







“ 该文章若有人看到,请对里面的每一句话保持最大的怀疑态度 ”
“ 仅仅是笔记 ”
本人代码小白,所以尝试理解dalao们在写什么 TAT
代码结构:
第一步:固定seed
初始化参数,固定seed值,以便保证每次训练结果一致
import numpy as np
import torch
import random
def set_seed(seed):
np.random.seed(seed)
random.seed(seed)
torch.manual_seed(seed)
if torch.cuda.is_available():
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
set_seed(114514)第二步:定义Dataset
重写 from torch.utils.data import Dataset,用于后面的DataLoader。这部分是把加载数据写在里面了。这里的init给的参数是segment_len(语音截取长度)和data_dir(数据存放位置)。
但总的说还是分为三部分: 1. __init__:初始化;2. __len__:获取长度;3. __getitem__:获得dataset中的每一个sample;
在该处可能是因为数据集本身的映射问题,在init中采用了json的方法。
__getitem__中通过某种...操作?获得了 语者->语音片段 的映射。
这里不想看数据集到底什么格式了,不做深究。
# --- Dataset ---
import os
import json
import torch
import random
from pathlib import Path
from torch.utils.data import Dataset
from torch.nn.utils.rnn import pad_sequence
class myDataset(Dataset):
def __init__(self, data_dir, segment_len=128):
self.data_dir = data_dir
self.segment_len = segment_len
# 加载从名字到id的映射
mapping_path = Path(data_dir) / "mapping.json"
mapping = json.load(mapping_path.open())
self.speaker2id = mapping["speaker2id"]
# 加载元数据
metadata_path = Path(data_dir) / "metadata.json"
metadata = json.load(open(metadata_path))["speakers"]
# Get the total number of speaker.
self.speaker_num = len(metadata.keys())
self.data = []
#建立语音->ID的数据
for speaker in metadata.keys():
for utterances in metadata[speaker]:
self.data.append([utterances["feature_path"],self.speaker2id[speaker]])
def __len__(self):
return len(self.data)
def __getitem__(self, index):
feat_path, speaker = self.data[index]
# 元数据的语音 & 名字ID
# 打开音频文件?
mel = torch.load(os.path.join(self.data_dir,feat_path))
# 将mel-spectrogram 分割成 长度为"segment_len" 帧.
if len(mel) > self.segment_len:
# 随机截取一段,先随机起点,然后开读
start = random.randint(0, len(mel) - self.segment_len)
mel = torch.FloatTensor(mel[start:start+self.segment_len])
else:
mel = torch.FloatTensor(mel)
# 强转转成long
speaker = torch.FloatTensor([speaker]).long()
# 返回真音频 ID
return mel, speaker
def get_speaker_number(self):
return self.speaker_num第三步:DataLoader
总的步骤是: 1. 获得所有数据;2. 划分训练和验证;3. 用DataLoader加载训练和测试
用 from torch.utils.data import DataLoader 加载数据,目的是为了获得:train_loader 和 vaild_loader,这里他自定义了 DataLoader 中的 collate_fn=collate_batch,参考下面的这个文章,该步骤可能为对不规整的数据,用 log 10^(-20) 进行填充。
参考 pytorch之深入理解collate_fn_音程的博客-CSDN博客
之后在加载数据集时候,因为原数据没有分训练集和验验证集,便采用 from torch.utils.data import random_split 函数对数据进行了划分。如下代码所示:
trainlen = int(0.9 * len(dataset))
lengths = [trainlen, len(dataset) - trainlen]
trainset, validset = random_split(dataset, lengths)
下面粘贴上所有代码:
# --- Dataloader ---
import torch
from torch.utils.data import DataLoader, random_split
from torch.nn.utils.rnn import pad_sequence
def collate_batch(batch):
# Process features within a batch.
"""Collate a batch of data."""
mel, speaker = zip(*batch)
# Because we train the model batch by batch, we need to pad the features in the same batch to make their lengths the same.
mel = pad_sequence(mel, batch_first=True, padding_value=-20) # pad log 10^(-20) which is very small value.
# mel: (batch size, length, 40)
return mel, torch.FloatTensor(speaker).long()
def get_dataloader(data_dir, batch_size, n_workers):
"""Generate dataloader"""
dataset = myDataset(data_dir)
speaker_num = dataset.get_speaker_number()
# 分割数据
trainlen = int(0.9 * len(dataset))
lengths = [trainlen, len(dataset) - trainlen]
trainset, validset = random_split(dataset, lengths)
train_loader = DataLoader(
trainset,
batch_size=batch_size,
shuffle=True, #traindata随机排序
num_workers=n_workers,
drop_last=True,
pin_memory=True,
collate_fn=collate_batch,
)
valid_loader = DataLoader(
validset,
batch_size=batch_size,
num_workers=n_workers,
drop_last=True,
pin_memory=True,
collate_fn=collate_batch,
)
return train_loader, valid_loader, speaker_num第四步:定义Model
baseline方法使用的是transformer(可以在colab上看到),课程中推荐使用conformer(Conformer是一种用于语音识别的神经网络模型)来代替(从代码上看他俩都是一行调用,实际是多了一块 Convolution Moduel 夹在中间)。下面是encoder部分。
self.encoder=ConformerBlock(
dim=d_model,
dim_head=4,
heads=4, #attension层头数?
ff_mult=4, #在feed forward network作为乘数的参数
conv_expansion_factor=2, #在卷积层中作成乘数的参数
conv_kernel_size=20,
attn_dropout=dropout, #attendsion层
ff_dropout=dropout, #feed forward层
conv_dropout=dropout #卷积层
)参考1:https://github.com/lucidrains/conformer
参考2(这里并不是用的这个库):Conformer — Torchaudio 2.1.0.dev20230714 documentation
Conformer资料很少....很多参数都没搞明白干什么用的,总之输入维度仍然等于输出维度,这里考虑了上下模型衔接,做了转换。具体模型结构入下图所示(截自视频)
输入->Linear->encoder(conformer)->pooling(mean)->Predict Layer(Linear)
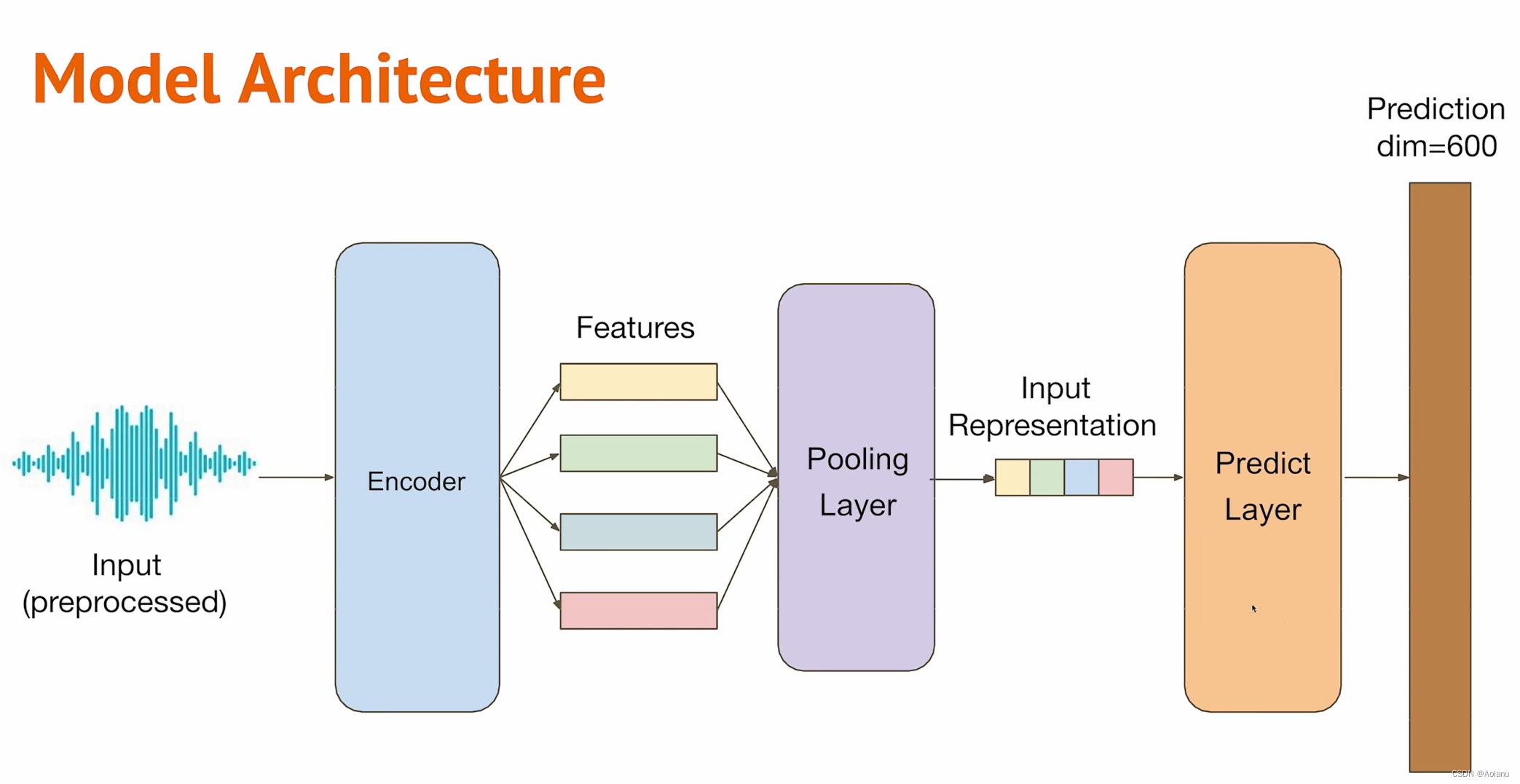
具体模型:
( transpose和permute查了一下,感觉在这里的作用是一样的,可能是用来演示有两种变形方法...)
# --- Model ---
!pip install conformer
import torch
import torch.nn as nn
import torch.nn.functional as F
from conformer import ConformerBlock
class Classifier(nn.Module):
def __init__(self, d_model=256, n_spks=600, dropout=0.2):
super().__init__()
# input -> d_model
self.prenet = nn.Linear(40, d_model)
# self.encoder_layer = nn.TransformerEncoderLayer(
# d_model=d_model, dim_feedforward=256, nhead=2
# )
# self.encoder = nn.TransformerEncoder(self.encoder_layer, num_layers=2)
# transformer不行,不如conformer
self.encoder=ConformerBlock(
dim=d_model,
dim_head=4,
heads=4, #attension层头数?
ff_mult=4, #在feed forward network作为乘数的参数
conv_expansion_factor=2, #在卷积层中作成乘数的参数
conv_kernel_size=20,
attn_dropout=dropout, #attendsion层
ff_dropout=dropout, #feed forward层
conv_dropout=dropout #卷积层
)
# Project the the dimension of features from d_model into speaker nums.
self.pred_layer = nn.Sequential(
nn.BatchNorm1d(d_model), #对小批量e2d或3d输入进行批标准化
nn.Linear(d_model, d_model),
nn.Sigmoid(),
nn.Linear(d_model, n_spks),
)
def forward(self, mels):
"""
args:
mels: (batch size, length, 40)
return:
out: (batch size, n_spks)
"""
# out: (batch size, length, d_model)
out = self.prenet(mels) # 先上到d_model
# out: (length, batch size, d_model)
out = out.permute(1, 0, 2) #变形
# The encoder layer expect features in the shape of (length, batch size, d_model).
out = self.encoder(out) #encoder就得酱紫,怪捏
# out: (batch size, length, d_model)
out = out.transpose(0, 1) #再变形
# mean pooling
stats = out.mean(dim=1) #取第1维的平均
# out: (batch, n_spks)
out = self.pred_layer(stats)
return out第五步:学习率调整计划
下面代码的全部就是想通过get_cosine_schedule_with_warmup,构建一个可以通过LambdaLR构建scheduler用来在训练中调整学习率的方案(控制梯度下降的速度)。
import math
import torch
from torch.optim import Optimizer
from torch.optim.lr_scheduler import LambdaLR #注意这玩意
##学习率调整计划
def get_cosine_schedule_with_warmup(
optimizer: Optimizer,
num_warmup_steps: int,
num_training_steps: int,
num_cycles: float = 0.5,
last_epoch: int = -1,
):
def lr_lambda(current_step):
# Warmup
if current_step < num_warmup_steps:
return float(current_step) / float(max(1, num_warmup_steps))
# decadence
progress = float(current_step - num_warmup_steps) / float(
max(1, num_training_steps - num_warmup_steps)
)
return max(
0.0, 0.5 * (1.0 + math.cos(math.pi * float(num_cycles) * 2.0 * progress))
)
return LambdaLR(optimizer,lr_lambda,last_epoch)第六步:定义训练和验证部分
训练和验证被单独拉出来写了个函数 model_fn 和 valid 。第一次见把他们单独拉出来的,蛮新奇的。。可能这么写更容易保持代码的简洁性...模块化,感觉读起来更费劲了。回去翻翻视频看看有没有什么人讲讲....虽然但是这部分没什么特别难读懂的。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









