







一:
什么是文件系统,详见:http://zh.wikipedia.org/zh/%E6%96%87%E4%BB%B6%E7%B3%BB%E7%BB%9F
其实一句话就是管理这块文件的机制(组织方式,数据结构之类...)
Linux系统中存在很多的文件系统,例如常见的ext2,ext3,ext4,sysfs,rootfs,proc...很多很多。。。我们知道每个文件系统是独立的,有自己的组织方法,操作方法。那么对于用户来说,不可能所有的文件系统都了解,那么怎么做到让用户透明的去处理文件呢?例如:我想写文件,那就直接read就OK,不管你是什么文件系统,具体怎么去读!OK,这里就需要引入虚拟文件系统。
所以虚拟文件系统就是:对于一个system,可以存在多个“实际的文件系统”,例如:ext2,ext3,fat32,ntfs...例如我现在有多个分区,对于每一个分区我们知道可以是不同的“实际文件系统”,例如现在三个磁盘分区分别是:ext2,ext3,fat32,那么每个“实际的文件系统”的操作和数据结构什么肯定不一样,那么,用户怎么能透明使用它们呢?那么这个时候就需要VFS作为中间一层!用户直接和VFS打交道。例如read,write,那么映射到VFS中就是sys_read,sys_write,那么VFS可以根据你操作的是哪个“实际文件系统”(哪个分区)来进行不同的实际的操作!那么这个技术也是很熟悉的“钩子结构”(此名称不知道是否合理,自己一直这样叫了)技术来处理的。其实就是VFS中提供一个抽象的struct结构体,然后对于每一个具体的文件系统要把自己的字段和函数填充进去,这样就解决了异构问题。
如图:
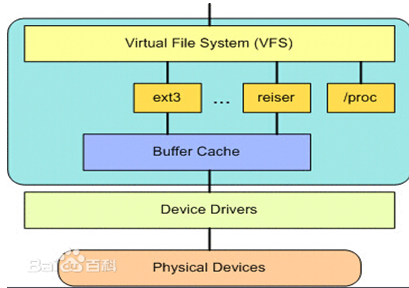
二:
Linux虚拟文件系统四大对象:
1)超级块(super block)
2)索引节点(inode)
3)目录项(dentry)
4)文件对象(file)
=> 超级块:一个超级块对应一个文件系统(已经安装的文件系统类型如ext2,此处是实际的文件系统哦,不是VFS)。之前我们已经说了文件系统用于管理这些文件的数据格式和操作之类的,系统文件有系统文件自己的文件系统,同时对于不同的磁盘分区也有可以是不同的文件系统。那么一个超级块对于一个独立的文件系统。保存文件系统的类型、大小、状态等等。
(“文件系统”和“文件系统类型”不一样!一个文件系统类型下可以包括很多文件系统即很多的super_block)
既然我们知道对于不同的文件系统有不同的super_block,那么对于不同的super_block的操作肯定也是不同的,所以我们在下面的super_block结构中可以看到上面说的抽象的struct结构(例如下面的:struct super_operations):
(linux内核2.4.37)
- <span style="font-size:14px;">struct super_block {
- 746 struct list_head s_list; /* Keep this first */
- 747 kdev_t s_dev;
- 748 unsigned long s_blocksize;
- 749 unsigned char s_blocksize_bits;
- 750 unsigned char s_dirt;
- 751 unsigned long long s_maxbytes; /* Max file size */
- 752 struct file_system_type *s_type;
- 753 struct super_operations *s_op;
- 754 struct dquot_operations *dq_op;
- 755 struct quotactl_ops *s_qcop;
- 756 unsigned long s_flags;
- 757 unsigned long s_magic;
- 758 struct dentry *s_root;
- 759 struct rw_semaphore s_umount;
- 760 struct semaphore s_lock;
- 761 int s_count;
- 762 atomic_t s_active;
- 763
- 764 struct list_head s_dirty; /* dirty inodes */
- 765 struct list_head s_locked_inodes;/* inodes being synced */
- 766 struct list_head s_files;
- 767
- 768 struct block_device *s_bdev;
- 769 struct list_head s_instances;
- 770 struct quota_info s_dquot; /* Diskquota specific options */
- 771
- 772 union {
- 773 struct minix_sb_info minix_sb;
- 774 struct ext2_sb_info ext2_sb;
- 775 struct ext3_sb_info ext3_sb;
- 776 struct hpfs_sb_info hpfs_sb;
- 777 struct ntfs_sb_info ntfs_sb;
- 778 struct msdos_sb_info msdos_sb;
- 779 struct isofs_sb_info isofs_sb;
- 780 struct nfs_sb_info nfs_sb;
- 781 struct sysv_sb_info sysv_sb;
- 782 struct affs_sb_info affs_sb;
- 783 struct ufs_sb_info ufs_sb;
- 784 struct efs_sb_info efs_sb;
- 785 struct shmem_sb_info shmem_sb;
- 786 struct romfs_sb_info romfs_sb;
- 787 struct smb_sb_info smbfs_sb;
- 788 struct hfs_sb_info hfs_sb;
- 789 struct adfs_sb_info adfs_sb;
- 790 struct qnx4_sb_info qnx4_sb;
- 791 struct reiserfs_sb_info reiserfs_sb;
- 792 struct bfs_sb_info bfs_sb;
- 793 struct udf_sb_info udf_sb;
- 794 struct ncp_sb_info ncpfs_sb;
- 795 struct usbdev_sb_info usbdevfs_sb;
- 796 struct jffs2_sb_info jffs2_sb;
- 797 struct cramfs_sb_info cramfs_sb;
- 798 void *generic_sbp;
- 799 } u;
- 800 /*
- 801 * The next field is for VFS *only*. No filesystems have any business
- 802 * even looking at it. You had been warned.
- 803 */
- 804 struct semaphore s_vfs_rename_sem; /* Kludge */
- 805
- 806 /* The next field is used by knfsd when converting a (inode number based)
- 807 * file handle into a dentry. As it builds a path in the dcache tree from
- 808 * the bottom up, there may for a time be a subpath of dentrys which is not
- 809 * connected to the main tree. This semaphore ensure that there is only ever
- 810 * one such free path per filesystem. Note that unconnected files (or other
- 811 * non-directories) are allowed, but not unconnected diretories.
- 812 */
- 813 struct semaphore s_nfsd_free_path_sem;
- 814 };</span>
解释字段:
s_list:指向超级块链表的指针,这个struct list_head是很熟悉的结构了,里面其实就是用于连接关系的prev和next字段。
内核中的结构处理都是有讲究的(内核协议栈中也说过),内核单独使用一个简单的结构体将所有的super_block都链接起来,但是这个结构不是super_block本身,因为本身数据结构太大,效率不高,所有仅仅使用
struct
{
list_head prev;
list_head next;
}
这样的结构来将super_block中的s_list链接起来,那么遍历到s_list之后,直接读取super_block这么长的一个内存块,就可以将这个
super_block直接读进来!这样就很快捷方便!这也是为什么s_list必须放在第一个字段的原因。
s_dev:包含该具体文件系统的块设备标识符。例如,对于 /dev/hda1,其设备标识符为 0x301
s_blocksize:文件系统中数据块大小,以字节单位
s_blocksize_bits:上面的size大小占用位数,例如512字节就是9 bits
s_dirt:脏位,标识是否超级块被修改
s_maxbytes:允许的最大的文件大小(字节数)
struct file_system_type *s_type:文件系统类型(也就是当前这个文件系统属于哪个类型?ext2还是fat32)
要区分“文件系统”和“文件系统类型”不一样!一个文件系统类型下可以包括很多文件系统即很多的super_block,后面会说!
struct super_operations *s_op:指向某个特定的具体文件系统的用于超级块操作的函数集合
struct dquot_operations *dq_op:指向某个特定的具体文件系统用于限额操作的函数集合
struct quotactl_ops *s_qcop:用于配置磁盘限额的的方法,处理来自用户空间的请求
s_flags:安装标识
s_magic:区别于其他文件系统的标识
s_root:指向该具体文件系统安装目录的目录项
s_umount:对超级块读写时进行同步
s_lock:锁标志位,若置该位,则其它进程不能对该超级块操作
s_count:对超级块的使用计数
s_active:引用计数
s_dirty:已修改的索引节点inode形成的链表,一个文件系统中有很多的inode,有些inode节点的内容会被修改,那么会先被记录,然后写回磁盘。
s_locked_inodes:要进行同步的索引节点形成的链表
s_files:所有的已经打开文件的链表,这个file和实实在在的进程相关的
s_bdev:指向文件系统被安装的块设备
u:u 联合体域包括属于具体文件系统的超级块信息
s_instances:具体的意义后来会说的!(同一类型的文件系统通过这个子墩将所有的super_block连接起来)
s_dquot:磁盘限额相关选项
=>索引节点inode:保存的其实是实际的数据的一些信息,这些信息称为“元数据”(也就是对文件属性的描述)。例如:文件大小,设备标识符,用户标识符,用户组标识符,文件模式,扩展属性,文件读取或修改的时间戳,链接数量,指向存储该内容的磁盘区块的指针,文件分类等等。
( 注意数据分成:元数据+数据本身 )
同时注意:inode有两种,一种是VFS的inode,一种是具体文件系统的inode。前者在内存中,后者在磁盘中。所以每次其实是将磁盘中的inode调进填充内存中的inode,这样才是算使用了磁盘文件inode。
注意inode怎样生成的:每个inode节点的大小,一般是128字节或256字节。inode节点的总数,在格式化时就给定(现代OS可以动态变化),一般每2KB就设置一个inode。一般文件系统中很少有文件小于2KB的,所以预定按照2KB分,一般inode是用不完的。所以inode在文件系统安装的时候会有一个默认数量,后期会根据实际的需要发生变化。
注意inode号:inode号是唯一的,表示不同的文件。其实在Linux内部的时候,访问文件都是通过inode号来进行的,所谓文件名仅仅是给用户容易使用的。当我们打开一个文件的时候,首先,系统找到这个文件名对应的inode号;然后,通过inode号,得到inode信息,最后,由inode找到文件数据所在的block,现在可以处理文件数据了。
inode和文件的关系:当创建一个文件的时候,就给文件分配了一个inode。一个inode只对应一个实际文件,一个文件也会只有一个inode。inodes最大数量就是文件的最大数量。
维基上说的也比较详细:维基-inode
- <span style="font-size:14px;">440 struct inode {
- 441 struct list_head i_hash;
- 442 struct list_head i_list;
- 443 struct list_head i_dentry;
- 444
- 445 struct list_head i_dirty_buffers;
- 446 struct list_head i_dirty_data_buffers;
- 447
- 448 unsigned long i_ino;
- 449 atomic_t i_count;
- 450 kdev_t i_dev;
- 451 umode_t i_mode;
- 452 unsigned int i_nlink;
- 453 uid_t i_uid;
- 454 gid_t i_gid;
- 455 kdev_t i_rdev;
- 456 loff_t i_size;
- 457 time_t i_atime;
- 458 time_t i_mtime;
- 459 time_t i_ctime;
- 460 unsigned int i_blkbits;
- 461 unsigned long i_blksize;
- 462 unsigned long i_blocks;
- 463 unsigned long i_version;
- 464 unsigned short i_bytes;
- 465 struct semaphore i_sem;
- 466 struct rw_semaphore i_alloc_sem;
- 467 struct semaphore i_zombie;
- 468 struct inode_operations *i_op;
- 469 struct file_operations *i_fop; /* former ->i_op->default_file_ops */
- 470 struct super_block *i_sb;
- 471 wait_queue_head_t i_wait;
- 472 struct file_lock *i_flock;
- 473 struct address_space *i_mapping;
- 474 struct address_space i_data;
- 475 struct dquot *i_dquot[MAXQUOTAS];
- 476 /* These three should probably be a union */
- 477 struct list_head i_devices;
- 478 struct pipe_inode_info *i_pipe;
- 479 struct block_device *i_bdev;
- 480 struct char_device *i_cdev;
- 481
- 482 unsigned long i_dnotify_mask; /* Directory notify events */
- 483 struct dnotify_struct *i_dnotify; /* for directory notifications */
- 484
- 485 unsigned long i_state;
- 486
- 487 unsigned int i_flags;
- 488 unsigned char i_sock;
- 489
- 490 atomic_t i_writecount;
- 491 unsigned int i_attr_flags;
- 492 __u32 i_generation;
- 493 union {
- 494 struct minix_inode_info minix_i;
- 495 struct ext2_inode_info ext2_i;
- 496 struct ext3_inode_info ext3_i;
- 497 struct hpfs_inode_info hpfs_i;
- 498 struct ntfs_inode_info ntfs_i;
- 499 struct msdos_inode_info msdos_i;
- 500 struct umsdos_inode_info umsdos_i;
- 501 struct iso_inode_info isofs_i;
- 502 struct nfs_inode_info nfs_i;
- 503 struct sysv_inode_info sysv_i;
- 504 struct affs_inode_info affs_i;
- 505 struct ufs_inode_info ufs_i;
- 506 struct efs_inode_info efs_i;
- 507 struct romfs_inode_info romfs_i;
- 508 struct shmem_inode_info shmem_i;
- 509 struct coda_inode_info coda_i;
- 510 struct smb_inode_info smbfs_i;
- 511 struct hfs_inode_info hfs_i;
- 512 struct adfs_inode_info adfs_i;
- 513 struct qnx4_inode_info qnx4_i;
- 514 struct reiserfs_inode_info reiserfs_i;
- 515 struct bfs_inode_info bfs_i;
- 516 struct udf_inode_info udf_i;
- 517 struct ncp_inode_info ncpfs_i;
- 518 struct proc_inode_info proc_i;
- 519 struct socket socket_i;
- 520 struct usbdev_inode_info usbdev_i;
- 521 struct jffs2_inode_info jffs2_i;
- 522 void *generic_ip;
- 523 } u;
- 524 };</span>
解释一些字段:
i_hash:指向hash链表指针,用于inode的hash表,下面会说
i_list:指向索引节点链表指针,用于inode之间的连接,下面会说
i_dentry:指向目录项链表指针,注意一个inodes可以对应多个dentry,因为一个实际的文件可能被链接到其他的文件,那么就会有另一个dentry,这个链表就是将所有的与本inode有关的dentry都连在一起。
i_dirty_buffers和i_dirty_data_buffers:脏数据缓冲区
i_ino:索引节点号,每个inode都是唯一的
i_count:引用计数
i_dev:如果inode代表设备,那么就是设备号
i_mode:文件的类型和访问权限
i_nlink:与该节点建立链接的文件数(硬链接数)
i_uid:文件拥有者标号
i_gid:文件所在组标号
i_rdev:实际的设备标识
注意i_dev和i_rdev之间区别:如果是普通的文件,例如磁盘文件,存储在某块磁盘上,那么i_dev代表的就是保存这个文件的磁盘号,但是如果此处是特殊文件例如就是磁盘本身(因为所有的设备也看做文件处理),那么i_rdev就代表这个磁盘实际的磁盘号。
i_size:inode所代表的的文件的大小,以字节为单位
i_atime:文件最后一次访问时间
i_mtime:文件最后一次修改时间
i_ctime:inode最后一次修改时间
i_blkbits:块大小,字节单位
i_blksize:块大小,bit单位
i_blocks:文件所占块数
i_version:版本号
i_bytes:文件中最后一个块的字节数
i_sem:指向用于同步操作的信号量结构
i_alloc_sem:保护inode上的IO操作不被另一个打断
i_zombie:僵尸inode信号量
i_op:索引节点操作
i_fop:文件操作
i_sb:inode所属文件系统的超级块指针
i_wait:指向索引节点等待队列指针
i_flock:文件锁链表
注意下面:address_space不是代表某个地址空间,而是用于描述页高速缓存中的页面的。一个文件对应一个address_space,一个address_space和一个偏移量可以确定一个页高速缓存中的页面。
i_mapping:表示向谁请求页面
i_data:表示被inode读写的页面
i_dquot:inode的磁盘限额
关于磁盘限额:在多任务环境下,对于每个用户的磁盘使用限制是必须的,起到一个公平性作用。
磁盘限额分为两种:block限额和inode限额,而且对于一个特文件系统来说,使用的限额机制都是一样的,所以限额的操作函数
放在super_block中就OK!
i_devices:设备链表。共用同一个驱动程序的设备形成的链表。
i_pipe:指向管道文件(如果文件是管道文件时使用)
i_bdev:指向块设备文件指针(如果文件是块设备文件时使用)
i_cdev:指向字符设备文件指针(如果文件是字符设备时使用)
i_dnotify_mask:目录通知事件掩码
i_dnotify:用于目录通知
i_state:索引节点的状态标识:I_NEW,I_LOCK,I_FREEING
i_flags:索引节点的安装标识
i_sock:如果是套接字文件则为True
i_write_count:记录多少进程以刻写模式打开此文件
i_attr_flags:文件创建标识
i_generation:保留
u:具体的inode信息
注意管理inode的四个链表:
inode_unused:将目前还没有使用的inode链接起来(通过i_list域链接)
inode_in_use:目前正在使用的inode链接起来(通过i_list域链接)
super_block中的s_dirty:将所有修改过的inode链接起来,这个字段在super_block中(通过i_list域链接起来)
inode_hashtable:注意为了加快inode的查找效率,将正在使用的inode和脏inode也会放在inode_hashtable这样一个hash结构中,
但是,不同的inode的hash值可能相等,所以将hash值相等的这些inode通过这个i_hash字段连接起来。
=>目录项:目录项是描述文件的逻辑属性,只存在于内存中,并没有实际对应的磁盘上的描述,更确切的说是存在于内存的目录项缓存,为了提高查找性能而设计。注意不管是文件夹还是最终的文件,都是属于目录项,所有的目录项在一起构成一颗庞大的目录树。例如:open一个文件/home/xxx/yyy.txt,那么/、home、xxx、yyy.txt都是一个目录项,VFS在查找的时候,根据一层一层的目录项找到对应的每个目录项的inode,那么沿着目录项进行操作就可以找到最终的文件。
注意:目录也是一种文件(所以也存在对应的inode)。打开目录,实际上就是打开目录文件。
- <span style="font-size:14px;"> 67 struct dentry {
- 68 atomic_t d_count;
- 69 unsigned int d_flags;
- 70 struct inode * d_inode; /* Where the name belongs to - NULL is negative */
- 71 struct dentry * d_parent; /* parent directory */
- 72 struct list_head d_hash; /* lookup hash list */
- 73 struct list_head d_lru; /* d_count = 0 LRU list */
- 74 struct list_head d_child; /* child of parent list */
- 75 struct list_head d_subdirs; /* our children */
- 76 struct list_head d_alias; /* inode alias list */
- 77 int d_mounted;
- 78 struct qstr d_name;
- 79 unsigned long d_time; /* used by d_revalidate */
- 80 struct dentry_operations *d_op;
- 81 struct super_block * d_sb; /* The root of the dentry tree */
- 82 unsigned long d_vfs_flags;
- 83 void * d_fsdata; /* fs-specific data */
- 84 unsigned char d_iname[DNAME_INLINE_LEN]; /* small names */
- 85 };</span>
d_count:引用计数
d_flags:目录项缓存标识,可取DCACHE_UNUSED、DCACHE_REFERENCED等
d_inode:与该目录项关联的inode
d_parent:父目录的目录项
d_hash:内核使用dentry_hashtable对dentry进行管理,dentry_hashtable是由list_head组成的链表,一个dentry创建之后,就通过
d_hash链接进入对应的hash值的链表中。
d_lru:最近未使用的目录项的链表
d_child:目录项通过这个加入到父目录的d_subdirs中
d_subdirs:本目录的所有孩子目录链表头
d_alias:一个有效的dentry必然与一个inode关联,但是一个inode可以对应多个dentry,因为一个文件可以被链接到其他文件,所以,这个dentry就是通过这个字段链接到属于自己的inode结构中的i_dentry链表中的。(inode中讲过)
d_mounted:安装在该目录的文件系统的数量!注意一个文件目录下可以有不同的文件系统!
d_name:目录项名称
d_time:重新变为有效的时间!注意只要操作成功这个dentry就是有效的,否则无效。
d_op:目录项操作
d_sb:这个目录项所属的文件系统的超级块
d_vfs_flags:一些标志
d_fsdata:文件系统私有数据
d_iname:存放短的文件名
一些解释:一个有效的dentry结构必定有一个inode结构,这是因为一个目录项要么代表着一个文件,要么代表着一个目录,而目录实际上也是文件。所以,只要dentry结构是有效的,则其指针d_inode必定指向一个inode结构。但是inode却可以对应多个
dentry,上面已经说过两次了。
注意:整个结构其实就是一棵树。
=>文件对象:注意文件对象描述的是进程已经打开的文件。因为一个文件可以被多个进程打开,所以一个文件可以存在多个文件对象。但是由于文件是唯一的,那么inode就是唯一的,目录项也是定的!
进程其实是通过文件描述符来操作文件的,注意每个文件都有一个32位的数字来表示下一个读写的字节位置,这个数字叫做文件位置。一般情况下打开文件后,打开位置都是从0开始,除非一些特殊情况。Linux用file结构体来保存打开的文件的位置,所以file称为打开的文件描述。这个需要好好理解一下!file结构形成一个双链表,称为系统打开文件表。
- <span style="font-size:14px;">565 struct file {
- 566 struct list_head f_list;
- 567 struct dentry *f_dentry;
- 568 struct vfsmount *f_vfsmnt;
- 569 struct file_operations *f_op;
- 570 atomic_t f_count;
- 571 unsigned int f_flags;
- 572 mode_t f_mode;
- 573 loff_t f_pos;
- 574 unsigned long f_reada, f_ramax, f_raend, f_ralen, f_rawin;
- 575 struct fown_struct f_owner;
- 576 unsigned int f_uid, f_gid;
- 577 int f_error;
- 578
- 579 size_t f_maxcount;
- 580 unsigned long f_version;
- 581
- 582 /* needed for tty driver, and maybe others */
- 583 void *private_data;
- 584
- 585 /* preallocated helper kiobuf to speedup O_DIRECT */
- 586 struct kiobuf *f_iobuf;
- 587 long f_iobuf_lock;
- 588 };</span>
f_list:所有的打开的文件形成的链表!注意一个文件系统所有的打开的文件都通过这个链接到super_block中的s_files链表中!
f_dentry:与该文件相关的dentry
f_vfsmnt:该文件在这个文件系统中的安装点
f_op:文件操作,当进程打开文件的时候,这个文件的关联inode中的i_fop文件操作会初始化这个f_op字段
f_count:引用计数
f_flags:打开文件时候指定的标识
f_mode:文件的访问模式
f_pos:目前文件的相对开头的偏移
unsigned long f_reada, f_ramax, f_raend, f_ralen, f_rawin:预读标志、要预读的最多页面数、上次预读后的文件指针、预读的字节数以及预读的页面数
f_owner:记录一个进程ID,以及当某些事发送的时候发送给该ID进程的信号
f_uid:用户ID
f_gid:组ID
f_error:写操作错误码
f_version:版本号,当f_pos改变时候,version递增
private_data:私有数据( 文件系统和驱动程序使用 )
重点解释一些重要字段:
首先,f_flags、f_mode和f_pos代表的是这个进程当前操作这个文件的控制信息。这个非常重要,因为对于一个文件,可以被多个进程同时打开,那么对于每个进程来说,操作这个文件是异步的,所以这个三个字段就很重要了。
第二:对于引用计数f_count,当我们关闭一个进程的某一个文件描述符时候,其实并不是真正的关闭文件,仅仅是将f_count减一,当f_count=0时候,才会真的去关闭它。对于dup,fork这些操作来说,都会使得f_count增加,具体的细节,以后再说。
第三:f_op也是很重要的!是涉及到所有的文件的操作结构体。例如:用户使用read,最终都会调用file_operations中的读操作,而file_operations结构体是对于不同的文件系统不一定相同。里面一个重要的操作函数式release函数,当用户执行close时候,其实在内核中是执行release函数,这个函数仅仅将f_count减一,这也就解释了上面说的,用户close一个文件其实是将f_count减一。只有引用计数减到0才关闭文件。
注意:对于“正在使用”和“未使用”的文件对象分别使用一个双向链表进行管理。
注意上面的file只是对一个文件而言,对于一个进程(用户)来说,可以同时处理多个文件,所以需要另一个结构来管理所有的files!
即:用户打开文件表--->files_struct
- <span style="font-size:14px;">172 struct files_struct {
- 173 atomic_t count;
- 174 rwlock_t file_lock; /* Protects all the below members. Nests inside tsk->alloc_lock */
- 175 int max_fds;
- 176 int max_fdset;
- 177 int next_fd;
- 178 struct file ** fd; /* current fd array */
- 179 fd_set *close_on_exec;
- 180 fd_set *open_fds;
- 181 fd_set close_on_exec_init;
- 182 fd_set open_fds_init;
- 183 struct file * fd_array[NR_OPEN_DEFAULT];
- 184 };</span>
解释一些字段:
count:引用计数
file_lock:锁,保护下面的字段
max_fds:当前文件对象的最大的数量
max_fdset:文件描述符最大数
next_fd:已分配的最大的文件描述符+1
fd:指向文件对象指针数组的指针,一般就是指向最后一个字段fd_arrray,当文件数超过NR_OPEN_DEFAULT时候,就会重新分配一个数组,然后指向这个新的数组指针!
close_on_exec:执行exec()时候需要关闭的文件描述符
open_fds:指向打开的文件描述符的指针
close_on_exec_init:执行exec()时候需要关闭的文件描述符初始化值
open_fds_init:文件描述符初值集合
fd_array:文件对象指针的初始化数组
注意上面的file和files_struct记录的是与进程相关的文件的信息,但是对于进程本身来说,自身的一些信息用什么表示,这里就涉及到fs_struct结构体。
- <span style="font-size:14px;"> 5 struct fs_struct {
- 6 atomic_t count;
- 7 rwlock_t lock;
- 8 int umask;
- 9 struct dentry * root, * pwd, * altroot;
- 10 struct vfsmount * rootmnt, * pwdmnt, * altrootmnt;
- 11 };</span>
解释一些字段:
count:引用计数
lock:保护锁
umask:打开文件时候默认的文件访问权限
root:进程的根目录
pwd:进程当前的执行目录
altroot:用户设置的替换根目录
注意:实际运行时,这三个目录不一定都在同一个文件系统中。例如,进程的根目录通常是安装于“/”节点上的ext文件系统,而当前工作目录可能是安装于/etc的一个文件系统,替换根目录也可以不同文件系统中。
rootmnt,pwdmnt,altrootmnt:对应于上面三个的安装点。
基本的概念和基本的结构总结完了,后面会总结看看这些之间的关系。
二,
(内核2.4.37)
一、首先,看看磁盘,超级块,inode节点在物理上整体的分布情况:
(图示来自:www.daoluan.net)
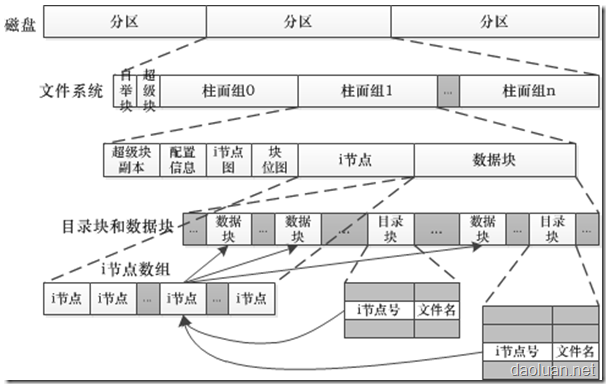
对于一个分区,对应一个文件系统,一个文件系统其实本质上还是磁盘的一部分,所以可以包括多个柱面。对于柱面上的数据,主要看看inode节点位图、block位图,i节点,数据块。inode节点位图是为了记录inode节点的使用情况,之前的违章中已经说过,inode节点在文件系统安装的时候,会初始化所有的inode节点,那么形成的位图表示使用or没使用的大表。对于block块也是一样的,记录数据块使用情况。
对于inode节点来说,每个文件都会对应一个inode节点,目录项也会对应一个inode节点。对于一个文件来说,只对应一个inode节点,但是一个文件可以有多个数据块,因为一个比较大的文件,一个数据块根本存放不了。所以inode中记录多个文件数据块的信息。
对于目录块来说,主要是为了索引而存在,所以里面的内容主要是inode节点号和文件名,其实就是一个映射表形式的东西。
二、
上一篇中对于VFS有一个简单的介绍与理解,我们知道,与用户打交道的是VFS,然后VFS与底层真正的文件系统交流。那我们知道在一个VFS下面,允许存在很多的“文件系统类型”,例如ext2,ext3,ext4,sysfs,proc等等。这些类型是可以共存的,同时,对于每一个类型来说,可以存在多个文件系统实体,例如:在一个目录下有多个子目录,子目录之间的文件系统类型可以不一样,也可以有部分是一样的类型,借用windows中的例子说就是,D盘和E盘可以都是NTFS类型文件系统,也可以是不一样的文件类型系统。
在Linux中,系统有一个全局变量叫做file_systems,这个变量用来管理所有的“文件系统类型”链表。也就是所有的文件系统类型都必须注册到(链接到)这个链表中,才可以被使用。如果是自己的文件系统,只要符合VFS的标准,也是可以注册进去的。最终形成一个单链表形式结构。
而对于一个文件系统类型,使用file_system_type结构表示:
- <span style="font-size:14px;">995 struct file_system_type {
- 996 const char *name;
- 997 int fs_flags;
- 998 struct super_block *(*read_super) (struct super_block *, void *, int);
- 999 struct module *owner;
- 1000 struct file_system_type * next;
- 1001 struct list_head fs_supers;
- 1002 };</span>
name:文件系统类型名称,如ext2。
flags:安装文件类型标志,在fs.h中有定义。
read_super:各种文件系统读入其“超级块”的函数指针,不同的文件系统之间可能不一样,因此读入函数也不一样。
owner:如果这个文件系统是通过一个可安装模块实现的,那么这个指针指向这个模块。
next:这个就是链接到下一个“文件类型”的指针。
fs_supers:属于相同的文件系统类型的所有的super_blocks构成一个双向链表。在超级块中有一个s_instance就是连接这个双链表的连接点。(超级块在上一篇有介绍)
1、
那么根据上面的解释,一个大的框架图如下:

同时,在内核中,有一个全局的变量super_blocks用于将所有的suoer_block连接在一起,形成一个双向链表,这样就会发现s_list字段就有意义了!
如图:

2、我们在之前也提过,文件系统最终还是要和进程一起协作的,任何对于文件的操作都是基于进程的。由操作系统的知识我们知道,对于进程来说,管理进程的叫“进程控制块PCB”,这个在内核中的结构为:task_struct,这个是很复杂的一个结构体,对于进程来说,可以有自己的操作的文件,那么进程的文件的信息,也是包含在这个结构中:
- 283 struct task_struct {
- ... ...
- 391 /* filesystem information */
- 392 struct fs_struct *fs;
- 393 /* open file information */
- 394 struct files_struct *files;
- ... ...
- }
代码中的两个字段就是涉及进程的文件的字段。每个进程在PCB中保存着一份文件描述符表,文件描述符就是这个表的索引(数组的下标),每个表项都有一个指向已打开文件的指针。
代码中第一个字段fs:代码本进程自身的文件系统的信息。例如进程本身的根目录,挂载点,当前目录等信息。
代码中第二个字段files:保存着本进程涉及的所有的文件的信息的指针。files_struct结构之前已经说过:files_struct
里面有两个重要字段:
- 172 struct files_struct {
- ... ...
- 178 struct file ** fd; /* current fd array */
- ... ...
- 183 struct file * fd_array[NR_OPEN_DEFAULT];
- 184 };
对于一个文件数组来说例如:fd[],所谓“文件描述符”其实就是这个数组的下标!例如:默认0就是标准输入文件描述符,1是标准输出,2是标准错误。对于用户来说操作的是这个“文件描述符”,但是对于内核来说,“文件描述符”仅仅是为了找到对应的文件而已!然后所有的在内核中的操作,都是使用实际文件的file指针进行的!关于file结构体在上一篇也说了(之前files_struct链接)。延伸一下:我们在写C语言程序的时候会遇到两个函数,open和fopen。对于前者,返回的就是一个“文件描述符”,即那个文件数组的下标,对于fopen,返回的是一个FILE的指针,这里面其实除了“文件描述符”之外,还包括IO缓冲这些信息。文件指针FILE*更上层,FILE指针将文件描述符和缓冲区封装在一起。
OK,那么用户进程打开一个文件的具体的过程是什么呢?下面分析总结一下:首先我们知道用户使用open返回一个“文件描述符”(具体怎么获得,之后再说),然后在进程PCB中,即task_struct文件数组中找到对应“文件描述符”(数组下标)的文件(file)指针,在file结构体中,f_dentry记录了这个文件的完整目录项,一般在内存中会有dentry的缓存,通过这个我们可以找到文件的inode。对于一个dentry来说,也是有自己的inode,目录名称之类信息。总之通过dentry,可以找到最终文件的inode,找到inode之后,就可以定位到具体的文件数据在磁盘上的位置了!
对于上面的过程,整体的一张图如下:

3、多个进程和多个文件之间的关系:
对于一个进程来说,可以打开多个文件,也可以多个进程打开一个文件,对于文件来说,不变的永远是自己的inode节点,变化的仅仅是和进程直接关系的file结构。可以看一下下面的大图:

三、
对于dup和fork函数来说,前者是复制一个文件描述符,后者是复制进程,同时相关的文件信息也会被复制。
一、对于Dup
之前已经知道,对于一个进程来说,有一个files_struct来管理所有的相关文件,最终的反应形式其实就是一个文件数组而已:

所谓文件描述符就是数组下标。Dup函数总是从数组第一个元素开始扫描,获取第一个可用的文件描述符(也就是没有关联实际文件的fd),这就是所谓:dup总是使用最小的文件描述符。理解了原理就简单了。
一个Dup操作之后,变成什么情况呢?看下面的图:

例如:dup(fd[y]),从开头找到第一个可以的文件描述符(所谓最小描述符),现在可以发现fd[x]和fd[y]同时指向file!这个千万注意,两个文件描述符指向同一个文件和指向同一个file不一样,指向同一个文件可以是不同的file,但是inode永远唯一,但是此处,fd指向同一个file,那么任意一个操作,另一个一定是同步的!
常见例子:一般来说,初始化的时候,进程都拥有默认的三个文件描述符默认代表,标准输入,标准输出,标准错误。但是这不是硬性规定,你可以自己改呀!例如下面的代码:
close(0);
dup(fd[x]);/* 这是一个普通文件的文件描述符 */
这之后,你会发现,0号文件描述符关联上了这个文件(0是最小的文件描述符,所以肯定会被dup选中!)。
2、对于fork函数:
父进程fork之后,子进程和父进程共享父进程打开的文件,那么使用图示表现为:

父子进程有相同的文件fd,并且对应的fd指向相同的file。
常见例子:父子进程使用管道通信时候。在父进程中创建一个pair_pipe,也就是创建一个可以通信的两个文件,一个口用于写,一个用于读。那么fork之后,子进程中复制上面信息,也拥有和父进程相同的pair_pipe,其实指向的就是同一个文件,如下图:

现在关闭父进程的pair_pipe[0],关闭子进程的pair_pipe[1],那么父子进程分别使用pair_pipe[0]和pair_pipe[1]进行通信!
具体的通信图示如下:

四、
在文件系统中,有三大缓冲为了提升效率:inode缓冲区、dentry缓冲区、块缓冲。
(内核:2.4.37)
一、inode缓冲区
为了加快对索引节点的索引,引入inode缓冲区,下面我们看Linux/fs/inode.c代码。inode缓冲区代码
1、一些数据结构:
之前已经说过,有多个链表用于管理inode节点:
- <span style="font-size:14px;">59 static LIST_HEAD(inode_in_use);
- 60 static LIST_HEAD(inode_unused);
- 61 static LIST_HEAD(inode_unused_pagecache);
- 62 static struct list_head *inode_hashtable;
- 63 static LIST_HEAD(anon_hash_chain); /* for inodes with NULL i_sb */</span>
inode_unused:有效的节点,但是还没有使用,处于空闲状态。(数据不在pagecache中)。
inode_unused_pagecache:同上。(数据在pagecache中)。
inode_hashtable:用于inode在hash表中,提高查找效率。
anon_hash_chain:用于超级块是空的的inodes。例如:sock_alloc()函数, 通过调用fs/inode.c中get_empty_inode()创建的套接字是一个匿名索引节点,这个节点就加入到了anon_hash_chain链表。
dirty:用于保存超级块中的所有的已经修改的inodes。
- <span style="font-size:14px;"> 76 struct inodes_stat_t inodes_stat;
- 77
- 78 static kmem_cache_t * inode_cachep;</span>
inodes_stat:记录inodes节点的状态。
inode_cachep:对inodes对象的缓存块。
2、基本初始化:初始化inode哈希表头和slab内存缓存块
索引节点高速缓存的初始化是由inode_init()实现的,现在看看下面代码:
- <span style="font-size:14px;">1296 /*
- 1297 * Initialize the hash tables.
- 1298 */
- 1299 void __init inode_init(unsigned long mempages) /* 参数:表示inode缓存使用的物理页面数 */
- 1300 {
- 1301 struct list_head *head;
- 1302 unsigned long order;
- 1303 unsigned int nr_hash;
- 1304 int i;
- 1305 /* 下面的一段操作就是根据PAGE_SHIFT,PAGE_SIZE给hash表分配空间 */
- 1306 mempages >>= (14 - PAGE_SHIFT);
- 1307 mempages *= sizeof(struct list_head);
- 1308 for (order = 0; ((1UL << order) << PAGE_SHIFT) < mempages; order++)
- 1309 ;
- 1310
- 1311 do {
- 1312 unsigned long tmp;
- 1313
- 1314 nr_hash = (1UL << order) * PAGE_SIZE /
- 1315 sizeof(struct list_head);
- 1316 i_hash_mask = (nr_hash - 1);
- 1317
- 1318 tmp = nr_hash;
- 1319 i_hash_shift = 0;
- 1320 while ((tmp >>= 1UL) != 0UL)
- 1321 i_hash_shift++;
- 1322 /* inode_hashtable是一个全局变量,用于hash表,上面说过,需要预定order页的内存作为inode-hash表使用 */
- 1323 inode_hashtable = (struct list_head *)
- 1324 __get_free_pages(GFP_ATOMIC, order);
- 1325 } while (inode_hashtable == NULL && --order >= 0);
- 1326
- 1327 printk(KERN_INFO "Inode cache hash table entries: %d (order: %ld, %ld bytes)\n",
- 1328 nr_hash, order, (PAGE_SIZE << order));
- 1329 /* 如果分配不成功就失败 */
- 1330 if (!inode_hashtable)
- 1331 panic("Failed to allocate inode hash table\n");
- 1332 /* 下面就是初始化每个inde-hash节点 */
- 1333 head = inode_hashtable;
- 1334 i = nr_hash;
- 1335 do {
- 1336 INIT_LIST_HEAD(head);
- 1337 head++;
- 1338 i--;
- 1339 } while (i);
- 1340
- 1341 /* inode slab cache:创建一个inode的slab缓存,以后的inode缓存都从这个slab中进行分配 */
- 1342 inode_cachep = kmem_cache_create("inode_cache", sizeof(struct inode),
- 1343 0, SLAB_HWCACHE_ALIGN, init_once,
- 1344 NULL);
- 1345 if (!inode_cachep)
- 1346 panic("cannot create inode slab cache");
- 1347
- 1348 unused_inodes_flush_task.routine = try_to_sync_unused_inodes;
- 1349 }
- 1350</span>
注意上面的逻辑,说明两个问题:
1). 第一初始化inode_hashtable作为链表的头。
2). 初始化inode的slab缓存,也就是说,如果我需要分配一个inode缓存在内存中,那么都从这个inode_cachep中分配一个inode内存节点。然后统一加入到这个inode_hashtable中进行管理!也就是所谓的创建inode slab分配器缓存。
下面看看具体的缓存的分配过程:
先看init_once函数:
- <span style="font-size:14px;">169 static void init_once(void * foo, kmem_cache_t * cachep, unsigned long flags)
- 170 {
- 171 struct inode * inode = (struct inode *) foo;
- 172
- 173 if ((flags & (SLAB_CTOR_VERIFY|SLAB_CTOR_CONSTRUCTOR)) ==
- 174 SLAB_CTOR_CONSTRUCTOR)
- 175 inode_init_once(inode);
- 176 }</span>
注意:在上面的kmem_cache_create函数中,执行的顺序是:
---> kmem_cache_create(里面重要的一步是cachep->ctor = ctor; cachep->dtor = dtor;)
---> kmem_cache_alloc
---> __kmem_cache_alloc
---> kmem_cache_grow(里面一个重要设置是:ctor_flags = SLAB_CTOR_CONSTRUCTOR;)
---> kmem_cache_init_objs:里面会执行cachep->ctor(objp, cachep, ctor_flags);
这样最终就跳转到上面的init_once函数中了!在init函数中执行的是inode_init_once函数:
- <span style="font-size:14px;">141 /*
- 142 * These are initializations that only need to be done
- 143 * once, because the fields are idempotent across use
- 144 * of the inode, so let the slab aware of that.
- 145 */
- 146 void inode_init_once(struct inode *inode)
- 147 {
- 148 memset(inode, 0, sizeof(*inode));
- 149 __inode_init_once(inode);
- 150 }</span>
- <span style="font-size:14px;">152 void __inode_init_once(struct inode *inode)
- 153 {
- 154 init_waitqueue_head(&inode->i_wait);
- 155 INIT_LIST_HEAD(&inode->i_hash);
- 156 INIT_LIST_HEAD(&inode->i_data.clean_pages);
- 157 INIT_LIST_HEAD(&inode->i_data.dirty_pages);
- 158 INIT_LIST_HEAD(&inode->i_data.locked_pages);
- 159 INIT_LIST_HEAD(&inode->i_dentry);
- 160 INIT_LIST_HEAD(&inode->i_dirty_buffers);
- 161 INIT_LIST_HEAD(&inode->i_dirty_data_buffers);
- 162 INIT_LIST_HEAD(&inode->i_devices);
- 163 sema_init(&inode->i_sem, 1);
- 164 sema_init(&inode->i_zombie, 1);
- 165 init_rwsem(&inode->i_alloc_sem);
- 166 spin_lock_init(&inode->i_data.i_shared_lock);
- 167 }</span>
3、注意知道现在我们主要说了上面的两个基本的问题(红字部分),但是这只是一个框架而已,对于具体的一个文件系统来说怎么个流程,下面需要看看!
我们以最常见的ext2作为说明:
现在一个ext2类型的文件系统想要创建一个inode,那么执行:ext2_new_inode函数
- <span style="font-size:14px;">314 struct inode * ext2_new_inode (const struct inode * dir, int mode)
- 315 {
- 316 struct super_block * sb;
- 317 struct buffer_head * bh;
- 318 struct buffer_head * bh2;
- 319 int group, i;
- 320 ino_t ino;
- 321 struct inode * inode;
- 322 struct ext2_group_desc * desc;
- 323 struct ext2_super_block * es;
- 324 int err;
- 325
- 326 sb = dir->i_sb;
- 327 inode = new_inode(sb); /* 创建一个inode节点,这个函数就是在fs/inode.c中的new_inode函数 */
- 328 if (!inode)
- 329 return ERR_PTR(-ENOMEM);
- 330
- 331 lock_super (sb);
- 332 es = sb->u.ext2_sb.s_es;
- 333 repeat:
- 334 if (S_ISDIR(mode))
- 335 group = find_group_dir(sb, dir->u.ext2_i.i_block_group);
- 336 else
- 337 group = find_group_other(sb, dir->u.ext2_i.i_block_group);
- 338
- 339 err = -ENOSPC;
- 340 if (group == -1)
- 341 goto fail;
- 342
- 343 err = -EIO;
- 344 bh = load_inode_bitmap (sb, group);
- 345 if (IS_ERR(bh))
- 346 goto fail2;
- 347
- 348 i = ext2_find_first_zero_bit ((unsigned long *) bh->b_data,
- 349 EXT2_INODES_PER_GROUP(sb));
- 350 if (i >= EXT2_INODES_PER_GROUP(sb))
- 351 goto bad_count;
- 352 ext2_set_bit (i, bh->b_data);
- 353
- 354 mark_buffer_dirty(bh);
- 355 if (sb->s_flags & MS_SYNCHRONOUS) {
- 356 ll_rw_block (WRITE, 1, &bh);
- 357 wait_on_buffer (bh);
- 358 }
- 359
- 360 ino = group * EXT2_INODES_PER_GROUP(sb) + i + 1;
- 361 if (ino < EXT2_FIRST_INO(sb) || ino > le32_to_cpu(es->s_inodes_count)) {
- 362 ext2_error (sb, "ext2_new_inode",
- 363 "reserved inode or inode > inodes count - "
- 364 "block_group = %d,inode=%ld", group, ino);
- 365 err = -EIO;
- 366 goto fail2;
- 367 }
- 368
- 369 es->s_free_inodes_count =
- 370 cpu_to_le32(le32_to_cpu(es->s_free_inodes_count) - 1);
- 371 mark_buffer_dirty(sb->u.ext2_sb.s_sbh);
- 372 sb->s_dirt = 1;
- 373 inode->i_uid = current->fsuid;
- 374 if (test_opt (sb, GRPID))
- 375 inode->i_gid = dir->i_gid;
- 376 else if (dir->i_mode & S_ISGID) {
- 377 inode->i_gid = dir->i_gid;
- 378 if (S_ISDIR(mode))
- 379 mode |= S_ISGID;
- 380 } else
- 381 inode->i_gid = current->fsgid;
- 382 inode->i_mode = mode;
- 383
- 384 inode->i_ino = ino;
- 385 inode->i_blksize = PAGE_SIZE; /* This is the optimal IO size (for stat), not the fs block size */
- 386 inode->i_blocks = 0;
- 387 inode->i_mtime = inode->i_atime = inode->i_ctime = CURRENT_TIME;
- 388 inode->u.ext2_i.i_state = EXT2_STATE_NEW;
- 389 inode->u.ext2_i.i_flags = dir->u.ext2_i.i_flags & ~EXT2_BTREE_FL;
- 390 if (S_ISLNK(mode))
- 391 inode->u.ext2_i.i_flags &= ~(EXT2_IMMUTABLE_FL|EXT2_APPEND_FL);
- 392 inode->u.ext2_i.i_block_group = group;
- 393 ext2_set_inode_flags(inode);
- 394 insert_inode_hash(inode); /* 将这个新的inode内存节点挂在hashtable中,这个函数在fs/inode.c中的insert_inode_hash函数 */
- 395 inode->i_generation = event++;
- 396 mark_inode_dirty(inode);
- 397
- 398 unlock_super (sb);
- 399 if(DQUOT_ALLOC_INODE(inode)) {
- 400 DQUOT_DROP(inode);
- 401 inode->i_flags |= S_NOQUOTA;
- 402 inode->i_nlink = 0;
- 403 iput(inode);
- 404 return ERR_PTR(-EDQUOT);
- 405 }
- 406 ext2_debug ("allocating inode %lu\n", inode->i_ino);
- 407 return inode;
- 408
- 409 fail2:
- 410 desc = ext2_get_group_desc (sb, group, &bh2);
- 411 desc->bg_free_inodes_count =
- 412 cpu_to_le16(le16_to_cpu(desc->bg_free_inodes_count) + 1);
- 413 if (S_ISDIR(mode))
- 414 desc->bg_used_dirs_count =
- 415 cpu_to_le16(le16_to_cpu(desc->bg_used_dirs_count) - 1);
- 416 mark_buffer_dirty(bh2);
- 417 fail:
- 418 unlock_super(sb);
- 419 make_bad_inode(inode);
- 420 iput(inode);
- 421 return ERR_PTR(err);
- 422
- 423 bad_count:
- 424 ext2_error (sb, "ext2_new_inode",
- 425 "Free inodes count corrupted in group %d",
- 426 group);
- 427 /* Is it really ENOSPC? */
- 428 err = -ENOSPC;
- 429 if (sb->s_flags & MS_RDONLY)
- 430 goto fail;
- 431
- 432 desc = ext2_get_group_desc (sb, group, &bh2);
- 433 desc->bg_free_inodes_count = 0;
- 434 mark_buffer_dirty(bh2);
- 435 goto repeat;
- 436 }</span>
这个函数比较复杂,但是我们主要看327行和394行,就是创建一个inode内存节点,然后将这个inode插入inode_hashtable中!
这个函数具体的解释不再看了,现在主要从这两个函数入手:
1). fs/inode.c中的new_inode函数,创建一个inode内存节点:
- <span style="font-size:14px;">964 struct inode * new_inode(struct super_block *sb)
- 965 {
- 966 static unsigned long last_ino;
- 967 struct inode * inode;
- 968
- 969 spin_lock_prefetch(&inode_lock);
- 970
- 971 inode = alloc_inode(sb);/* 这个是主要的分配函数 */
- 972 if (inode) {
- 973 spin_lock(&inode_lock);
- 974 inodes_stat.nr_inodes++; /* inode_stat是一个所有节点状态字段,这里表明增加了一个新的inode */
- 975 list_add(&inode->i_list, &inode_in_use); /* 将这个inode加入到正在使用的链表中:inode_use链表 */
- 976 inode->i_ino = ++last_ino; /* 给这个inode分配一个inode号! */
- 977 inode->i_state = 0;
- 978 spin_unlock(&inode_lock);
- 979 }
- 980 return inode;
- 981 }</span>
看看这个alloc_inode函数:
- <span style="font-size:14px;"> 80 static struct inode *alloc_inode(struct super_block *sb)
- 81 {
- 82 static struct address_space_operations empty_aops;
- 83 static struct inode_operations empty_iops;
- 84 static struct file_operations empty_fops;
- 85 struct inode *inode;
- 86
- 87 if (sb->s_op->alloc_inode) /* 如果提供了自己的分配函数,那么这个文件系统自己分配去~~~,具体不多说 */
- 88 inode = sb->s_op->alloc_inode(sb);
- 89 else {
- 90 inode = (struct inode *) kmem_cache_alloc(inode_cachep, SLAB_KERNEL);/* 这个就是通用的分配函数,从我们初始化好的inode_cache中分配 */
- 91 /* will die */
- 92 if (inode)
- 93 memset(&inode->u, 0, sizeof(inode->u));
- 94 }
- 95 /* 下面初始化的东西就不多说了 */
- 96 if (inode) {
- 97 struct address_space * const mapping = &inode->i_data;
- 98
- 99 inode->i_sb = sb;
- 100 inode->i_dev = sb->s_dev;
- 101 inode->i_blkbits = sb->s_blocksize_bits;
- 102 inode->i_flags = 0;
- 103 atomic_set(&inode->i_count, 1);
- 104 inode->i_sock = 0;
- 105 inode->i_op = &empty_iops;
- 106 inode->i_fop = &empty_fops;
- 107 inode->i_nlink = 1;
- 108 atomic_set(&inode->i_writecount, 0);
- 109 inode->i_size = 0;
- 110 inode->i_blocks = 0;
- 111 inode->i_bytes = 0;
- 112 inode->i_generation = 0;
- 113 memset(&inode->i_dquot, 0, sizeof(inode->i_dquot));
- 114 inode->i_pipe = NULL;
- 115 inode->i_bdev = NULL;
- 116 inode->i_cdev = NULL;
- 117
- 118 mapping->a_ops = &empty_aops;
- 119 mapping->host = inode;
- 120 mapping->gfp_mask = GFP_HIGHUSER;
- 121 inode->i_mapping = mapping;
- 122 }
- 123 return inode;
- 124 }</span>
我们主要看87行和90行!看了注释也就明白了!第一种是文件系统也就是这个超级快提供了分配函数,那么就这个文件系统按照自己的意愿去分配,如果没有,那么就是要用这个通用的分配函数inode = (struct inode *) kmem_cache_alloc(inode_cachep, SLAB_KERNEL);这个函数其实很简单,其实就是在我们已经初始化好的这个inode_cache中分配一个inode内存块出来。
2). fs/inode.c中的insert_inode_hash函数,将新的分配的inode插入到inode_hashtable中:
- <span style="font-size:14px;">1166 void insert_inode_hash(struct inode *inode)
- 1167 {
- 1168 struct list_head *head = &anon_hash_chain; /* anon_hash_chain是代表没有超级块的inode链表(有些临时的inode无需超级块) */
- 1169 if (inode->i_sb)
- 1170 head = inode_hashtable + hash(inode->i_sb, inode->i_ino); /* 这个是正常的插入 */
- 1171 spin_lock(&inode_lock);
- 1172 list_add(&inode->i_hash, head);
- 1173 spin_unlock(&inode_lock);
- 1174 }</span>
注意这个hash表其实就可以看做是一个数组链表组合体,如图所示:

head = inode_hashtable + hash(inode->i_sb, inode->i_ino);这一行就是通过这个hash函数算出hash值,找到这个inode应该放在哪一列。譬如定位到第三列,那么第三列中的都是hash值相同的inode。然后所有的这列inode都是构成双向链表的。注意inode中的i_hash字段就做这个事的!!list_add(&inode->i_hash, head);函数就是将hash值相同的inode构成双向链表。
看一下这个具体的hash函数(inode.c中):
- <span style="font-size:14px;">1043 static inline unsigned long hash(struct super_block *sb, unsigned long i_ino)
- 1044 {
- 1045 unsigned long tmp = i_ino + ((unsigned long) sb / L1_CACHE_BYTES);
- 1046 tmp = tmp + (tmp >> I_HASHBITS);
- 1047 return tmp & I_HASHMASK;
- 1048 }</span>
OK,上面的具体的inode创建和加入的流程基本清楚了。具体创建的过程是涉及到内存这一块的,不多说了。
4. 下面看看给一个怎么去找到一个inode,涉及ilookup函数:
- <span style="font-size:14px;">1102 struct inode *ilookup(struct super_block *sb, unsigned long ino)
- 1103 {
- 1104 struct list_head * head = inode_hashtable + hash(sb,ino);/* 获得hash值 */
- 1105 struct inode * inode;
- 1106
- 1107 spin_lock(&inode_lock);
- 1108 inode = find_inode(sb, ino, head, NULL, NULL); /* 寻找inode */
- 1109 if (inode) {
- 1110 __iget(inode);
- 1111 spin_unlock(&inode_lock);
- 1112 wait_on_inode(inode);
- 1113 return inode;
- 1114 }
- 1115 spin_unlock(&inode_lock);
- 1116
- 1117 return inode;
- 1118 }</span>
这个函数其实比较简单了,首先还是获得这个inode的hash值定位,然后开始finde_inode:
- <span style="font-size:14px;">929 static struct inode * find_inode(struct super_block * sb, unsigned long ino, struct list_head *head, find_inode_t find_actor, void *opaque)
- 930 {
- 931 struct list_head *tmp;
- 932 struct inode * inode;
- 933
- 934 repeat:
- 935 tmp = head;
- 936 for (;;) {
- 937 tmp = tmp->next;
- 938 inode = NULL;
- 939 if (tmp == head) /*双向循环链表结束条件*/
- 940 break;
- 941 inode = list_entry(tmp, struct inode, i_hash); /*获得链表中一个inode*/
- 942 if (inode->i_ino != ino) /*是否找到*/
- 943 continue;
- 944 if (inode->i_sb != sb) /*是否合理:是不是我需要的super_block中的inode*/
- 945 continue;
- 946 if (find_actor && !find_actor(inode, ino, opaque)) /*这个是一个查找函数指针,用户定义的一些规则是否满足*/
- 947 continue;
- 948 if (inode->i_state & (I_FREEING|I_CLEAR)) { /*注意inode节点的状态如果是free或者clear,那么等free之后再重新找*/
- 949 __wait_on_freeing_inode(inode);
- 950 goto repeat;
- 951 }
- 952 break;
- 953 }
- 954 return inode; /*返回找到的inode节点*/
- 955 }</span>
上面函数最核心的本质不就是双向链表的查找么,OK。
最后:关于inode怎么工作的,将会在后面的分析ext2代码中在详细研究。
五、
在文件系统中,有三大缓冲为了提升效率:inode缓冲区、dentry缓冲区、块缓冲。
(内核:2.4.37)
二、块buffer缓冲区
0、整体来说,Linux 文件缓冲区分为page cache和buffer cache,每一个 page cache 包含若干 buffer cache。
》 内存管理系统和 VFS 只与 page cache 交互,内存管理系统负责维护每项 page cache 的分配和回收,同时在使用“内存映射”方式访问时负责建立映射。
》 VFS 负责 page cache 与用户空间的数据交换。
》 而具体文件系统则一般只与 buffer cache 交互,它们负责在存储设备和 buffer cache 之间交换数据,具体的文件系统直接操作的就是disk部分,而具体的怎么被包装被用户使用是VFS的责任(VFS将buffer cache包装成page给用户)。
》 每一个page有N个buffer cache,struct buffer_head结构体中一个字段b_this_page就是将一个page中的buffer cache连接起来的结构
看一下这个结构:/include/linux/mm.h,对于struct buffer_head下面再看。
看到下面167行代码就懂了~
- typedef struct page {
- 156 struct list_head list; /* ->mapping has some page lists. */
- 157 struct address_space *mapping; /* The inode (or ...) we belong to. */
- 158 unsigned long index; /* Our offset within mapping. */
- 159 struct page *next_hash; /* Next page sharing our hash bucket in
- 160 the pagecache hash table. */
- 161 atomic_t count; /* Usage count, see below. */
- 162 unsigned long flags; /* atomic flags, some possibly
- 163 updated asynchronously */
- 164 struct list_head lru; /* Pageout list, eg. active_list;
- 165 protected by pagemap_lru_lock !! */
- 166 struct page **pprev_hash; /* Complement to *next_hash. */
- 167 struct buffer_head * buffers; /* Buffer maps us to a disk block. */
- 168
- 169 /*
- 170 * On machines where all RAM is mapped into kernel address space,
- 171 * we can simply calculate the virtual address. On machines with
- 172 * highmem some memory is mapped into kernel virtual memory
- 173 * dynamically, so we need a place to store that address.
- 174 * Note that this field could be 16 bits on x86 ... ;)
- 175 *
- 176 * Architectures with slow multiplication can define
- 177 * WANT_PAGE_VIRTUAL in asm/page.h
- 178 */
- 179 #if defined(CONFIG_HIGHMEM) || defined(WANT_PAGE_VIRTUAL)
- 180 void *virtual; /* Kernel virtual address (NULL if
- 181 not kmapped, ie. highmem) */
- 182 #endif /* CONFIG_HIGMEM || WANT_PAGE_VIRTUAL */
- 183 } mem_map_t;
关系图如下:

1、对于具体的Linux文件系统,会以block(磁盘块)的形式组织文件,为了减少对物理块设备的访问,在文件以块的形式调入内存后,使用块高速缓存进行管理。每个缓冲区由两部分组成,第一部分称为缓冲区首部,用数据结构buffer_head表示,第二部分是真正的存储的数据。由于缓冲区首部不与数据区域相连,数据区域独立存储。因而在缓冲区首部中,有一个指向数据的指针和一个缓冲区长度的字段。
Ps:内核同样有几种不同的链表来管理buffer cache,在fs/buffer.c中定义:
static struct buffer_head **hash_table;
static struct buffer_head *lru_list[NR_LIST];
static struct buffer_head * unused_list;
下面我们具体看看这个结构体struct buffer_head,这个版本中这个结构体在fs.h中,后面的一些版本,在buffer_head.h中。
- 246 struct buffer_head {
- 247 /* First cache line: */
- 248 struct buffer_head *b_next; /* Hash queue list */
- 249 unsigned long b_blocknr; /* block number */
- 250 unsigned short b_size; /* block size */
- 251 unsigned short b_list; /* List that this buffer appears */
- 252 kdev_t b_dev; /* device (B_FREE = free) */
- 253
- 254 atomic_t b_count; /* users using this block */
- 255 kdev_t b_rdev; /* Real device */
- 256 unsigned long b_state; /* buffer state bitmap (see above) */
- 257 unsigned long b_flushtime; /* Time when (dirty) buffer should be written */
- 258
- 259 struct buffer_head *b_next_free;/* lru/free list linkage */
- 260 struct buffer_head *b_prev_free;/* doubly linked list of buffers */
- 261 struct buffer_head *b_this_page;/* circular list of buffers in one page */
- 262 struct buffer_head *b_reqnext; /* request queue */
- 263
- 264 struct buffer_head **b_pprev; /* doubly linked list of hash-queue */
- 265 char * b_data; /* pointer to data block */
- 266 struct page *b_page; /* the page this bh is mapped to */
- 267 void (*b_end_io)(struct buffer_head *bh, int uptodate); /* I/O completion */
- 268 void *b_private; /* reserved for b_end_io */
- 269
- 270 unsigned long b_rsector; /* Real buffer location on disk */
- 271 wait_queue_head_t b_wait;
- 272
- 273 struct list_head b_inode_buffers; /* doubly linked list of inode dirty buffers */
- 274 };
b_next:用于链接到块缓冲区的hash表
b_blocknr:本block的块号
b_size:block的大小
b_list:表示当前的这个buffer在那个链表中
b_dev:虚拟设备标识
b_count:引用计数(几个人在使用这个buffer)
b_rdev:真实设备标识
b_state:状态位图,如下:
- 212 /* bh state bits */
- 213 enum bh_state_bits {
- 214 BH_Uptodate, /* 如果缓冲区包含有效数据则置1 */
- 215 BH_Dirty, /* 如果buffer脏(存在数据被修改情况),那么置1 */
- 216 BH_Lock, /* 如果缓冲区被锁定,那么就置1 */
- 217 BH_Req, /* 如果缓冲区无效就置0 */
- 218 BH_Mapped, /* 如果缓冲区有一个磁盘映射就置1 */
- 219 BH_New, /* 如果缓冲区是新的,而且没有被写出去,那么置1 */
- 220 BH_Async, /* 如果缓冲区是进行end_buffer_io_async I/O 同步则置1 */
- 221 BH_Wait_IO, /* 如果要将这个buffer写回,那么置1 */
- 222 BH_Launder, /* 如果需要重置这个buffer,那么置1 */
- 223 BH_Attached, /* 1 if b_inode_buffers is linked into a list */
- 224 BH_JBD, /* 如果和 journal_head 关联置1 */
- 225 BH_Sync, /* 如果buffer是同步读取置1 */
- 226 BH_Delay, /* 如果buffer空间是延迟分配置1 */
- 227
- 228 BH_PrivateStart,/* not a state bit, but the first bit available
- 229 * for private allocation by other entities
- 230 */
- 231 };
- 232
b_next_free:指向lru链表中next元素
b_prev_free:指向链表上一个元素
b_this_page:连接到同一个page中的那个链表
b_reqnext:请求队列
b_pprev:hash队列双向链表
data:指向数据块的指针
b_page:这个buffer映射的页面
b_end_io:IO结束时候执行函数
b_private:保留
b_rsector:缓冲区在磁盘上的实际位置
b_inode_buffers:inode脏缓冲区循环链表
3、关于VFS怎么去管理几个buffer cache的链表,如下:
》 hash表:用于管理包含有效数据的buffer,在定位buffer的时候很快捷。哈希索引值由数据块号以及其所在的设备标识号计算(散列)得到。
关于这段hash代码如下:
- <span style="font-size:14px;">539 /* After several hours of tedious analysis, the following hash
- 540 * function won. Do not mess with it... -DaveM
- 541 */
- 542 #define _hashfn(dev,block) \
- 543 ((((dev)<<(bh_hash_shift - 6)) ^ ((dev)<<(bh_hash_shift - 9))) ^ \
- 544 (((block)<<(bh_hash_shift - 6)) ^ ((block) >> 13) ^ \
- 545 ((block) << (bh_hash_shift - 12))))</span>
当我们在一个具有的文件系统中,当我们需要读取一块数据的时候,需要调用bread函数(面包?ヾ(。`Д´。),应该是buffer read的缩写吧。。。)。
如下:
- 1181 /**
- 1182 * bread() - reads a specified block and returns the bh
- 1183 * @block: number of block 块号
- 1184 * @size: size (in bytes) to read 需要读取的size
- 1185 *
- 1186 * Reads a specified block, and returns buffer head that
- 1187 * contains it. It returns NULL if the block was unreadable. 返回一个包含这个block的buffer
- 1188 */
- 1189 struct buffer_head * bread(kdev_t dev, int block, int size)
- 1190 {
- 1191 struct buffer_head * bh;
- 1192
- 1193 bh = getblk(dev, block, size); /* 找到这个buffer */
- 1194 if (buffer_uptodate(bh)) /* 判断是否存在有效数据,如果存在那么直接返回即可 */
- 1195 return bh;
- 1196 set_bit(BH_Sync, &bh->b_state); /* 如果不存在有效数据,将这个buffer设置成同步状态 */
- 1197 ll_rw_block(READ, 1, &bh); /* 如果没有,那么需要从磁盘中读取这个block到buffer中,这个是一个底层的读取操作 */
- 1198 wait_on_buffer(bh); /* 等待buffer的锁打开 */
- 1199 if (buffer_uptodate(bh)) /* 理论上这个时候应该是存在有效数据的了,直接返回就可以 */
- 1200 return bh;
- 1201 brelse(bh);
- 1202 return NULL;
- 1203 }
第一:通过dev号+block号找到相应的buffer,使用函数getblk,如下:
- 1013 struct buffer_head * getblk(kdev_t dev, int block, int size)
- 1014 {
- 1015 for (;;) {
- 1016 struct buffer_head * bh;
- 1017
- 1018 bh = get_hash_table(dev, block, size); /* 关键函数,得到hash表中的buffer */
- 1019 if (bh) {
- 1020 touch_buffer(bh);
- 1021 return bh; /* 返回这个buffer */
- 1022 }
- 1023 /* 如果没有找到对应的buffer,那么试着去增加一个buffer,就是使用下面的grow_buffers函数 */
- 1024 if (!grow_buffers(dev, block, size))
- 1025 free_more_memory();
- 1026 }
- 1027 }
简单看一下这个查找buffer函数:get_hash_table
- 628 struct buffer_head * get_hash_table(kdev_t dev, int block, int size)
- 629 {
- 630 struct buffer_head *bh, **p = &hash(dev, block); /* 首先通过hash值得到对应的位置,这个函数h很easy */
- 631 /* 其实就是 #define hash(dev,block) hash_table[(_hashfn(HASHDEV(dev),block) & bh_hash_mask)]。hashfn函数上面已经说过了,就是通过hash值得到buffer*/
- 632 read_lock(&hash_table_lock);
- 633
- 634 for (;;) { /* 下面就是判断这个得到的buffer数组中有没有我们需要的buffer */
- 635 bh = *p;
- 636 if (!bh)
- 637 break;
- 638 p = &bh->b_next;
- 639 if (bh->b_blocknr != block)
- 640 continue;
- 641 if (bh->b_size != size)
- 642 continue;
- 643 if (bh->b_dev != dev)
- 644 continue;
- 645 get_bh(bh); /* 如果有那么直接执行这个函数,这个函数很easy,其实就是增加一个使用计数器而已: atomic_inc(&(bh)->b_count);*/
- 646 break;
- 647 }
- 648
- 649 read_unlock(&hash_table_lock);
- 650 return bh;
- 651 }
如果没找到对应的buffer,那么使用grow_buffers函数增加一个新的buffer,看函数:
- 2596 /*
- 2597 * Try to increase the number of buffers available: the size argument
- 2598 * is used to determine what kind of buffers we want.
- 2599 */
- 2600 static int grow_buffers(kdev_t dev, unsigned long block, int size)
- 2601 {
- 2602 struct page * page;
- 2603 struct block_device *bdev;
- 2604 unsigned long index;
- 2605 int sizebits;
- 2606
- 2607 /* Size must be multiple of hard sectorsize */
- 2608 if (size & (get_hardsect_size(dev)-1))
- 2609 BUG();
- 2610 /* Size must be within 512 bytes and PAGE_SIZE */
- 2611 if (size < 512 || size > PAGE_SIZE)
- 2612 BUG();
- 2613
- 2614 sizebits = -1;
- 2615 do {
- 2616 sizebits++;
- 2617 } while ((size << sizebits) < PAGE_SIZE);
- 2618
- 2619 index = block >> sizebits;
- 2620 block = index << sizebits;
- 2621
- 2622 bdev = bdget(kdev_t_to_nr(dev));
- 2623 if (!bdev) {
- 2624 printk("No block device for %s\n", kdevname(dev));
- 2625 BUG();
- 2626 }
- 2627
- 2628 /* Create a page with the proper size buffers.. */
- 2629 page = grow_dev_page(bdev, index, size);
- 2630
- 2631 /* This is "wrong" - talk to Al Viro */
- 2632 atomic_dec(&bdev->bd_count);
- 2633 if (!page)
- 2634 return 0;
- 2635
- 2636 /* Hash in the buffers on the hash list */
- 2637 hash_page_buffers(page, dev, block, size);
- 2638 UnlockPage(page);
- 2639 page_cache_release(page);
- 2640
- 2641 /* We hashed up this page, so increment buffermem */
- 2642 atomic_inc(&buffermem_pages);
- 2643 return 1;
- 2644 }
- 2645
第二:如果没有找到需要的buffer,那么执行底层读取函数ll_rw_block将数据从磁盘去读进来,这个函数在/source/drivers/block/ll_rw_blk.c中,具体的代码不看了。
OK,至此,寻找一个我们需要的buffer就结束了。
》 LRU链表
对于每一种不同缓冲区都会使用一个LRU来管理未使用的有效缓冲区
Ps:缓冲区类型如下:
- 1152 #define BUF_CLEAN 0
- 1153 #define BUF_LOCKED 1 /* Buffers scheduled for write */
- 1154 #define BUF_DIRTY 2 /* Dirty buffers, not yet scheduled for write */
这个三种链表怎么得到的呢,看代码也知道是吻合的,看LRU的声明:static struct buffer_head *lru_list[NR_LIST];
再看:#define NR_LIST 3,OK
当我们需要寻找一块buffer的时候,如果发现buffer在缓冲区中,且在LRU链表中,那么从LRU表中删除。
结合上面的一个hash链表,基本过程就是:
首先呢在hash表中寻找,如果找到,那就OK,如果没有找到,那么需要分配新的buffer,如果分到,那么加载数据进来,继续...如果没有足够的空间分配,那么, 需要将LRU中一个取出(LRU链首元素),先看是否置了“脏”位,如已置,则将它的内容写回磁盘。然后清空内容,将它分配给新的数据块。
在缓冲区使用完了后,将它的b_count域减1,如果b_count变为0,则将它放在某个LRU链尾,表示该缓冲区已可以重新利用。
unused_list 用于辅助就不多说了~~~
六、
在文件系统中,有三大缓冲为了提升效率:inode缓冲区、dentry缓冲区、块缓冲。
(内核:2.4.37)
为什么这个缓冲区会存在,不好意思,我说了废话,当然和前面一样的,为了提升效率,例如我们写一个.c的helloworld文件,简单的过程是编辑,编译,执行。。。那么这个过程都是需要找到所在的文件位置的,如果每次都从根开始找并且还有构造相应的目录项对象,是很费时的,所以将目录项一般也都是缓存起来的~~~
Ps:dentry结构
- 67 struct dentry {
- 68 atomic_t d_count;
- 69 unsigned int d_flags;
- 70 struct inode * d_inode; /* Where the name belongs to - NULL is negative */
- 71 struct dentry * d_parent; /* parent directory */
- 72 struct list_head d_hash; /* lookup hash list */
- 73 struct list_head d_lru; /* d_count = 0 LRU list */
- 74 struct list_head d_child; /* child of parent list */
- 75 struct list_head d_subdirs; /* our children */
- 76 struct list_head d_alias; /* inode alias list */
- 77 int d_mounted;
- 78 struct qstr d_name;
- 79 unsigned long d_time; /* used by d_revalidate */
- 80 struct dentry_operations *d_op;
- 81 struct super_block * d_sb; /* The root of the dentry tree */
- 82 unsigned long d_vfs_flags;
- 83 void * d_fsdata; /* fs-specific data */
- 84 unsigned char d_iname[DNAME_INLINE_LEN]; /* small names */
- 85 };
和前面的一样,这个也涉及到几个相应的链表来管理,那么看看/fs/dcache.c中哪些链表被定义了。
- 52 static struct list_head *dentry_hashtable;
- 53 static LIST_HEAD(dentry_unused);
哈希链表 :从中能够快速获取与给定的文件名和目录名对应的目录项对象。
“未使用”链表:所有未使用 目录项对象都存放在一个LRU的双向链表。LRU链表的首元素和尾元素的地址存放在变量dentry_unused中的next 域和prev域中。目录项对象的d_lru域包含的指针指向该链表中相邻目录的对象。
简单的看一下dcache初始化过程:
- 1181 static void __init dcache_init(unsigned long mempages)
- 1182 {
- 1183 struct list_head *d;
- 1184 unsigned long order;
- 1185 unsigned int nr_hash;
- 1186 int i;
- 1187
- 1188 /*
- 1189 * A constructor could be added for stable state like the lists,
- 1190 * but it is probably not worth it because of the cache nature
- 1191 * of the dcache.
- 1192 * If fragmentation is too bad then the SLAB_HWCACHE_ALIGN
- 1193 * flag could be removed here, to hint to the allocator that
- 1194 * it should not try to get multiple page regions.
- 1195 */
- 1196 dentry_cache = kmem_cache_create("dentry_cache",
- 1197 sizeof(struct dentry),
- 1198 0,
- 1199 SLAB_HWCACHE_ALIGN,
- 1200 NULL, NULL);
- 1201 if (!dentry_cache)
- 1202 panic("Cannot create dentry cache");
- 1203
- 1204 #if PAGE_SHIFT < 13
- 1205 mempages >>= (13 - PAGE_SHIFT);
- 1206 #endif
- 1207 mempages *= sizeof(struct list_head);
- 1208 for (order = 0; ((1UL << order) << PAGE_SHIFT) < mempages; order++)
- 1209 ;
- 1210
- 1211 do {
- 1212 unsigned long tmp;
- 1213
- 1214 nr_hash = (1UL << order) * PAGE_SIZE /
- 1215 sizeof(struct list_head);
- 1216 d_hash_mask = (nr_hash - 1);
- 1217
- 1218 tmp = nr_hash;
- 1219 d_hash_shift = 0;
- 1220 while ((tmp >>= 1UL) != 0UL)
- 1221 d_hash_shift++;
- 1222
- 1223 dentry_hashtable = (struct list_head *)
- 1224 __get_free_pages(GFP_ATOMIC, order);
- 1225 } while (dentry_hashtable == NULL && --order >= 0);
- 1226
- 1227 printk(KERN_INFO "Dentry cache hash table entries: %d (order: %ld, %ld bytes)\n",
- 1228 nr_hash, order, (PAGE_SIZE << order));
- 1229
- 1230 if (!dentry_hashtable)
- 1231 panic("Failed to allocate dcache hash table\n");
- 1232
- 1233 d = dentry_hashtable;
- 1234 i = nr_hash;
- 1235 do {
- 1236 INIT_LIST_HEAD(d);
- 1237 d++;
- 1238 i--;
- 1239 } while (i);
- 1240 }
上面代码就是相当于分配cache空间,并将hash表什么的都初始化了~~~
下面看一下怎么分配一个目录项对象,涉及函数d_alloc:
- 580 /**
- 581 * d_alloc - allocate a dcache entry
- 582 * @parent: parent of entry to allocate
- 583 * @name: qstr of the name
- 584 *
- 585 * Allocates a dentry. It returns %NULL if there is insufficient memory
- 586 * available. On a success the dentry is returned. The name passed in is
- 587 * copied and the copy passed in may be reused after this call.
- 588 */
- 589
- 590 struct dentry * d_alloc(struct dentry * parent, const struct qstr *name)
- 591 {
- 592 char * str;
- 593 struct dentry *dentry;
- 594
- 595 dentry = kmem_cache_alloc(dentry_cache, GFP_KERNEL); /* 分配一个dentry空间 */
- 596 if (!dentry)
- 597 return NULL;
- 598
- 599 if (name->len > DNAME_INLINE_LEN-1) {
- 600 str = kmalloc(NAME_ALLOC_LEN(name->len), GFP_KERNEL);
- 601 if (!str) {
- 602 kmem_cache_free(dentry_cache, dentry);
- 603 return NULL;
- 604 }
- 605 } else
- 606 str = dentry->d_iname;
- 607 /* 复制name */
- 608 memcpy(str, name->name, name->len);
- 609 str[name->len] = 0;
- 610 /* 下面根据dentr的字段进行赋值,具体的字段意义见:http://blog.csdn.net/shanshanpt/article/details/38943731 */
- 611 atomic_set(&dentry->d_count, 1);
- 612 dentry->d_vfs_flags = 0;
- 613 dentry->d_flags = 0;
- 614 dentry->d_inode = NULL;
- 615 dentry->d_parent = NULL;
- 616 dentry->d_sb = NULL;
- 617 dentry->d_name.name = str;
- 618 dentry->d_name.len = name->len;
- 619 dentry->d_name.hash = name->hash;
- 620 dentry->d_op = NULL;
- 621 dentry->d_fsdata = NULL;
- 622 dentry->d_mounted = 0;
- 623 INIT_LIST_HEAD(&dentry->d_hash);
- 624 INIT_LIST_HEAD(&dentry->d_lru);
- 625 INIT_LIST_HEAD(&dentry->d_subdirs);
- 626 INIT_LIST_HEAD(&dentry->d_alias);
- 627 if (parent) {
- 628 dentry->d_parent = dget(parent);
- 629 dentry->d_sb = parent->d_sb;
- 630 } else
- 631 INIT_LIST_HEAD(&dentry->d_child);
- 632
- 633 spin_lock(&dcache_lock);
- 634 if (parent)
- 635 list_add(&dentry->d_child, &parent->d_subdirs);
- 636 dentry_stat.nr_dentry++;
- 637 spin_unlock(&dcache_lock);
- 638
- 639 return dentry;
- 640 }
- 641
下面看看怎么去寻找一个目录,涉及函数d_lookup:
- 698 /**
- 699 * d_lookup - search for a dentry
- 700 * @parent: parent dentry
- 701 * @name: qstr of name we wish to find
- 702 *
- 703 * Searches the children of the parent dentry for the name in question. If
- 704 * the dentry is found its reference count is incremented and the dentry
- 705 * is returned. The caller must use d_put to free the entry when it has
- 706 * finished using it. %NULL is returned on failure.
- 707 */
- 708
- 709 struct dentry * d_lookup(struct dentry * parent, struct qstr * name)
- 710 {
- 711 unsigned int len = name->len;
- 712 unsigned int hash = name->hash;
- 713 const unsigned char *str = name->name;
- 714 struct list_head *head = d_hash(parent,hash); /* 通过hash值计算得到目录项缓冲区位置的head */
- 715 struct list_head *tmp;
- 716
- 717 spin_lock(&dcache_lock);
- 718 tmp = head->next;
- 719 for (;;) { /* 下面循环找到对应的dentry */
- 720 struct dentry * dentry = list_entry(tmp, struct dentry, d_hash);
- 721 if (tmp == head)
- 722 break;
- 723 tmp = tmp->next;
- 724 if (dentry->d_name.hash != hash)
- 725 continue;
- 726 if (dentry->d_parent != parent)
- 727 continue;
- 728 if (parent->d_op && parent->d_op->d_compare) {
- 729 if (parent->d_op->d_compare(parent, &dentry->d_name, name))
- 730 continue;
- 731 } else {
- 732 if (dentry->d_name.len != len)
- 733 continue;
- 734 if (memcmp(dentry->d_name.name, str, len))
- 735 continue;
- 736 }
- 737 __dget_locked(dentry);
- 738 dentry->d_vfs_flags |= DCACHE_REFERENCED; /* 找到,那么添加引用就OK */
- 739 spin_unlock(&dcache_lock);
- 740 return dentry; /* 返回找到的dentry。里面有我们需要的信息例如inode */
- 741 }
- 742 spin_unlock(&dcache_lock);
- 743 return NULL;
- 744 }
其他的代码暂时就不看了,以后总结。。。















 3437
3437

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









