






来自:口仆
本笔记是 deeplearning.ai 最近推出的短期课程《ChatGPT Prompt Engineering for Developers》的学习总结。
1 引言
总的来说,当前有两类大语言模型(LLM): 「基础 LLM」 和 「指令微调 LLM」 。

基础 LLM 基于大量文本数据训练而成,核心思想为预测一句话的下一个单词(即词语接龙)。基于语料的限制,有时会返回不符合预期的结果(如上图所示)。
指令微调 LLM 基于人类设定的指令(格式化的输入与输出)对基础 LLM 进行微调训练,使其能够返回更加有用且无害的结果。当前还会使用 RLHF(基于人类反馈的强化学习)来进一步提升模型效果,此处不做展开。
本课程旨在介绍如何基于 ChatGPT 官方 API 编写 Prompt(即指令),来驱动模型更好地完成各种各样的任务。
2 指南
总的来说,Prompt 的编写有两大原则:
-
原则一:编写明确而清晰的指令
-
原则二:给模型足够的时间思考
下面将结合具体的代码来对这两条原则进行详细说明。在这之前,首先给出本课程中所使用的模型调用函数的代码(略去了从环境变量获取 key 的部分):
import openai
openai.api_key = 'xxx' def get_completion(prompt, model="gpt-3.5-turbo"): messages = [{ "role": "user", "content": prompt}] response = openai.ChatCompletion.create( model=model, messages=messages, temperature= 0, # this is the degree of randomness of the model's output ) return response.choices[ 0].message[ "content"]2.1 编写明确而清晰的指令
对于这一原则,课程中给出了四条具体的策略来实践该原则:
「策略 1:使用分隔符,避免 Prompt 入侵」
我们可以通过分隔符来标识仅需要 ChatGPT 进行阅读的文本,防止其被解析为指令(即 Prompt 入侵)。常用的分隔符包括:三个引号、三个反引号、三个破折号等,ChatGPT 对于这些分隔符的区分并不是很敏感(例如在 Prompt 中说明使用反引号分隔,但实际用的是引号,并不会影响模型输出)。

具体的代码示例如下(Prompt 不作翻译,可以自行替换为中文):
text = f"""
内容省略(可添加任意内容)"""prompt = f"""Summarize the text delimited by triple backticks into a single sentence.```{text}```"""response = get_completion(prompt)print(response)「策略 2:要求模型提供结构化输出」
对于开发者来说,要求模型提供诸如 HTML 或 JSON 的格式化输出,有利于构建更加健壮的应用。具体的代码示例如下:
prompt = f"""
Generate a list of three made-up book titles along with their authors and genres. Provide them in JSON format with the following keys: book_id, title, author, genre."""response = get_completion(prompt)print(response)「策略 3:让模型进行条件判断」
对于较复杂的 Prompt,模型生成结果的时间可能会较长,同时可能浪费大量的 token。为了规避不必要的 API 调用消耗,我们可以在 Prompt 中包含一定的条件判断逻辑,来帮助模型在不满足条件时提前终止运算,直接返回结果。具体的代码示例如下:
text_1 = f"""
如何把大象放进冰箱?首先打开冰箱的门,然后把大象放进去,最后关上冰箱门。"""prompt = f"""You will be provided with text delimited by triple quotes. If it contains a sequence of instructions, re-write those instructions in the following format:Step 1 - ...Step 2 - ……Step N - …If the text does not contain a sequence of instructions, then simply write "No steps provided."```{text_1}```"""response = get_completion(prompt)print( "Completion for Text 1:")print(response)「策略 4:少量(Few-shot)训练提示」
有时候,对于某些任务,我们需要为模型提供少量完成该任务的成功示例,来帮助模型更好地理解并完成该任务。具体的代码示例如下:
prompt = f"""
Your task is to answer in a consistent style.<child>: Teach me about patience.<grandparent>: The river that carves the deepest valley flows from a modest spring; the grandest symphony originates from a single note; the most intricate tapestry begins with a solitary thread.<child>: Teach me about love."""response = get_completion(prompt)print(response)2.2 给模型足够的时间思考
这一原则的意义是:对于较为复杂的任务,如果不进行拆解,要求模型在短时间内通过少量词语进行回答,则可能导致结果的不准确。课程中给出了两条具体的策略来实践该原则:
「策略 1:指定完成任务所需的步骤」
该策略即通过 Prompt 拆解任务步骤降低复杂度,以帮助模型更好地完成任务。具体的代码示例如下(省略了 text 的内容,指定输出格式):
prompt = f"""
Your task is to perform the following actions: 1 - Summarize the following text delimited by <> with 1 sentence.2 - Translate the summary into Chinese.3 - List each name in the Chinese summary.4 - Output a json object that contains the following keys: chinese_summary, num_names.Use the following format:Text: <text to summarize>Summary: <summary>Translation: <summary translation>Names: <list of names in Chinese summary>Output JSON: <json with summary and num_names>Text: < {text}>"""response = get_completion(prompt)print( "nCompletion for prompt 2:")print(response)「策略 2:提示模型在匆忙得出结论之前思考自己的解决方案」
通过提示模型在回答之前思考自己的解决方案,有时可以得到更好的结果。课程中给出了一个解数学题的案例,如果没有提示模型首先尝试解题,则模型会判断学生的解法是正确的,但是如果提示模型首先自己推导解题过程再进行判断,则其会得出学生的解法是错误的结论。具体的代码如下(比较长):
prompt = f"""
Your task is to determine if the student's solution is correct or not.To solve the problem do the following:- First, work out your own solution to the problem. - Then compare your solution to the student's solution and evaluate if the student's solution is correct or not. Don't decide if the student's solution is correct until you have done the problem yourself.Use the following format:Question:'''question here'''Student's solution:'''student's solution here'''Actual solution:'''steps to work out the solution and your solution here'''Is the student's solution the same as actual solution just calculated:'''yes or no'''Student grade:'''correct or incorrect'''Question:'''I'm building a solar power installation and I need help working out the financials. - Land costs $100 / square foot- I can buy solar panels for $250 / square foot- I negotiated a contract for maintenance that will cost me a flat $100k per year, and an additional $10 / square footWhat is the total cost for the first year of operations as a function of the number of square feet.'''Student's solution:'''Let x be the size of the installation in square feet.Costs:1. Land cost: 100x2. Solar panel cost: 250x3. Maintenance cost: 100,000 + 100xTotal cost: 100x + 250x + 100,000 + 100x = 450x + 100,000'''Actual solution:"""response = get_completion(prompt)print(response)该代码的输出结果为:
Let x be the size of the installation in square feet.
Costs:1. Land cost: 100x2. Solar panel cost: 250x3. Maintenance cost: 100,000 + 10xTotal cost: 100x + 250x + 100,000 + 10x = 360x + 100,000Is the student's solution the same as actual solution just calculated:NoStudent grade:IncorrectPS:课程中在多行文本中使用反斜杠来代替换行符,保证原始文本中没有换行,但是其在反斜杠添加了空格,会导致换行依旧存在,需要去除空格(实际对模型来说并没有影响,只是影响展示)
此外,本节还提到了模型的一种局限性: 「幻觉」 (Hallucination)。幻觉指 LLM 模型对于知识的边界性有时把握不足,可能会出现一本正经地胡说八道的情况。为了减少幻觉,我们可以提示模型首先收集相关信息,基于这些信息来回答问题。
3 迭代
编写 Prompt 是一个持续迭代的过程,通过对模型返回结果的分析,不断地修改 Prompt,我们可以最终得到较为满意的输出。同时,对 Prompt 的修改需要遵循上一章节提到的原则。

4 摘要
我们可以使用 ChatGPT 来辅助生成对长文本的总结,以帮助我们在短时间内获取更多的信息。具体来说,通过模型执行摘要任务有以下两个注意点:
4.1 细化需求
通过 Prompt 来细化摘要的具体目的与关注点,可以获得更加精准的摘要。具体的代码示例如下:
prompt = f"""
Your task is to generate a short summary of a product review from an ecommerce site to give feedback to the Shipping deparmtment. Summarize the review below in Chinese, delimited by triple backticks, in at most 30 words, and focusing on any aspects that mention shipping and delivery of the product. Review: ''' {prod_review}'''"""response = get_completion(prompt)print(response)4.2 关键字差异
如果在 Prompt 中使用关键字 「总结」 (summarize),虽然模型会基于 Prompt 返回对应的总结,但其中通常会包含一些其他的信息;而如果使用关键字 「提取」 (extract),则模型会专注于提取在 prompt 中所提示的范围,返回更加精准的摘要。具体的代码示例如下:
prompt = f"""
Your task is to extract relevant information from a product review from an ecommerce site to give feedback to the Shipping department. The extracted result should be translated into Chinese.From the review below delimited by triple quotes extract the information relevant to shipping and delivery. Limit to 30 words. Review: ''' {prod_review}'''"""response = get_completion(prompt)print(response)5 推理
ChatGPT 非常适合用来对文本进行推理,对于传统 NLP 方法来说需要大量步骤(例如数据收集、打标签、训练、测试等)才能完成的任务,ChatGPT 可以通过 Prompt 轻松完成。本节将列举两种主要的推理任务: 「情感分析」 与 「信息提取」 。
5.1 情感分析
我们可以通过多种方式来指导 ChatGPT 分析一段文字中的情感,例如:
「识别积极/消极」
prompt = f"""
What is the sentiment of the following product review, which is delimited with triple backticks?Give your answer as a single word, either "positive" or "negative".Review text: ''' {lamp_review}'''"""response = get_completion(prompt)print(response)「识别多种情感」
prompt = f"""
Identify a list of emotions that the writer of the following review is expressing. Include no more than five items in the list. Format your answer as a list of lower-case words separated by commas.Review text: ''' {lamp_review}'''"""response = get_completion(prompt)print(response)「识别特定情感」
prompt = f"""
Is the writer of the following review expressing anger?The review is delimited with triple backticks. Give your answer as either yes or no.Review text: ''' {lamp_review}'''"""response = get_completion(prompt)print(response)5.2 信息提取
我们可以通过不同的 Prompt 指导 ChatGPT 提取不同维度的信息,例如:
「提取标签(实体)信息」
prompt = f"""
Identify the following items from the review text: - Item purchased by reviewer- Company that made the itemThe review is delimited with triple backticks. Format your response as a JSON object with "Item" and "Brand" as the keys. If the information isn't present, use "unknown" as the value.Make your response as short as possible. Review text: ''' {lamp_review}'''"""response = get_completion(prompt)print(response)「提取主题信息」
对于主题提取,ChatGPT 可以直接提取多个主题:
prompt = f"""
Determine five topics that are being discussed in the following text, which is delimited by triple backticks.Make each item one or two words long. Format your response as a list of items separated by commas.Text sample: ''' {story}'''"""response = get_completion(prompt)print(response)也可以给定主题列表,判断输入文本中包含了哪些特定主题(该方式也被称为 Zero Shot 训练):
topic_list = [
"nasa", "local government", "engineering", "employee satisfaction", "federal government"]prompt = f"""Determine whether each item in the following list of topics is a topic in the text below, whichis delimited with triple backticks.Give your answer as list with 0 or 1 for each topic.List of topics: {", ".join(topic_list)}Text sample: '''{story}'''"""response = get_completion(prompt)print(response)6 转换
本节将介绍如何使用 ChatGPT 来进行文本转换任务,例如翻译、拼写与语法检查、语气调整、格式转换等,主要以代码示例为主。
6.1 翻译
ChatGPT 基于多种语言进行训练,具有较强的翻译能力,例如:
「翻译多种语言」
prompt = f"""
Translate the following text to French and Spanishand English pirate: '''I want to order a basketball'''"""response = get_completion(prompt)print(response)「识别当前语言」
prompt = f"""
Tell me which language this is: '''Combien coûte le lampadaire?'''"""response = get_completion(prompt)print(response)6.2 语气调整
基于不同的读者(观众),输出的文字可能有较大差异。ChatGPT 可以基于 Prompt 产生不同的语调,例如:
prompt = f"""
Translate the following from slang to a business letter: 'Dude, This is Joe, check out this spec on this standing lamp.'"""response = get_completion(prompt)print(response)6.3 格式转换
ChatGPT 支持多种格式的转换,Prompt 应该清楚地描述输入与输出格式,例如:
data_json = { "resturant employees" :[
{ "name": "Shyam", "email": "shyamjaiswal@gmail.com"}, { "name": "Bob", "email": "bob32@gmail.com"}, { "name": "Jai", "email": "jai87@gmail.com"}]}prompt = f"""Translate the following python dictionary from JSON to an HTML table with column headers and title: {data_json}"""response = get_completion(prompt)print(response)6.4 文字检查
ChatGPT 还可以用来检查拼写和语法,帮助你改写文字(写文章必备),例如:
「普通校对与改写」
text = f"""
Got this for my daughter for her birthday cuz she keeps taking mine from my room. Yes, adults also like pandas too. She takes it everywhere with her, and it's super soft and cute. One of the ears is a bit lower than the other, and I don't think that was designed to be asymmetrical. It's a bit small for what I paid for it though. I think there might be other options that are bigger for the same price. It arrived a day earlier than expected, so I got to play with it myself before I gave it to my daughter."""prompt = f"proofread and correct this review: ```{text}```"response = get_completion(prompt)print(response)课程中还使用了 redlines 包来查看改写前后的差异:
from redlines import Redlines
diff = Redlines(text,response)display(Markdown(diff.output_markdown))
「基于特定风格的校对与改写」
prompt = f"""
proofread and correct this review. Make it more compelling. Ensure it follows APA style guide and targets an advanced reader. Output in markdown format.Text: ``` {text}```"""response = get_completion(prompt)display(Markdown(response))7 扩展
ChatGPT 可以用来对文字进行扩展(将短文本变成长文本),本节将给出一个使用 ChatGPT 自动回复 email 的示例,并介绍对扩展来说很重要的一个 API 参数: 「温度」 (Temperature)
7.1 扩展示例
下面的例子给出了基于用户的评价生成自动回复 email 的 Prompt:
prompt = f"""
You are a customer service AI assistant.Your task is to send an email reply in Chinese to a valued customer.Given the customer email delimited by ```, Generate a reply to thank the customer for their review.If the sentiment is positive or neutral, thank them for their review.If the sentiment is negative, apologize and suggest that they can reach out to customer service. Make sure to use specific details from the review.Write in a concise and professional tone.Sign the email as `AI customer agent`.Customer review: ''' {review}'''Review sentiment: {sentiment}"""response = get_completion(prompt)print(response)实际上情感可以由 ChatGPT 自动提取,无需指定。此外,为了防止不好的用途,课程中建议明确表明上述内容是由 AI 生成的。
7.2 温度参数
温度参数可以用来控制模型输出的随机性,具体规则如下:
-
温度越低,模型的输出越稳定(更保守)
-
温度越高,模型的输出越随机(更具有创造力)

在不同的场景下,通过对温度参数的控制,可以得到更加合适的输出(温度参数通常设置在 0-2 之间)。
8 聊天机器人
本节将介绍如何使用 ChatGPT 构建一个聊天机器人,其关键在于如何为模型提供 「上下文信息」 。对模型来说,每一轮对话都是独立的,我们需要在接口中传入之前对话的历史信息。对于接口来说,总共存在三种角色,分别是:
-
System 角色:用于设定模型的身份,约束模型行为,放置于一轮对话的最开头
-
User 角色:当前对话的用户,提供输入信息
-
Assistant 角色:生成回复的模型
历史信息需要明确地表明每一条消息所对应的角色,如下图所示:

为了实现历史信息的传入,需要修改之前的模型调用函数:
def get_completion_from_messages(messages, model="gpt-3.5-turbo", temperature=0):
response = openai.ChatCompletion.create( model=model, messages=messages, temperature=temperature, # this is the degree of randomness of the model's output ) # print(str(response.choices[0].message)) return response.choices[ 0].message[ "content"]基于上述函数,可以手动实现历史消息的传入:
messages = [
{ 'role': 'system', 'content': 'You are friendly chatbot.'},{ 'role': 'user', 'content': 'Hi, my name is Isa'},{ 'role': 'assistant', 'content': "Hi Isa! It's nice to meet you. Is there anything I can help you with today?"},{ 'role': 'user', 'content': 'Yes, you can remind me, What is my name?'} ]response = get_completion_from_messages(messages, temperature= 1)print(response)为了实现一个聊天机器人,我们需要支持对于对话历史消息的自动收集,课程中基于 panel 包实现了一个点菜机器人,通过精心设置的 System Prompt 实现了自动化点菜与价格计算,具体的代码此处不作展开。
这里给出一个更加通用的聊天机器人 demo,基于 Streamlit 实现,可以自由设置 System Prompt,同时对于对话历史消息进行了自动收集与上传:
import streamlit as st
import openaist.markdown( '# ChatGPT demo') def init_session(): if 'round' not in st.session_state: print( "重置轮数") st.session_state[ 'round'] = 1 if 'question' not in st.session_state: print( "重置问题记录") st.session_state[ 'question'] = [] if 'answer' not in st.session_state: print( "重置回答记录") st.session_state[ 'answer'] = []init_session()code_input = st.text_input( '请输入使用密钥')system_input = st.text_input( '请设定 ChatGPT 角色(用于生成符合角色的回答)', "你是一个有用的AI助手")latest_input = st.text_area( '请输入内容')openai.api_key = code_input if st.button( '发送'): st.session_state[ 'question'].append(latest_input) message_list = [] dic_q_item = { "role": "system", "content": system_input} message_list.append(dic_q_item) for n in range(st.session_state[ 'round']): # 第 n 轮,有 n 个问题,n - 1 个答案待组装 if n - 1 >= 0: dic_a_item = { "role": "assistant", "content": st.session_state[ 'answer'][n - 1]} message_list.append(dic_a_item) dic_q_item = { "role": "user", "content": st.session_state[ 'question'][n]} message_list.append(dic_q_item) completion = openai.ChatCompletion.create( model= "gpt-3.5-turbo", max_tokens= 1000, user= "wzy", messages=message_list, temperature= 0 ) answer = completion.choices[ 0].message[ 'content'] st.session_state[ 'answer'].append(answer) col1, col2 = st.columns( 2) for i in range(st.session_state[ 'round']): with col1: st.text( 'User') st.write( ' ' + st.session_state[ 'question'][i]) st.text( ' ') st.write( ' ') with col2: st.text( ' ') st.write( ' ') st.text( 'ChatGPT') st.write( ' ' + st.session_state[ 'answer'][i]) st.session_state[ 'round'] += 1 if st.button( '清空对话记录'): st.session_state.clear()9 总结
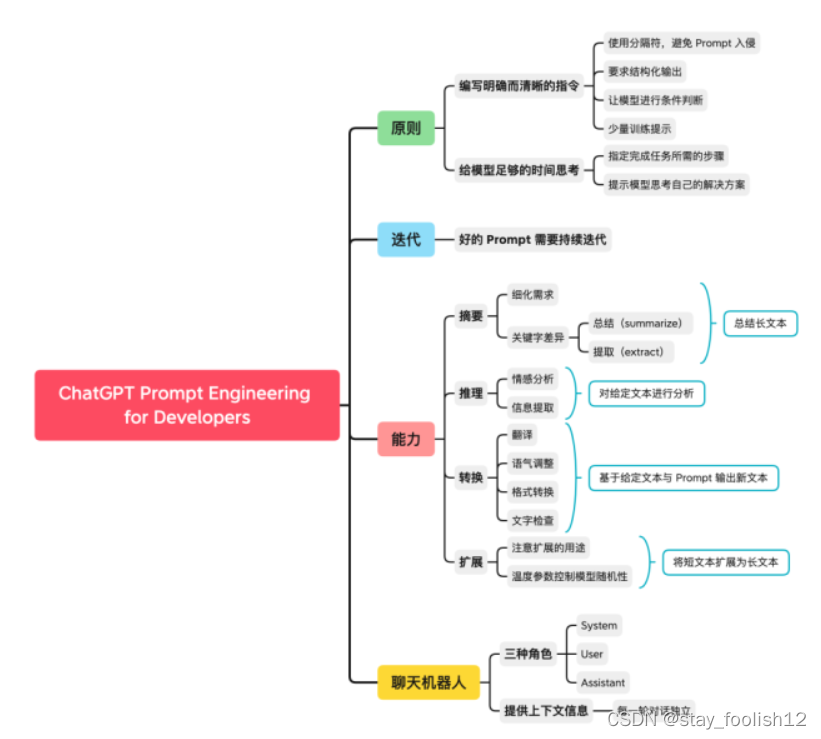
以下为本课程核心知识点的思维导图总结:

















 2704
2704











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









