







词项和全文检索
Term
表达语义的最小单位,在Es中,对于Term的查询,对输入不做分词,会将输入作为一个整体,在倒排索引中查找准确的词项,并计算词项在该文档中算分 可以通过Constant Score将该查询转换为Filtering,避免算分,利用缓存,提高性能
全文检索
索引和搜索时,都会分词,查询字符串先传递到一个合适的分词器,然后生成一个供查询的此项列表
查询时候,先会对输入的查询进⾏分词,然后每个词项逐个进⾏底层的查询,最终将结果进行合并。并为每个文档生成一个算分
检索过程:
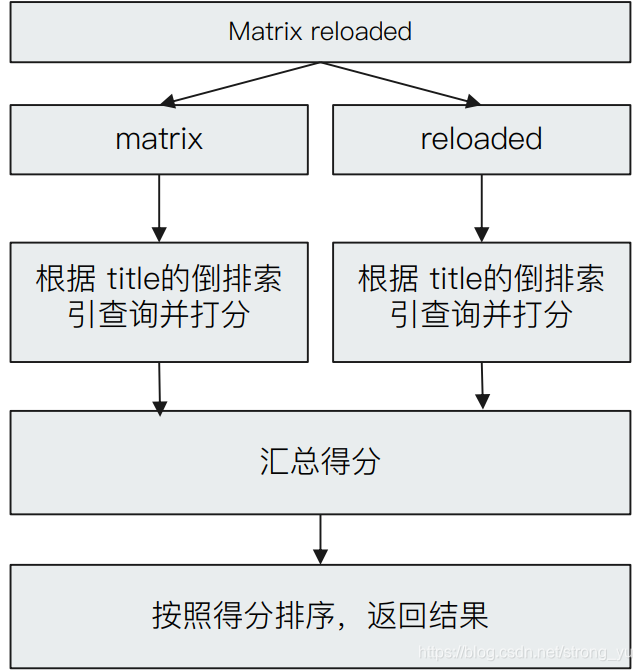
结构化搜索
布尔,时间,日期和数字这类结构化数据:有精确的格式,我们可以对这些格式进⾏行行逻辑操作。包括⽐较数字或时间的范围,或判定两个值的大小。
结构化的文本也可以做精确匹配或者部分匹配
- Term 查询 / Prefix 前缀查询
结构化结果只有“是”或“否”两个值
根据场景需要,可以决定结构化搜索是否需要打分可以通过Constant Score,将查询转为Filtering
使⽤用 Exist 查询处理理⾮非空 Null 值
精确值 & 多值字段的精确值查找
Term 查询是包含,不不是完全相等。针对多值字段查询要尤其注意
Query&Filtering与多字符串串多字段查询
对于多项文本的搜索,在Elasticsearch中,有Query和Filter两种不同
的Context
QueryContext:相关性算分
FilterContext:不需要算分,可以利⽤Cache, 获得更好的性能
boolQuery
⼀个bool查询,是一个或者多个查询子句的组合,包括四种子句
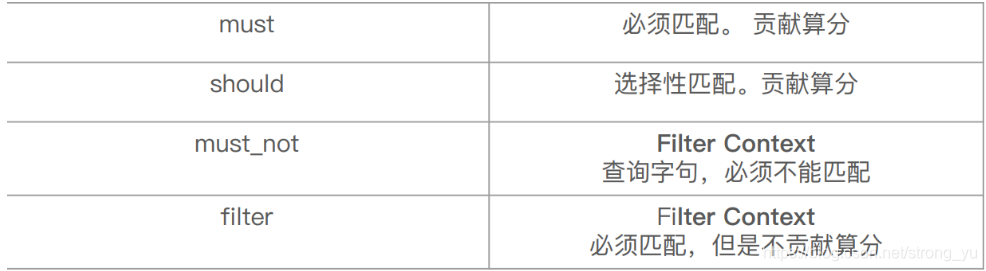
Boosting
Boosting是控制相关度的⼀种手段,索引,字段或查询子条件
参数 boost的含义:
当 boost > 1 时,打分的相关度相对性提升
当 0 < boost < 1 时,打分的权重相对性降低
当 boost < 0 时,贡献负分
单字符串串多字段查询:DisMaxQuery
对于一个字符串在多个字段中查询,会出现算分错误,单字符串在多个字段中查询的过程如下:
比如在两个字段中查询
- 查询 should 语句句中的两个查询
- 加和两个查询的评分
- 乘以匹配语句句的总数
- 除以所有语句句的总数
这种就不是我们想要的结果,DisMaxQuery就是解决这种问题的
DisMaxQuery的过程:
将任何与任一查询匹配的文档作为结果返回。采用字段上最匹配的评分最终评分返回
tie_breaker
有时候同时多个字段都会匹配到该字符串,但是DisMaxQuery只会按照单字段匹配的分数返回,如果想要考虑其它字段的匹配度,那么就可以使用tie_breaker参数来设置,TierBreaker 是一个介于 0-1 之间的浮点数。0
代表使⽤用最佳匹配;1代表所有语句句同等重要
计算过程:
- 获得最佳匹配语句的评分_score
- 将其他匹配语句的评分与tie_breaker相乘
- 对以上评分求和并规范化
单字符串串多字段查询:Multi Match
分为三种情况,最佳字段、多数字段、混合字段
最佳字段 (Best Fields)
当字段之间相互竞争,⼜相互关联,只取匹配度最高的字段来打分
多数字段 (Most Fields):
多个字段都会匹配 、
混合字段 (Cross Field)
跨字段查询,例如,一个地址在多个字段中,可以使用copy_to来解决















 1754
1754











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









