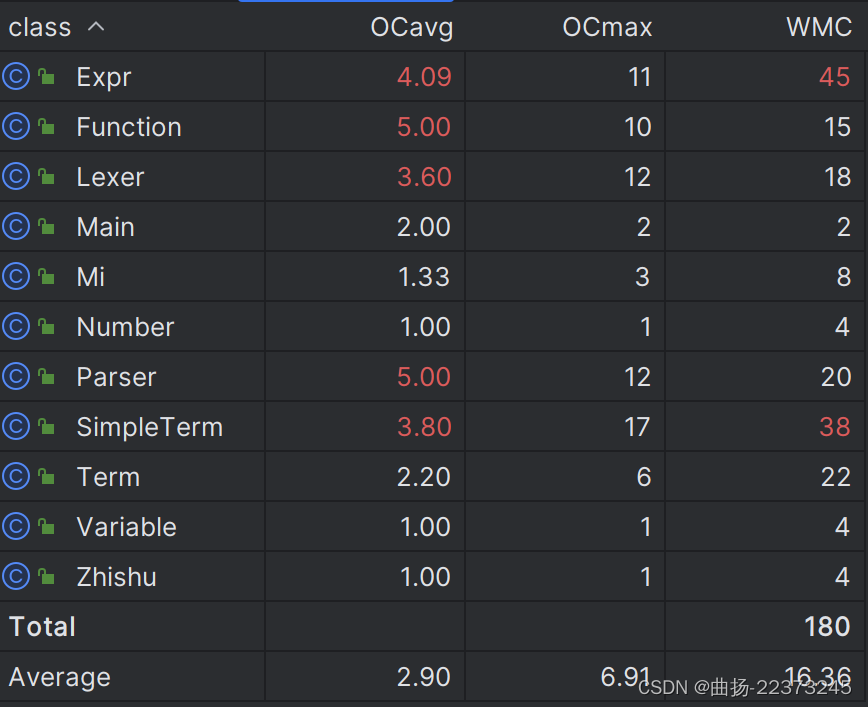
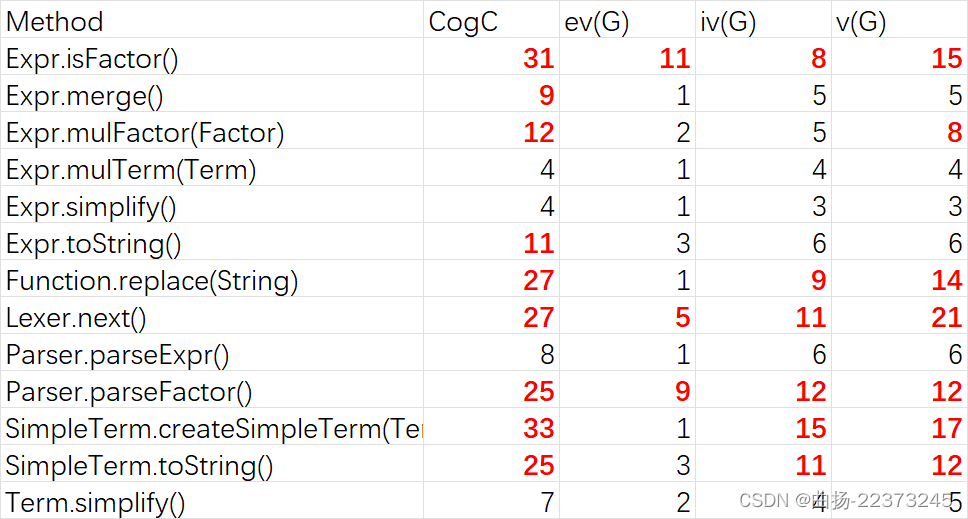
选取了部分复杂度超标的方法
- 可以看出这个架构整体设计的问题较多,耦合度过高,没有较好的实现模块化的设计,可扩展性也较低
- 在方法的复杂度上,由于采用了较多对于
Factor类型的判断导致复杂度较高 - 并且由于化简方法的设计不够简洁,多次进行不必要的遍历和深克隆,之后的
MLE问题其实是可以预料到的
2.0版本
UML

- 相较于1.0版本,最大的改动便是去除了
Term类,转为将乘法和加法在SimpleTerm的层面实现 - 在实现方法上进行极大程度的优化,在文法分析遍历时直接将表达式化为最简,仅需一次遍历就可以实现目的
- 在
parseFactor()后直接将因子乘入SimpleTerm中,每个parseTerm()返回的都是最简形式的Term,直接将其加入表达式的hashmap中即可 - 对于
hashmap中key的处理方式仍采用1.0版本中字符串的方法
复杂度分析
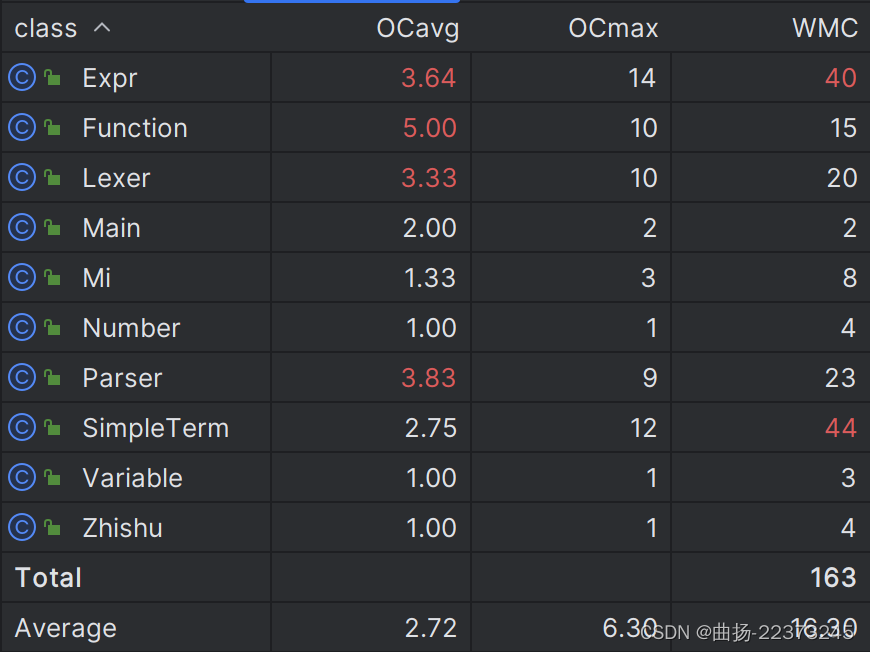
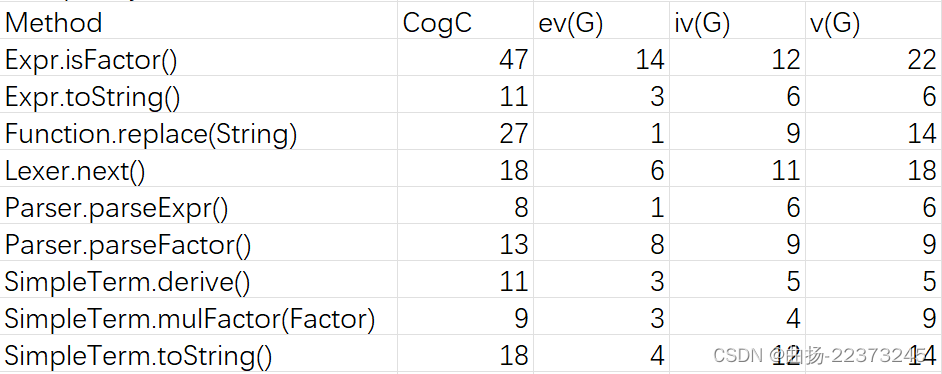
- 各个复杂度相较于1.0都有了较为明显的提升
- 但是由于架构设计问题,模块之间的耦合度整体还是比较高,在之后的作业中应当注意采用扩展性和更容易维护的架构
可扩展性思考
如果之后继续进行添加,则需要增加更多的Factor类,并且修改SimpleTerm的形式,相应的修改Expr的表达,例如:如果加入三角函数,因为三角函数之间的乘法较难化简,初步考虑在SimpleTerm中加入三角集合,单独进行处理
Bug分析
- 第一次互测中被hack的Bug
- 问题数据:
256*256*256*256 - 出现问题:在
Expr转String时对单项式的系数特判是否为0,采用如下方法
- 问题数据:
if(term.getXi().intValue() == 0)
这样乍看没有问题,但其实intValue()方法在遇到超过int范围的BigInterger会返回0,这就导致了许多项会不被输出,于是修改为
if(term.getXi().signum() == 0)
- 第二次强测爆栈的问题
- 问题数据:
(((((((((((x^8)^8)^8)^8)^8)^8)^8)^8)^8)^8)^8)^8 - 出现问题:由于1.0版本采用的方法是将所有的幂函数展开以
*连接因子,所以该数据直接MLE了 - 解决方法: 重构,2.0版本将所用内存从1个多G优化为27MB
- 问题数据:
可以发现,出现Bug的方法圈复杂度均较高,在设计架构时应当将各个模块设计的更为独立,降低模块间的耦合度,并将各个方法设计的更为简洁
hack策略
- 黑盒攻击,盲刀(基本用来凑base分)
自己捏造较强的数据,特殊的数据(通常涉及特判0,BigInterger等),自己曾产生bug的数据 - 利用自动评测机,以数量弥补质量
采用数据随机生成,利用
level机制控制expr随机生成Term的上限,在Expr内的Expr因子``level会下降一到两级,从而控制嵌套层数不会太多
除了多人多拍模式之外,利用sympy库和eval()函数直接对展开的表达式进行正确性检验
优化分析
- 尽量去除表达式开头符号,将符号为正的
Term调整到表达式开头,减少一个字符的长度
遍历Expr中所有Term,若为正则添加到字符串开头,若为负则添加到字符串尾部 - 判断
exp指数函数内容是否为单独的因子,如果是的话可以省去一层括号 - 判断
exp内容是否为a*x^b或a*exp(c)的形式,如果是的话,可以提出常数,使内部为一个单独的因子,从而进行第二步的化简
心得体会
经历了刚开学第一天的崩溃忙碌,之后的优化迭代逐渐进入了正轨,但第二次强测结束后的重构还是给我敲响了警钟,也通过数据然我感觉到了不同架构设计之间效率的差距,在接下来的单元和以后的设计中,一定要在开始前做更为充分的思考,在可扩展性和性能方面做出更大的提升
最后祝大家新学期快乐~享受oo享受生活
















 379
379











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









