







资料表明,在当今计算机上,排序占用计算机CPU时间已经高达30%—50%,排序是计算机程序设计中的一种基础性操作,研究以及掌握各种排序算法非常重要,今天就总结一下插入类的三种排序算法
下面主要是插入类排序算法的代码总结以及测试对比。其实描述一个算法用文字是相对比较抽象的,如果对这些算法不太熟悉,建议对于排序算法的具体学习推荐B站韩顺平老师讲的《数据结构与算法》,非常详细!
插入类排序
a.直接插入排序基本操作:将第i个记录插入到前面i-1已经排好的记录中。代码如下
// 直接插入排序算法
static void inSort(int r[]) {
int j;
int r0;
for (int i = 1; i < r.length; i++) {
// r0备份待插入的记录
r0 = r[i];
// 此时j指向前面有序序列的最后一个记录
j = i - 1;
// for循环寻找应该插入的位置
for (; j >= 0; j--) {
// 如果待插入的记录小于r[j],则将r[j]向后移
// 否则跳出循环
if (r0 < r[j]) {
r[j + 1] = r[j];
} else
break;
}
// 程序执行到这一步,意味着r0>r[j],则应该将r0赋给r[j+1]
r[j + 1] = r0;
}
}
最好的情况(顺序):待排序的数据为有序的序列,此时每次内部循环只执行一次,且不移动记录,时间复杂度为O(n)
最坏的情况(逆序):此时平均时间复杂度为O(n^2)
空间复杂度:在该算法当中,只需要一个辅助的空间r0,所以复杂度为O(1)
稳定性:稳定,待插入元素的比较是从后向前执行的,相同的关键字是没有必要进行交换的,所以相同的元素不会换到前面,所以是稳定的。
测试数据:(百万以上数据规模在该算法中过慢,没有纳入测试范围...)

b.折半插入排序:此算法对直接插入算法做了优化,因为,对于有序表进行折半查找,性能是优于顺序查找的,所以折半查找的思想可以用于有序记录r[0...j-1]。代码如下
//折半插入算法
static void halfInSort(int[] r) {
//定义三个边界下标值,分别记录插入的上界与下界
int low, high, mid;
//r0备份待插入的记录
int r0;
//从第二个记录开始遍历
for (int i = 1; i < r.length; i++) {
r0 = r[i];
low = 0;
high = i - 1;
//while循环寻找插入的位置,当low=high,即找到位置的时候跳出循环
while (low <= high) {
//mid为中间下标
mid = (low + high) / 2;
//如果待插入的记录小于中间值
if (r0 <= r[mid])
//则将上界往前一半调
high = mid - 1;
else
//否则将下界往上调
low = mid + 1;
}
//程序执行到这里,说明已经找到该插入的位置,即下标值为low的地方
for (int j = i - 1; j >= low; j--) {
//将low到i-1中间的元素全部向后移
r[j + 1] = r[j];
}
//元素移动完成之后,将待插入记录赋给r[low]
r[low] = r0;
}
}折半查找可以减少比较的次数,平均关键字比较次数为nlog2n,n较大的时候,折半查找会比直接插入排序的最差情况要好得多,但比其最好情况要差,由于该算法只是改善了比较次数,在最坏的情况下,比较时间复杂度为O(nlogn),但移动元素的时间消耗没有减少,所以总的时间复杂度为O(n^2),在最好情况下,不需要移动,时间复杂度为O(nlogn)。同理,该算法是稳定的,空间复杂度O(1)。
数据测试:
| 数据规模 | 1000 | 10000 | 100000 |
| 时间/s | 0.012324161 | 0.110314439 | 9.594870053 |
还是好了些的~
c.希尔排序:在直接插入排序中,如果较小的元素出现在后面,则需要花比较多的比较以及移动次数才能将其移到前面,效率比较低,而希尔排序可以通过增量解决这个问题,即使小的元素在后面,也能够“跳”到前面。
个人理解,这是一种“宏观调控”的排序算法,先将待排序的序列分割成若干个“较稀疏”的子序列,对这些子序列进行直接插入排序。然后经过这样的调整,,整个序列已经基本有序了,最后对全部记录进行最后一次直接插入排序,利用了直接插入排序算法的最好情况。代码如下
public static void shellInsort(int[] r) {
int r0;
int j;
//delta为增量,这里选择了d=[n/2],d=[d/2],直到d=1,当然,还有其他更多的选择
for (int delta = r.length / 2; delta > 0; delta /= 2) {
//直接让i从delta开始循环,每次让i+1
for (int i = delta; i < r.length; i++) {
//注意这里是i - delta,而不是i-1,因为在希尔排序算法中,元素是跳着比的,跳跃长度为当前增量delta
if (r[i] < r[i - delta]) {
//备份当前待插入的元素r[i]
r0 = r[i];
//寻找插入的位置,与直接插入排序有所不同的是,此时不是一个一个移,而是跳着移
for (j = i - delta; j >= 0 && r0 < r[j]; j -= delta)
r[j + delta] = r[j];
r[j + delta] = r0;
}
}
}
}时间复杂度:O(n^1.5) 空间复杂度O(1)
稳定性:希尔排序是不稳定的,举个例子
例如,有待排序序列{2,4,1,2},采用希尔排序,设d1=2,则有
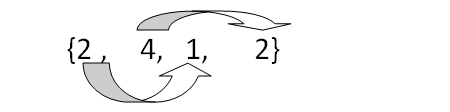
得到一趟排序结果为{1,2,2,4},之前在后面的2换到了前面2的前面(不要在意这里的箭头),所以希尔排序是不稳定的
数据测试:
| 数据规模 | 时间/s |
| 1000 | 0.002278115 |
| 10000 | 0.013082773 |
| 100000 | 0.06379576 |
| 1000000 | 0.557292275 |
| 10000000 | 8.554733172 |
注意当数据规模变成10万时,希尔排序只用了0.06379576秒,比前面的折半插入排序快了100多倍呀,有木有感觉到算法的神奇
噢噢,最后附上我的测试代码
public static void main(String[] args) {
// TODO Auto-generated method stub
int n = 10000000;//数据规模
int r[] = new int[n];
Random rom = new Random();
for (int i = 0; i < n; i++) {
r[i] = rom.nextInt(Integer.MAX_VALUE);
}
long time1 = System.nanoTime();
//halfInSort(r);
//inSort(r);
shellInsort(r);
long time2 = System.nanoTime();
double time = (time2 - time1) / 1000000000.0;
System.out.println(time);
}















 450
450











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









