






 本文详细解释了IP头部TOS字段的两种使用方式:传统的DSCP方式和更先进的ECN方式。重点介绍了DSCP的分类以及ECN在拥塞控制中的角色,包括TCP的拥塞控制机制和路由器的优化策略,以及TCP头部如何支持ECN协商和响应。
本文详细解释了IP头部TOS字段的两种使用方式:传统的DSCP方式和更先进的ECN方式。重点介绍了DSCP的分类以及ECN在拥塞控制中的角色,包括TCP的拥塞控制机制和路由器的优化策略,以及TCP头部如何支持ECN协商和响应。
IP头部的TOS字段,占据IP头的第二字节,它有两种利用方式。
第一种是传统方式,是默认的,在RFC791,1349中定义这种方式的格式。
第二种是DSCP方式,是在RFC2474、3168中定义的格式。这种方式需要开启才能使用,开启后,同时支持ECN。
一、第一种方式
如图所示,将8bit分成三段,最后一段占1bit,保留不用设为0。
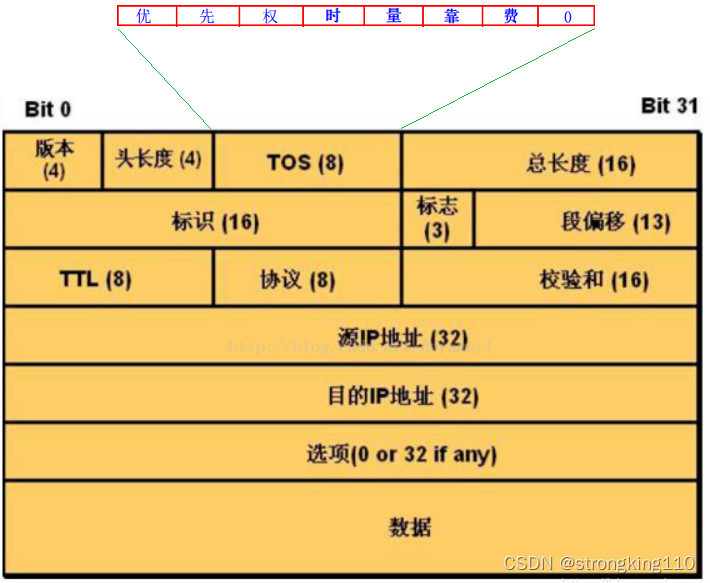
3 bit的优先权字段(现在已被大多数路由器忽略),一般代表流量的业务类型,是在RFC791定义的。
该字段可以通过setsockopt进行配置,比如:
uint proiority = 3;
setsockopt(m_socket, SOL_SOCKET, SO_PRIORITY, &priority, sizeof(priority));
后面的4位性能指标,分别代表最小时延、最大吞吐量、最高可靠性和最小费用,是在RFC1349中定义的。
它们也可以通过setsockopt进行配置,比如:
unsigned char service_type = 0xe0 | IPTOS_LOWDELAY | IPTOS_RELIABILITY;
setsockopt(sock, SOL_IP, IP_TOS, (void *)&service_type, sizeof(service_type));
不管是precedence还是性能指标,包括后面的dscp,都是给路由器看的,路由器根据标志区别对待。
二、第二种方式
这种方式,在Linux下通过下面的函数开启:
setsockopt(s32sockfd, SOL_IP,IP_TOS,&U32DSCP,sizeof(U32));
这种方式下,TOS字节分成两段
一段是DSCP,格式在RFC2474中定义,这一段的用途,是按流量类型进行区分服务。
另一段是ECN,格式在RFC3168中定义,这一段的用途,是为了进行更先进的拥塞控制。
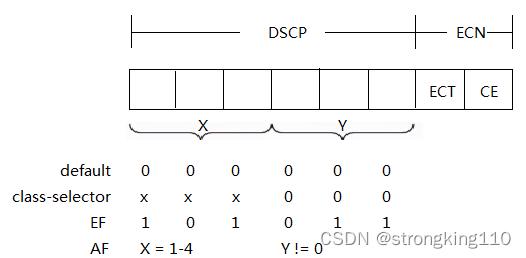
(一)DSCP部分
这部分占6位,分成X、Y两段,各3位。根据X和Y的不同取值组合,DSCP分成4类
Default类
TOS 6 bit全部为0
Class-Selector类
该类目的是向前兼容Precendence
X不能为0,可能取值1-7
Y必须为0
EF类
X=5,Y=3的恒定值。对应语音流量
AF类
X值不能为0(用到了1-4),Y不能为0
X代表优先级,值越大,优先级越高
Y为丢弃优先级,Y越高丢弃概率越大
(二)ECN部分
1、背景
前面说到,这一部分用于更先进的拥塞控制。
之所以说更先进,是由于TCP早期的拥塞控制机制,只是靠接收方和发送方,自己感知并进行决策,没有中间路由器什么事,当路由器缓存队列过载之后,只是简单的丢弃报文。这种机制的最大缺陷在于,能够直接感知发生拥塞的路由器,却不能参与发方和收方的拥塞控制过程。
2、TCP重传和快速重传机制
1)分组丢失是判断路由器出现拥塞的依据。分组丢失的依据:一是超时,二是3个连续的确认(对同一个发包)。
2)超时重传
当拥塞发生时,路由器会丢包,发送方就收不到ACK,于是该包的计时器会超时,需要重发。至于计时器设置的时间长度,针对同一个包,分两种情况。
如果是新发包(假设这次是第N个发包),其超时时长按2倍预估RTT计算,预估RTT的计算方法是前面N-2次的RTT均值和第N-1次的RTT按照不同权重求和。
如果是重发包,按照指数退避算法计算RTT,重发次数越多,RTT越高,超时值最高到64秒不再增加。
3)快速重传
当TCP接收方收到重复的3次ACK时,会认为被索要的报文段被网络丢弃,但由于收到的重复的3次ACK,则认为该报文段之后的三个报文已经被接收端收到,则不等待定时器超时,直接重发该报文段。
3、早期TCP拥塞控制机制
前面也提到,在早期,TCP的拥塞控制过程,路由器并没有直接参与,也就是说IP头TOS中的ECN在那时是没有的。
早期的拥塞控制,在TCP协议中,是通过几个一直在运行的算法来实现的。这几个算法,中心思想是即时控制发方的cwnd(发送窗口)的大小,主要涉及3个算法:
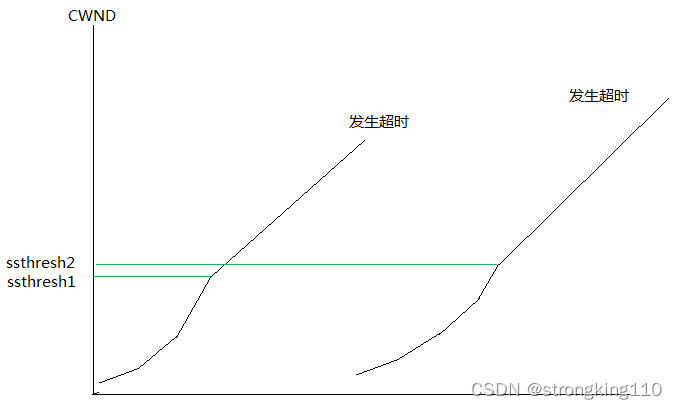
1)慢启动算法
此时,cwnd从一个初始值开始(一般是一个MSS大小),随着不断收到ACK,呈指数方式增长。以这种方式,是为了探测网络实际性能,也为了避免一开始就发送过多数据。
该阶段进行到当cwnd到达当前ssthresh时,不再继续,而是过渡为拥塞避免阶段。
2)拥塞避免算法
该阶段,cwnd呈线性方式增长。
至此,ssthresh的确定就成为了关键,它是在发生超时的情况下,按照当时的cwnd值的一半来更新的。
此时的cwnd新初始值,回到1个MSS大小,重新进行慢启动。
如果只有阶段1和阶段2的情况,则进行周期性的循环
导致慢启动重启的原因,是发生超时,发送方假定是中间路由器发生了拥塞,这与接收方无关。
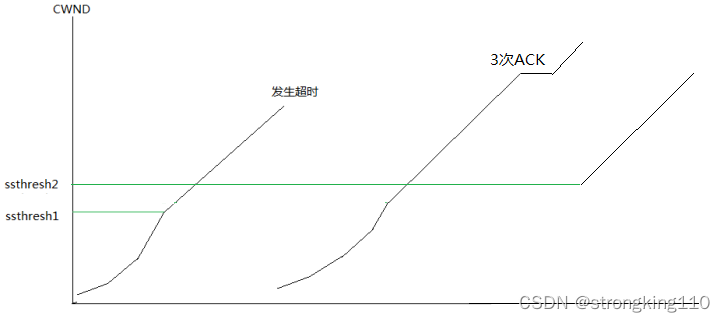
3)快速恢复算法
如果超时之前,发送方收到了同一个包的重复的3次ACK时(参见前面快速重传),拥塞控制不再按前面的阶段1和阶段2自然转变,而是立即更新ssthresh,也是按照当时的cwnd值的一半来更新。
而cwnd的即时值有一小段时间(3个发包)先按原线性方式增加,而后,立即更新到新ssthresh值,而不是从慢启动开始
导致发生快速恢复的原因是3次重复ACK,发方假定中间路由器发生丢包,但是通过收方回复的3个ACK来判断的。
4、路由器对拥塞的优化
为了避免自己的缓存队列过载,路由器一般实现了“随机早期侦测(Random Early Detection:RED)”功能,在过载之前(仍需要超出平均队列长度时),随机丢弃一些TCP报文,以避免所有通过的TCP连接全部同时超时。这样会导致一部分连接发生TCP超时,剩余部分则表现正常。
5、加上了ECN后的拥塞控制
1)原理
在开启了ECN机制后,当路由器发现缓存队列长度到达平均队列长度时,给途径的包打标记并进行转发,而不是丢弃,表示即将发生拥塞。发送方得知该消息后,主动放缓发送速率,避免出现拥塞。
ECN不是全新的拥塞控制机制,是在此前机制基础上,新增了一项功能,或者叫做优化。
2)IP头TOS字段的ECT和CE位的含义
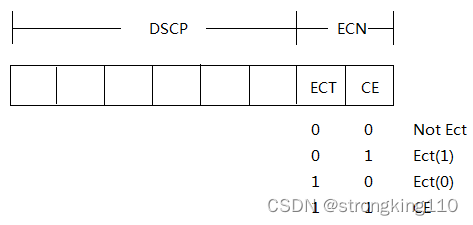
当拥塞发生时,如果ECT+CE取值00,则不采用ECN机制,而是用原来的RED机制,即丢弃该包
当拥塞发生时,如果取值为01或10,则路由器标记为11,表示该包打上了即将拥塞的标记,并继续转发该数据包到收方
3)TCP头对ECN机制的支持
前面提到,通过setsockopt开启DSCP时,同时开启ECN机制。为支持ECN,TCP头中新增了2个flags位CWR和ECE,如图所示
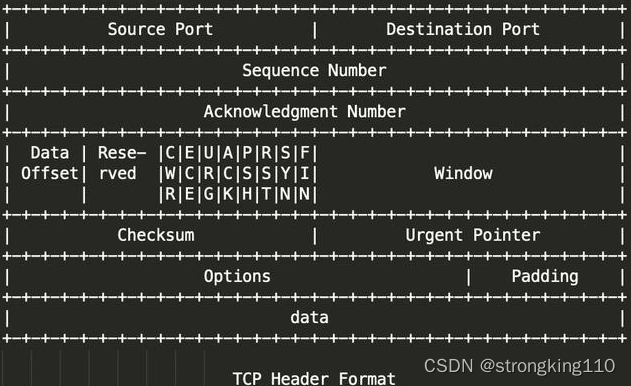
协商ECN机制
ECN机制的使用,需要收发双方协商一致。CWR和ECE的作用之一是实现协商。
在三次握手中,发方在SYN包中会置位CWR + ECE,如果收方支持,则回复SYN-ACK时置位ECE。
如果回复SYN-ACK不带ECE,协商失败,不能启用ECN机制
不支持ECN功能的主机,不能发起协商
ECN机制下传输普通数据
接下来,双方收发数据包时,会带ECN支持,路由器才能识别并打标记
当路由器标记了CE(ECN为11),收方接到该数据包,首先发现即将发生拥塞,于是在回复ACK时会打上ECE标记(以通知发方),并且此后一段时间,即使收到的包不带CE,ACK仍然维持ECE标记
发方收到带ECE的ACK,则主动将发送窗口缩小到一半,降低发送速率,并在发送新报文时,携带CWR位
收方接到带CWR的新包,后面ACK中不再继续使用ECE标记,直到下次收到标记了CE的包时,再此标记ECE
4)一些细节
• 如果发方所发的是一个纯ACK,则不能带ECN标记,即ECN必须是00,因为收方不会对纯ACK进行回复
• 即便一开始ECN协商没有成功,后续有收到CE标记的TCP报文,也要正确按照支持ECN处理,发出ECE置位的ACK包
• 一旦连接进入TIME-WAIT或CLOSED状态,ECN协商结果不可继承,必须重新协商
• 如果主机发送ECN协商的SYN包后,收到了RST,或者在SYN超时后重新发送。后续要重新发送一个普通ECE/CWR都不置位的SYN包,进行非ECN连接。
• TCP重传报文不允许设置ECN,防止DOS攻击。
• 收包窗口之外的报文应该忽略ECN位的处理,防止DOS攻击。
• TCP窗口探测报文不允许设置IP头ECT位或TCP CWR标记,窗口探测报文如果被置CE,接收端要按照ECN标准正确处理
• 窗口内只处理一次ECE报文,或者一个RTT周期内处理一次ECE。
• 如果TCP支持ECN,TCP发送端口不论什么原因导致的窗口减小,都要在窗口减小后发送的第一个包中将CWR置位,如果此CWR置位的包被丢弃。(对应重传定时器超时),发送端需要再次减小窗口并发送一个新的CWR置位的包,CWR置位的包不能是重传的包。
• 针对主机侧TCP仅有一端支持ECN功能时,支持ECN的TCP端需要先尝试进行ECN的协商,如果连接不成功,必须进行非ECN功能的TCP连接协商,以保证TCP的向后兼容性。
• TCP接收端在收到IP头的ECN=11时,但TCP序号不正确的报文,回应ACK时,不应该将ECE bit置位,以避免DOS攻击。
[注]
文中的代码部分未经验证
部分内容参考IP-ECN简介_ip ecn-CSDN博客

















 777
777

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









