









快速排序
顾名思义,快速排序是时间复杂度比较快的一种排序。
1. 快速排序
快速排序的算法思想是:通过一趟排序将待排序的数组分割成两部分,其中一部分的关键字均比另一部分的关键字小,然后继续对这两部分继续排序,最后整个序列就是有序的了。很明显,快速排序的思想的一种递归的思想。
首先要选择一个关键字作为枢轴值,然后想办法使得将它放到一个位置,使得左边的值小于枢轴值,右边的值大于枢轴值。
其中最重要的就是这个合适的位置怎么找?
可以使用一个low和high分别指向要排序的这一段的第一个关键字和最后一个关键字,然后从high向前和枢轴值比较,如果枢轴值大,high向前移动,知道出现枢轴值大于high所指向的关键字,然后将high和low所指向的关键字交换,然后又从low开始向后比较枢轴值和如果枢轴值比low指向的关键字大时,交换high和low所指向的关键字。重复上述过程直到low >= high。
假设现在要排序的数组为{45, 64, 13, 25, 48, 78, 32, 11},选择枢轴值为第一个关键字45,如下图,然后从high开始比较,11小于45,所以将high和low所指向的关键字交换;然后接下来从low开始,11小于45,当然low的加1,然后64大于45,所以将low和high所指向的关键字交换……
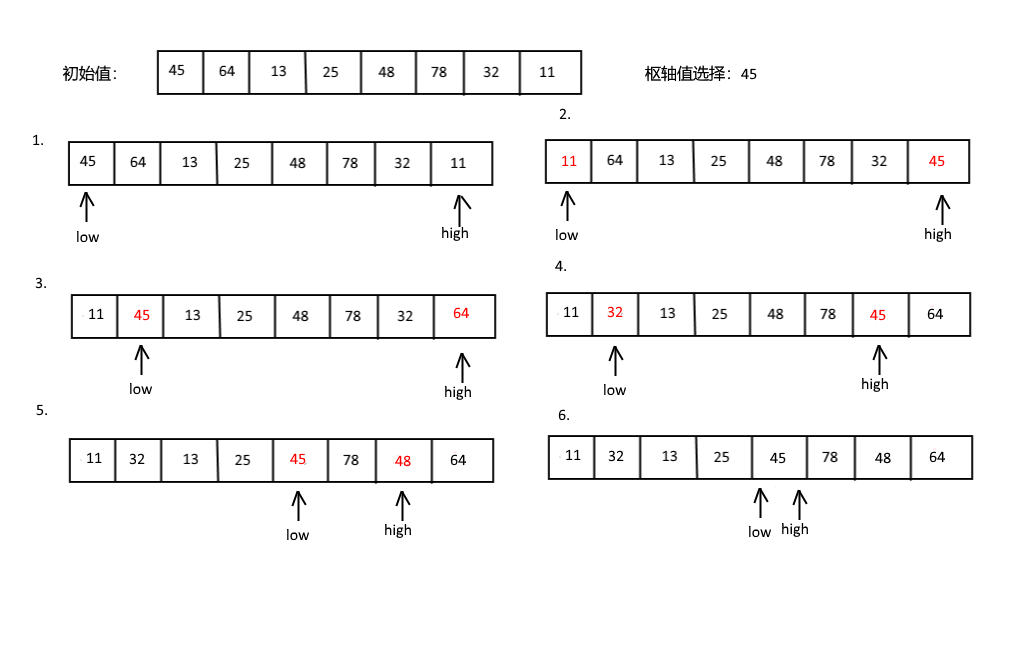
上述的这个过程的实现如下:
while (low < high) {
while (low < high && a[high] >= pivotKey)
high--;
temp = a[low];
a[low] = a[high];
a[high] = temp;
while (low < high && a[low] <= pivotKey)
low++;
temp = a[low];
a[low] = a[high];
a[high] = temp;
}
快速排序的代码如下:
// 交换函数
void swap(int *a, int *b) {
int temp = *a;
*a = *b;
*b = temp;
}
// 因为是递归实现的所以会有下面的这个函数
void QuickSort(int a[], int n) {
QSort(a, 0, n - 1);
}
// 下面的这个函数是递归进行对数组进行分割排序
void QSort(int a[], int low, int high) {
int pivot;
if (low < high) {
// 将a数组一分为二,并算出枢轴值pivot
pivot = Partition(a, low, high);
// 对低于枢轴值的表排序
QSort(a, low, pivot - 1);
// 对高于枢轴值的表排序
QSort(a, pivot + 1, high);
}
}
// 下面这个函数的作用是定位枢轴值
int Partition(int a[], int low, int high) {
int pivotKey;
pivotKey = a[low];
// 核心
while (low < high) {
while (low < high && a[high] >= pivotKey)
high--;
swap(&a[low], &a[high]);
while (low < high && a[low] <= pivotKey)
low++;
swap(&a[low], &a[high]);
}
return low;
}
void QSort(int a[], int low, int high) {
int pivot;
if (low < high) {
// 将a数组一分为二,并算出枢轴值pivot
pivot = Partition(a, low, high);
// 对低于枢轴值的表排序
QSort(a, low, pivot - 1);
// 对高于枢轴值的表排序
QSort(a, pivot + 1, high);
}
}
2. 快速排序的时间复杂度
快速排序的时间复杂度的计算很复杂,总的来说它的时间复杂度为O(nlogn)。
3. 排序算法的优化
上面的只是最基本的快速排序,当然它也可以优化。
3.1 优化选择枢轴值
枢轴值的作用是将数组或者表分成两部分,使得前半部分小于枢轴值,后半部分大于枢轴值。**枢轴值选择的最好情况是有序数组中间的那个关键字,**因为这样的话分成的前后两部分的长度将一样大或者差1,这样选择枢轴值递归的深度将是最低的。
之前的快排算法中,我们选择的枢轴值都是low所指向的关键字,如果需要排序的数组是一个基本有序的,那么固定的选择第一个值肯定是不合理的。
当然出现问题,就会有人改进,有人提出在low和high随机选择一个作为枢轴值。既然是随机的,那么它有可能会比之前的更块,也有可能比之前的更慢。
再继续改进就出现了三数取中法,意思就是在low所指向的关键之和(low+high)/2所指向的关键字以及high所指向的关键字中取一个中间值作为枢轴值。这种方法比之前的那种方法靠谱多了。
代码如下:
int Partition(int a[], int low, int high) {
int pivotKey;
int mid = (low + high) / 2;
if (a[low] > a[high]) {
swap(&a[low], &a[high]);
}
if (a[mid] > a[high]) {
swap(&a[mid], &a[high]);
}
if (a[mid] > a[low]) {
swap(&a[mid], &a[low]);
}
// 此时的a[low]已经是三个值中的中间值了。
pivotKey = a[low];
while (low < high) {
while (low < high && a[high] >= pivotKey)
high--;
swap(&a[low], &a[high]);
while (low < high && a[low] <= pivotKey)
low++;
swap(&a[low], &a[high]);
}
return low;
}
3.2 优化不必要的交换
从上面的那张图中不难看出,枢轴值在排序的过程中不断的在和其它的数字交换,这是因为定位的枢轴值,所以才会存在在排序的过程中出现大量其它数字和枢轴值交换的过程。但是其中的好多交换其实是没有必要的。因此可以对这里进行优化。优化的措施是将原本的交换变成替换。
代码如下:
int Partition(int a[], int low, int high) {
int pivotKey;
int mid = (low + high) / 2;
if (a[low] > a[high]) {
swap(&a[low], &a[high]);
}
if (a[mid] > a[high]) {
swap(&a[mid], &a[high]);
}
if (a[mid] > a[low]) {
swap(&a[mid], &a[low]);
}
// 此时的a[low]已经是三个值中的中间值了。
pivotKey = a[low];
while (low < high) {
while (low < high && a[high] >= pivotKey)
high--;
a[low] = a[high];
while (low < high && a[low] <= pivotKey)
low++;
a[high] = a[low];
}
a[low] = pivotKey;
return low;
}
3.3 优化小数组的排序
这种优化不能算是对快速排序算法的优化,它是对于排序的优化,对数组小的时候,快速排序不如直接插入排序快,(直接插入排序时简单排序中性能最好的)所以可以加个判断当数组的长度小于某个数时采用直接插入排序。当然这个数组有人认为7个比较好,有人认为50个更好。
这个比较简单这里就不给出代码了。
3.4 优化快排的递归操作
众所周知,递归对于算法的性能是有影响的。如果对于一个逆序的数组,之前的那种方式的递归将变得极不平衡。而且栈的大小也是有限的。这里可以使用尾递归,将两次递归操作变成一次递归。代码如下:
void QSort(int a[], int low, int high) {
int pivot;
while (low < high) {
// 将a数组一分为二,并算出枢轴值pivot
pivot = Partition(a, low, high);
QSort(a, low, pivot - 1);
low = pivot + 1;
}
}
上面这个尾递归将低子表使用递归进行处理,而将高子表使用循环处理,这样就大大的减少了栈空间的使用,从而提高了性能。
源码链接















 20万+
20万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









