







流
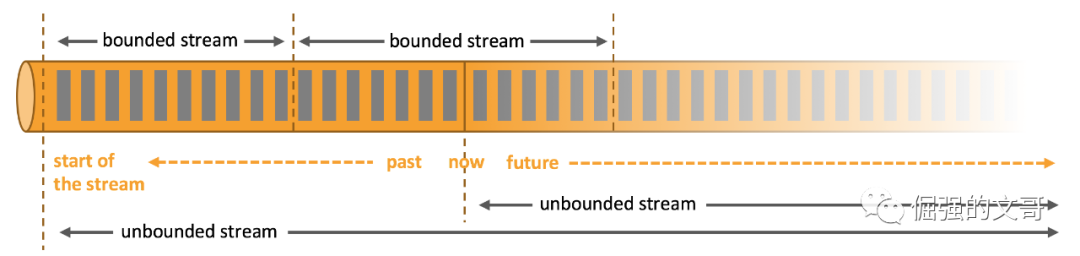
数据流分为有界数据流和无界数据流,它们的区别是有没有明确的结束点。
有界数据流有结束点,对有界数据流的处理称为批处理,特点是在处理之前就可以拿到所有的数据。
无界数据流没有结束点,数据是源源不断的,对数据的处理将会是持续性的。
flink是一个分布式流计算引擎,需要结合计算资源才能执行计算作业。
flink作业部署
如果是上手体验,可以在本地运行测试。如果是生产使用,有三种选择:
(1)在虚拟机上运行,部署多个 JobManager 备实例做 HA,通过 zookeeper 做故障感知和切换。
(2)与 Yarn、Mesos 等资源管理器集成部署,或者使用 Docker、Kubernetes 部署在容器环境。
(3)直接使用云产商提供的云计算服务,例如 AliCloud Realtime Compute、Amazon Kinesis Data Analytics For Java、Huawei Cloud Stream Service 等,可以开箱即用,聚焦业务开发,无需关注运维。
flink作业提交
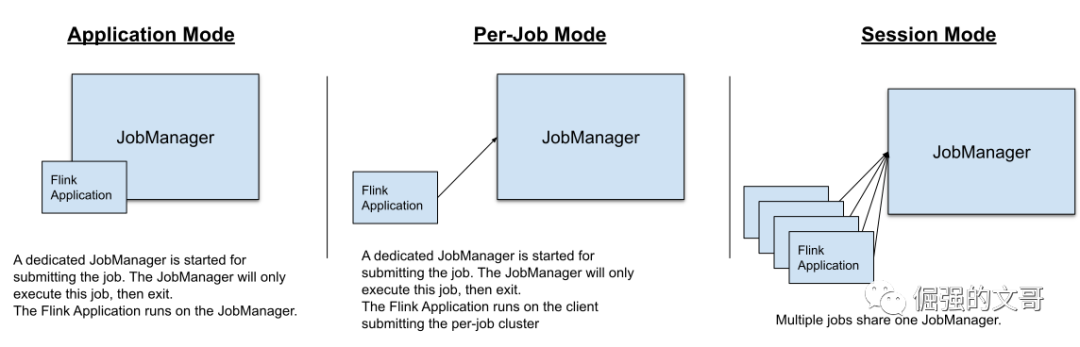
根据集群的生命周期及资源隔离程度、应用程序的 main() 方法是执行在 JobManager 还是 client,作业提交模式有三种:
会话模式: 一个 JobManager 实例管理多个作业,多个作业共享同一套 TaskManager 集群。这个模式考虑到出现故障时可能互相影响,所以并不常用,但也有它的优势,因为是共享 JobManager,所以不需要为每个提交的作业初始化一个新的 JobManager,比较适合对启动时间比较敏感的短作业。
作业模式: 每个作业独享 JobManager,作业的 main() 方法运行在 client(集群创建之前)。优点是资源隔离、故障隔离,但由于 main() 方法的执行是在 client 上,而 main() 方法主要就是做一些作业提交前的准备工作,包括下载依赖 jar 这种比较消耗带宽的操作、生成 dataflow graft 这种比较消耗cpu 的操作,如果在一个中心化的部署环境,也就是一台机器上同时运行多个 client,就会导致带宽和 cpu 热点问题。
应用模式:每个作业独享 JobManager,作业的 main() 方法在 JobManager 上执行。这种模式就解决了作业模式可能导致带宽和cpu热点的问题,同时资源和故障也都是隔离的。
当部署一个 flink 作业时,flink 会根据作业设置的并行度,向资源管理器申请资源。
一个被提交的任务会被拆分成很多个子任务,并行地在集群里执行。
当某个节点发生故障时,flink会申请新的资源替换发生故障的节点,保证任务能够继续执行。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









