







多模态大模型简介
多模态大语言模型(Multimodal LargeLanguageModel)是指能够处理和融合多种不同类型数据(如文本、图像、音频、视频等)的大型人工智能模型。这些模型通常基于深度学习技术,能够理解和生成多种模态的数据,从而在各种复杂的应用场景中表现出强大的能力。
下面两个例子展示了MLLM的能力:

多模态研究的重点是不同模态特征空间的对齐
模态对齐范式
介绍两种对齐范式,分别使用了Q-Former和MLP来做对齐。
Q-Former(BLIP系列)
BLIP系列工作提出了Q-Former结构来对齐视觉和文本两个模态。模型总体的工作流程如下。
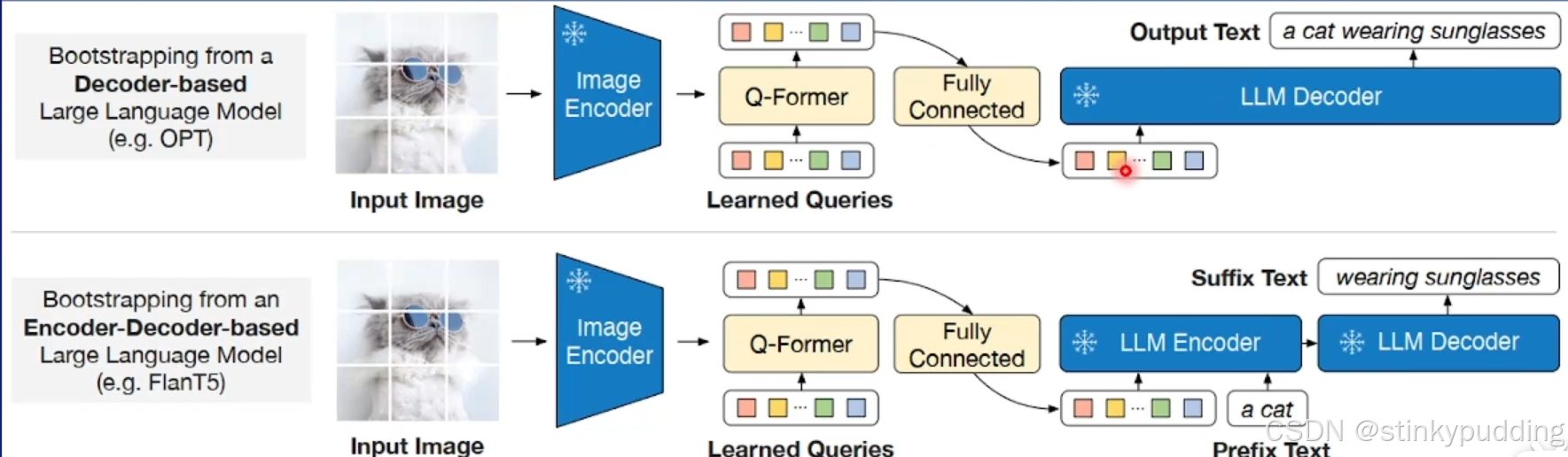
对于Q-Former部分,其设计较为复杂,如下:
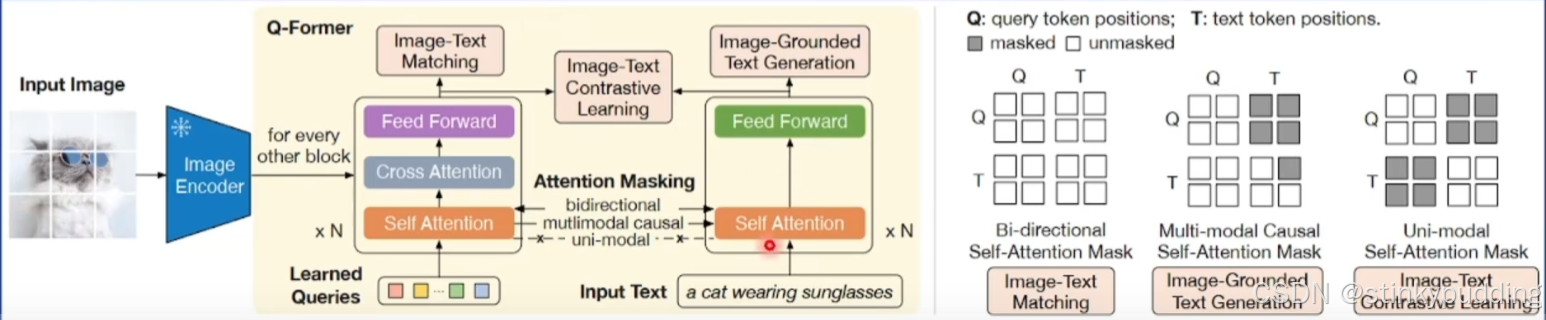
具体来说,Q-Former类似传统多模态模型,优化了三个loss:
- ITMloss:图文匹配
- LM loss: Predict Next Token
- ITC loss:对比学习
架构设计:
- 共享SelfAttention:模态交
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2251
2251

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









