






Python实战:腾讯视频弹幕
通过 Python 获取腾讯视频弹幕
网页分析
在腾讯视频网站,打开电视剧,播放任意一集,查看浏览器地址栏中的 url,这个 url 由电视剧的id和每一集的id组成。
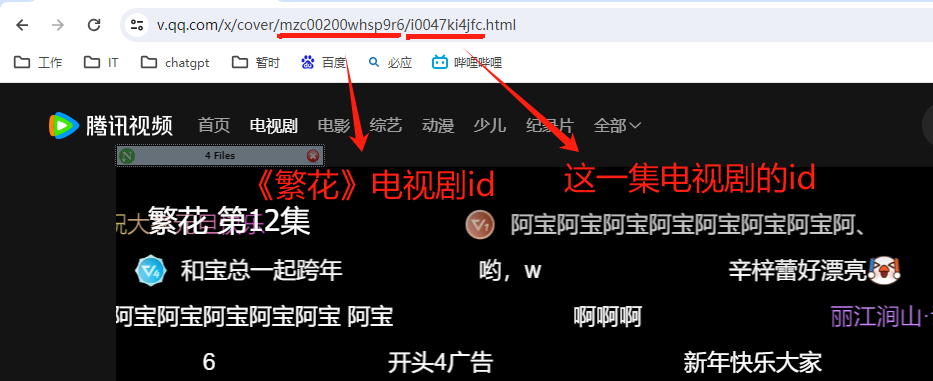
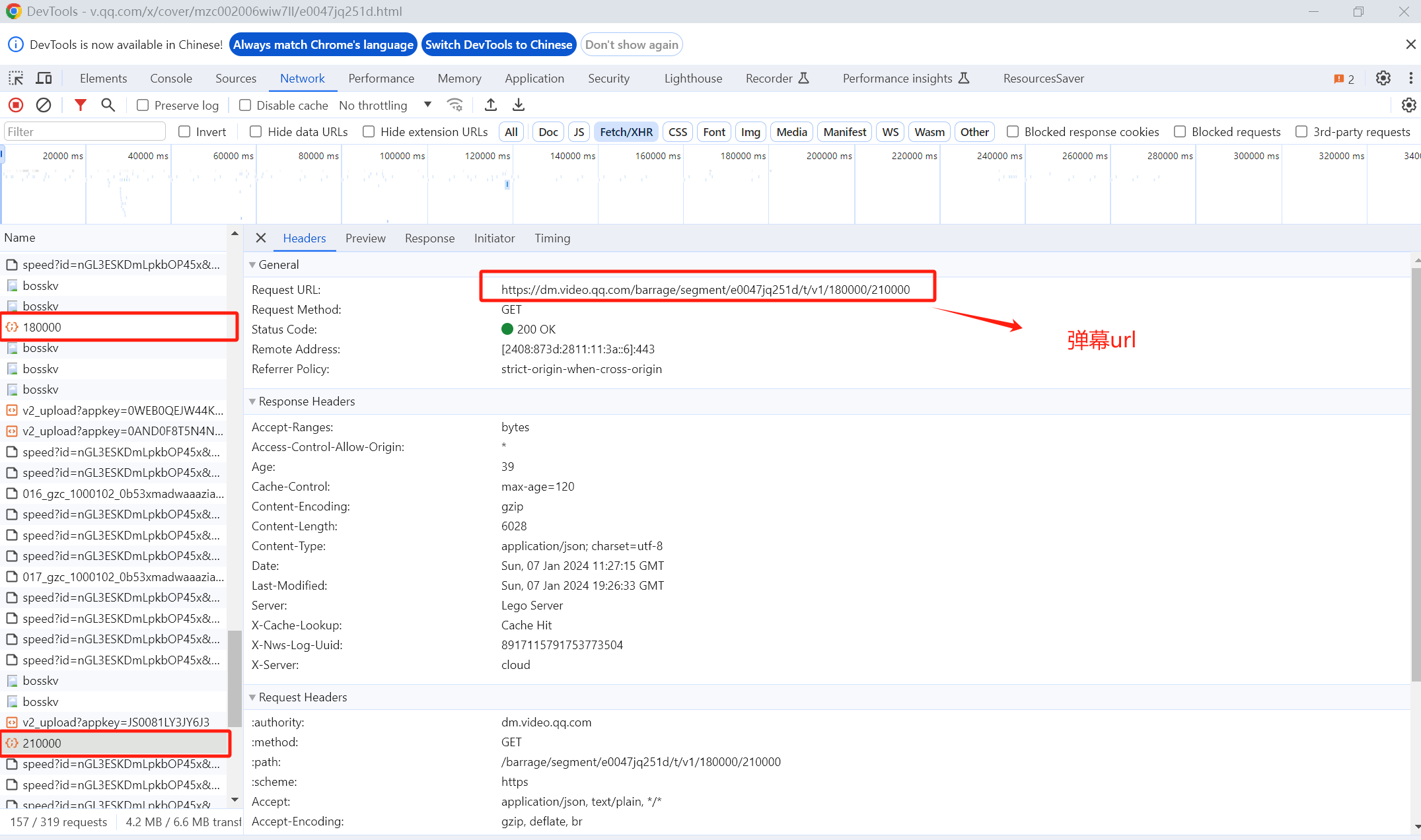
继续播放视频,打开开发者工具,查看 Network 中的请求,其中红框中的180000、210000之类的就是弹幕请求。
查看分析弹幕 url,例如:
https://dm.video.qq.com/barrage/segment/e0047jq251d/t/v1/150000/180000,
是由https://dm.video.qq.com/barrage/segment/拼接e0047jq251d,再拼接/t/v1/,再拼接150000/180000组成。
其中e0047jq251d 是 这一集电视剧id,150000/180000是递增 30000 的参数。
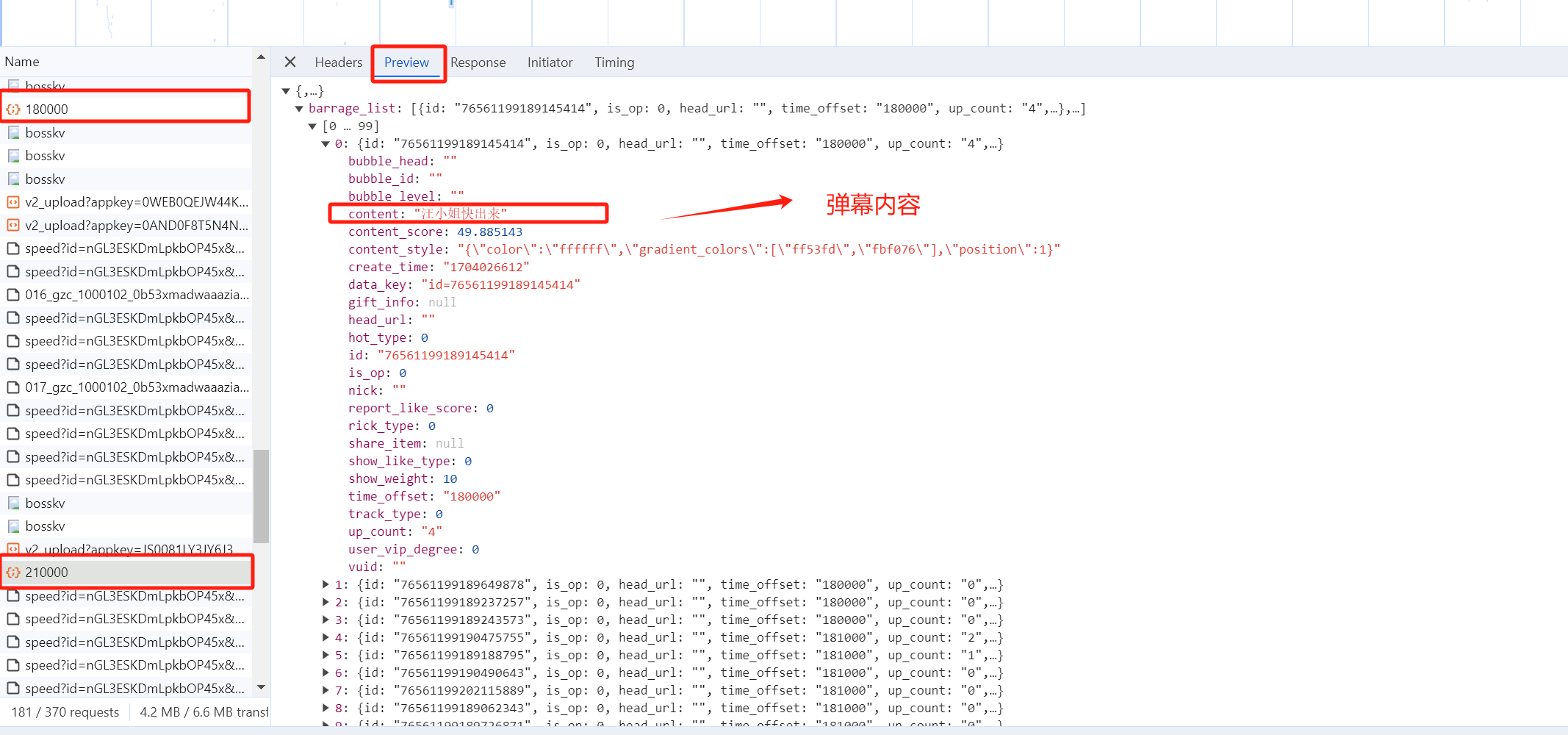
查看弹幕请求的Preview或者Response,可以看出返回的 json 格式的数据,也可以很容易通过代码提前出来。
分析完成,接下来写 Python 代码就简单了。
获取弹幕
通过分析弹幕 url 规律,构造请求地址,放入爬虫中运行就可以获得一集电视剧的弹幕。可以将弹幕字段保存到 csv 文件中,方便后续进行数据处理分析。
Python 代码如下:
#(本文首发在“程序员coding”公众号)
import requests
import pandas as pd
# episodes_danmu_DataFrame是存放一集所有弹幕的DataFrame
episodes_danmu_DataFrame = pd.DataFrame()
# 填写腾讯视频的参数,video_code是腾讯视频的编号,num是获取弹幕的次数,step是步进参数
video_code = "c004725utxa"
num = 10000 # 设置一个较大的请求次数,程序会自动判断,当没有弹幕了会自动退出循环
step = 30000
# 循环num次获取弹幕
for i in range(num):
url = f'https://dm.video.qq.com/barrage/segment/{video_code}/t/v1/{i * 30000}/{i * 30000 + step}'
response = requests.get(url=url).json()
if (len(response["barrage_list"])) > 0:
# temp_danmu_DataFrame是存放本次弹幕的DataFrame
temp_danmu_DataFrame = pd.json_normalize(response['barrage_list'], errors='ignore')
episodes_danmu_DataFrame = pd.concat([episodes_danmu_DataFrame, temp_danmu_DataFrame])
print("第", i + 1, "次请求弹幕,请求地址为:", url, "获取到:", temp_danmu_DataFrame.shape[0],
"条弹幕,这一集总弹幕已获取到", episodes_danmu_DataFrame.shape[0], "条。")
else:
break
print("总共获取到", episodes_danmu_DataFrame.shape[0], "条弹幕")
# 查看 DataFrame 的行数和列数。
rows = episodes_danmu_DataFrame.shape
print("请求得到的表格行数与列数:", rows)
# 将 DataFrame 保存为 csv 文件
# 选择保存的列
episodes_danmu_DataFrame = episodes_danmu_DataFrame.loc[:, ['time_offset', 'create_time', 'content']]
episodes_danmu_DataFrame.to_csv(f"腾讯视频弹幕-繁花-{episodes_danmu_DataFrame.shape[0]}条弹幕.csv", mode='w',
encoding="utf-8", errors='ignore', index=False)
print("弹幕保存完成!")
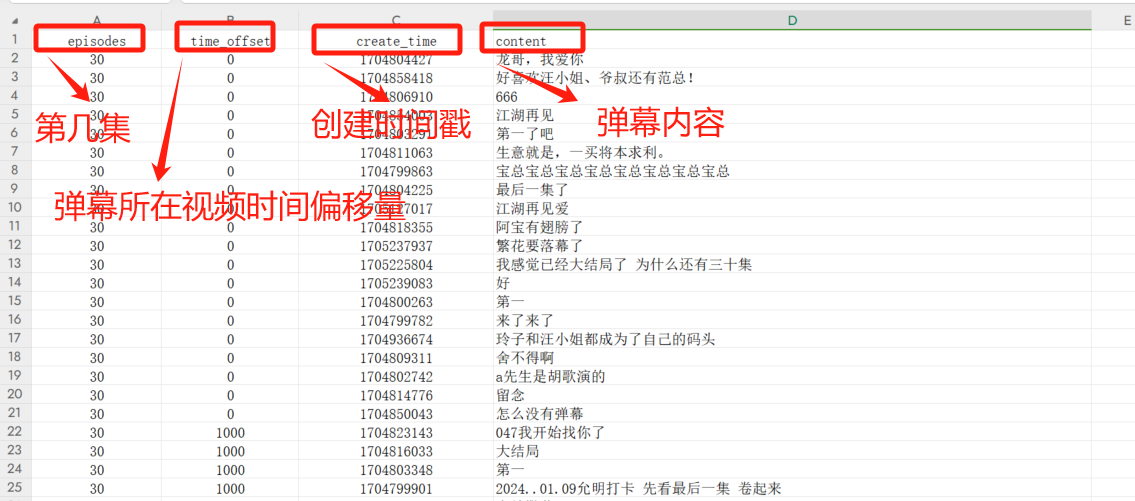
本文首发在“程序员coding”公众号,完整代码已经上传在公众号文章中。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









