






1.目的
利用九步消解法,将谓词公式化为子句集形式。
(1)本文Python等语言编写出谓词公式消解演示程序。
(2)界面可以通过实例按钮,由程序指定具体的实例,给出原始谓词公式;
(3)设计九个步骤的按钮,每按一步按钮,给出这一步消解的结果。
2.原理
在谓词逻辑中,任何一个谓词公式都可以通过应用等价关系及推理规则将其转化为相应的字句集,其化简步骤有:
1.消去连接词
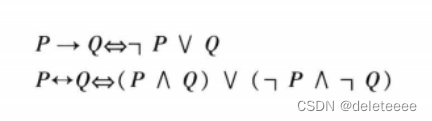
2.减少否定符号的辖域

3.对变元标准化
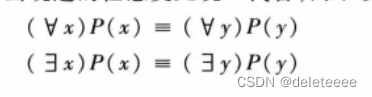
4.化为前束范式
把所有量词都移到公式的左边,并且在移动时不能改变其相对顺序。
5.消去存在量词
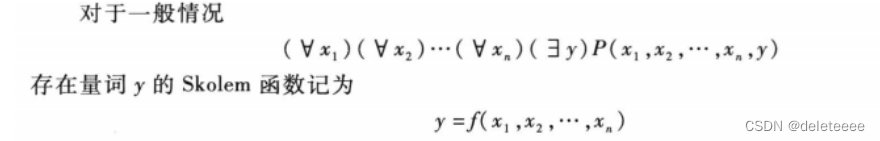
6.化为Skolem标准型

7.消去全称量词

8.消去合取词
在母式中消去所有合取词,把母式用子句集的形式表示出来。其中,子句集中的每一个元素都是一个子句。
9.更换变元名称。
对子句集中的某些变量重新命名,使任意两个子句中不出现相同的变量名。
3. 结果
利用python语言设计的GUI界面,其中有九个按钮分别对应化简字句集的九个步骤,中间的列表框中对应的是几个实例,下方为输出每一步结果的文本框

图1 界面总体设计
可以选择其中第二个实例并且依次点击九个按钮(必须得依次点击,否则将会错误,并且由于初始的数据是在第一步的按钮中导入的,所以第一步按钮必须要点击才能开始其他步骤),可以得到得到以下九步结果:

图2 第二个实例的结果
再尝试选择其中第一个实例并且依次点击九个按钮得到以下九步结果:

图3 选择第一个实例结果
接下来再随便选取一个实例点击完第一步后直接点击消去存在量词的结果如下:
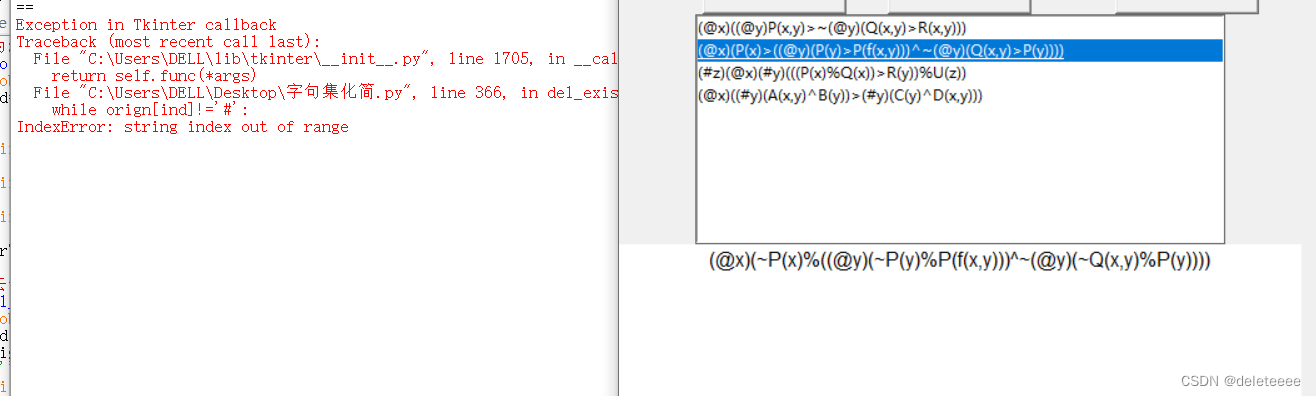
图4 点击完第一步后直接点击消去存在量词
通过对上述实验的验证可以得知选取实例后按步骤依次点击按钮则程序所给出的结果均为正确结果。而程序在实际过程中除去第六步外其实可以满足大部分原始公式的其它步骤化简,不仅限于上述所给出的四个实例,只是由于第六步化skolem标准型这一步骤我在设计过程中暂时没有通过编程自动计算所以需要在程序中通过if语句来判断我所选的实例从而给出这一步骤的结果给出这一步骤对应结果。
4.完整代码python
'''
字句集消解实验
'''
'''
->:>
析取:%
合取:^
全称:@
存在:#
非:~
'''
import tkinter as tk
global orign
window = tk.Tk()
window.title('字句集化简')
window.geometry('800x700')
var2 = tk.StringVar()
lb = tk.Listbox(window, listvariable=var2,width=60)
lb.grid(row=3,column=0,columnspan=3)
# 创建一个list并将值循环添加到Listbox控件中
lb.insert(1, '(@x)((@y)P(x,y)>~(@y)(Q(x,y)>R(x,y)))')
lb.insert(2, '(@x)(P(x)>((@y)(P(y)>P(f(x,y)))^~(@y)(Q(x,y)>P(y))))')
lb.insert(3, '(#z)(@x)(#y)(((P(x)%Q(x))>R(y))%U(z))')
lb.insert(4, '(@x)((#y)(A(x,y)^B(y))>(#y)(C(y)^D(x,y)))')
var1 = tk.StringVar()
l = tk.Label(window, bg='white', fg='black',font=('Arial', 12), width=60, textvariable=var1)
l.grid(row=4,column=0,columnspan=3)
var3 = tk.StringVar()
l1 = tk.Label(window, bg='white', fg='black',font=('Arial', 12), width=60, textvariable=var3)
l1.grid(row=5,column=0,columnspan=3)
var4 = tk.StringVar()
l2 = tk.Label(window, bg='white', fg='black',font=('Arial', 12), width=60, textvariable=var4)
l2.grid(row=6,column=0,columnspan=3)
var5 = tk.StringVar()
l3 = tk.Label(window, bg='white', fg='black',font=('Arial', 12), width=60, textvariable=var5)
l3.grid(row=7,column=0,columnspan=3)
var6 = tk.StringVar()
l4 = tk.Label(window, bg='white', fg='black',font=('Arial', 12), width=60, textvariable=var6)
l4.grid(row=8,column=0,columnspan=3)
var7 = tk.StringVar()
l5 = tk.Label(window, bg='white', fg='black',font=('Arial', 12), width=60, textvariable=var7)
l5.grid(row=9,column=0,columnspan=3)
var8 = tk.StringVar()
l6 = tk.Label(window, bg='white', fg='black',font=('Arial', 12), width=60, textvariable=var8)
l6.grid(row=10,column=0,columnspan=3)
var9 = tk.StringVar()
l7 = tk.Label(window, bg='white', fg='black',font=('Arial', 12), width=60, textvariable=var9)
l7.grid(row=11,column=0,columnspan=3)
var10 = tk.StringVar()
l8 = tk.Label(window, bg='white', fg='black',font=('Arial', 12), width=60, textvariable=var10)
l8.grid(row=12,column=0,columnspan=3)
#1.消去>蕴涵项
def del_inlclue():
global orign
orign = lb.get(lb.curselection()) # 获取当前选中的文本
ind = 0
flag=0
orignStack=[]
while (ind < len(orign)):
orignStack.append(orign[ind])
if ((ind+1<len(orign)) and (orign[ind+1]=='>')):
right_bracket = 0
flag=1
if orign[ind].isalpha():#是字母
orignStack.pop()
orignStack.append('~')
orignStack.append(orign[ind])
orignStack.append('%')
ind=ind+1
if orign[ind]==')':
a=0
tempStack = []
while(right_bracket!=0 or a==0):
a+=1
tempStack.append(orignStack[-1])
if orignStack[-1]==')':
right_bracket+=1
if orignStack[-1]=='(':
right_bracket=right_bracket-1
orignStack.pop()
if orignStack and orignStack[-1].isalpha():
tempStack.append(orignStack[-1])
orignStack.pop()
if orignStack[-3] in'@#':
for i in range(4):
tempStack.append(orignStack[-1])
orignStack.pop()
elif orignStack and orignStack[-3] in'@#':
for i in range(4):
tempStack.append(orignStack[-1])
orignStack.pop()
orignStack.append('~')
tempStack.reverse()
for i in tempStack:
orignStack.append(i)
orignStack.append('%')
ind=ind+1
ind=ind+1
value=''.join(orignStack)
orign=value
var1.set(value) # 为label设置值
#2.减少否定符号辖域
def dec_neg_rand():
#处理~(@x)p(x) 变为(#x)~p(x)#####################################
global orign
ind = 0
flag = 0
orignStack = []
left_bracket = 0
while (ind < len(orign)):
orignStack.append(orign[ind])
if orign[ind]=='~':
if orign[ind+1]=='(':
if orign[ind+2]=='@' or orign[ind+2]=='#':
flag=1
ind=ind+1
orignStack.pop()#去掉前面的~
orignStack.append(orign[ind])
if orign[ind+1]=='@':
orignStack.append('#')
else:
orignStack.append('@')
orignStack.append(orign[ind+2])#'x'
orignStack.append(orign[ind+3])#')'
orignStack.append('~')
ind=ind+3
ind=ind+1
if flag==1:
a=''
for i in orignStack:
a=a+i
orign2=a
else:
orign2=orign
#print('orign2',orign2)
# 处理~(p%q) 变为(~p^~q)#####################################
ind = 0
flag = 0
flag2 = 0 # 判断是否进入while left_bracket>=1:循环 ,若进入,出来后ind再减1
orignStack = []
left_bracket = 0
while (ind < len(orign2)):
orignStack.append(orign2[ind])
if orign2[ind] == '~':
if orign2[ind + 1] == '(':
orignStack.pop()
ind=ind+2#此时为p
left_bracket=left_bracket+1
orignStack.append('(~')
while left_bracket>=1:
flag2=1
orignStack.append(orign2[ind])
if orign2[ind]=='(':
left_bracket=left_bracket+1
if orign2[ind]==')':
left_bracket=left_bracket-1
if left_bracket==1 and orign2[ind+1]=='%' and orign2[ind+2]!='@' and orign2[ind+2]!='#':
flag=1
orignStack.append('^~')
ind=ind+1
if left_bracket == 1 and orign2[ind + 1] == '^' and orign2[ind + 2] != '@' and orign2[ind + 2] != '#':
flag = 1
orignStack.append('%~')
ind = ind + 1
ind=ind+1
if flag2==1:
ind=ind-1
flag2=0
ind=ind+1
if flag==1:
a=''
for i in orignStack:
a=a+i
orign3=a
else:
orign3=orign2
#print('orign3',orign3)
# 处理~~p 变为p#####################################
ind = 0
flag = 0
bflag = 0
orignStack = []
while (ind < len(orign3)):
orignStack.append(orign3[ind])
if orign3[ind] == '~':
if orign3[ind + 1] == '~':
flag = 1
orignStack.pop()
ind = ind + 1
ind = ind + 1
if flag == 1:
a = ''
for i in orignStack:
a = a + i
orign4 = a
else:
orign4 = orign3
# print('orign4', orign4)
# 处理~(~p) 变为p#####################################
ind = 0
flag = 0
bflag=0
orignStack = []
while (ind < len(orign4)):
orignStack.append(orign4[ind])
if orign4[ind] == '~':
if orign4[ind + 1] == '(':
left_bracket = 1
if orign4[ind+2]=='~':
flag=1
orignStack.pop()
ind=ind+2
while left_bracket>=1:
orignStack.append(orign4[ind+1])
if orign4[ind+1]=='(':
left_bracket=left_bracket+1
if orign4[ind+1]==')':
left_bracket=left_bracket-1
if orign4[ind+1]=='%' or orign4[ind+1]=='^':
bflag=1
ind=ind+1
orignStack.pop()
ind = ind + 1
if flag==1 and bflag==0:
a=''
for i in orignStack:
a=a+i
orign5=a
else:
orign5=orign4
orign=orign5
var3.set( orign5)
#3.变元标准化
def standard_var():#对变量标准化,简化,不考虑多层嵌套
global orign
flag = 1
desOri=[]
des=['w','k','j']
j=0
orignStack = []
left_bracket=0
ind = 0
while flag!=0:
flag=0
while (ind < len(orign)):
orignStack.append(orign[ind])
if orign[ind] == '@' or orign[ind]=='#':
x=orign[ind+1]#保存x
if orign[ind+1] in desOri:
orignStack.append(des[j])
desOri.append(des[j])
j=j+1
orignStack.append(')')
ind=ind+3
if ind<len(orign):
if orign[ind].isalpha():#(@x)p(x,y)这种情况
orignStack.append(orign[ind])#p
ind = ind + 1
if orign[ind]=='(':
left_bracket = left_bracket + 1
orignStack.append(orign[ind])
ind=ind+1
while left_bracket>0:
if orign[ind]== ')':
left_bracket = left_bracket - 1
if orign[ind]== '(':
left_bracket=left_bracket+1
if orign[ind]== x:
flag=1
orignStack.append(des[j-1])
else:
orignStack.append(orign[ind])
ind=ind+1
ind=ind-1
if ind<len(orign):
if orign[ind] == '(' :
left_bracket = left_bracket + 1
orignStack.append(orign[ind])
ind = ind + 1
while left_bracket > 0:
if orign[ind] == ')':
left_bracket = left_bracket - 1
if orign[ind] == '(':
left_bracket = left_bracket + 1
if orign[ind] == x:
flag = 1
orignStack.append(des[j - 1])
else:
orignStack.append(orign[ind])
ind = ind + 1
ind=ind-1
else:
desOri.append(orign[ind+1])
ind=ind+1
a=''
for i in orignStack:
a=a+i
orign=a
var4.set(orign)
#4.前束化
def convert_to_front():#化为前束
global orign
ind = 0
orignStack = []
tempStack=[]#存放全称量词
while (ind < len(orign)):
orignStack.append(orign[ind])
if orign[ind]=='(' and orign[ind+1]in '#@':
orignStack.pop()
tempStack.append(orign[ind:ind+4])
ind=ind+3
ind = ind + 1
orignStack=tempStack+orignStack
a=''
for i in orignStack:
a = a + i
orign=a
var5.set(orign)
#5.消去存在量词
def del_exists():
global orign
ind = 0
flag = 1
orignStack = []
orignStack2=[]
c=['a','b','c']
d=['f','g']
j=0
k=0
x=''
y=''
# 第1种情况:前面有全称量词 (@x)((#y)p(x,y))变为(@x)p(x,f(x))
while flag!=0: #为了嵌套的情况出现
flag=0
while (ind < len(orign)):
orignStack.append(orign[ind])
if orign[ind] == '(' and orign[ind+1] == '@' and orign[ind+4]=='(':
x=orign[ind+2]
for i in range(4):
orignStack.append(orign[ind+1+i])
ind=ind+5#指向
while orign[ind]!='#':
orignStack.append(orign[ind])
ind=ind+1
orignStack.pop()
y=orign[ind+1]#为y
ind=ind+2#指向p
flag=1
ind = ind + 1
if flag==1:
orignStack2=[]
for i in orignStack:
if i==y:
orignStack2.append(d[k])
orignStack2.append('(')
orignStack2.append(x)
orignStack2.append(')')
else:
orignStack2.append(i)
k+=1
a = ''
for i in orignStack2:
a = a + i
orign2 = a
ind = 0
flag = 1
orignStack = []
# 第2种情况:前面没有全称量词 (#y)p(x,y)变为p(x,A)
while flag != 0: # 为了嵌套的情况出现
flag = 0
while (ind < len(orign2)):
orignStack.append(orign2[ind])
if orign2[ind] == '#' :
t=ind
y=orign2[ind+1]
orignStack.pop()
orignStack.pop()
ind=ind+2#指向')'
flag=1
ind = ind + 1
if flag==1:
orignStack2 = []
for i in orignStack:
if i == y:
if '@'in orign2[:t]:
orignStack2.append(d[k])
orignStack2.append('(')
orignStack2.append(x)
orignStack2.append(')')
else:
orignStack2.append(c[j])
j+=1
else:
orignStack2.append(i)
a = ''
for i in orignStack2:
a = a + i
orign2 = a
if len(orign2)>0:
orign=orign2
var6.set(orign)
#6.化为Skolem标准型(此步骤不能满足任意输入,需根据给出实例)
def Skolem():
global orign
ind=lb.curselection()
if ind[0]==0:
orign='(@x)((~P(x,f(x))%Q(x,g(x)))^(~P(x,f(x))%~R(x,g(x))))'
elif ind[0]==1:
orign='(@x)(@y)((~P(x)%~P(y)%P(f(x,y)))^(~P(x)%Q(x,f(x)))^(~P(x)%~P(f(x))))'
elif ind[0]==2:
orign='(@x)((~P(x)%R(f(x))%U(a))^(~Q(x)%R(f(x))%U(a)))'
elif ind[0]==3:
orign='(@x)(@y)((~A(x,y)%~B(y)%C(f(x)))^(~A(x,y)%~B(y)%D(x,f(x))))'
var7.set(orign)
#7.消去全称量词
def del_all():
global orign
ind = 0
orignStack = []
a=''
while(ind<len(orign)):
orignStack.append(orign[ind])
if orign[ind]=='@':
orignStack.pop()
orignStack.pop()
ind=ind+2
ind+=1
for i in orignStack[1:-1]:
a+=i
orign=a
var8.set(orign)
#8.消去合取词
def del_and():
global orign
orign=orign.replace('^','\n')
var9.set(orign)
#9.更换变元名称
def change_name():
global orign
orign=orign.split('\n')
for i in range(len(orign)):
orign[i]=orign[i].replace('x','x'+str(i))
orign='\n'.join(orign)
var10.set(orign)
#按钮组,九步
b1 = tk.Button(window, text='去除蕴含式', width=15, height=2, command=del_inlclue)
b1.grid(row=0,column=0,stick='e')
b2 = tk.Button(window, text='减少否定符号辖域', width=15, height=2, command=dec_neg_rand)
b2.grid(row=0,column=1)
b3 = tk.Button(window, text='变元标准化', width=15, height=2, command=standard_var)
b3.grid(row=0,column=2)
b4 = tk.Button(window, text='化为前束范式', width=15, height=2, command=convert_to_front)
b4.grid(row=1,column=0,stick='e')
b5 = tk.Button(window, text='消去存在量词', width=15, height=2, command=del_exists)
b5.grid(row=1,column=1)
b6 = tk.Button(window, text='化为Skolem标准型', width=15, height=2, command=Skolem)
b6.grid(row=1,column=2)
b7 = tk.Button(window, text='消去全称量词', width=15, height=2, command=del_all)
b7.grid(row=2,column=0,stick='e')
b8 = tk.Button(window, text='消去合取词', width=15, height=2, command=del_and)
b8.grid(row=2,column=1)
b9 = tk.Button(window, text='更换变元名称', width=15, height=2, command=change_name)
b9.grid(row=2,column=2)
window.mainloop()
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











