







【作者主页】:小鱼神1024
【擅长领域】:JS逆向、小程序逆向、AST还原、验证码突防、Python开发、浏览器插件开发、React前端开发、NestJS后端开发等等
本文章中所有内容仅供学习交流使用,不用于其他任何目的,不提供完整代码,抓包内容、敏感网址、数据接口等均已做脱敏处理,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关!若有侵权,请联系作者立即删除!
【该文章已同步至星球】:https://t.zsxq.com/vytag
前言
刚过完年,不算太忙,应星球小伙伴要求,帮忙分析了一下某多多 anti-content 签名算法,记录一下分析过程,希望对大家有所帮助。
前置分析
在请求参数里,都会携带一个 anti-content 参数,如下:

这个是以 0aq 开头的,目前已知还有以 0ap、0ar、0as等等开头的,猜测是不同的业务场景,所以签名算法不同,但大体流程是一样的。
当不携带 anti-content 参数时,会返回如下错误:
{'success': False, 'error_code': 40002, 'error_msg': '手机网络繁忙,请稍后再试'}
逆向分析
全局搜索 anti-content,打上断点断住了。如下:
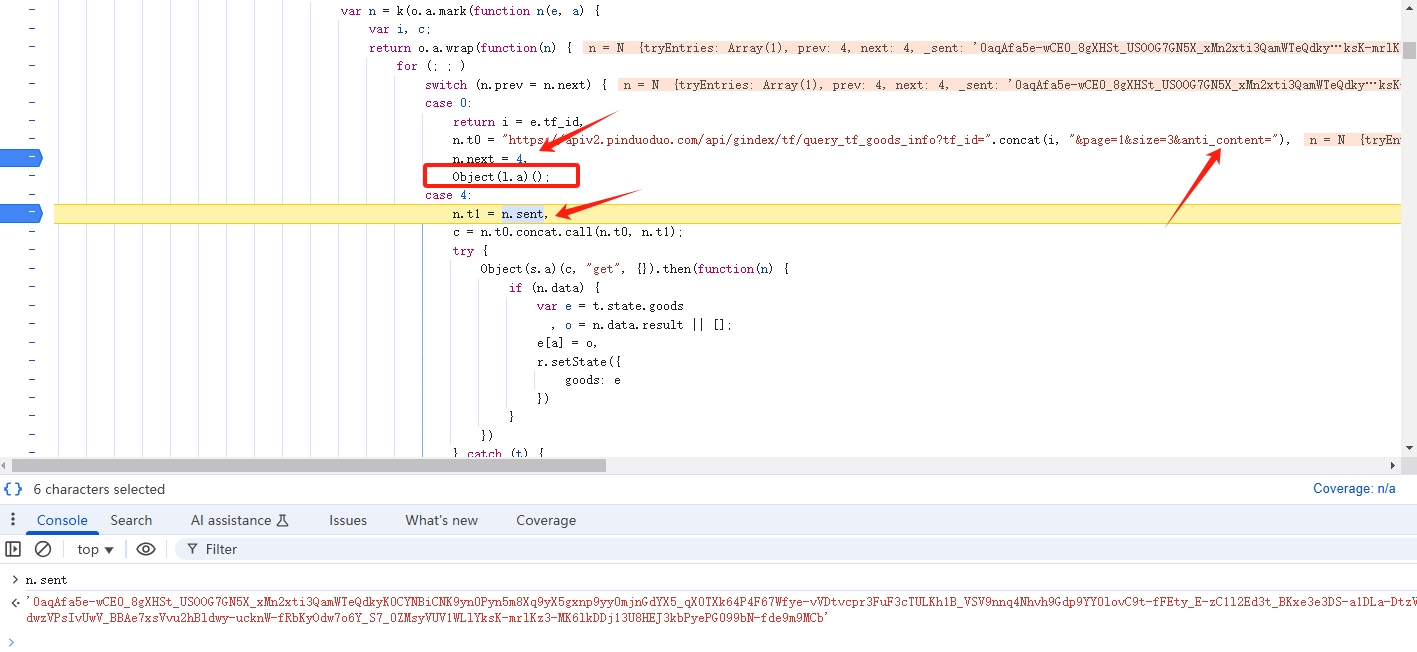
由于在 n.next = 4, 之前还没生成签名,在 n.sent 时就生成了签名。那真相只有一个了,那就是在执行 Object(l.a)() 生成了 anti-content。
那进入 Object(l.a)() 看看,如下:
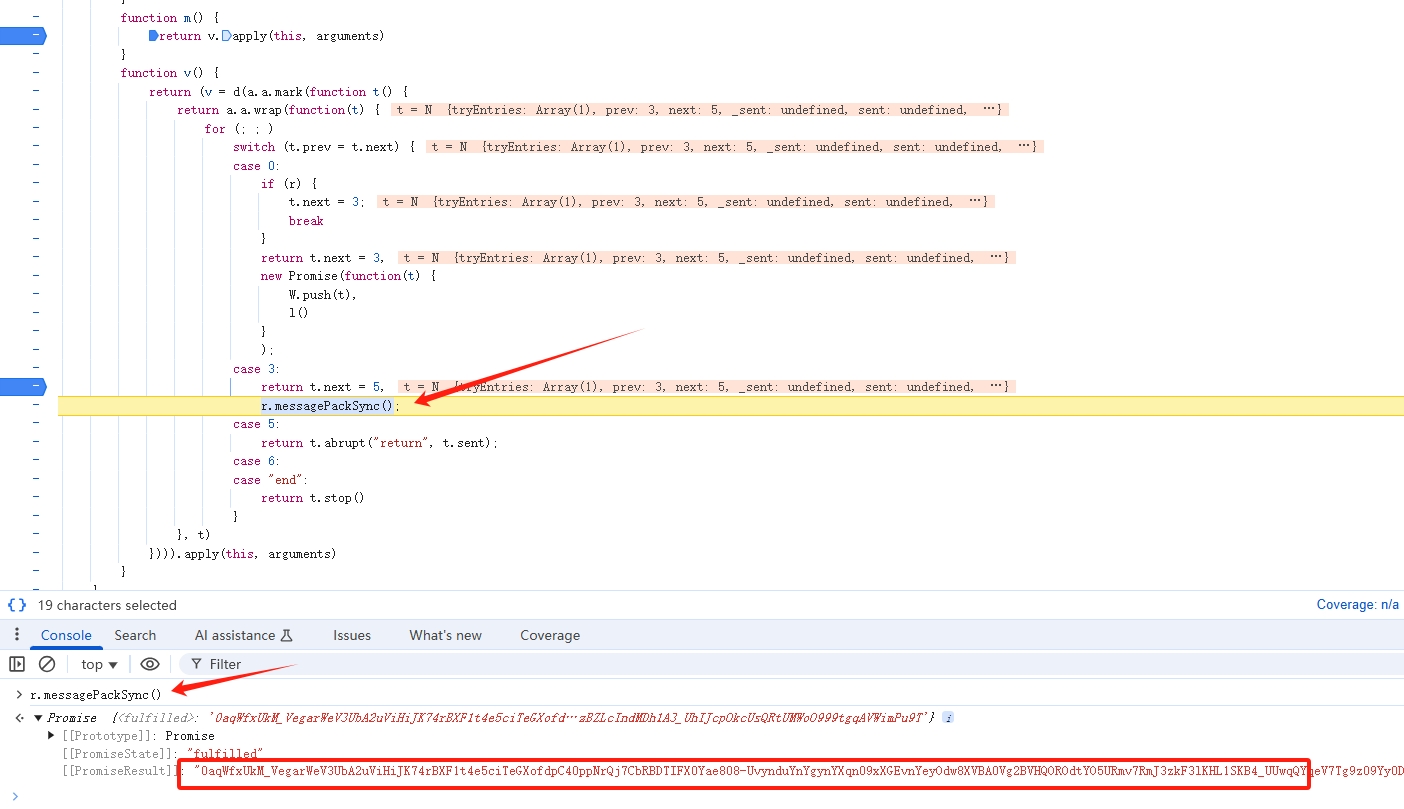
打上断点,发现 anti-content 是通过 r.messagePackSync() 生成的。通过结果可以看出 messagePackSync 是一个异步函数。
那进入 messagePackSync 看看,如下:
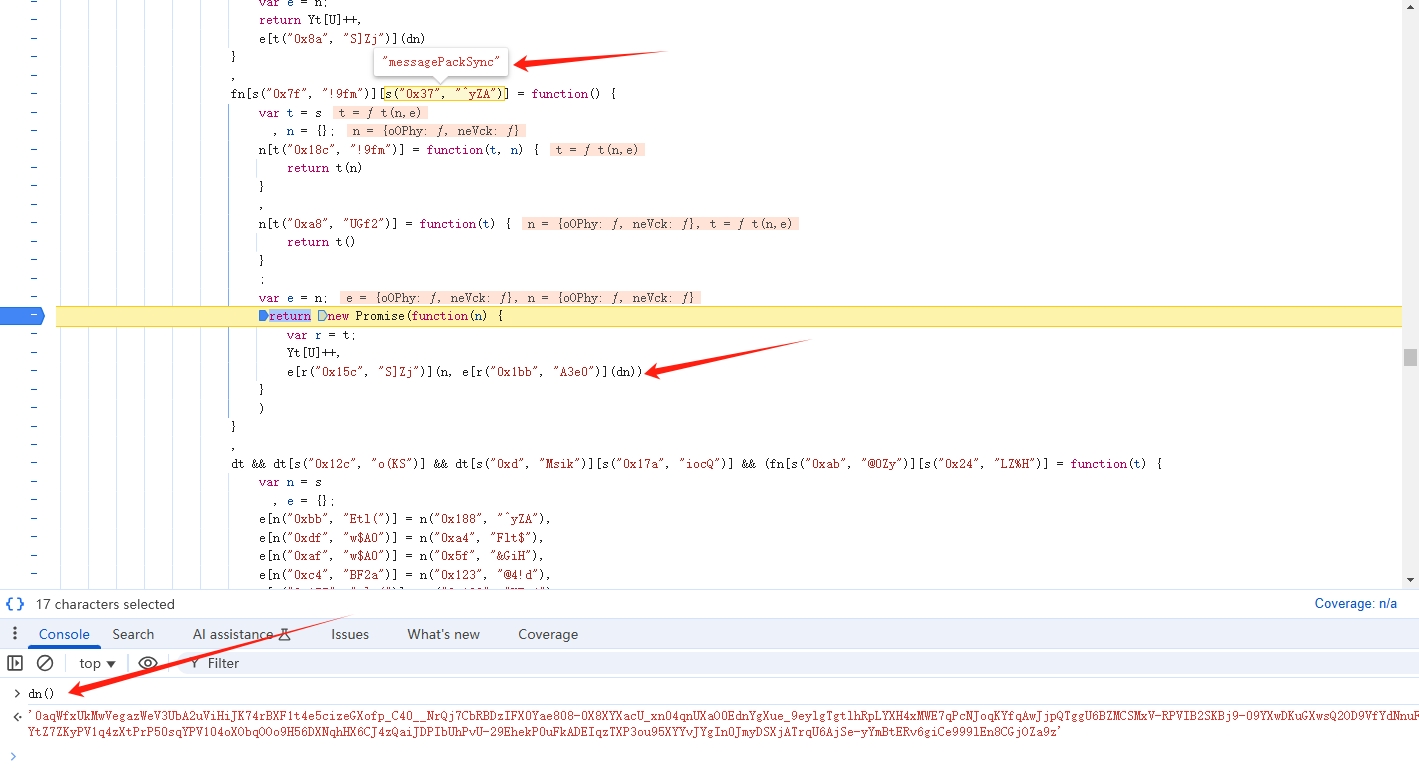
打上断点,发现 anti-content 是通过 dn() 生成的。
进入 dn() 看看,如下:
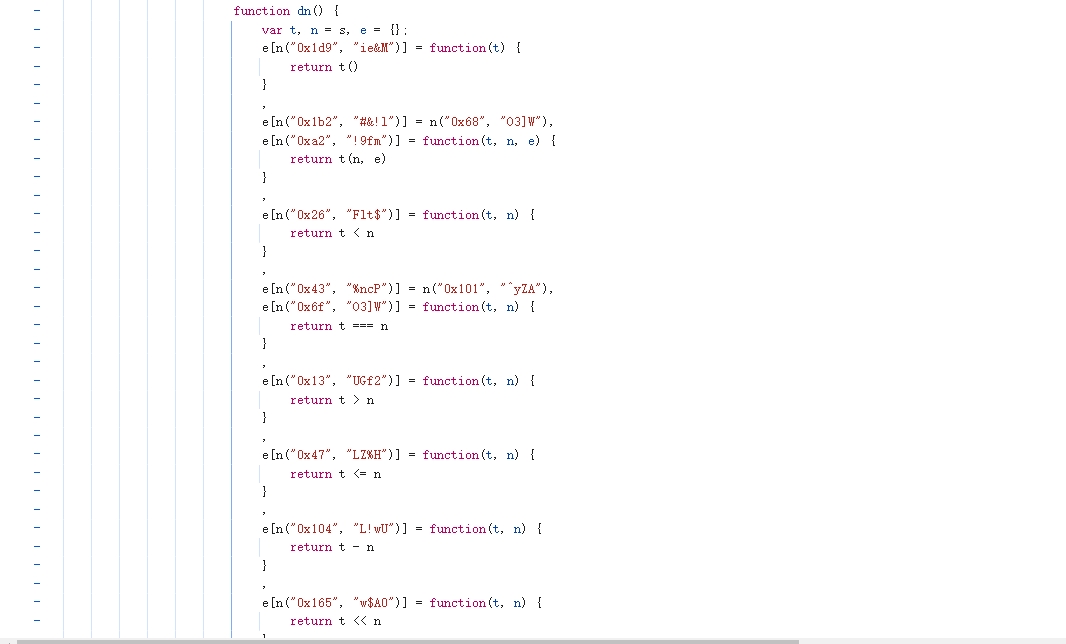
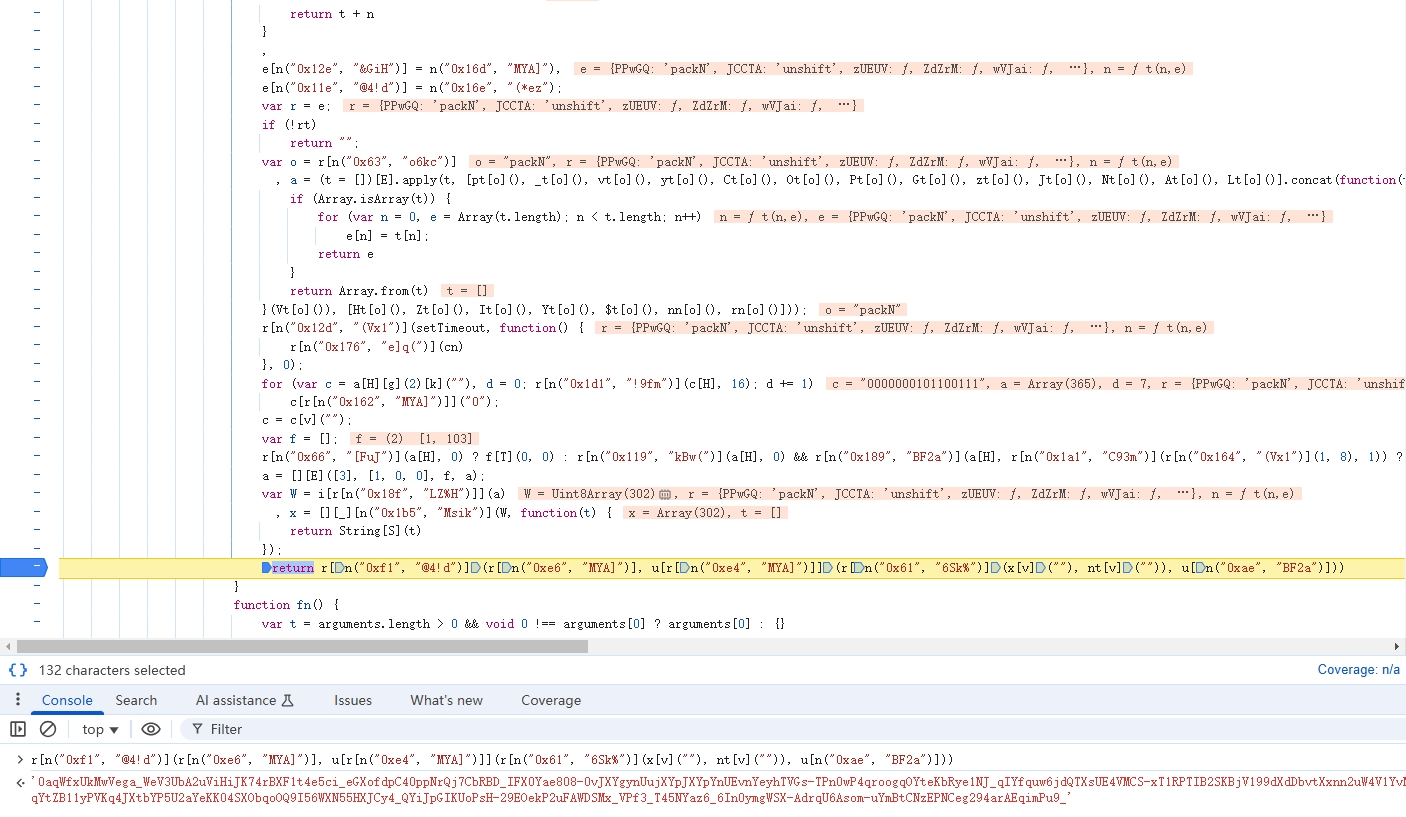
可以看到 anti-content 是通过 r[n("0xf1", "@4!d")](r[n("0xe6", "MYA]")], u[r[n("0xe4", "MYA]")]](r[n("0x61", "6Sk%")](x[v](""), nt[v]("")), u[n("0xae", "BF2a")])) 生成的。
分析到这里,有个问题,还要不要继续分析其中 r、u、x、v、nt 这些从哪里来呢?
当然了,你可以继续深分析下去,工作量也是巨大的。
我们可以翻到这个文件的最上面,看看有没有什么线索,如下:
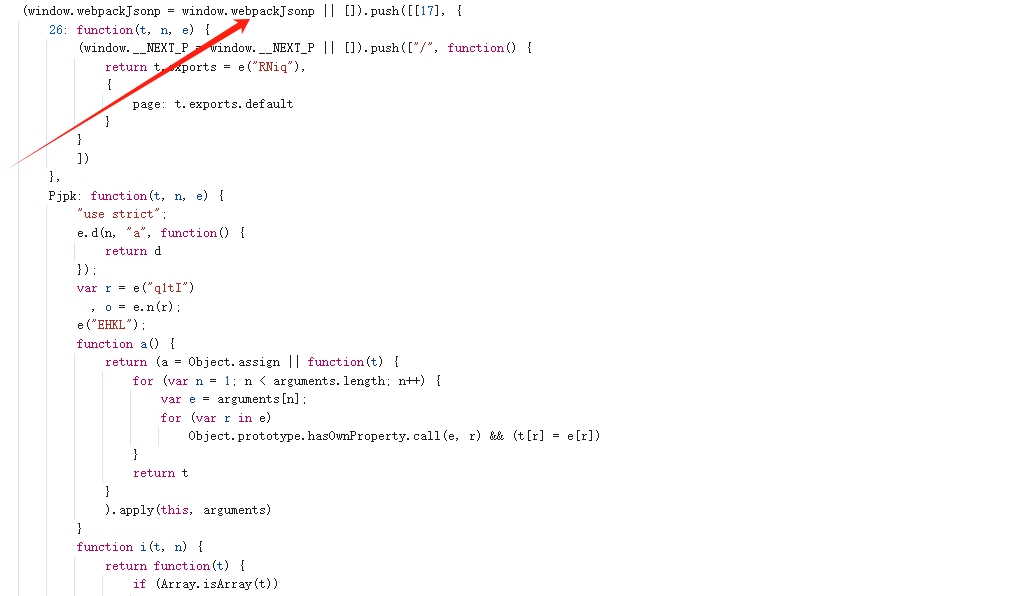
发现它是一个标准的 webpack 打包后的文件,那我们可以通过扣代码的方式,来生成签名。
所以,要先定位 dn 函数所在的模块,如下:

如果你对 webpack 扣代码不熟悉,可以使用我的自动扣 webpack 代码框架:自动扣webpack框架演示。
代码扣好之后,通过 webpack加载器 调用 fbeZ 模块。
在这个文件里搜素 fbeZ,找到调用的地方,如下:
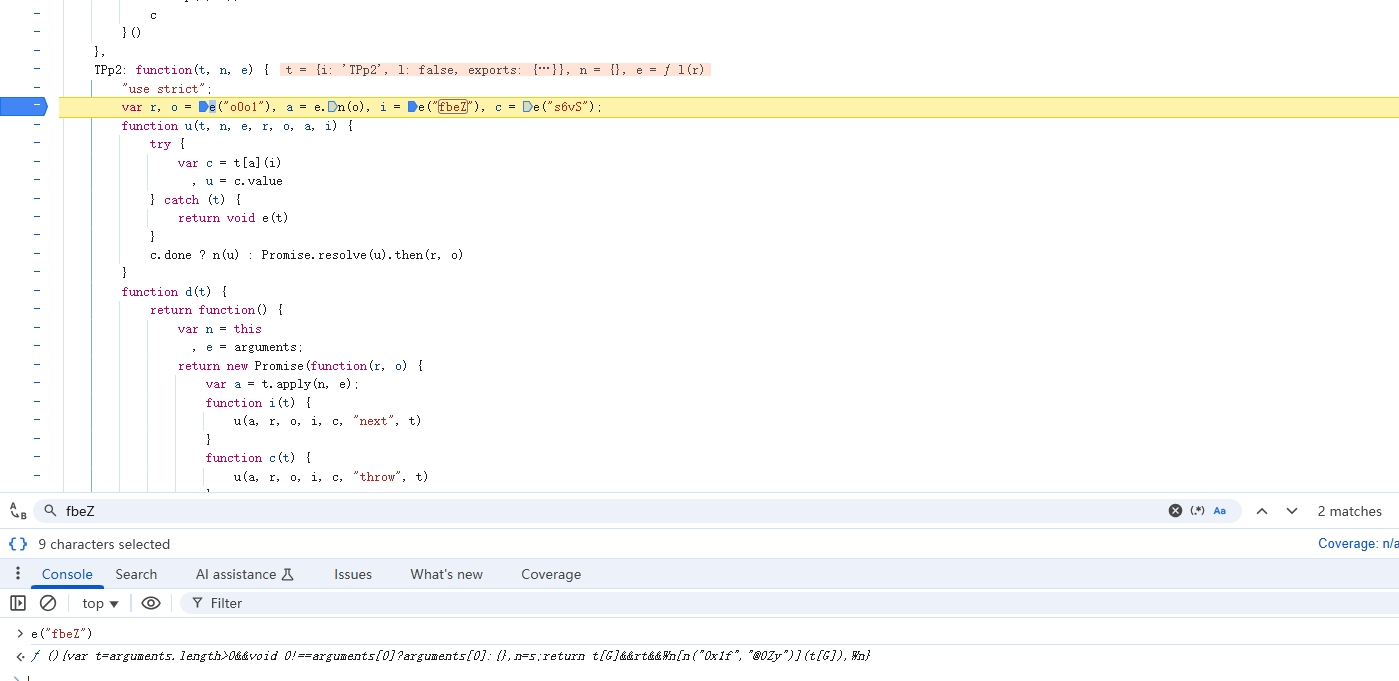
双击 e("fbeZ") 生成的代码,跳转到 fbeZ 调用的地方,如下:
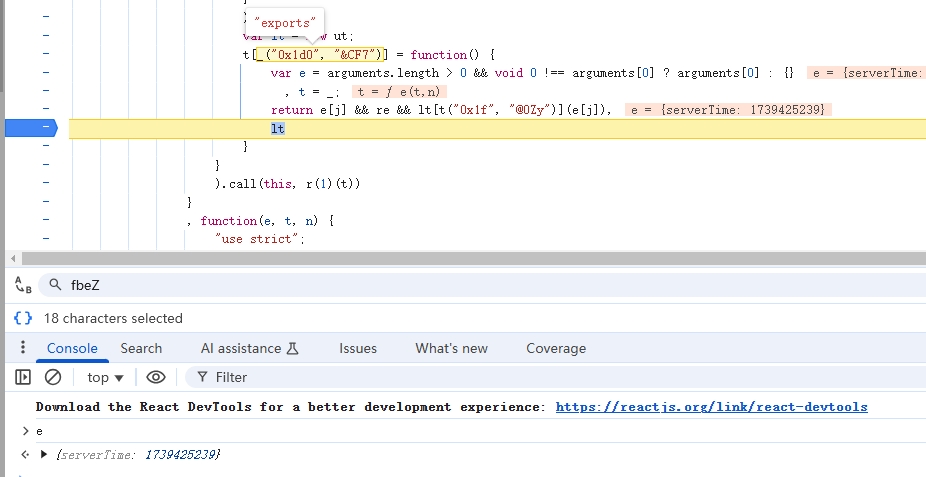
剩下的就补充一下基础环境就行了。
参数验证
写个小例子,验证下生成的参数是否正确,如下:

【anti-content参数生成js】:https://t.zsxq.com/9vGns
以上代码仅供学习交流使用,请勿用于其他任何目的!


















 1241
1241

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









