







什么是布隆过滤器?
布隆过滤器(Bloom Filter)是一种空间利用效率极高的概率型数据结构,由 Burton Howard Bloom 在1970年提出。它主要用于判断一个元素是否可能属于某个集合,不支持直接获取集合中的所有元素。
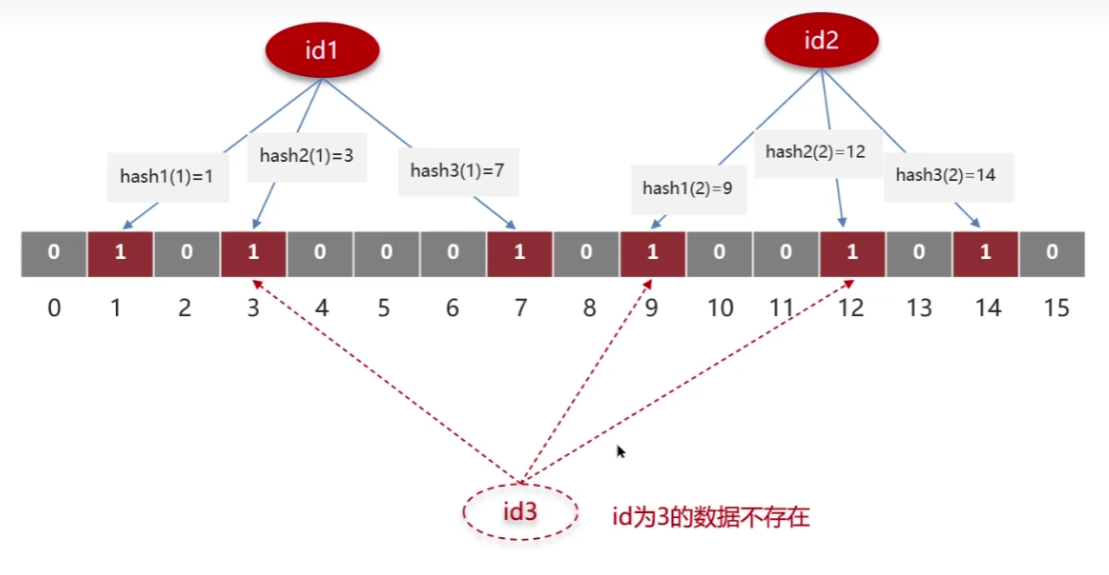
布隆过滤器的基本结构是一个固定长度的位数组和一组哈希函数。
布隆过滤器的工作流程
- 初始化时,位数组的所有位都被设置为0。
- 当要插入一个元素时,使用预先设定好的多个独立、均匀分布的哈希函数对元素进行哈希运算,每个哈希函数都会计算出一个位数组的索引位置。
- 将通过哈希运算得到的每个索引位置的位设置为1。
- 查询一个元素是否存在时,同样使用与插入时相同的哈希函数对该元素进行运算,并检查对应位数组的索引位置是否都是1。如果所有位都为1,则认为该元素可能存在于集合中;如果有任何一个位为0,则可以确定该元素肯定不在集合中。
- 由于哈希碰撞的存在,当多位同时为1时,可能出现误报(False Positive),即布隆过滤器的查询结果显示元素可能在集合中,但实际上并未被插入过。但布隆过滤器不会出现漏报(False Negative),即如果布隆过滤器说元素不在集合中,则这个结论是绝对正确的。

布隆过滤器的优点
- 空间效率高:相比于精确存储所有元素的数据结构,布隆过滤器所需的内存空间小得多。
- 查询速度快:只需要执行几个哈希函数并检查位数组即可完成查询。
- 布隆过滤器存储空间小,并且节省空间,不存储数据本身,仅存储hash结果取模运算后的位标记
布隆过滤器的缺点
- 不存储数据本身,所以只能添加但不可删除,因为删掉元素会导致误判率增加
- 由于存在hash碰撞,匹配结果如果是“存在于过滤器中”,实际不一定存在,所以布隆过滤器中一个元素如果判断结果为存在的时候元素不一定存在,但是判断结果为不存在的时候则一定不存在。因此,布隆过滤器不适合那些对结果必须精准的应用场景。
- 当容量快满时,hash碰撞的概率变大,插入、查询的错误率也就随之增加了
为了减轻误判问题带给数据库的压力,我们一般可以设置布隆过滤的误判率,大概不会超过5%,这样小概率的误判不至于在高并发的情况下给数据库带来过大的压力。
误判率越低,使用的hash函数数量越多,消耗时间越多。
实现布隆过滤
Guava工具实现布隆过滤器
guava是由谷歌公司提供的工具包,里面提供了布隆过滤器的实现。
1.导入依赖
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>30.1.1-jre</version>
</dependency>
2.测试代码
public static void main(String[] args) {
// 初始化布隆过滤器,设计预计元素数量为100_0000L,误差率为1%
//第一个参数固定,第二个参数为位图的大小,第三个元素是误判率
BloomFilter<CharSequence> bloomFilter = BloomFilter.create(Funnels.stringFunnel(StandardCharsets.UTF_8), 100_0000, 0.01);
int n = 100_0000;
for (int i = 0; i < n; i++) {
bloomFilter.put(String.valueOf(i));
}
int count = 0;
for (int i = 0; i < (n * 2); i++) {
if (bloomFilter.mightContain(String.valueOf(i))) {
count++;
}
}
System.out.println("过滤器误判率:" + 1.0 * (count - n) / n);
}执行结果:
过滤器误判率:0.010039Redis实现布隆过滤
redis中借助Redisson中封装好的方法实现布隆过滤
1.导入依赖(还需要导入redis的相关依赖和配置)
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.12.0</version>
</dependency>2.测试代码
public static void main(String[] args) {
//配置Redisson
Config config = new Config();
config.useSingleServer().setAddress("redis://127.0.0.1:6379");
//使用redis中的那一个数据库
config.useSingleServer().setDatabase(0);
RedissonClient client = Redisson.create(config);
//使用Redisson创建一个布隆过滤器,名字为bulon
RBloomFilter<Object> bloomFilter = client.getBloomFilter("bulon");
//初始化布隆过滤器,设计预计元素数量为1000000(100万),误差率为1%
int n = 1000000;
bloomFilter.tryInit(n, 0.01);
for (int i = 0; i < n; i++) {
bloomFilter.add(String.valueOf(i));
}
int count = 0;
for (int i = 0; i< (n * 2); i++) {
if (bloomFilter.contains(String.valueOf(i))) {
count++;
}
}
System.out.println("过滤器误判率:" + 1.0 * (count - n) / n);
}输出:
过滤器误判率:0.0111














 4944
4944











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









