







平台奖励创作,可能会升级VIP文章,可以移步我的公众号:【编程朝花夕拾】,且可获取首发内容。
01 引言
同事每天准点下班,而我还在加班写爬虫?项目Deadline逼近,数据却卡在网页结构里抽不出来?答案可能藏在XPath里。
无论是爬虫、还是现在流行的大模型的Agent工作流,解析网页数据的工具都可能用到Xpath。Xpath到底是什么呢?
02 Xpath简介
XPath是一种用于在XML和HTML文档中定位和遍历元素的语言。在Web开发中,XPath是非常重要的技能之一。掌握XPath的语法可以帮助开发人员更快速地解析和提取数据。
有过Jquery基础的可能会更加容易上手一下,归根到底,就是定位网页中的DOM节点,取出自己想要的数据。现在主流的浏览器如Chrome 本身就支持Xpath的语法,更方面我们直接调试。
03 基础语法
3.1 语法
| 表达式 | 描述 |
|---|---|
| nodename | 选取此节点的所有子节点。 |
| / | 从根节点选取(取子节点)。 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置(取子孙节点)。 |
| . | 选取当前节点。 |
| … | 选取当前节点的父节点。 |
| @ | 选取属性。 |
| * | 通配符,匹配任何元素节点 |
值得注意的是://忽略节点位置的
3.2 表达式案例
| 路径表达式 | 结果 |
|---|---|
| dd | 选取所有名为 dd的节点 |
| /dd | 选取根元素 dd |
| dd/span | 选取属于 dd 的子元素的所有 span元素 |
| //span | 选取所有 span子元素,而不管它们在文档中的位置 |
| dd//span | 选择属于 dd 元素的后代的所有 span元素,而不管它们位于 dd之下的什么位置。 |
| //@href | 选择包含href属性的所有节点。 |
3.3 浏览器中的使用
语法:
$x("xpath表达式");
例:获取所有包含href属性的节点
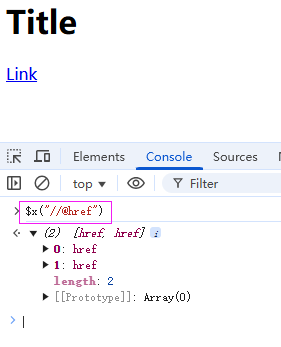
04 【必学】5个神技
语法很简单,如果要熟练使用,就需要多家练习。这里总结5个必学神奇,轻松驾驭80%的场景
案例Html:
<html>
<body>
<div class="content-1">
<h1>内容1</h1>
<p>Paragraph</p>
<input type="text" value="1">
<a href="example.com">链接跳转1</a>
</div>
<div>
<h1>内容2</h1>
<ul class="content-2">
<li>测试1</li>
<li>测试2</li>
<li>
测试3
<p>Paragraph测试3</p>
</li>
<li>
测试4
<a href="simonking.com">链接跳转4</a>
</li>
</ul>
<ul class="content-3">
<li>测试31</li>
<li>测试32</li>
<li>
测试33
<p>Paragraph测试33</p>
</li>
<li>
测试34
<a href="simonking.com">链接跳转34</a>
</li>
</ul>
</div>
</body>
</html>
4.1 「绝对路径」陷阱
假如我们需要会获取第一个
div下的p标签
# 绝对路径
/html/body/div/p
# 相对路径
//div[@class='content-1']/p
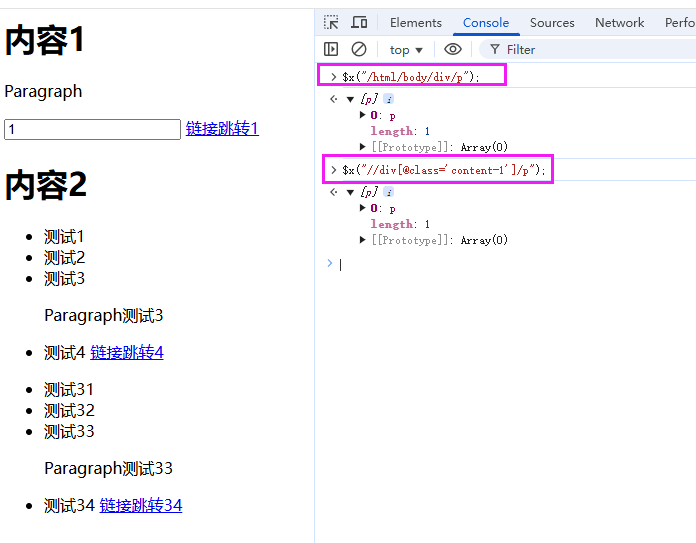
两种方案都可取代需要的节点,但是我们更推荐相对路径。因为绝对路径必须严格遵守节点顺序,一旦发生更改,就会造成取值错乱,可移植性很差,这也是90%的新手最容易踩的坑。
4.2 模糊匹配黑科技
获取class名称包含content-的节点
//*[contains(@class, "content-")]
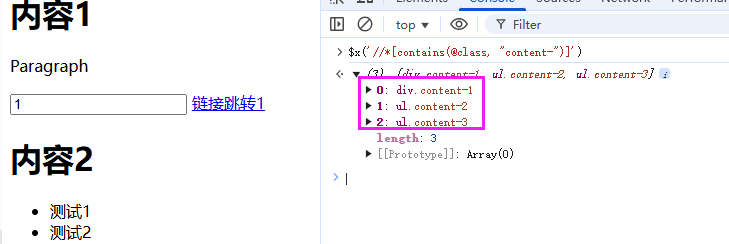
这样可以轻松应对动态的节点。
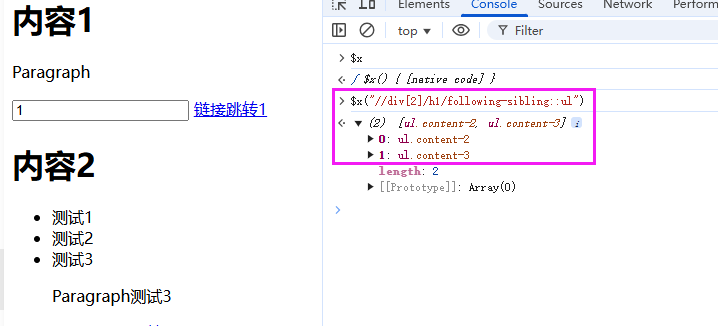
4.3 同级节点穿梭术
获取第二个div中h1标签之后的所有同级标签
这里需要使用到Xpath的轴(Axes)。
//div[2]/h1/following-sibling::ul
其中following-sibling就是轴(Axes),表示后续的同级节点。其他的轴,后面我们单独来讲。
4.4 条件筛选绝招
获取class为content-2的ul,下中间的两个li
//ul[@class='content-2']/li[position()>1 and position()<last()]
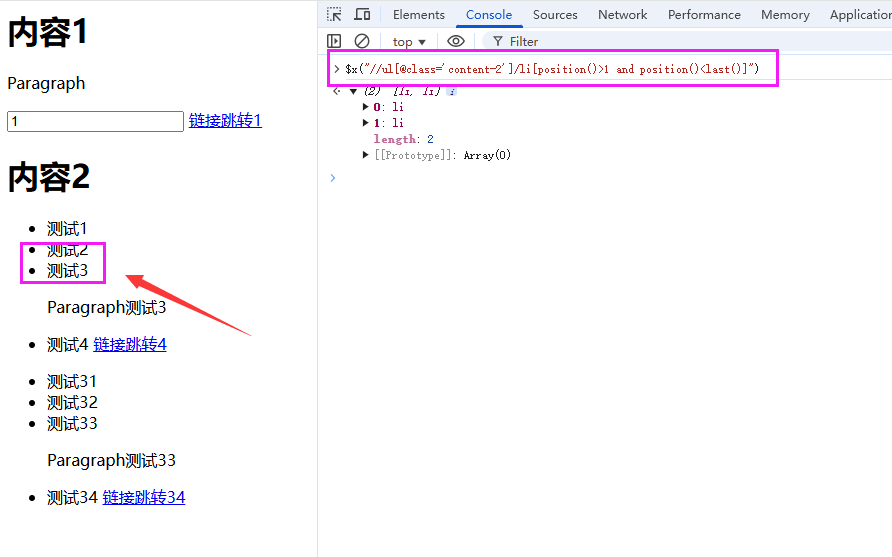
通过position()函数获取位置,last() 表示最后一个位置。
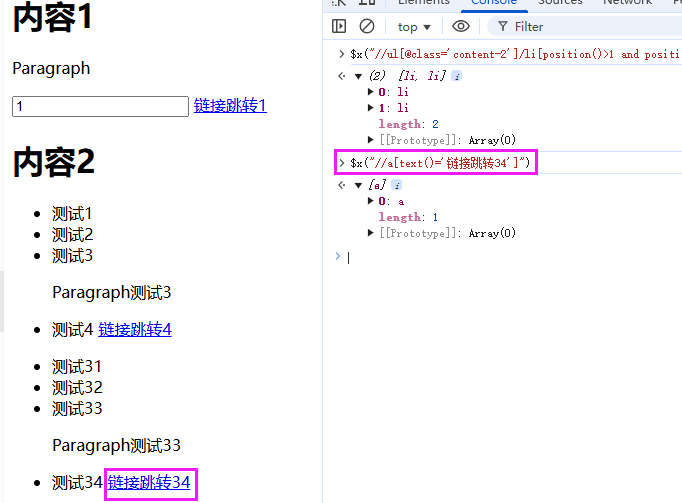
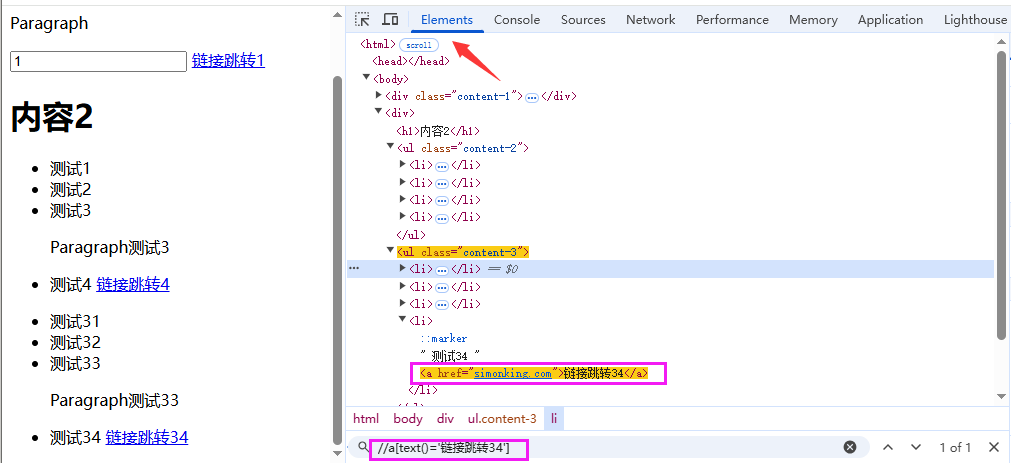
4.5 文本定位必杀技
获取链接跳转34的a标签
//a[text()='链接跳转34']
05 高手的进阶技巧
Chrome开发者工具隐藏功能,按下Ctrl+F在Elements面板直接调试XPath,实时高亮匹配结果。
性能优化三原则:
- 少用
//多用具体标签 - 善用轴(axis)减少扫描范围
- 优先使用@id等唯一属性
06 小结
你的下一个爬虫项目,可能只需要10行代码。XPath就像数据世界的望远镜,当别人还在用肉眼搜寻数据时,你已经拥有了降维打击的能力。现在打开浏览器开发者工具,用Ctrl+F开启你的第一个XPath查询吧!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











