









 DeepFaceLab是一个开源的人脸交换系统,由iperov创建,具有直观的命令行工具和灵活的管道设计,使得用户能够轻松实现高质量的面部交换,而无需深入了解深度学习。该系统包含人脸检测、对齐和分割模块,并支持高分辨率图像生成。DeepFaceLab的训练部分使用了高级的模型结构和损失函数,以实现逼真的面部表情和姿态匹配。此外,系统还提供了一系列工具来处理复杂情况,如遮挡和光照变化。通过与其他流行方法的比较,DeepFaceLab展示了其在生成高保真度结果方面的优势。
DeepFaceLab是一个开源的人脸交换系统,由iperov创建,具有直观的命令行工具和灵活的管道设计,使得用户能够轻松实现高质量的面部交换,而无需深入了解深度学习。该系统包含人脸检测、对齐和分割模块,并支持高分辨率图像生成。DeepFaceLab的训练部分使用了高级的模型结构和损失函数,以实现逼真的面部表情和姿态匹配。此外,系统还提供了一系列工具来处理复杂情况,如遮挡和光照变化。通过与其他流行方法的比较,DeepFaceLab展示了其在生成高保真度结果方面的优势。
[Paper] DeepFaceLab:A simple, flexible and extensible face swapping framework
[Code-Pytorch]deepfakes/faceswap
[Code-Official]iperov/DeepFaceLab
摘要
DeepFaceLab是一个由iperov创建的开源deepfake系统,其中的人脸交换在Github中以有3000个分支和14000颗星星。它为对深度学习框架没有全面了解或需要模型实现的人提供了一个命令式且易于使用的管道,同时对于需要用其他特性加强自己的管道的人来说,它仍然是一个灵活和松散的耦合结构。 编写复杂的样板代码。在本文中,我们详细介绍了 DeepFaceLab 实现的驱动原理,并介绍了它的管道,通过这些管道,用户可以轻松修改管道的各个方面以实现其定制目的,值得注意的是,DeepFaceLab 可以获得高 保真度,并且确实无法被主流的伪造检测方法识别出来。我们通过将我们的方法与当前流行的系统进行比较来展示我们系统的优势。

介绍
由于近年来深度学习为计算机视觉领域赋能,数字图像的处理,尤其是人像图像的处理,得到了快速的提升,在大多数情况下都达到了逼真的效果。面部交换是一项引人注目的任务,通过将源面部转移到目的地,同时保持源面部运动和表情变形来生成虚假内容。
面部操作技术背后的主要动机是生成对抗网络 (GAN) [8]。越来越多的人脸由 StyleGAN [14]、StyleGAN2 [15] 合成,变得越来越逼真,与人类视觉系统完全无法区分。
大量通过基于 GAN 的换脸方法合成的恶搞视频发布在 youtube 和其他视频网站上。ZAO2 和 FaceApp3 等商业移动应用程序允许普通网民轻松创建假图像和视频,极大地促进了这些交换技术的传播,称为 deepfakes。MrDeepFakes,最著名的论坛,人们谈论deepfakes技术本身的前沿进展,或者制作精美的换脸视频的一套技巧,进一步加速了deepfakes制作的视频在互联网上的推广。
这些内容生成和修改技术可能会影响公共话语的质量和保护人权,特别是考虑到深度伪造可能被恶意用作错误信息、操纵、骚扰和说服的来源。识别被操纵的媒体是一项技术要求高且发展迅速的挑战,需要整个科技行业及其他行业的合作。
媒体防伪检测的研究正在蓬勃发展,并且越来越多地致力于伪造人脸检测。DFDC4 就是一个典型的例子,它是 Facebook 和微软在 2019 年发起的百万美元挑战。
然而,被动防御从来都不是检测深度伪造的好主意。在我们看来,无论是学术界还是大众,最好了解什么是 deepfake,以及它如何将源人变成目标人的逼真视频,而不是像一句老话那样被动地防御它: “最好的防守就是好的进攻”。让广大网民意识到deepfake的存在,加强对社交网络上发布的恶搞媒体的识别能力,比苦恼恶搞媒体是否真实重要得多。
据我们所知,Synthesising Obama [26]、FSGAN [20] 和 FaceShifter [17] 是合成人脸操作视频最具代表性的作品。这些作品和其他相关作品的问题在于,它们的作者并没有完全开源他们的代码或只发布部分代码,而开源社区对这些论文的复制几乎很难产生令人信服的 结果如论文所示。“细节中的魔鬼”是我们在训练生成模型时都承认的座右铭。由于换脸算法的发展趋势越来越复杂,插入的处理程序也越来越复杂,仅凭论文就完全实现一个梦幻般的换脸算法似乎是不现实的目标。
此外,这些算法或系统或多或少需要困难的人工手工操作或指定条件,这提高了想要深入挖掘的初学者的门槛。例如,合成奥巴马 [26] 需要一个高质量的奥巴马 3D 模型和一个规范的手动绘制的蒙版,这意味着当您更改为视频剪辑或重新选择要更改的源人物时,您需要自定义一个新的 3D 模型和 绘制用于合成纹理的规范蒙版。显然,执行这样的计划是沉重的。
作为生成虚假数字内容的整个管道,除了换脸之外,还需要更多的组件来填充整个框架:如人脸检测模块、人脸识别模块、人脸对齐模块、人脸解析模块、人脸混合模块等。当前不完整的管道工作在某种程度上阻碍了该领域的进展,并增加了许多新手的学习成本。
为了解决这些问题,DeepFakes [4] 引入了一个完整的生产流程,将源人物的面部替换为目标人物的面部,以及相同的面部表情,如眼球运动、面部肌肉运动。然而,DeepFakes 产生的结果在某种程度上很差,Nirkin 的自动换脸的结果也是如此 [21]。
本文介绍了 DeepFaceLab,这是一个易于使用的开源系统,具有管道的清洁状态设计,无需痛苦的调整即可实现逼真的面部交换结果。事实证明,DeepFaceLab 非常受公众欢迎。例如,许多艺术家制作基于 DeepFaceLab 的视频并将其发布到他们的 YouTube 频道,其中,其中最受欢迎的五个平均订阅量超过 20 万,这些在 DeepFaceLab 中的点击量总和超过了 1 亿。
DeepFaceLab 的贡献可以总结如下:
- 提出了一个由成熟度管道组成的最先进的框架,旨在实现逼真的面部交换结果。
- DeepFaceLab 于 2018 年开源代码,始终紧跟计算机视觉领域的进展,为主动和被动防御 deepfakes 做出了积极贡献,在开源社区和 VFX 领域引起了广泛关注。
- DeepFaceLab 中引入了一些高效的组件和工具,因此用户可能希望 DeepFaceLab 工作流程具有更大的灵活性,同时及时发现问题。
DeepFaceLab 的特点
DeepFaceLab 的成功源于将先前的想法编织到一个设计中,该设计平衡了速度和易用性,以及计算机视觉在人脸识别、对齐、重建、分割等方面的蓬勃发展。我们的实施背后有四个主要特征:
Leras
现在DeepFaceLab提供了一个全新的基于纯TensorFlow[1]的高级深度学习框架,旨在拯救一些常用的高级框架如Keras[3]和plaidML[29]带来的不必要的限制和额外开销。iperov 将其命名为 Leras:Lighter Keras 的缩写。 Leras的主要优点是:
- 简单灵活的模型构建 Leras 通过提供 Pythonic 风格来完成模型工作,减轻了研究人员和从业者的负担,类似于 PyTorch(即定义层、组成神经模型、编写优化器),但采用图形模式(没有急切执行)。
- 以性能为中心的实施 使用 Leras 代替 Keras,训练时间平均减少约 10 20%。
- 细粒度张量管理 切换到纯 Tensorflow 的动机是 Keras 和 plaidML 不够灵活。此外,它们在很大程度上已经过时,并且无法完全控制张量的处理方式。
把用户放在第一位
DeepFaceLab 致力于尽可能轻松和高效地使用其管道,包括数据加载器和处理、模型训练和后处理。与其他面部交换系统不同,DeepFaceLab 提供了一个完整的命令行工具,管道的每个方面都可以按照用户选择的方式执行。值得注意的是,固有的复杂性以及许多精心挑选的用于细粒度控制的特征,例如用于面部对齐的规范面部标志,应该在内部处理并隐藏在 DeepFaceLab 之后。也就是说,人们只要按照工作流程的设置,就可以在不需要手动选择特征的情况下,获得流畅和逼真的换脸结果,只需要两个文件夹:源(src)和目标( dst) 而无需在 src 和 dst 之间配对相同的面部表情。在某种程度上,DeepFaceLab 可以像傻瓜相机一样发挥作用。此外,根据 DeepFaceLab 用户的许多实际反馈,需要高度灵活和定制的人脸转换器,因为需要处理很多复杂的问题:泛光灯、雨水、玻璃隔开、面部受伤等许多情况。因此,在转换阶段采用了交互模式,减轻了 deepfake 制作者的工作量,因为交互式预览可以帮助他们在更改各种选项和启用/禁用各种功能时观察他们所做的所有更改的效果。
工程支持
为了充分发挥 CPU 和 GPU 的潜力,增加了一些实用措施来提高性能:多 GPU 支持、半精度训练、使用固定 CUDA 内存来提高吞吐量、使用多线程来加速图形操作和数据处理 .
可扩展性和可扩展性
为了加强 DeepFaceLab 工作流程的灵活性并吸引研究界的兴趣,用户可以自由更换任何不满足其项目需求或性能要求的 DeepFaceLab 组件,因为 DeepFaceLab 的大多数模块都设计为可互换。例如,人们可以提供一种新的人脸检测器,以实现对极端角度或远区域人脸的高性能检测。一般情况下,DeepFaceLab 的许多大师倾向于定制他们的网络结构和训练范式,例如 PGGAN [13] 的渐进式训练范式结合 LSGAN [19] 或 WGAN-GP [9] 的特殊损失设计。
管道
在 DeepFaceLab(简称 DFL)中,我们将管道抽象为三个主要组件:提取、训练和转换。这三个部分依次呈现。此外,值得注意的是,DFL属于典型的一对一换脸范式,这意味着只有两个数据文件夹:src和dst,源和目的地的缩写,用于以下叙述。此外,与之前的工作不同,我们可以生成高分辨率图像并推广到不同的输入分辨率。
提取
提取是DFL的第一阶段,它包含了很多算法和处理部分,即人脸检测、人脸对齐和人脸分割。在提取过程之后,用户将从您的输入数据文件夹中获得具有精确蒙版和面部标志的对齐人脸,这部分使用 src 进行说明。另外,由于DFL提供了多种人脸类型(即half face、full face、whole face),代表了Extraction的人脸覆盖区域。除非另有说明,否则默认采用full face。
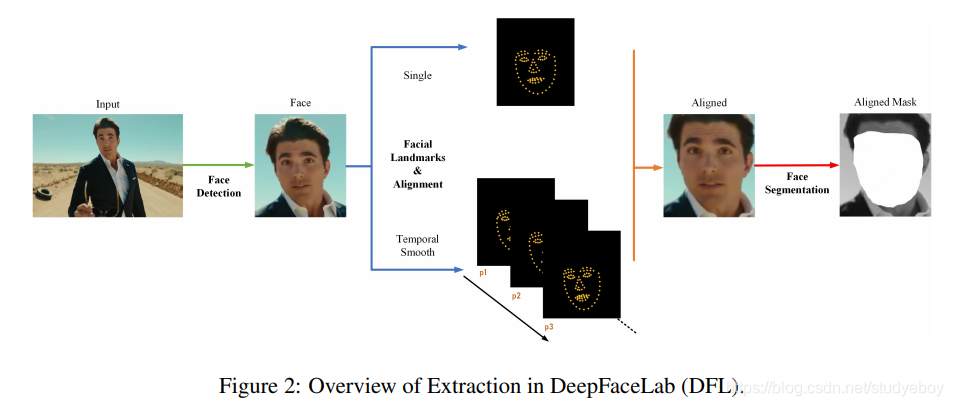
人脸检测
Extraction 的第一步是在给定的文件夹中找到目标人脸:src 和 dst。DFL 使用 S3FD [34] 作为其默认人脸检测器。显然,您可以选择任何其他人脸检测算法来替换指定目标的 S3FD,即 RetinaFace [5]、MTCNN [33]。
面部对齐
第二步是人脸对齐,经过无数次实验和失败,我们需要找到一种可以随时间保持稳定的面部标志算法,这对于制作成功的连续镜头和电影至关重要。
DFL 提供了两种典型的面部标志提取算法来解决这个问题:(a)基于热图的面部标志算法 2DFAN [2](用于正常姿势的面部)和(b)具有 3D 面部先验信息的 PRNet [6](用于具有大 欧拉角(偏航、俯仰、滚转),例如偏航角大的面,意味着面的一侧是看不见的)。在检索到面部标志后,我们提供了一个可选功能,该功能具有可配置的时间步长,以在单次拍摄中平滑连续帧的面部标志。
然后我们采用 Umeyama [28] 提出的经典点模式映射和变换方法来计算用于人脸对齐的相似变换矩阵。
由于 Umeyama [28] 方法在计算相似变换矩阵时需要标准的面部标志模板,DFL 提供了三个规范对齐的面部标志模板:前视图和侧视图(左视图和右视图)。值得一提的是,DFL 可以根据获取的人脸标志自动确定欧拉角,这可以帮助 Face Alignment 选择合适的面部标志模板,无需任何人工干预。
人脸分割
人脸对齐后,得到一个标准前/侧视图对齐src的人脸数据文件夹。我们在对齐的 src 之上采用了细粒度的人脸分割网络(TernausNet [10]),通过它,可以准确地分割带有头发、手指或眼镜的人脸。它是可选但有用的,旨在消除不规则的遮挡,以保持训练过程中的网络对手、眼镜和任何其他可能以某种方式覆盖面部的物体的鲁棒性。
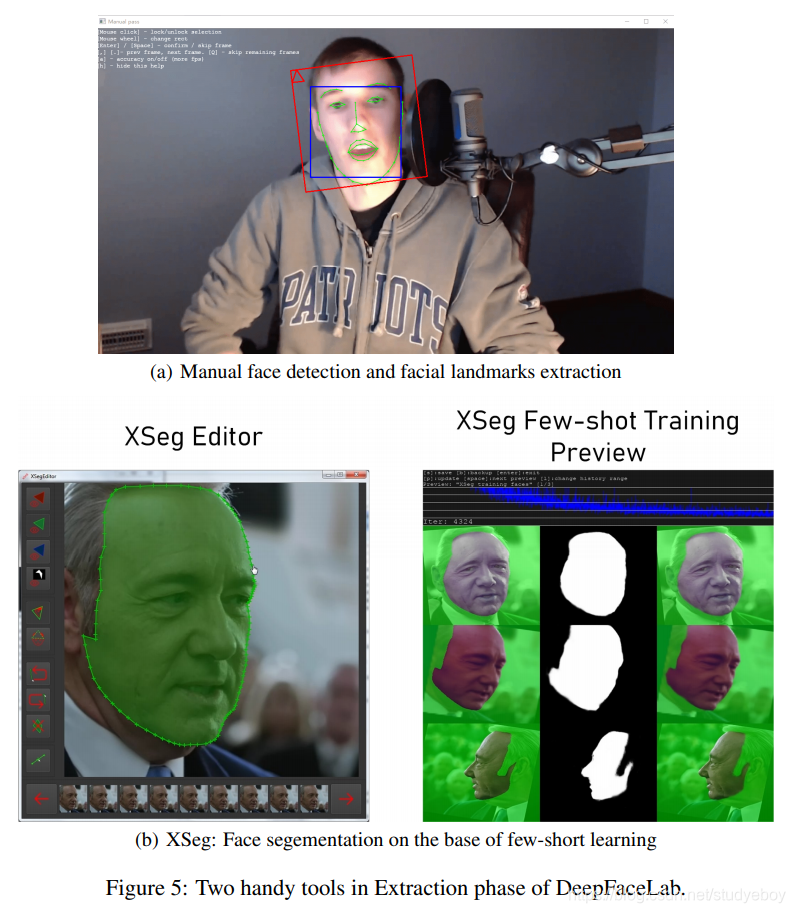
然而,由于一些最先进的人脸分割模型无法在某些特定镜头中生成细粒度的掩码,因此在 DFL 中引入了 XSeg 模型。XSeg 现在允许每个人通过少样本学习范式训练自己的模型来分割特定面集(对齐的 src 或对齐的 dst)。例如,如果一个faceset大约有2000张图片,手动标记最有代表性的50-100个样本就足够了。然后 XSeg 训练以在那些手动标记的对之上实现所需的分割质量并推广到整个面集。需要明确的是,XSeg(optional) 仅在使用 Whole_face 类型或需要从 full_face 类型上的掩码中移除障碍物的情况下才需要。 XSeg 的草图在 4 中列出。
由于上述工作流程按顺序执行,我们在下一阶段(训练)中获得了 DFL 所需的一切:裁剪人脸及其原始图像中的对应坐标、面部标志、对齐的人脸和来自 src 的像素级分割掩码(自 dst 与 src 相同,因此无需详细说明)。
训练
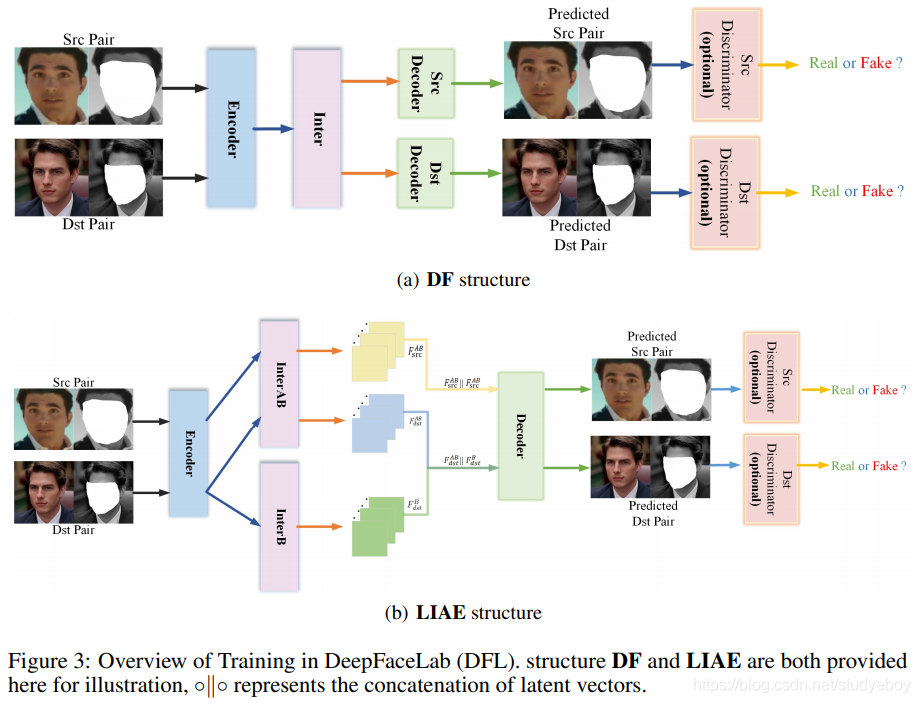
训练是实现 DeepFaceLab 逼真的面部交换结果的最重要角色。
在没有要求对齐 src 和对齐 dst 的面部表情严格匹配的情况下,我们的目标是设计一种简单有效的算法范式来解决这个未配对的问题,同时保持生成的人脸的高保真度和感知质量。如图 3(a) 所示,DF 由一个 Encoder 和 Inter 组成,Inter 在 src 和 dst 之间共享权重,另一个 Decoder 分别属于 src 和 dst。src 和 dst 的泛化是通过共享的 Encoder 和 Inter 实现的,很容易解决前面提到的不成对问题。
src 和 dst 的潜在代码为 Fsrc 和 Fdst,均由 Inter 提取。
如图 3(b) 所示,LIAE 是一个更复杂的结构,具有共享权重的编码器、解码器和两个独立的 Inter 模型。与 DF 相比的另一个区别是 InterAB 用于生成 src 和 dst 的潜在代码,而 InterB 仅输出 dst 的潜在代码。这里, F s r c A B F^{AB}_{src} FsrcAB 表示由 InterAB 产生的 src 的潜在代码,我们将此表示推广到 F d s t A B F^{AB}_{dst} FdstAB , F d s t B F^{B}_{dst} FdstB 。
在从 InterAB 和 InterB 获取所有潜在代码后,LIAE 然后通过通道连接这些特征图: F s r c A B F^{AB}_{src} FsrcAB || F s r c A B F^{AB}_{src} FsrcAB 获得了 src 的新潜在代码表示和 F d s t A B F^{AB}_{dst} FdstAB || F d s t B F^{B}_{dst} FdstB用同样的方法获得 dst 的潜在代码表示。
然后 F s r c A B F^{AB}_{src} FsrcAB || F s r c A B F^{AB}_{src} FsrcAB 和 F d s t A B F^{AB}_{dst} FdstAB || F d s t B F^{B}_{dst} FdstB被放入解码器,因此我们得到了预测的 src (dst) 和它们的掩码。连接 F d s t B F^{B}_{dst} FdstB和 F d s t A B F^{AB}_{dst} FdstAB 的动机是将潜在代码的方向转移到我们需要的类(src 或 dst)的方向上,InterAB 通过它获得了潜在空间中 src 和 dst 的紧凑且对齐的表示 .
除了模型的结构之外,一些有用的技巧对于提高生成的人脸的质量是有效的。受 PRNet [7] 的启发,同时在需要充分利用面罩和地标的驱动下,可以添加一般 SSIM [30] 中的加权和面罩损失,使面部的每个部分在 AE 训练下具有不同的权重 例如,我们为眼睛区域添加了比脸颊更多的权重,目的是使网络专注于生成具有生动眼睛的面部。
至于损失,DFL 默认使用混合损失(DSSIM(结构差异)[18] + MSE)。这种组合的原因是从两者中获益:DSSIM 可以更快地概括人脸,同时 MSE 提供更好的清晰度。这种组合损失用于在泛化和清晰度之间找到折衷。
我们没有编写太多的样板代码,而是减轻了用户设计自己的训练范式或网络结构的负担,具体来说,用户可以添加额外的中间模型来混合 src 和 dst 的潜在表示(即 LIAE),或者 当用户选择使用 GAN 范式进行训练时,允许将自定义判别器(即多尺度判别器 [12] 或 RealnessGAN 判别器 [31])放在解码器之后以缓解生成人脸的语义差距,尤其是在数据集数量有限的情况下 src 和 dst。
在 src2dst 的情况下(图 4),我们在转换阶段使用一个奇特的真人脸模型 TrueFace 来生成与 dst 更相似的人脸。对于LIAE,它的目标是使 F s r c A B F^{AB}_{src} FsrcAB 的分布接近 F d s t A B F^{AB}_{dst} FdstAB 。而对于 DF,目的地则变为 F s r c F_{src} Fsrc 和 F d s t F_{dst} Fdst。
此外,与 deepfakes 和其他换脸框架的固定分辨率限制不同,我们可以通过调整训练部分中模型定义的设置来生成高分辨率图像并泛化到不同的输出分辨率,这通过 DFL 干净清晰的界面变得相当容易。
显然,LIAE 和 DF 都支持上述特性,并且这些特性被设计为可插拔的,进一步提高了 DFL 框架的灵活性。更多关于 DF 和 LIAE 的设计细节,请参考附录。
转换
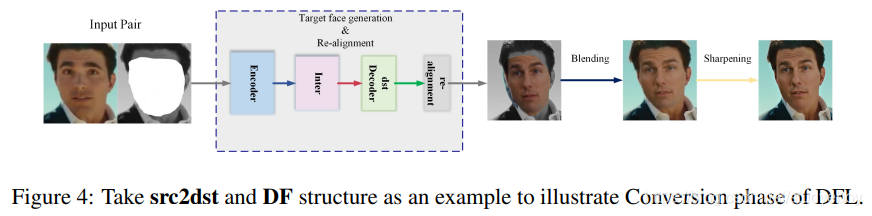
最后,我们来到转换阶段,如图 4 所示,用户可以将 src 的 face 交换为 dst,反之亦然。
在 src2dst 的情况下,Conversion 中提出的人脸交换方案的第一步是将生成的人脸
I
t
r
I^r_t
Itr 连同其掩码
M
t
M_t
Mt从 dst 解码器转换到目标图像
I
t
I_t
It 在 src 中的原始位置,这是由于 Umeyama 的可逆性 [28]。下面的部分是关于混合的,目标是重新对齐的重演人脸
I
t
r
I^r_t
Itr 沿着
M
t
M_t
Mt的外部轮廓与目标图像
I
t
I_t
It无缝匹配。为了保持肤色一致,DFL提供了另外五种颜色转移算法(即reinhard颜色转移:RCT [24],迭代分布转移:IDT [23]等),使
I
t
r
I^r_t
Itr更适应目标图像
I
t
I_t
It。在它之上,可以通过组合两个图像来获得混合的结果:
I
t
r
I^r_t
Itr 和
I
t
I_t
It。
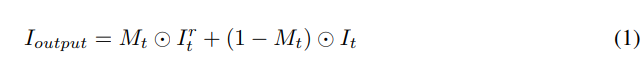
任何混合都必须考虑到不同的肤色、面部形状和照明条件,尤其是在
I
t
r
I^r_t
Itr与定界区域和
I
t
I_t
It之间的交界处。在这里,我们将泊松混合 [22] 优化定义为:
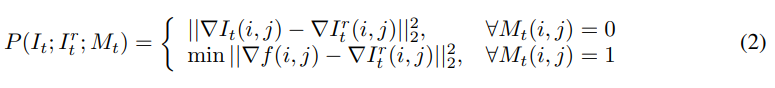
从等式 2 很容易看出,我们只需要最小化面部部分,用
∀
M
t
(
i
,
j
)
=
1
\forall M_t(i, j) = 1
∀Mt(i,j)=1 因为
∣
∣
∇
I
t
(
i
,
j
)
−
∇
I
t
r
(
i
,
j
)
∣
∣
2
2
||\nabla I_t(i, j) − \nabla I^r_t (i, j)||^2_2
∣∣∇It(i,j)−∇Itr(i,j)∣∣22 是一个常数项。
然后我们来到 DFL 管道和转换工作流程的最后一个常规步骤:锐化。添加了一个预训练的人脸超分辨率神经网络(表示为 FaceEnhancer)来锐化混合后的人脸。由于注意到几乎当前最先进的面部交换作品中生成的面部或多或少都经过平滑处理,并且缺少细微的细节(即痣、皱纹)。如果一切顺利,我们就可以看到高清假图了(将生成的人脸无缝贴合到目标人脸的指定部分,同时将生成的人脸肤色调整到目标人脸,然后根据目标人脸重新拟合回原图) 到它在相位提取中记录的坐标),即使在频域分析的帮助下也很难区分真假。
DeepFaceLab 中的生产力工具
一般而言,当存在大量面部交换条件的面部时,DFL 在制作视频的工作流程中充当生产力工具。因此,合成假图像的真实性要求远高于普通消费级产品,即分辨率高、遮挡复杂、光照差。
为了解决上述问题,我们提供了一些有效的工具来实现超高保真度和真实感的高清假像。
在图 5 中,DFL 的提取阶段有两个常用的工具。图 5(a) 是一种手动人脸检测和面部标志提取工具,专为具有极端欧拉角的面部而设计,其中常用的面部检测器和面部标志提取器会失败。
此外,当合成视频中存在视频抖动时,该工具可以帮助用户通过参考相邻帧来细化/平滑目标人脸的面部标志。
同样,图 5(b) 是 XSeg 手动人脸分割编辑器,用于细粒度控制面罩范围,旨在避免手、头发等遮挡物的干扰。
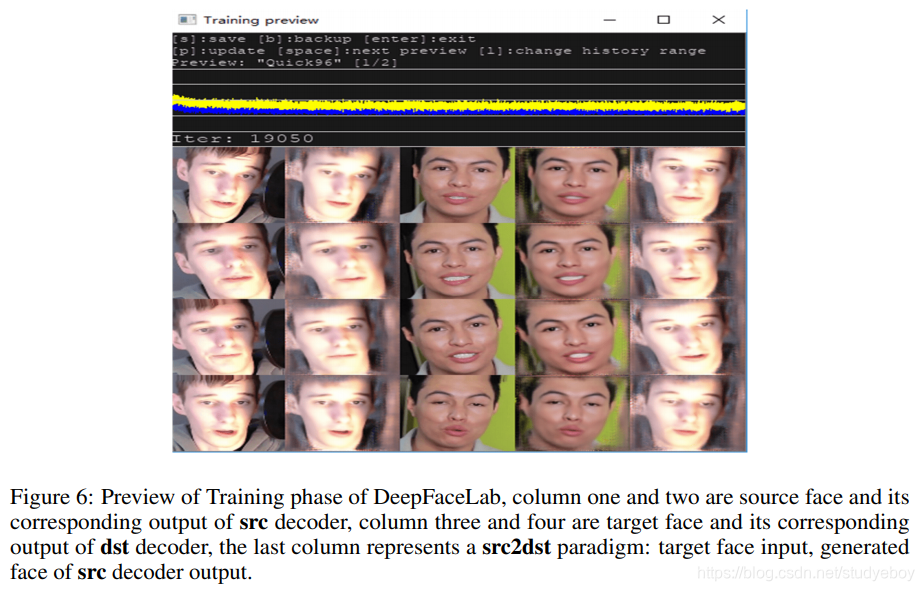
在训练过程中,我们为研究人员提供了详细的预览来测试他们的新想法,而无需编写任何额外的代码,图 6 中的黄线和蓝线表示了损失运动,代表了 src2src 和 dst2dst 的损失历史,为人们提供了有价值的信息 调试他们独特的模型架构是否好。
评估
在本节中,我们将 DeepFaceLab 的性能与其他几个常用的人脸交换框架和两个最先进的工作进行比较,发现 DFL 在它们之间具有竞争性。
噪声和误差分析
由于大多数现有的人脸交换算法共享将重新生成的人脸混合到现有背景图像中的通用步骤,因此不可避免地会出现跨越混合边界的图像差异和不连续性问题。
这里的问题是这种差异会在高分辨率图像中被放大。 我们在图 7 中说明了噪声分析 5 和错误级别分析。

定性结果
图 8(a) 提供了取自 FaceForensics++ 数据集 [25] 的代表性开源项目(DeepFakes [4]、Nirkin 等人 [21] 和 Face2Face [27])的面部交换结果。在我们的实验中选择了不同表情、面部形状和光照的示例。从观察 FaceForensics++ 的视频片段可以清楚地看出,它们不仅训练不充分,而且是从低分辨率模型中挑选出来的。为了公平起见,我们采用了 Quick96 模式:DF 结构在下面的轻量级模型,输出 96 × 96 分辨率的 Ioutput(没有 GAN 和 TrueFace)。平均训练时间限制在3小时以内。我们使用 Adam [24] ( l r = 0.00005 , β 1 = 0.5 , β 2 = 0.999 ) (l_r=0.00005, β_1 = 0.5, β_2 = 0.999) (lr=0.00005,β1=0.5,β2=0.999) 来优化我们的模型。我们所有的网络都在单个 NVIDIA GeForce 1080Ti GPU 和 Intel Core i7-870 CPU 上进行了训练。



定量结果
FaceForensics++ 在定量实验中仍在使用。在实践中,换脸方法结果的自然性和真实性很难用一些特定的量化指标来描述。然而,姿势和表情确实体现了对换脸结果的宝贵见解。此外,SSIM 用于比较结构相似性,并采用感知损失 [11] 来比较目标主题和交换主题之间的高级差异,如内容和风格差异。
为了测量姿势的准确性,我们计算了 I t I_t It 和 I o u t p u t I_{output} Ioutput 的欧拉角(通过 FSA-Net [32] 提取)之间的欧几里得距离。此外,面部表情的准确性是通过 2D 地标(2DFAN [2])之间的欧几里得距离来衡量的。我们使用 DLIB [16] 的默认人脸验证方法进行身份比较。
为了具有统计意义,我们计算了 FaceForensics++ 中前 500 个视频的 100 帧(随时间均匀采样)的这些测量值的均值和方差,并对这些视频求平均值。在这里,DeepFakes [4] 和 Nirkin 等人。 [21] 被选为基线进行比较。需要注意的是,DeepFaceLab 制作的所有视频都遵循与 5.2 相同的设置。
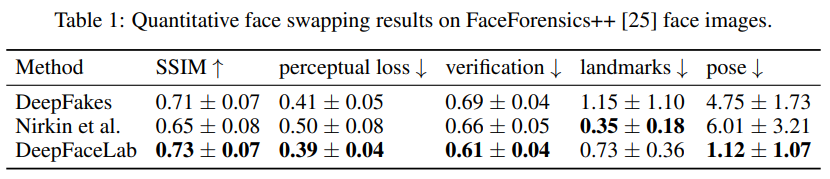
从表 1 列出的指标来看,DeepFaceLab 比基线更擅长保持姿势和表情。此外,在Conversion中超分辨率的赋能,DFL经常会产生眼睛生动、牙齿锋利的
I
o
u
t
p
u
t
I_{output}
Ioutput,但这种现象在类似SSIM的评分中并不能体现得淋漓尽致,因为它们只占了整张脸的一小部分。
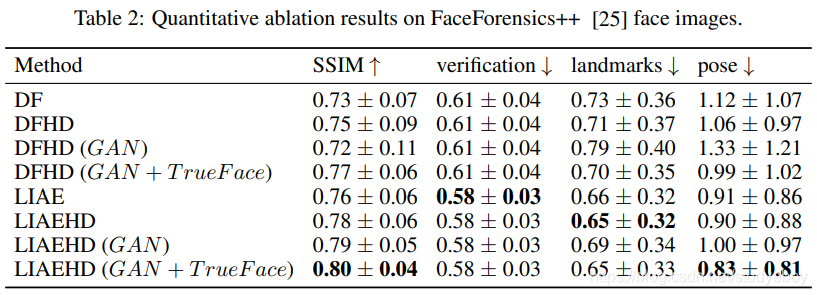
消融研究
为了比较不同模型选择、GAN 设置等的视觉效果,我们进行了多项消融测试。消融研究在三个关键部分之上进行:网络结构、训练范式和潜在空间约束。
除了 DF 和 LIAE,我们通过添加更多的特征提取层、与原始版本相比的残差块,将 DF 和 LIAE 增强到 DFHD 和 LIAEHD,这有助于丰富模型结构进行比较。不同模型结构的定性结果见图 9,不同训练范式的定性结果见图 10。


定量消融结果如表 2 所示,除模型结构外,训练的实验设置与 5.2 几乎相同。
表 2 的验证结果表明,源身份在具有相同结构的网络中得以保留。随着更多快捷连接被添加到模型中(即 DF 到 DFHD,LIAE 到 LIAEHD),在没有 GAN 的情况下,地标和姿势的分数会减少。同时生成的结果可以更好地摆脱源人脸的影响。此外,我们发现 TrueFace 有效地缓解了 GAN 的不稳定性,从而实现了更逼真的结果,而不会造成太大的退化。此外,SSIM随着网络的增加而逐渐增加,有更多的捷径连接,TrueFace和GAN也不同程度地发挥了作用。
结论
快速发展的DeepFaceLab通过将人们从繁琐的数据处理、训练和转换部分的琐碎细节工作中解放出来,成为深度学习从业者社区中流行的换脸工具。在继续紧跟计算机视觉的最新趋势和进步的同时,我们计划在未来继续提高 DeepFaceLab 的速度和可扩展性。受到该领域一些杰出研究人员的启发:“抑制此类方法的发表不会阻止它们的发展,而是只会使有限数量的专家和潜在的盲目决策者可以使用它们,如果它没有任何限制的话”。作为领先的、广受认可的开源换脸工具,我们发现我们有责任将 DeepFaceLab 正式发布给学术界。
附录:剖析DF的详细结构
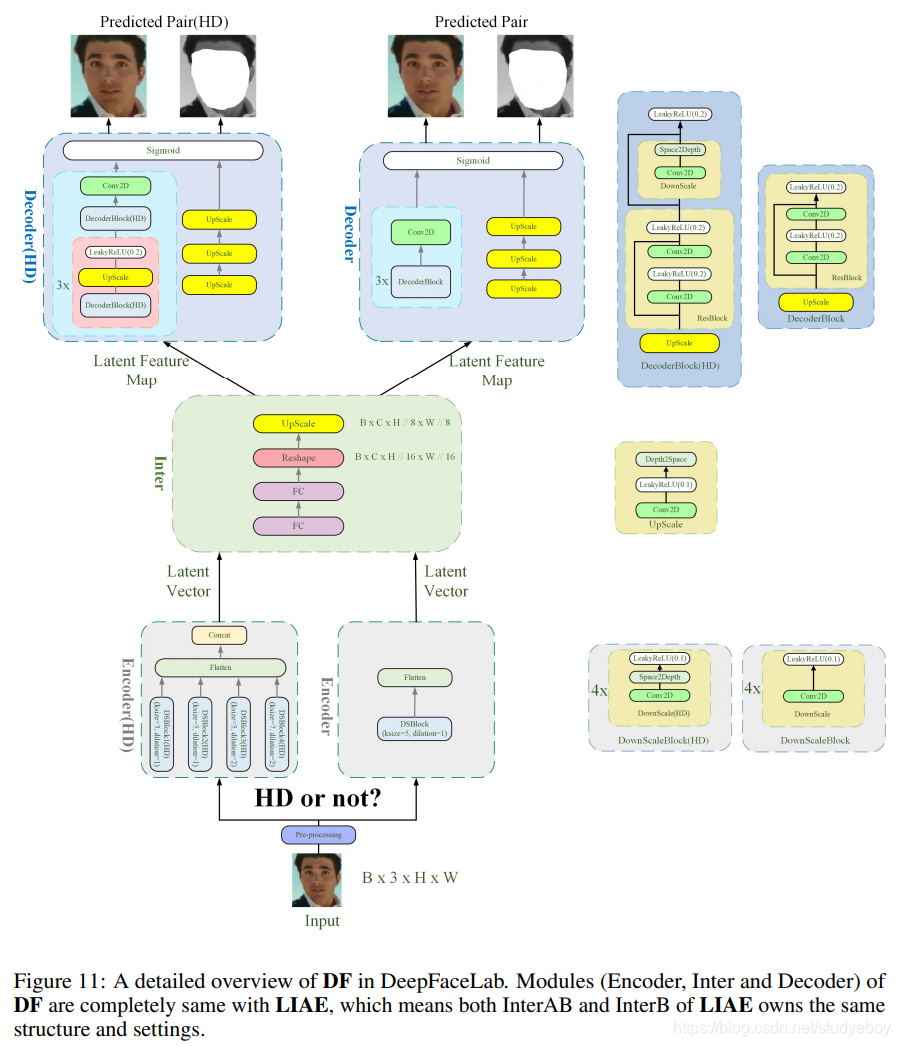
DF 的布局以及每个指定的子模块如图 11 所示。根据结果,很容易看出原始DF和增强版DFHD的区别在于DFHD具有更多的特征提取层和不同的堆叠顺序。该结构的三个典型特征是:
- 我们使用pixelshuffle(depth2space)进行上采样而不是转置卷积,既不是双线性采样,也不是卷积,目的是消除伪影和棋盘效应。
- 由Resnet衍生而来的Identity Shortcut连接,经常用于组成Decoder的模块。这是因为具有更多捷径连接的模型总是同时具有许多独立的有效路径,这使得模型具有类似集成的行为。
- 我们将图像标准化为 0 到 1,而不是 -1 到 1。然后 Sigmoid 作为 Decoder 输出的最后一层而不是 Tanh。

















 1648
1648

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









